SEO-Константа
Яндекс.Директ + оптимизация
От методологии DiffusionRank давайте перейдем к не менее оригинальному алгоритму ранжирования AIR, также использующего в своей работе ссылочную информацию. Стоит отметить, что после их анализа было бы вполне логичным перейти к исследованию BrowseRank [17], рассчитываемого по графу веб-серфинга. Однако, как мы с вами неоднократно говорили, обзор алгоритмов, применяющих при своем расчете поведенческие факторы, выходит за рамки настоящей работы. Коммерческие организации, желающие продвинуть свои веб-сайты в результатах органической выдачи, вкладывают огромные суммы денежных средств на раскрутку. С другой стороны, SEO-компании находят все больше манипулятивных схем [5,8], которые с большей или меньшей эффективностью позволяют выводить ресурсы в ТОП 10 за счет искусственного завышения рейтинга цифровых документов. Большинство из предлагаемых поисковой оптимизацией решений являются лишь модификациями уже известных практик, к которым поисковые машины уже успели выработать иммунитет. Мы можем изменить форму, но для смены содержания нам потребуется куда более существенный шаг в сторону создания идеальной модели поискового спама, то есть настолько качественного репликанта, что ни один ссылочный алгоритм поисковой системы, не сможет отличить его от оригинала. Говоря о ссылочных алгоритмах [9, 10], мы, прежде всего, имеем в виду Google PageRank [2], который, несмотря на всю свою эффективность, на сегодняшний день имеет следующие уязвимости: во-первых, гарантированно распространяет на все новые документы в Глобальной Сети некоторое номинальное значение голосующей способности; во-вторых, рассматривает в качестве рекомендации посетить сторонний веб сайт абсолютно все входящие ссылки; в-третьих, в самом PR не предусмотрено штрафование на случай цитирования некачественных веб-страниц. Немного поразмыслив, мы можем вывести для себя такую агрессивную модель продвижения интернет-сайта, которая будет заключаться в автоматической генерации искусственной сети страниц, ссылающихся на тот документ/сайт, который мы бы хотели раскрутить. Каждой странице из нашего спам-множества будет присвоена некая минимальная голосующая способность, которая в совокупности даст необходимый импульс к поднятию URL в результатах органического поиска. Для обхода фильтров оценивающих качество или размер документа, мы также можем скачивать уже существующие в Сети содержимое, всего лишь изменяя присутствующие там пути на интернет-адрес нашей целевой страницы. С учетом полной автоматизации процесса, размер искусственного веба может приближаться масштабам реального, что незамедлительно отобразится на объективности всех оценок, присуждаемых Google PageRank. Несмотря на то, что для выявления некоторого набора атрибутов, сигнализирующих о неестественной природе документов с их последующей фильтрацией/удалением из результатов поиска [5], мы можем использовать ряд статичных факторов (непосредственно относятся к HTML-странице), куда более эффективной моделью представляется разработка нового механизма ранжирования, который позволит выйти на качественно новый уровень.
Несмотря на то, что ценность страницы для каждого конкретного человека будет зависеть от многочисленных субъективных предпочтений, мы полагаем, что естественные гиперссылки, рекомендующие данный документ для прочтения, могут служить для нас более объективным показателем, сигнализирующим о его качестве. Однако мы сможем присвоить всем нашим документам справедливые оценки лишь в том случае, если подавляющая часть глобальной гиперссылочной структуры будет проанализирована надлежащим образом, то есть от состояния самой системы будет зависеть то, насколько качественно мы сможем отранжировать включенные в нее элементы. Ниже предлагается модель ранжирования с учетом Аффинити-индекса (Affinity Index Ranking), посредством применения которой мы можем приближенно рассчитать относительное качество (или ранг) каждой страницы, оценивая ее популярность или авторитетность на основании гиперссылочного окружения. Алгоритм AIR подсчитывает ранг V интернет-документа i, используя схему голосования, подчиняющуюся следующим правилам:
Если ранг страницы не соответствует Правилу №3, он должен быть скорректирован. Например, если веб-документ передает прочим страницам в Сети больше голосов, нежели чем та сумма, которую он сам получает со своего ссылочного окружения, его ранг должен быть пессимизирован до достижения баланса между количеством входящих и исходящих голосов. Аналогично, ранг документа может быть увеличен в том случае, если число входящих голосов, превышает количество исходящих. Естественно, что при такой схеме корректировка коснется рангов всех соседствующих с нашим документом интернет-страниц, и процесс будет продолжаться итеративно до тех пор, пока вся система не будет приведена в состояние равновесия, удовлетворяя, тем самым, Правило №3. Образцы снабжаются необходимым числом голосов, необходимых им для поддержания возложенных на них обязательств, касательно обеспечения прочих документов в Сети способностью к индоссированию. Как правило, в качестве образцов избираются высококачественные и трастовые страницы (например, yahoo.com), а их достаточное количество гарантирует нам независимость от кого-то конкретного веб-узла. Для них мы устанавливаем максимальное ранговое значение Vmax = 100. Для того, чтобы схематически смоделировать предложенное нами решение мы будем использовать методологию электронных аналогий, то есть далее мы будем описывать данную модель голосования в виде эквивалентной электрической схемы. Ее пример вы можете увидеть на Рисунке 63. В литературе [4,14] для изучения социальных сетей, состоящих из некоторого множества связанных взаимоотношениями социальных объектов, в качестве элементов эквивалентной электронной схемы были применены резисторы. Резисторы также используются при эквивалентировании «малых миров» [11,12], суть которых заключается в том, что вопреки своим масштабам, в подавляющем большинстве крупных социальных сетей существует наикратчайший реберный путь между любыми двумя его вершинами. Например, в США средняя длина цепи знакомств составляет 6 человек.
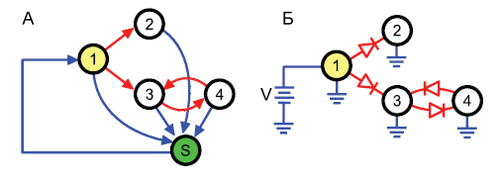
Рисунок 63. Связанный граф (а) и его эквивалентная электронная схема (б)
В нашей эквивалентной схеме мы будем рассматривать гиперссылки по аналогии с диодами. Примем за ранг V страницы электрический потенциал конкретного веб-узла (далее — узловой потенциал), тогда для расчета того значения саппортизации, которое документ j окажет странице i в случае ее цитирования, нам необходимо вычислить ток ветви Iji в соответствии с Законом Ома:
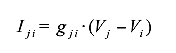
,где коэффициент gji является электропроводимостью идеального диода, принимающего гиперссылку за единицу электропроводимости. Как и всякий идеальный диод, он имеет нулевое сопротивление (gji=1) в том случае, если существует ссылка между узлами и Vj>Vi [см. Правило №1]; или, в противном случае, является абсолютным изолятором (gji=0). Опционально, коэффициент g0 электропроводимости к общему стоку может иметь отличное от регулярных ссылок значение. Ранг Vi документа i определяется Правилом токов Кирхгофа, которое гласит, что алгебраическая сумма сил токов для каждого узла равна нулю. Иными словами, сколько тока поступает в узел i, столько тока из него и вытекает [См. Правило №3]:
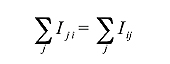
Все узлы имеют общий узел, который заземляется (его значение равно 0) [См. Правило №4], а узловые потенциалы образцовых документов в нашей схеме равны подключенному к ним идеальному источнику постоянного напряжения [См. Правило №5]. Для того, чтобы нам рассчитать относительный ранг интернет-страниц на веб-графе, эквивалентного электронной схеме, с помощью алгоритма AIR все величины рассматриваются нами как безразмерные, то есть их размерность принимается за единицу. Используя предыдущие уравнения, определим узловые потенциалы ссылочного окружения нашей страницы Vi:
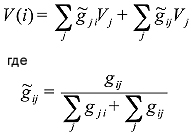
,где g~ij является отмасштабированной электропроводимостью. Последнее уравнение может быть решено с помощью таких простых итерационных методологий, как метод Якоби [3,15] при сохранении минимального потенциала в общем стоке Vmin=0 и поддержания необходимого узлового потенциала в образцовых страницах. Как и в Google PageRank, сложность подсчета AIR будет зависеть от числовых и структурных особенностей гиперссылок, хотя по причине влияния ранга веб-документов на электропроводимость диодов в нашей модели потребуется некоторое количество дополнительных итераций. Несмотря на схожесть присутствующих в обоих алгоритмах схем голосования [2], в нашем случае имеется ряд важных отличий. Во-первых, в отличие от PageRank, который воспринимает все без исключения гиперссылки как рекомендацию веб-мастера посетить ту или иную страничку, AIR рассматривает их как диоды, учитывая линки лишь с нисходящих по своему рангу интернет-документов [см. Правило №1]. Во-вторых, по причине того, что количество передаваемых по ссылке голосов зависит от ранговой разности, в алгоритме AIR саппортизация некачественных страниц является более «дорогой», нежели чем качественных веб-узлов [см. Правило №2]. Следовательно, если какой-либо документ все-таки имеет множество исходящих гиперссылок на некоторое множество некачественных страниц, тогда его узловой потенциал (или ранг) будет понижен до того момента, пока он не будет удовлетворять нашим требованиям [см. Правило №3]. Для большего понимания «стоимости ссылки», давайте представим, что мы пришли в очень необычный магазин с некоторой суммой денег. Необычность этого магазина заключается в том, что цена на товар тем выше, чем ниже его качество. Чем больше мы покупаем низкосортной продукции, тем меньше денег остается в нашем с вами кошельке. Обратная ситуация здесь заключается в том, что за более качественный продукт мы тоже заплатим, но куда более меньшую сумму денег. Представили? Отлично, потому что такая логика должна заставить веб-мастеров цитировать сторонние сайты с большей осторожностью во избежании наложения штрафных санкций на содержимое их сайта за использование методов ссылочного спама. В-третьих, в отличие от классического алгоритма Google PR в нашей модели не существует минимальной голосующей способности, даваемой всем вновь созданным страницам «не по заслугам, а по праву их появления в Сети». Здесь каждый документ должен заработать свой голос самостоятельно, получая естественные гиперссылки с качественных веб-сайтов. Скажем, что для полного исключения неестественных линков (в том числе и приобретенных на коммерческой основе) уровень траста данных сайтов должен очень высок (например, yahoo.com или dmoz.org).
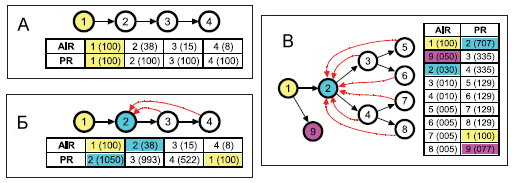
Рисунок 64. Сравнение AIR и Google PageRank на простой цепи (а) с обратными ссылками (б) и на ориентированной древовидной структуре (в)
На Рисунке 64 (а) изображена простая цепь, включающая в себя три веб-узла подключенных к образцовой странице (узел 1). По мере отдаления от точки отчета, за которую мы принимаем наш образец, значение AIR будет уменьшаться, что отличается от той философии, которая положена в модель Google PageRank, назначающая всем узлам в данной цепи одинаковую голосующую способность. Заметьте, что узел 3 (узел 4) располагается в двух (трех) кликах от образцового документа, в то время как узел 2 подключен к нему напрямую. Поскольку мы подразумеваем под образцами только качественные и высоко ранжируемые ресурсы, передача большего веса ближайшим от них вершинам выглядит вполне логичным. Это также находит свое оправдание с позиции рядовых интернет-пользователей, большинство из которых, после посещения какого-либо трастового ресурса (в нашем случае им является образцовый узел), могут проходить по исходящим ссылкам на менее популярные веб-сайты. Однако они нетерпеливы и крайне ленивы в поиске информации, поэтому мы считаем крайне маловероятным возникновение события, заключающееся в достижении узла 4, особенно в том случае, если их потребность будет удовлетворена узлом 2 или 3. В этом смысле, рис. 64 (а) отражает фактор близости (или Аффинити-индекс) всякой интернет-страницы от образцового узла. Давайте теперь посмотрим на Рисунок 64 (б), на котором мы добавили 3 и 2 узлу нашей простой цепи обратные ссылки, ведущие на узел 2. В соответствии с Правилом №1 алгоритм AIR будет игнорировать данные линки при подсчете ранговых показателей, что существенно отличается от модели PageRank, который автоматически учтет всех участников вышеописанного голосования. Более того, последовательность узлов 2-4 имеет даже больший PageRank, чем сам документ-образец!
Идем дальше. Ориентированная древовидная структура, изображенная на рисунке 64 (в), продолжает демонстрацию всех преимуществ алгоритма AIR над классическим Google PR. Исходя из нее видно, что узел 2 является центральным элементом ссылочной фермы, используя в качестве своих саппортеров сгенерированное множество потомков (узлы 3-8), которое на него ссылается. Поисковое продвижение сайтов активно использует подобного рода манипулятивную практику при увеличении PR целевого документа: цитирующие целевую страницу потомки 3-8 не только возвращают все голоса, которые они получают от узла 2, но и агрегированные значения своего минимального весового приращения, получаемого от своего родителя вследствие эффекта обратной связи. Именно по причине действующей в PR обратной связи, которая наблюдается на каждой итерации алгоритма вплоть до достижения мыслимой точки сходимости, узел 2 получает более высокий PageRank, что еще больше увеличивает голосующую способность его потомков. В алгоритме AIR такая схема работать не будет, поскольку узел 2 не только не сможет получить приращение своей голосующей способности за счет цитирования менее авторитетных документов, но и будет пессимизирован (при подсчете AIR его голос оказывается ниже, чем веб-узла 9) по причине массового использования в качестве саппортеров низкокачественных страниц.
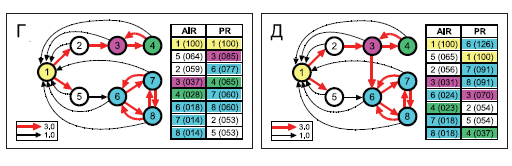
Рисунок 65. Сравнение AIR и Google PageRank на ориентированном графе с манипулятивной схемой (г), а также легальный способ продвижения в новой модели ранжирования(д)
Рисунок 65 (г) изображает ориентированный граф, на котором одно ребро красного цвета соответствует трем ребрам черного. Как вы можете видеть, узлы 6-8, формирующие искусственную сеть документов, являются сильно-связанными, а также изолированными от оставшейся части (узлы 1-5) естественного веба за исключением одной единственной ссылки, ведущей из узла 5 в 6. Вопреки чувствительности Goolge PageRank к таким искусственным структурам, при которых он ранжирует спам-страницы (узлы 6-8) выше, нежели чем высококачественные сайты реального веба (узлы 2 и 5), алгоритму AIR удается вычислить обманные техники и отсортировать все их множество надлежащим образом. Чем большее число HTML-страниц / сайтов будет включаться в искусственное образование, тем жестче будут штрафные санкции, которые мы к ним применим. Отсюда, ошибочно полагать, что увеличение размеров сети веб-сайтов, увеличит шансы успешной раскрутки в органическом поиске. Рисунок 65 (д) иллюстрирует законный способ увеличения голосующей способности веб-страниц в предложенной нами модели AIR. Дополнительный исходящий линк с 3 на 6-ой узел улучшит авторитетность и, соответственно, видимость интернет-сайта, содержащего документы 6-8, в результатах органического поиска. Получив саппортизацию качественного ресурса (узел 3), он автоматически включается в естественный веб, и даже получает более высокий ранг, чем узел 4. Важно отметить, что в результате саппортизации узла 6, документ-донор 3 испытает понижение своего ранга. Учитывая то обстоятельство, что единственное отличие рисунка 65 (г) от 58 (д) заключается в наличии данного линка, можно предположить, что пессимизация голосующей способности веб-страницы 3 является несправедливой, ведь она рекомендует к посещению высококачественный ресурс. На самом деле, схожая картина обнаруживается и на других веб-узлах. Например, на рисунке 65 (г), при наличии меньшего числа входящих гиперссылок интернет-страничка 5 получает больший вес, чем узел 2. Однако именно эта мнимая «несправедливость» является, наверное, одной из самых основных характеристик алгоритма AIR, предполагающего лишь нисходящую саппортизацию, следующей от образцового узла к общему стоку. По сути, здесь мы можем провести четкую аналогию с вентильным свойством p-n-перехода, пропускающего электрический ток только в одном направлении. Только превосходящий по своим показателям родитель может «профинансировать» ранг своих потомков: либо исходящие гиперссылки оказываются бесполезными в плане увеличения голосующей способности страницы (проставляется линк на родителя), либо они понижают ее ранг (проставляется линк на потомка), за исключением тех авторитетных сайтов, которые принимаются нами в качестве образцов и чья авторитетность фиксирована. Никто не может увеличить ранг документа, который уже и так имеет самый высокий ранг среди множества веб-узлов, посредством применения таких манипулятивных схем, как генерация огромного количества интернет-страниц на сайте с целью поднятия голосующей способности целевого узла. Эта особенность алгоритма AIR возвращает ссылкам их первоначальный смысл, а именно обеспечение пути к наиболее ценной и полезной для пользователей информации, а также облегчения навигации между HTML-страницами. Также, мы предполагаем, что вебмастера будут более аккуратно и избирательно подходить к обмену ссылками между сайтами.
Для того чтобы продемонстрировать устойчивость алгоритма AIR к ссылочному спаму, мы решили сравнить эффективность его работы не только с классическим алгоритмом Google PageRank, но также и с такими специальными методами, как DiffusionRank и TrustRank [7]. Для начала мы используем тот же самый малый граф, который упоминался в работе H. Yang [16], где манипулятивная схема реализовывалась посредством последовательного создания сети потомков и обмена ссылками (см. Рис. 66). Здесь страница 4 выбирается в качестве трастового (или образцового) узла. Добавляя к нашей схеме новых потомков (A,B,C,…), узел 1 пытается увеличить свою голосующую способность. Далее, наблюдая за его относительной оценкой и рангом, мы будем делать выводы об эффективности того или иного алгоритма в задачах вычисления спама.
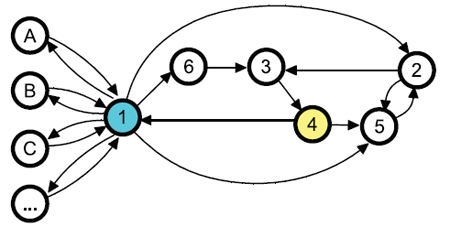
Рисунок 66. Пример графа, используемого при тестировании алгоритмов на предмет устойчивости к схемам манипуляции
Для расчета PageRank, TrustRank и DiffusionRank мы использовали коэффициент затухания α=0.85. Коэффициент теплопроводности в DiffusionRank составляет 1; для AIR коэффициент электропроводимости g0=0.5. Для достижения точки сходимости количество итераций во всех трех алгоритмах составляет 100. Результаты эксперимента представлены на рисунке 67.
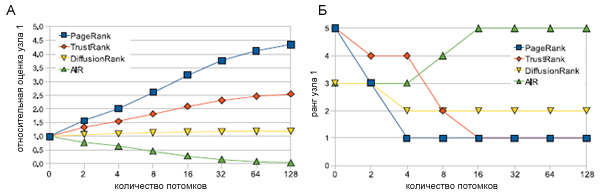
Рисунок 67. Сравнение относительной оценки (а) и ранга (б) манипулируемого узла.
Видно, что из всех алгоритмов наиболее устойчивым к ссылочным манипуляциям оказывается метод AIR. Второе и третье место занимают DiffusionRank и TrustRank соответственно, а классический алгоритм Google PR демонстрирует наихудший результат. Мы также наблюдаем, что AIR является единственным алгоритмом, который действительно понижает оценку манипулируемого узла 1 (см. Рис. 67 (а)). Вследствие используемого оптимального коэффициента теплопроводности,
оценка, присуждаемая алгоритмом DiffusionRank растет крайне медленно. Еще один интересный момент заключается в увеличении оценки, присуждаемой алгоритмом TrustRank веб-узлу 1, хотя она возрастает не столь быстрыми темпами, как в случае с Google PR — страница достигает ранга 1 после добавления в нашу манипулятивную схему 16 потомков (см. Рис. 67 (б)). Далее мы использовали набор данных Become.com, включающий в себя более 3.5 млрд. страниц и 40 млрд. ссылок. После того, как документы были отранжированны по PR и AIR, мы подсчитали количество веб-страниц, содержащих в своих URL ключевые слова (sw1, sw2,…, swN), которые наиболее распространены в спамденсинге. Рисунок 68 демонстрирует, что AIR является более эффективным для подавления спама в результатах поисковой выдачи и улучшения качества поиска. Несмотря на то, что по запросу взрослой тематики sw1 алгоритм AIR показал большее присутствие соответствующих страниц, чем Google PageRank, более детальный анализ показал то, что подавляющая их доля относилась к легальным веб-ресурсам, не использующих технологий ссылочного спама.
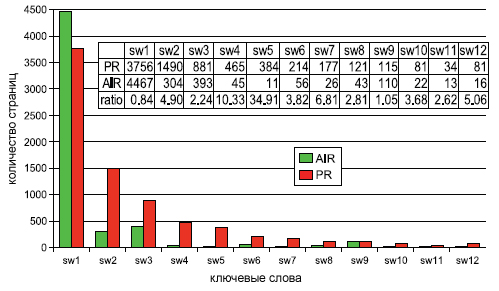
Рисунок 68. Подавление спамденсинга.
Оригинал: «Ranking billions of web pages using diodes»
Ссылки:
[1] Arasu, A., Cho, J., Garcia-Molina, H., Paepcke, A., and Raghavan, S. Searching the Web. ACM Transactions on Internet Technology 1, 1, (June 2001) 2–43.
[3] Bronshtein, N. I., and Semendyayev, A. K. Handbook of Mathematics, 892. Springer-Verlag, New York, 3rd edition, 1997.
[4] Faloutsos, C., Mccurley, S. K., and Tomkins, A. Fast discovery of connection subgraphs. In Proceedings of the 2004 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, NY, (2004), 118-127.
[6] Gulli, A., and Signorini, A. The indexable Web is more than 11.5 billion pages. In Special interest tracks and posters of the 14th International Conference on World Wide Web, ACM, NY, (2005), 902-903.
[8] Henzinger, M., Motwani, R., and Silverstein, C. Challenges in Web search engines. SIGIR Forum 36, 2, 2002.
[9] Kleinberg, J., and Lawrence, S. The structure of the Web. Science, 294:1849, 2001.
[11] Korniss, G., Hastings, B. M., Bassler, E. K., Berryman, J. M., Kozma, B., and Abbott, D. Scaling in small-world resistor networks. Physics Letters A, 350:324, 2006.
[12] Lopez, E., Buldyrev, V. S., Havlin, S., and Stanley, S. H. Anomalous transport in scale-free networks. Physical Review Letters 94, 24, 2005.
[13] Lyman, P., Varian, R. H., Swearingen, K., Charles, P., Good, N., Lamar Jordan, L., and Pal, J. How much information? 2003; sims.berkeley.edu/howmuch-info-2003, 2003.
[14] Newman, M. E. J., and Girvan, M. Finding and evaluating community structure in networks. Physical Review E (Statistical, Nonlinear, and Soft Matter Physics) 69, 2, 2004.
[15] Press, H. W., Flannery, P. B., Teukolsky, A. S., and Vetterling, T. W. Numerical Recipes in FORTRAN: The Art of Scientific Computing. Cambridge University Press, Cambridge, U.K, 1992, 864-866.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации