SEO-Константа
Яндекс.Директ + оптимизация
В текущем материале предлагается подход, позволяющий идентифицировать релевантные источники информации на основании истории скомбинированных поведенческих данных множества пользователей, которые собираются на поиске, а также при просмотре страниц интернет-сайтов. В то время как предыдущие исследования сфокусировали свое внимание на взаимодействии пользователей с системами информационного поиска, наглядно продемонстрировав, что оно может быть использовано в целях улучшения ранжирования цифровых документов, поведение пользователей, которое складывается при просмотре документов вне страниц с результатами поисковой выдачи, было в значительной степени ими проигнорировано. Настоящая работа демонстрирует, что пользовательская активность при просмотре страниц по окончанию поиска отчетливо отражает неявное одобрение посещенных страниц, позволяющее оценить тематическую релевантность интернет-ресурсов, посредством майнинга крупномасштабных наборов данных маршрутов поиска. Мы предлагаем эвристический и вероятностный алгоритмы, которые используют в своей работе подобные наборы данных для предложения авторитетных веб-сайтов по поисковым запросам. Экспериментальная оценка показала, что использование полных маршрутов пользовательских просмотров по окончанию поиска, по отдельности превосходит альтернативные способы получения данных (например, логи пользовательских кликов), а также улучшает аккуратность в случае их применения в качестве характеристики в задачах обучения ранжированию.
Традиционные технологии информационного поиска определяли релевантность документов относительно заданного запроса, вычисляя сходство между его содержимым и текстом пользовательского вопроса [36]. Проблемы поиска информации в масштабах Глобальной паутины мотивировали разработчиков к созданию ряда подходов, использующих такие источники данных, которые выходили за пределы содержимого веб-страниц. К ним можно отнести структуру гиперссылочного графа [10, 23, 26], взаимодействие пользователей с поисковыми системами [17, 2, 4, 42], а также алгоритмы машинного обучения, которые комбинируют различные характеристики в задачах оценки релевантности ресурсов [5, 7,33, 19]. Общим у многих из указанных выше алгоритмов информационного поиска было использование при оценки авторитетности веб-документов основания, вытекающего из неорганизованного поведения множества индивидуумов. Гиперссылочная структура, создаваемая миллионами отдельных веб-мастеров и используемая как алгоритмами HITS [23] и PageRank [26], так и многими другими, служит только одним из ярких примером феномена, возникающего из локальной активности множества пользователей. Другая группа алгоритмов информационного поиска, которая использует в своей работе крупномасштабные данные пользовательского поведения, включает в себя методологии, учитывающие логи пользовательских кликов (search engine clickthrough logs) на страницах с результатами поиска, клик по которым рассматривается как неявное голосование за авторов соответствующих страниц и/или их релевантности, относительно исходного запроса [17, 48, 2, 4]. Кроме того, логи пользовательских запросов (search engine query logs) могут включаться в контекст пользовательского запроса, полученного из исторических данных его поиска, совершенствуя, тем самым, модели языка запросов, которые, в свою очередь, улучшают аккуратность поисковых результатов [42].
В то время как в предыдущих исследованиях нам демонстрируется ценность логов пользовательских запросов и кликов как источника неявного контроля за алгоритмами обучения, подавляющая доля пользовательского поведения, наблюдаемая при просмотре веб-страниц, складывается вне их взаимодействия с системами информационного поиска. В них сообщается, что поведение пользователей при поиске информации часто включает в себя ориентирование: переход к интересующим их ресурсам посредством выполнения последовательности шагов, а не попытка достижения целевого документа непосредственно через вопрос, задаваемый поисковой системе [43]. Следовательно, поведение пользователей, которое складывается при просмотре документов вне страниц с результатами поисковой выдачи, представляется для нас ценным источником данных в задачах идентификации документов, релевантных информационным целям пользователей, раскрытых ими при подачи на поиск своих предыдущих запросов.
В данной работе предлагается использовать комбинацию активности множества веб-пользователей, связанную с поиском и просмотром интернет-документов в целях идентификации релевантных ресурсов для их последующих вопросов. Насколько мы знаем, предшествующие подходы не брали в расчет майнинг истории пользовательской активности вне результатов органической выдачи, и результаты наших экспериментов показывают, что комплексные логи (comprehensive logs) поведения пользователей по окончанию поиска являются информативным источником неявной обратной связи для определения релевантных ресурсов. Мы также расходимся с предыдущими исследованиям в том аспекте, что предлагаем модели, основанные на термах (term-based models), которые обобщают прежде неучтенные запросы, составляющие значительную долю всех пользовательских вопросов, адресуемых системе информационного поиска.
Для того чтобы продемонстрировать полезность использования коллективного поведения интернет-пользователей на поиске и при просмотре веб-сайтов в задачах оценки авторитетности цифровых документов, мы опишем ряд алгоритмов, полагающихся на такого рода данные при идентификации релевантных ресурсов по новым поисковым запросам. Наш первоначальный подход мотивирован эвристическими методологиями, которые применяются в традиционном информационном поиске, основанном на модели векторного пространства. Затем, мы совершенствуем его посредством применения вероятностной порождающей модели к документам, запросам и их термам; наилучшие результаты достигаются при использовании того варианта модели, которая включает в себя модификацию простого случайного блуждания. Интуитивно, все указанные алгоритмы используют логи пользовательского поведения, чтобы выдавать в ответ на запрос те сайты, которые ранее были высоко оценены другими пользователями со схожими (или аналогичными) запросами.
Мы оцениваем предложенные алгоритмы, используя независимый набор данных запросов, адресованных системе информационного поиска, для которых асессоры определили релевантные веб-страницы, а также автоматически сгенерированный набор данных, состоящий из ранее неучтенных запросов. Полученные результаты демонстрируют, что релевантные сайты идентифицируются с большей аккуратностью в том случае, когда используются полные маршруты пользовательских просмотров по окончанию поиска с ассоциированным количеством остановок, по сравнению с использованием исключительно пользовательских кликов, совершаемых на странице с результатами органической выдачи, или в случае игнорирования количества остановок. Мы также демонстрируем, что модели, использующие термы поисковых запросов, являются более предпочтительными, если исходить из предшествующих вопросов, с которыми пользователи обращались на поиск, постольку, поскольку большая часть из них является уникальной. Наконец, мы демонстрируем, что поведение пользователей при просмотре страниц, следующее по окончанию поиска, может быть использовано для улучшения производительности алгоритмов обучения ранжированию в дополнение к стандартным контентным, ссылочным и поведенческим характеристикам, используемым в поисковых машинах.
Оставшаяся часть работы организована следующим образом. В Разделе 3 мы рассматриваем смежные работы, посвященные информационному поиску и дата майнингу. В Разделе 3 описываются данные пользовательского поведения и их предварительная обработка для получения пользовательских маршрутов поиска и просмотров. В Разделе 4 представляются наши методологии, которые предназначаются для получения скорринг-особенностей релевантности. Экспериментальная оценка и анализ полученных результатов приводятся в Разделе 5, с последующим обсуждением будущей работы и подведением итогов в Разделах 6 и 7 соответственно.
Исследования информационного поиска наследуют использование частоты употребления слов, а также их распределения в качестве основы для всех операций, связанных с поиском информации [36]. Для этого существует достаточно веская причина: ранжирование документов осуществляется на основании статистических моделей их содержимого, позволяющих развивать вероятностные методологии ранжирования (например, работы [24, 35]), которые количественно измеряют соответствие документов информационным потребностям, формализованных в виде поискового запроса. Однако в органическом поиске источники доказательства релевантности, находящиеся за пределами контента, также оказались полезными в задачах ранжирования документов. Взаимные гиперссылки, создаваемые между страницами сайтов, позволяют веб-мастерам связывать их документы, сайты, а также архивы с другими релевантными интернет-ресурсами. Алгоритмы ссылочного анализа использовали эту демократическую особенность авторской страницы в качестве неявного одобрения цифровых документов, содержащихся в Сети. В основном, алгоритмы ссылочного анализа либо запросо-независимые (например, PageRank [26]), где относительная авторитетность веб-страницы и домена рассчитывается в оффлайновом режиме до обращения пользователя к поиску со своим вопросом, либо запросо-зависимые (например, HITS [23]), в которых оценки назначаются цифровым документам в процессе поиска с учетом их алгоритмического соответствия пользовательскому запросу. Ключевой характеристикой алгоритмов гиперссылочного анализа является то, что они рассчитывают значение авторитетности на основании ссылок, созданных веб-мастерами и предположения о том, что пользователи перемещаются по данному графу случайным или псевдо-интеллектуальным образом. Однако с учетом быстрого роста пользования Глобальной сетью, на текущем этапе возможно использование коллективного поведения, складывающегося при просмотрах страниц множеством интернет-пользователей, в целях улучшения качества поиска, нежели чем применение случайных или прямых обходов веб-графа. Для этого в текущей работе мы опишем использование коллективного поведения множества интернет-пользоватей, складывающегося при просмотре страниц по окончанию поиска.
Алгоритмы неявной обратной связи [22] использовали наблюдаемые исследователями аспекты взаимодействия пользователей на поиске (например, логи запросов, клики по результатам алгоритмической выдачи, количество демонстраций страницы, активность скроллинга для поддержания более эффективного поиска. С учетом того, что выражение истинных интересов и намерений пользователей поиска существенно зашумлено, ряд исследований использовали надежность неявной обратной связи. В работе [21] Kelly и Belkin сообщают, что время, которое пользователь затрачивает на прочтение, не может быть свидетельством релевантности документа, и оно существенно варьируется в зависимости от тематик и поставленных задач, крайне затрудняя адекватную интерпретацию. В противоположность этому умозаключению, Fox и др. [12] демонстрируют в своем исследовании, что общее время пользовательских взаимодействий с системой информационного поиска, а также количество кликов, указывают на удовлетворенность пользователя предложенными ему результатами. Joachims и др. [18] обнаружили, что кликабельность зависит от релевантности результата, а также то, что пользователи полагаются на своё мнение о поисковой системе и на общее качество результатов. В своей работе они предлагают стратегии, которые позволяют генерировать из пользовательских кликов относительные сигналы обратной связи. Shen и др. и Tan и др. [39, 42] использовали логи пользовательских запросов для обогащения моделей языка запросов посредством включения контекста, полученного из продолжительного по времени пользовательского поведения. White и др. [47] разработали ряд пользовательских интерфейсов, нацеленных на получение более аккуратной обратной связи для текущего пользователя, основываясь на тех информационных элементах с которыми происходит взаимодействие; это помогает отдельным пользователям достигать своих целей. В качестве альтернативы используется неявная обратная связь для охвата преобладающих намерений множества пользователей поиска.
Записи кликов обеспечивают поисковые машины ненадежными признаками релевантности, основанной на метаданных, предоставленных пользователю на странице поисковых результатов. Указанные записи могут быть полезными в качестве обучающих данных для ранжирующих алгоритмов [17, 3], при ранжировании документов по отдельности [2] или в комбинации с запросной информацией [30], для аннотаций [48] и поисковых подсказок [6, 20]. Однако последние исследования, связанные с поведением пользователей на поиске [43, 46] демонстрируют, что существенная доля взаимодействий, совершаемых в ходе поисковых сессий наблюдается вне страниц с результатами алгоритмического поиска. Алгоритмы неявной обратной связи, которые фокусируются исключительно на взаимодействии пользователей с поиском не учитывают этот потенциально ценный источник информации, уменьшая их возможную эффективность. Следовательно, мы надеемся, что учет подобного рода взаимодействий позволит построить улучшенные алгоритмы ранжирования, нежели чем те, что основаны только на итерациях с поиском. Agichtein и др. [2] использовали характеристики просмотров для обучения алгоритмов ранжирования, а также продемонстрировали улучшение качества поиска. Тем не менее, наша работа существенно отличается от прочих исследований по трем основным аспектам: (i) посредством использования подходов лингвистического моделирования мы можем обобщать неучтенные запросы, вместо того, чтобы запоминать поведение, ассоциированное с ранее учтенными вопросами пользователей; (ii) мы используем полный маршрут пост-запросной навигации, включающей в себя документы, на которые приходится множество кликов со странице органической выдачи, а не только первую тройку посещенных документов; (iii) мы осуществляем более точное сравнение между использованием в анализе только данных о кликабельности и поведением пользователя, наблюдаемое по завершению поиска.
Некоторыми исследователями был предложен ряд подходов, основанных на машинном обучении, для создания адаптивных характеристик ранжирования, которые сочетали в себе множество различных источников положения о релевантности, включая и те, что обеспечивались прочими алгоритмами. Среди последних работ, посвященных указанным подходам, можно выделит: Burges и др [7], в работе которых был разработан алгоритм ранжирования, основанный на искусственной нейронной сети; Richardson и др. [33], в которой использовалось взаимодействие множества пользователей с доменами сайтов для улучшения их статичного ранга вне зависимости от гиперссылочной структуры; работа Agarwal и др. [1], в которой было предложена комбинация случайных блужданий по гиперссылочному графу с обратной связью; наконец, Agichtein и Zhang [4], в работе которых была применена технология классификации с задействованием алгоритмов машинного обучения для включения положений о релевантности на основании кликабельности в выборку высокоранжируемых результатов алгоритмического поиска. Описанный нами подход может быть использован в сочетании с указанными и схожими с ними методологиями, обеспечивая их дополнительными характеристиками в целях комбинированного ранжирования, что, в свою очередь, приводит к большей аккуратности.
Логовый анализ паттернов пользовательских просмотров, фиксируемых в рамках определенных интернет-сайтов, может привести к пониманию пользовательских потребностей и намерений, а следовательно, информировать веб-мастера о необходимых изменениях структуры своего ресурса для обеспечения пользовательской удовлетворенности [28, 29]. Пути просмотра, следующие за человеческими «первопроходцами» [8] посредством информационного пространства может предоставить в неявном виде сходства и ассоциации между посещенными элементами, которые могут включаться в системы рекомендаций маршрута [11]. Подход, который мы описали в текущей работе, аналогичен указанным исследованиям в том смысле, что он использует маршруты для выявления интересов пользователей, однако в куда большем масштабе и для несколько другой цели, а именно для оценки релевантности, нежели чем включения в системы рекомендации маршрутов в задачах поддержки просмотров. В работе [44] Wexelblat и Maes описывают систему поддержки внутридоменной навигации, основанной на маршрутах просмотра документов другими пользователями. В своей недавней работе [27], Pandit и Olston представили руководящую информационно-маршрутную модель навигационно-поддерживающего поиска, основанную на стохастической симуляции поведения при просмотре страниц. В противоположность этой работе, наш подход сосредоточен на управлении данными: мы предлагаем модель релевантности, обучающуюся на крупных наборах данных пользовательского поведения, напрямую используя исторические данные реальных пользователей на поиске, а также при просмотре ими страниц веб-сайтов.
Исследования в области совместного фильтрования использовали явную и неявную информацию о пользовательских предпочтениях для рекомендаций в таких специализированных областях, как ленты новостей [31], музыкальные альбомы и артисты [38], электронная коммерция [37]. Однако насколько нам известно, указанные технологии не использовались непосредственно на органическом поиске. В предыдущем материале, мы использовали множество пользовательских итераций, выполняемых в ходе просмотра, для создания документных рекомендаций, основанных на пункте назначения, в который прибывает множество иных пользователей Сети со схожими информационными нуждами [45]. Эти популярные пункты назначения постоянно располагались в конце пост-запросных навигационных маршрутов большинства пользователей и были им рекомендованы отдельно от результатов органической выдачи (то есть, в перечне рекомендаций, которые были размещены рядом с поисковыми результатами). В текущей работе мы описываем использование маршрутов относительно ранжирования, нежели чем области интерактивных подсказок, а также используем все страницы по маршрутам, а не только пункт назначения, что, как мы демонстрируем, значительно улучшает результаты. Мы предлагаем алгоритмы майнинга маршрутов; исследуем вопрос о том, действительно ли использование взаимодействий за пределами страницы с результатами органической выдачи добавляет существенную пользу поисковым результатам, а также определяем полезность добавления прохождения маршрута как характеристики для обучения ранжированию.
Панели инструментов, расширяющие функциональность интернет-обозревателей, за последние годы становятся все более популярными среди пользователей, обеспечивая им ускоренный доступ к таким дополнительным возможностям, как осуществление поиска без непосредственного захода на главную страницу той или иной поисковой системы или возможность поиска по посещенным ранее страницам. Примеры наиболее популярных тулбаров включают те, которые аффилированы с поисковыми машинами (например, Google Toolbar, Yahoo! Toolbar и Windows LiveToolbar), а также те, что ориентированы на пользователей с определенными интересами (например, StumbleUpon и eBay Toolbar). В целях обеспечения исследователей ценными характеристиками интернет-пользователей, большинство популярных тулбаров отправляют историю пользовательского поведения на центральный сервер, если пользователи согласились на подобную отправку персональных данных при установке. Каждая запись в логе включает в себя анонимный идентификатор сессии, метку времени и URL-адрес посещенной веб-страницы.
На основании этих, а также схожих логов взаимодействия могут быть реконструированы пользовательские маршруты посредством использования методологии, описанной White и Drucker [46]. Мы извлекаем указанные маршруты из логов пользователей Windows Live Toolbar. Для каждого пользователя логи взаимодействий были сгруппированы на основании информации идентификатора интернет-обозревателя. Для каждого экземпляра интернет-браузера, пользовательская навигация была обобщена в качестве пути, известного как маршрут обозревателя (browser trail), от первой до последней посещенной веб-страницы данным браузером. Поисковые маршруты (search trails) содержатся внутри некоторых из этих маршрутов, и начинаются с момента отправки пользовательского запроса коммерческой системе информационного поиска; они являются теми поисковыми маршрутами, которые мы используем для обучения алгоритмов, описанных в последующих разделах.
После старта поисковых маршрутов с момента подачи поискового запроса, они продолжаются вплоть до достижения точки своего завершения (подключения), в которой, как предполагается, пользователь завершает свою информационно-поисковую активность или достигает определенного аспекта информационных потребностей. Маршруты должны содержать страницы, которые либо представляют собой страницы результатов органической выдачи, либо документы, связанные со страницей алгоритмической выдачи через последовательность пройденных гиперссылок. Извлечение поисковых маршрутов с использованием указанной методологии также делает шаги на пути обработки нескольких задач, когда пользователи выполняют множественный поиск. Поскольку пользователи могут открывать новое окно браузера (или вкладки) при поиске необходимой информации, каждая задача имеет свой собственный маршрут браузера, а также соответствующий ему отдельный поисковый маршрут.
Для уменьшения количества «шума», следующего из страниц, не связанных с пользовательской активностью при выполнении поисковых задач, который может загрязнять наши данные, поисковые маршруты оканчиваются в том случае, когда наступает одно из следующих событий: (1) пользователь обращается с новым поисковым запросом; (2) пользователь возвращается на главную страницу поисковых систем, инициирует в браузере окно отправки электронной почты или посещает страницу, которая требует аутенфикации, вводит URL-адрес или посещает страницу, содержащуюся в закладках; (3) просмотр страницы продолжается более 30 минут при полном отсутствии какой-либо активности со стороны пользователя; (4) пользователь сворачивает активное окно браузера. В среднем наличествует порядка 5 шагов, приходящихся на поисковый маршрут. Для того чтобы проиллюстрировать указанную концепцию, мы изображаем поисковый маршрут в качестве поведенческого веб-графа [9], пример которого представлен на Рисунке 1. Этот граф отражает пользовательскую активность в рамках поискового маршрута, начиная с подачи запроса и заканчивая точкой, в которой выполняется один из приведенных выше четырех критериев окончания маршрута. Узлы графа представляют собой интернет-страницы, посещенные пользователем: прямоугольники представляют собой просмотренные страницы, а прямоугольники с закругленными углами — это страницы с результатами органической выдачи. Вертикальные линии представляют собой возврат к предыдущему состоянию. «Обратная» стрелка, такая как указана под узлом p2, предполагает, что пользователь вернулся к документу, ранее посещённому в ходе своего поискового маршрута. Темпоральная последовательность событий продолжается слева направо, а затем сверху вниз.
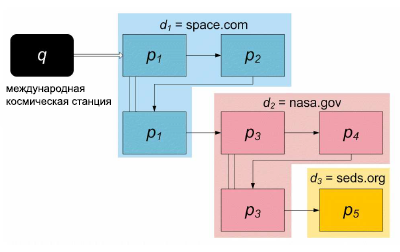
Рисунок 1. Пример поискового маршрута
Глядя на Рисунок 1 видно, что маршрут начинается с пользовательского запроса [международная космическая станция], адресуемого коммерческой поисковой машине. Пользователь переходит со страницы результатов алгоритмической выдачи на страницу p1, ассоциированную с веб-сайтом space.com (d1), перемещается на другую страницу p2 в пределах заданного интернет-ресурса, а затем возвращается на исходный документ p1. С него пользователь следует по гиперссылке, ведущей на сайт nasa.gov (d2), откуда он следует по ссылке на главную страницу сайта организации «Студенты за освоение космоса и развитие космонавтики» (d3=seds.org), где заданный поисковый маршрут завершается. Данный пример демонстрирует высокую информативность пост-поискового пользовательского поведения с навигацией по нескольким страницам различных сайтов в длительном временном интервале.
Логи данных пользовательского поведения могут быть преобразованы в набор данных поисковых маршрутов D = {q→(d1, . . . , dm)} как это было описано в предыдущем Разделе, в котором для каждого запроса, с которым пользователь обратился на поиск, q упорядоченная последовательность документов m заключает в себе указанный маршрут. (Несмотря на то, что в этом Разделе мы говорим о di как о «документе», им может являться и веб-сайт, и страница, и домен или какой-либо другой абстрактный ресурс). Кроме этого, время пребывания (dwell time) t(q~→di) может извлекаться из маршрута для каждого документа di посредством использования информации временных меток. С учетом того, что наша цель заключается в использовании указанного корпуса D в задачах идентификации релевантных ресурсов для будущих запросов, непосредственный подход заключается в хранении фактических запросов вместе с ассоциированными документами, ранжируя выше те из них, которые имеют высокие индексы посещаемости или продолжительное кумулятивное время пребывания. Однако мы обнаружили, что более 60% пользовательских поисковых запросов являются уникальными для заданной пользовательской сессии по всему набору данных за 12 месяцев, которые имеются в нашем распоряжении, что препятствует применению этого подхода для подавляющего большинства входящих запросов (сравнительные доли уникальных запросов сообщаются в более ранних исследованиях логов пользовательских запросов [40, 15]). Следовательно, обобщение прошлого пользовательского поведения до новых запросов требует разработки моделей, основанных на термах (term-based models), схожих с теми, что традиционно применялись в стандартном информационном поиске. Здесь и далее мы предполагаем, что каждый запрос q может быть представлен в качестве неупорядоченного набора k термов или фраз, q = {t1, . . . , tk}, полученного посредством токенизации и/или дополнительных этапов обработки, которые могут включать нормализацию токена, расширение запроса, распознание именованной сущности, а также построение n-грамов. В следующих подразделах мы опишем некоторые поисковые модели, основанные на термах, которые используют наборы данных пользовательского поведения.
Для начала мы рассмотрим специальную модель, мотивом к разработке которой послужил успех эвристики TF.IDF (частота слова x обратная частота документа), а также ее модификаций на традиционном текстовом поиске. На основании поисковых маршрутов корпуса D мы создаем представление документов в векторном пространстве, в котором каждый документ di представлен через агломерацию запросов, по которым указанная страница была посещена пользователями в ходе их поисковых маршрутов. Каждый документ, таким образом, описывается как разреженный вектор, ненулевые элементы которого кодируют относительный вес соответствующего терма. Веса в указанной модели должны захватывать частоту с которой пользователи посещали документ после своих запросов, содержащих каждый терм, отмасштабированный пропорционально относительной специфичности данного терма по всему корпусу запросов. Тогда, учитывая корпус поискового маршрута D, компонент, соответствующий терму tj в векторе, представляющего документ di, может быть рассчитан как произведение частоты запросного терма QTFi,j и обратной частоты запроса для данного терма IQFj:
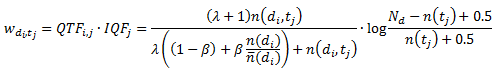
где:
Данная формула является эффективной адаптацией оценочной функции BM25, которая, в свою очередь, является вариацией традиционной эвристики TF.IDF, доказавшей хорошую производительность в нескольких поисковых тестированиях [34]. Для получения частотностей терма, рассчитываемых по всем маршрутам, которые начинались запросами с данным термом и вели на документ n(di,qj), можно использовать несколько разных реализаций функции характеристики f(q~→di), чтобы взвесить вклад каждого отдельного маршрута. В нашей работе мы рассматриваем три варианта данной функции:
При работе с большим объёмом типовых корпусов D поисковых маршрутов векторы документа эффективнее всего вычисляются за несколько итераций, конструируя индекс терма и документа, затем рассчитывая частотность терма-документа и, наконец, рассчитывая итоговые оценки документов-термов. При данном запросе q^ = {t^1,…,t^k}, документы-кандидаты извлекаются из инвертированного индекса для расчёта их релевантности через скалярное произведение векторов документа и запроса:
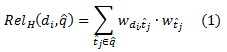
,где wt^j – относительный вес каждого терма в запросе, рассчитанный через обратную частоту запроса по выборке всех запросов в корпусе:
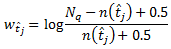
где Nq и n(t^j) – это общее число запросов и число запросов, содержащих терм t^j, соответственно.
В последнее время повышенным интересом стали пользоваться статистические подходы к информационному поиску по контентной основе, которые рассматривались наряду с эвристическими методиками на протяжении нескольких десятилетий. Помимо элегантности своей теории, вероятностные модели поиска обладают конкурентоспособной производительностью и их можно использовать для объяснения эмпирического успеха эвристических моделей (к примеру, в большом числе исследований предлагается генеративная интерпретация эвристики IDF). Таким образом, мы задействуем статистический фреймворк для формирования альтернативного подхода к поиску наиболее релевантных запросу документов, используя большой объём данных о пользовательском поведении при просмотре и поиске.
Мы рассматриваем генеративную модель для запросов, термов и документ, в которой каждый запрос q реализует мультиномиальное распределение по своим термам. В свою очередь, каждый терм в словаре ассоциирован с мультиномиальным распределением по документам, рассматриваемым как вероятность того, что пользователь доберётся до документа после подачи запроса с данным термом (или же вероятность того, что пользователь просматривает документ за единицу времени в зависимости от конкретной реализации распределения). Фактически, данная вероятность заключает в себе тематическую релевантность документа конкретному терму. Тогда вероятность выбора документа di при данном новом запросе q^ можно использовать для оценки релевантности документа:
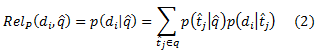
Выбор конкретной параметризации для распределения запрос-терм p(t^j|q^) и распределения по документам для данного терма p(di|t^j) позволяет реализовывать различные поисковые функции. В данной работе мы оцениваем мгновенную мультиномиальную вероятность запроса-терма p(t^j|q^) через отрицательно экспоненциированный терм из корпуса запроса, который похож на взвешивание IDF: более низкочастотные термы обладают большим влиянием на выбор документов:
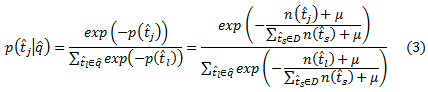
где n(t^j) – это количество запросов с термом t^j, а μ – константа сглаживания (во всех наших экспериментах μ=10; но так же возможны альтернативные методики сглаживания, например, использованные в языковом моделировании [49]).
Вероятности документа для каждого терма запроса можно рассчитать методом максимального правдоподобия по обучающей выборке для всех путей в D, которые начинаются с запросов с термом t^j. Используя сглаживание Лапласа для более точной оценки, вероятности терма-документа рассчитываются как:
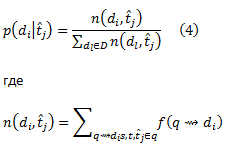
– это агрегация визитов документа di, к которому перешли с запросов, содержащих терм t^j. Как было сказано ранее, можно использовать различные реализации подсчёта (чистый подсчёт визитов, время пребывания, и т.д.) в соответствии с семантикой вероятностного распределения (вероятность достижения документа, вероятность просмотра документа за единицу времени и т.д.).
В целом формулирование вероятностей аналогично вышеописанной эвристической модели, в частности агрегацией наиболее релевантных документов для каждого терма в запросе для последующего взвешивания пропорционально относительной известности терма.
В вероятностной модели, описанной в предыдущем разделе, процесс выбора релевантного запросу документа можно рассматривать как двухшаговое случайное блуждание (random walk) по k-дольному графу при k=3, сформированному запросами, термами запросов и документов. Рисунок 2 наглядно иллюстрирует этот подход. Сплошные линии являются переходами, соответствующими распределениям вероятностей запроса-терма и терма-документа. Тогда вероятность достижения документа, начиная путь от данного запроса будет равна вероятности посещения узла документа при двухшаговом случайном блуждании, начатом в узле запроса и движущимся по узлам термов. Вероятности перехода от узла запроса к узлам термов мгновенно рассчитываются в момент запроса, как описано в уравнении 3.
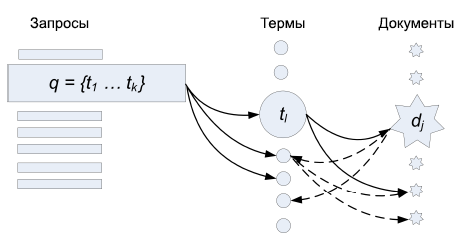
Рисунок 2. Случайное блуждание для поисковых маршрутов
Такой подход подразумевает, что базовая модель, описанная в предыдущем разделе может быть улучшена путём рассмотрения случайного блуждания с более чем двумя шагами. Для эффективности вычислений мы будем рассматривать простое улучшение вероятностной модели случайным блужданием с 4 шагами наряду с двухшаговым вариантом. На Рисунке 2 это отражено пунктирными линиями, которые переходя к узлам термов от узлов документов, а затем опять возвращаются к узлам документов. После достижения документа на втором шаге случайного блуждания в стандартной модели, блуждание либо поглощается с вероятностью α, либо переходит далее ко всем термам, через которые был достигнут документ и движется к прочим документам, достигнутым через данные термы. Тогда релевантность документ в di для данного запроса q^ рассчитывается как вероятность окончания случайного блуждания в узле di:
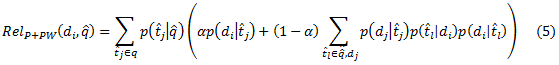
На первый взгляд кажется, что вычисление данной формулы очень затратно, однако факторы в скобках не зависят от запроса и, следовательно, могут быть рассчитаны заранее. Очевидно, что данная модель выше оценивает те документы, которые достигаются по нескольким термам запроса, а так же увеличивает оценку для документов, достигнутых по смежным термам (где мера сходства термов – это сходство распределений их документов; изучение информационно-теоретической подоплёки данного подхода и его расширение является интересным направлением для дальнейших исследований).
Вклад данной работы заключается в том, чтобы продемонстрировать насколько ценны логи пост-поискового поведения при оценке релевантности документа для будущих запросов. Чтобы подтвердить это эмпирически, мы применяем вышеописанные методы по определению релевантных веб-сайтов для двух наборов реальных запросов. В первом наборе релевантные страницы размечены асессорами, а во втором релевантные новым запросам веб-сайты определены на основании поисковых маршрутов за период, взятый за несколько месяцев до обучающей выборки. Наконец, мы демонстрируем, что предложенные методы помогают обучать ранжированию алгоритм с контролируемым обучением, так как они расширяют стандартные атрибуты, извлечённые из содержания документа, ссылочной структуры и взаимодействия с поисковой системой.
Оценка точности поиска является трудной задачей в масштабах интернета. Было предложено несколько способов и метрик оценки в сообществе IR [41, 16]. Мы проводим эксперименты двух типов, чтобы проверить, насколько осуществима идентификация релевантности ресурсов на основе логов пользовательской активности:
При оценке аккуратности ранжирования проводятся эксперименты на уровне веб-сайтов, не касаясь вопроса релевантности отдельных страниц. По-прежнему остаётся открытым вопрос изучения полезности предложенных методов для оценки релевантности конкретной страницы, но оценки на уровне сайта более актуальны в ряде поисковых задач, например, в задаче динамического переранжирования поисковых результатов [25] и статического ранжирования [33]; так же отметим, что популярные поисковые системы объединяют поисковые результаты с одного и того же сайта, когда они во множестве появляются на странице выдачи. Однако мы включаем ранжирование на уровне страниц в оценку обучения ранжированию, описанную в Разделе 5.4, таким образом измеряя полезность наших характеристик релевантности на уровне сайта.
Чтобы сравнить согласованность результатов ранжирования, мы использовали метрику NDCG [16]. NDCG определяется для каждой позиции ранга i в целевом ранжировании как:
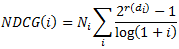
где r(di) – оценка релевантности документа di на позиции i, а Ni – коэффициент нормализации. Если результат di не представлен в целевом ранжировании, то соответствующая r(di) = 0. NDCG набирает популярность в оценке информационного поиска ввиду своей высокой чувствительности к точности топовых результатов. С его помощью можно проводить агрегацию по запросам даже с неодинаковым числом результатов и/или целевых элементов, так как на выходе всё равно будет значение нуля или единицы. Во всех экспериментах, связанных с аккуратностью ранжирования, мы случайным образом разбили тестовый набор запросов и их соответствующих списков результатов на 10 блоков с целью обеспечения тестирования статистической значимостью.
Обучающая выборка включала в себя порядка 140 млн. поисковых маршрутов, охватывающих 12-месячный период с января по декабрь 2006. По методу из Раздела 3 данные извлекались случайным образом из логов нескольких сотен тысяч пользователей тулбаров. Для проверки мы составили два блока запросов. Первый блок HumanRanking содержал 33,150 запросов, случайно выбранных по своей относительной частотности из логов Windows Live Search. По каждому запросу асессоры оценили релевантность нескольких веб-страниц по шкале от 1 до 5 (от Плохо до Идеально). Соответствующим веб-сайтам назначалась максимальная оценка, полученная какой-либо из его страниц.
Второй блок UsageRanking составлялся автоматически путём выбора 10,000 запросов из поисковых маршрутов за май 2007, при этом запросы не входили в обучающую выборку и каждый был введён как минимум в 2 разных поисковых системы. По каждому запросу собирались все сайты, посещённые в ходе маршрута. Затем сайты были отранжированы по общему числу просмотра страниц от разных пользователей всех поисковых маршрутов. Ранг сайта в списке результатов отражал его популярность среди пользователей, вводивших запрос. Следовательно, ранг эмпирически демонстрировал релевантность ресурса. И хотя ранжированные результаты смещены, так как их получали из того же источника, что и обучающую выборку, использование новых запросов и результатов из нескольких поисковых систем адекватно поправляет оценку алгоритма, одобряющего по старым запросам только популярные сайты. Релевантные результаты по каждому запросу в блоках HumanRanking и UsageRanking были отсортированы для составления целевого ранжирования, которое затем сопоставлялось с предсказанием алгоритма и, таким образом, являлось мерой оценки его работы. Актуальные оценки релевантности такие же как r(i) в HumanRanking, но аналогичные показатели UsageRanking, основанные на позиции элемента, идут от большего к меньшему (т.е. в целевом ранжировании 5 элементов первый результат имеет оценку релевантности r(i) = 5, а пятый r(i)=1).
И хотя методы из Раздела 4 можно применять для оценки на уровне страниц, наша выборка маршрутов не может охватить все страницы индекса Веба. Зато она охватывает достаточное количество сайтов, а оценка на уровне сайта является ключевым компонентом во множестве случаев, например, в обучении ранжированию; фильтрации практик, связанных с продвижением сайтов; и в назначении приоритетов сканирования. Как видно из результатов в Разделе 5.4, применение наших методов на уровне сайта повышает аккуратность обучения ранжированию на уровне страниц.
Эксперименты, связанные с аккуратностью ранжирования, оценивают качество прогнозов релевантности, полученных нашим методом отдельно ото всех прочих факторов ранжирования, что позволяет изучить влияние таких факторов как полезность модели термов относительно простого ведения индекса популярности на уровне запросов, важность объёма доступной обучающей выборки и пользу включения в алгоритм пользовательского поведения в поисковом маршруте после выбора результатов.
5.3.1 Полезность модели запроса-терма
Так как все предложенные методы основаны на термовых моделях, мы сперва сравниваем их производительность с базовой методикой, которая не дробит запросы на термы, но вместо этого ассоциирует запросы целиком с веб-сайтами, посещёнными в последующих маршрутах. Эта методика рассматривает каждый запрос как единый терм, для которого проводится агрегация сайтов. Эта стратегия использовалась в более ранней работе Agichtein и др. [2], который рассматривал возможность использования истории поиска и поведения, складывающегося при просмотре страниц, для извлечения особенностей пользования веб-графом по отдельным пользовательским запросам.
| Метод | NDCG@1 | NDCG@3 | NDCG@10 |
| Сверка с запросами | 0.220 | 0.200 | 0.212 |
| Эвристический | 0.311 | 0.279 | 0.278 |
| Вероятностный | 0.313 | 0.288 | 0.288 |
| Вероятностный + RW | 0.317 | 0.292 | 0.293 |
Таблица1. Сравнение сверки с (прошлыми) запросами и методов, основанных на термах.
Таблица 1 отражает сравнение трех различных методологий, предложенных в Разделе 4 с запросной базовой методикой, реализованной посредством вероятностного метода, дополненного случайным блужданием. Поскольку набор данных HumanRanking использует сверку с (прошлыми) запросами он непригоден для новых запросов, которые составляют набор UsageRanking. Подход, базирующийся на сверке, показывает куда более худшую производительность, нежели чем методы, основанные на термах, что объясняется тем фактом, что существенная доля запросов является новыми, и информационный поиск, в основе которого лежат поведенческие факторы, невозможен по ним без разбиения по термам. Эти результаты также демонстрируют нам относительную эффективность трех предложенных алгоритмов, обученных по полному обучающему множеству. Эвристическая модель показывает худшую из всех трех моделей производительность для всех уровней NDCG, в то время как расширенный вероятностный алгоритм, который использует в своей работе случайное блуждание, показывает хоть и небольшие, но достаточно последовательные улучшения по сравнению с базисной вероятностной моделью. Различия между оценками NDCG между лучшим по своей производительности методом (RelP+RW) и прочими подходами статистически значимы на уровне в 0.05.
5.3.1 Полезность полных маршрутов
Предшествующие исследования рассматривали либо начальные точки поисковых маршрутов — логов запросов систем информационного поиска и последовательность кликов по возвращенным результатам ранжирования [17, 2, 4], либо только конечные точки поисковых маршрутов, также известные как пункты назначения (дестинации) [45]. Для того чтобы исследовать полезность использования полных поисковых маршрутов мы сравнили оценки NDCG, полученные на наборе данных HumanRanking с полными маршрутами просмотров интернет-страниц, с теми, что были получены либо при использовании только начальных точек поисковых маршрутов (кликов по результатам ранжирования), либо только конечных (поисковых дестинаций).
| Эвристический алгоритм | Вероятностный алгоритм | Вероятностный алгоритм + RW | |||||||
| NDCG@1 | NDCG@3 | NDCG@10 | NDCG@1 | NDCG@3 | NDCG@10 | NDCG@1 | NDCG@3 | NDCG@10 | |
| Полные маршруты | 0.311 | 0.279 | 0.278 | 0.313 | 0.288 | 0.288 | 0.317 | 0.292 | 0.293 |
| Клики по результатам | 0.297 | 0.267 | 0.268 | 0.295 | 0.273 | 0.276 | 0.296 | 0.274 | 0.277 |
| Дестинации | 0.301 | 0.271 | 0.273 | 0.305 | 0.279 | 0.283 | 0.310 | 0.287 | 0.289 |
Таблица 2. Сравнение полных поисковых маршрутов с начальными и конечными точками
В Таблице 2 приведены результаты обозначенных экспериментов для трех методологий, которые вновь были обучены на всем доступном множестве поисковых маршрутов. Эти результаты показывают нам, что для всех алгоритмов, использование полных навигационных данных, содержащихся в поисковых маршрутах, приводит к улучшению производительности: с учетом всех сайтов, посещенных пользователями, они обеспечивают наши модели большим объемом информации, делая прогнозы по релевантности более аккуратными. Важно также отметить, что более высокие оценки получаются тогда, когда для обучения используются конечные точки поисковых маршрутов, нежели чем начальные; это указывает на то, что поисковые дестинации охватывают ресурсы, релевантные информационным потребностям пользователей с большей аккуратностью, чем начальные клики по результатам органической выдачи, смещающихся в соответствии с рекомендациями систем информационного поиска, которые могут быть субоптимальными.
5.3.3 Сравнение длительности визитов с их прямым подсчетом
Справедливость рассмотрения времени пребывания в качестве индикатора релевантности страницы или пользовательской удовлетворенности в ходе взаимодействия с системой информационного поиска обсуждалась в более ранних работах [21, 12]. Поскольку все методы, описанные нами в Разделе 4, полагаются на функцию f(q~→di), которая может охватить либо время пребывания, либо чистый подсчет визитов, мы сравнили оценки NDCG, полученные с использованием следующих трех вариантов f:
Результаты, приведенные в Таблице 3, демонстрируют, что использование логарифма длительности визита обеспечивает лучшую производительность среди трех вариантов, приведенных выше: несмотря на то, что время просмотра содержит в себе некоторую полезную для нас информацию, сглаживание параметра, посредством взятия логарифма, приводит к большей аккуратности постольку, поскольку снижается влияние выпадающих показателей, при поддержании некоторой дифференциации, обеспечивая золотую середину между чистым временем просмотров и подсчетом визитов.
| Эвристический алгоритм | Вероятностный алгоритм | Вероятностный алгоритм + RW | |||||||
| NDCG@1 | NDCG@3 | NDCG@10 | NDCG@1 | NDCG@3 | NDCG@10 | NDCG@1 | NDCG@3 | NDCG@10 | |
| log(Время просмотра) | 0.311 | 0.279 | 0.278 | 0.313 | 0.288 | 0.288 | 0.317 | 0.292 | 0.293 |
| Время просмотра | 0.297 | 0.267 | 0.262 | 0.292 | 0.271 | 0.271 | 0.302 | 0.278 | 0.281 |
| Подсчет | 0.297 | 0.267 | 0.266 | 0.287 | 0.268 | 0.273 | 0.296 | 0.275 | 0.277 |
Таблица 3. Сравнение длительности визитов с их прямым подсчетом
Для того чтобы оценит влияние объема обучающих данных на предсказание релевантности, мы оценили производительность предложенных методологий с использованием различного количества данных для обучения. Кривые обучения, представленные на Рисунке 3, иллюстрируют, что доступ к большим наборам данным пользовательского поведения имеет важное значение для достижения хорошей производительности. И хотя ожидается, что данное распределение частотностей запросов подчиняется степенному закону и, следовательно, оно очень разрежено, эти эксперименты демонстрируют, что наборы данных, состоящие как минимум из 100 млн. маршрутов более предпочтительны для максимизации аккуратности в предсказании ранжирования, основанного на логах пользовательского поведения. Результаты по набору данных UsageRanking демонстрируют обобщающую способность предложенных методологий: хотя ни один из запросов в этом наборе данных не был обнаружен на протяжении обучающего процесса, модель, основанная на термах, достаточно эффективна в деле идентификации наиболее просматриваемых веб-сайтов по отдельным термам, которые далее комбинируются в модели запроса-терма. В целом, эти результаты показывают, что наилучшая производительность по всем объемам обучающих данных достигается с использованием алгоритма вероятностного предсказания, дополненного случайным блужданием, оправдывая, тем самым, дополнительные вычислительные затраты, которые требует указанная методология.
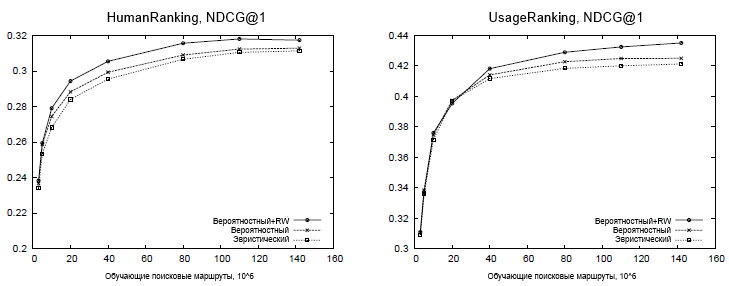
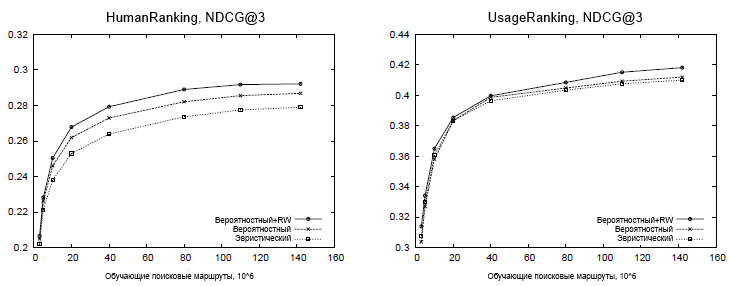
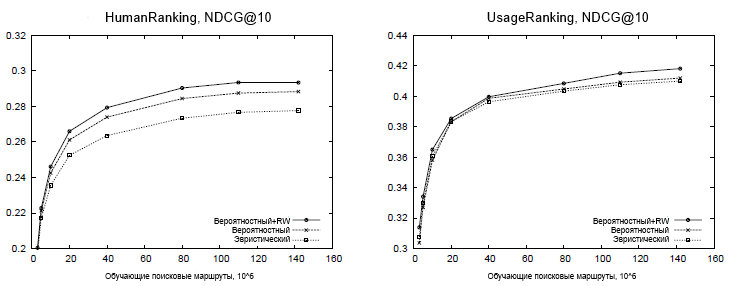
Рисунок 3. Аккуратность ранжирования для разного объема обучающих данных
Несмотря на то, что экспериментальные результаты, представленные в предыдущем Разделе, демонстрируют, что предложенные модели способны, используя крупные наборы данных о поведении пользователей на поиске и при просмотре интернет-страниц, идентифицировать релевантные веб-сайты по запросам, они не касаются проблематики практической полезности методологий в контексте улучшения качества поиска. Современные поисковые системы, как правило, полагаются на алгоритмы ранжирования, в основе которых лежит машинное обучение, что позволяет включать сотни и тысячи особенностей, использующих всевозможные источники доказательства релевантности [7, 4]. Эти особенности могут охватывать такие сигналы, как сходство между пользовательским запросом и контентом интернет-страницы, гиперссылочную структуру и такие ее особенности, как текст ссылочного анкора; общее качество страницы, а также особенности, следующие из пользовательских взаимодействий с системой информационного поиска. Следовательно, для проверки пригодности предложенных алгоритмов по части улучшения качества поиска, мы провели эксперименты, в которых для обучения функции ранжирования был использован RankNet — контролируемый алгоритм машинного обучения. RankNet использует двухслойный нейросетевой алгоритм, обученный с использованием попарных предпочтений о релевантности с целью оптимизации метрики NDCG [7]. Эксперименты проводились с использованием набора данных HumanRanking, описанных выше, которые содержали 30150 запросов, случайным образом извлеченных из логов пользовательских запросов и сопровожденных наборами интернет-страниц, имеющих асессорскую оценку по пятибалльной шкале релевантности (от Плохо до Идеально). Набор данных был разбит на обучающее, валидационное и тестовое подмножество в пропорции 10:1:1, с учетом тестового набора, состоящего из 2762 запросов. Экспериментальный базис использовал большое количество особенностей, которые включали как контентные и гиперссылочные характеристики, так и те, что учитывали взаимодействие с результатами органической выдачи (кликабельность). Мы оценили полезность наших методологий посредством пополнения базисных особенностей с оценками релевантности, полученных нашими алгоритмами через Уравнения (1), (2) и (5), а также их бинарных и логарифмических преобразований.
| Набор особенностей | NDCG@1 | NDCG@3 | NDCG@10 |
| Базис | 0.622 | 0.635 | 0.691 |
| Базис + RelH | 0.625 | 0.638 | 0.695 |
| Базис + RelP | 0.628 | 0.641 | 0.696 |
| Базис + RelP+RW | 0.631 | 0.643 | 0.696 |
Таблица 4. Обучение ранжированию с использованием маршрутных особенностей
Таблица 4 демонстрирует результаты, которые были получены в ходе указанных экспериментов; здесь полужирный шрифт указывает на то, что имеющие место быть улучшения по сравнению с базисом являются статистически значимыми в соответствии с двухсторонним t-тестом (p < 0.05). Результаты демонстрируют, что предсказания, даваемые нашими методологиями, приводят к улучшению NDCG при обучении ранжированию. Выгода наиболее выражена в NDCG@1 и NDCG@3, где улучшенная вероятностная модель приводит к улучшению NDCG практически в 1%. Более скромные улучшения в NDCG@10 объясняются тем фактом, что наши алгоритмы наиболее аккуратны в идентификации небольшого числа топовых авторитетных веб-сайтов, которым, как правило, соответствуют только несколько топовых результатов, в то время как ранжируемые на более низких позициях интернет-ресурсы представляются менее полезными при упорядочивании результатов органической выдачи. Отметим, что улучшение наблюдалось над всем базисом, который уже включает характеристики кликабельности, демонстрируя нам полезность майнинга пользовательских просмотров из полных поисковых маршрутов по сравнению с использованием только логов пользовательских кликов по возвращенным результатам поиска.
Цель нашей работы заключалась в получении такого экспериментального доказательства, который бы наглядно демонстрировал нам однозначные преимущества, предоставляемые комбинацией полных маршрутов и информации о пользовательских просмотрах интернет-страниц, и методы, которые мы здесь предложили, могут быть расширены и улучшены по нескольким направлениям. Альтернативные производные функций релевантности, основанных на обучающих наборах поисковых маршрутов, могут быть созданы как эвристически, так и с использованием различных вероятностных формулировок. В частности, использование технологий языкового моделирования для определения дополнительных распределений запроса-терма, которые учитывают как содержимое документа, так и логи пользовательских запросов [49, 39, 42] является перспективным направлением для будущих исследований, аналогично экспериментированию с различными формулировками случайного блуждания, использующего схемы перехода отличные от тех, что были описаны в подразделе 4.3. Относительно применения, существует ряд задач, которые могут использовать на поиске запросо-зависимую авторитетность интернет-документов, превосходящую оценку релевантности. Например, было продемонстрировано, что подтвержденная пользователем авторитетность может быть полезна для идентификации поискового спама [13]. Поскольку маловероятно, что пользователи часто посещают неинформативные ресурсы, и покидают их практически сразу после захода, использование логов пользовательской активности может снабдить алгоритмы, занимающиеся вычислением поискового спама, крайне ценной информацией. Наконец, в отличие от моделей «случайного серфера» или «ориентированного серфера», прежде использовавших алгоритмы из семейства PageRank [26, 14, 32], поведение реальных пользователей, складывающееся при просмотре интернет-страниц, обеспечивает эмпирическое распределение блужданий по всему веб-графу. Выведение теоретико-графовых алгоритмов ранжирования, которые используют схемы обхода, обученные на поведении реальных пользователей, складывающегося на поиске и просмотре интернет-страниц, также является интересной темой будущей работы, и может улучшить алгоритмы статического ранжирования и таких приложений, как приоритетное сканирование.
Мы предложили и оценили эвристические и вероятностные алгоритмы для идентификации релевантных веб-сайтов с использованием комбинированных исторических данных о поведении множества пользователей, складывающегося на поиске и при просмотрах интернет-страниц. Алгоритмы, которые используют неявную обратную связь, следующую из активности пользователей при просмотрах страниц сайтов по окончанию поиска, позволяют нам оценить тематическую релевантность веб-сайтов. Используя экспериментальную оценку мы показали, что (1) алгоритмы обучения ранжированию по пользовательским взаимодействиям, следующим из навигационных маршрутов после кликов по результатам поисковой выдачи, позволяют повысить аккуратность поиска, превосходящую обучение с использованием только данных кликабельности или поисковых дестинаций, и (2) использование особенностей поведения в маршруте в качестве фактора ранжирования в алгоритмах улучшает качество поиска. Кроме того, мы так же продемонстрировали важность обобщаемого обучения по сверке термов запросов, полезность логарифмического преобразования времени просмотра веб-сайта над чистыми временем просмотра и подсчетом посещений, а также значимость увеличения объемов обучающего набора. Наше исследование несет в себе серьезные последствия для разработки алгоритмов ранжирования и улучшения взаимодействия с пользователями поиска, и мы надеемся, что это станет стимулом для последующей работы, использующей крупные наборы данных поведения пользователей, складывающегося на поиске и при просмотре интернет-страниц.
Перевод материала «Mining the Search Trails of Surfing Crowds: Identifying Relevant Websites From User Activity» выполнили Константин Скоморохов и Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации