SEO-Константа
Яндекс.Директ + оптимизация
В первой части текущего материала мы постараемся оценить работу алгоритма доверия на реальном интернет-графе, а также показать вам то, что для учета качественной стороны веб-сайтов нам не следует столь уж сильно опираться на данные Google PageRank, который, надо сказать, не является эффективным инструментом для решения задач выявления спама. Поэтому вторая часть будет посвящена еще двум модификациям известного алгоритма — HostRank и DirRank.
Для того чтобы оценить эффективность работы алгоритма TrustRank мы выполнили серию практических экспериментов на документах из индексной коллекции AltaVista по состоянию на август 2003 года. С целью снижения вычислительных затрат мы упростили задачу исследования спама в содержимом интернет-ресурсов за счет группировки всех известных нам страниц со схожими хостами по веб-сайтам (всего получилось 31,003,964 сайтов). Думаем, что вы все прекрасно знаете, что полным именем хоста (Host Name) называется часть URL- адреса после префикса http://, в котором последовательно перечисляются слево направо все без исключения промежуточные хосты между листом и корнем доменного имени следующим образом: web.net.wseob.ru. После выбора в качестве объекта своего исследования не HTML-страниц, а веб-сайтов, мы также упростили оригинальный интернет-граф за счет учета только одной ссылки с сайта А на веб-сайт В, тогда как количество взаимосвязи между ними может значительно варьироваться. Стоит отметить, что более 1/3 анализируемых веб-сайтов (13,197,046) представляли собой корневые узлы, то есть в их содержимом не было обнаружено входящих ссылок с посторонних ресурсов, в то время, как алгоритмы распространения доверия основываются на информации входящего ребра. К счастью, содержащимся в индексе корневым ресурсам присваивается минимальное значение PageRank, поэтому задача классификации внутри данной группы сайтов не является для нас столь необходимой для улучшения качества поисковой выдачи.
Мы решили провести сравнительный анализ стратегий формирования набора предпочтительных сайтов на основании инверсивного и наибольшего PageRank, о которых мы подробно рассказывали вам в предыдущей части нашего материала, по результатом которых выяснилось, что применение инверсивного (обратного) PR является для нашей задачей куда более эффективной стратегией. В [1] мы подробно описываем проведенные эксперименты на таком искусственном веб-графе, который в наиболее полной мере отражал бы квинтэссенцию интернет-спама, но в рамках текущей работы на реальном графе мы не будем вдаваться в эти детали, и будем только пользоваться сделанными в ней выводами. После построения ранга сайтов на основании значений обратного PageRank, мы получили список из 25,000 веб-сайтов, который еще до вызова функции прогнозирования было решено подвергнуть существенной корректировке с целью ликвидации некачественных сайтов. Для упрощения процесса зачистки, а также некоторой перестраховки мы оставили в нем только те ресурсы, которые числились в каталоге DMOZ, в результате чего мы уменьшили первоначальную выборку до 7,900 (31,6%) веб-сайтов. Из них, мы вручную оценили 1,250 сайтов (выборка S) и назначили 178 ресурсам статус хорошего сайта. Относительно небольшой объем хорошей выборки S+ связан с очень строгим критерием отбора, как, например, учитывались не только сетевые характеристики тех или иных сайтов, но и их реальная авторитетность, то есть принадлежность к государственным и общественным организациям, крупным компаниям и т.д. Кроме всего прочего, такой дополнительный фильтр позволил нам уменьшить вероятность деградации нашей хорошей выборки в краткосрочной перспективе.
Для использования метрик попарного ранжирования, точности и полноты нам потребуется дополнительный χ набор эталонных сайтов с известными значениями доверия. Мы пришли к выводу, что наиболее оптимальной, как с точки зрения существующего ограничения на вызов функции прогнозирования доверия, так и получения достаточно объективной и достоверной информации, была бы выборка, состоящая из 1,000 сайтов. Было также решено не формировать данную выборку из случайных сайтов по той простой причине, что в этом случае возникает значительная вероятность получения существенного количества интернет-ресурсов с незначительным объемом страниц и/или низким показателем PageRank, а следуя степенному распределению, частота выхода блуждающего по графу пользователя на подобного рода сайты достаточно низка. В то самое время как основная задача по выявлению спама заключается именно в среде тех веб-сайтов, которые имеют высокое значение PR и, соответственно, будут находиться на более топовых позициях в поисковой выдаче, не говоря уж о том, что во втором случае, мы располагаем куда большей доказательной информацией при использовании нашей функции прогнозирования.
Надо сказать, что в целях обеспечения разнообразия представленных в выборке сайтов, мы предварительно отранжировали все веб-сайты в порядке их убывающего значения PageRank, а также разделили их общее множество на 20 блоков. При этом, несмотря на то, что всякий блок содержал в себе различное количество сайтов, суммарное значение показателя авторитетности всех сайтов в каждом блоке составляло 5% от показателя PageRank сайтов всего множества. Таким образом, в первом блоке было сосредоточено 86 интернет-ресурсов с наибольшим значением показателя PR, во втором было уже 665 сайтов, тогда как в двадцатом блоке находилось порядка 5 млн. веб-сайтов с минимальным значением PR. Только после завершения данных манипуляций, мы осуществили отбор ресурсов, изымая из каждого блока случайным образом по 50 штук сайтов, а затем вызвали функцию прогнозирования доверия. На Рис. 8 представлена круговая диаграмма, демонстрирующая нам результаты оценки веб-сайтов на наличие в их содержимом поискового спама:
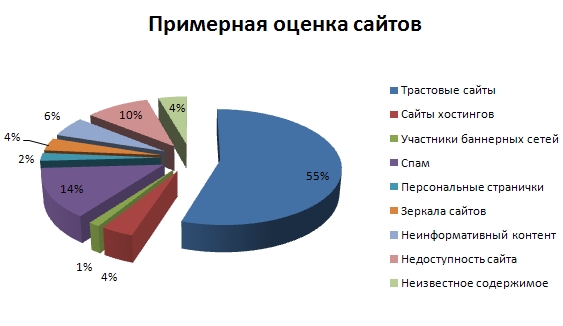
Поскольку 252 ресурса были нами забракованы, только 748 сайтов из 1,000 смогли участвовать в последующем формировании необходимой для нас выборки Х. Среди причин брака значились:
Ранее мы уже описали вам ряд методологий, касающихся пропагации доверия из исходного набора качественных страниц. Сейчас мы сфокусируемся на трех альтернативных методологиях: TrustRank и двух базовых подходах, а затем оценим их производительность, используя нашу выборку χ:
Для начала давайте рассмотрим разницу между алгоритмом авторитетности Google PageRank и предложенным нами TrustRank. Вспомним, что методология PageRank не включает в себя каких-либо предварительных знаний, касающихся качества интернет-ресурсов, как и наложения явных штрафных санкций в случае применения ими манипулятивных схем. В действительности, мы увидим, что ситуация при которой некоторый сайт, созданный профессиональным спамером, получает высокую голосующую способность является достаточно распространенной. В противовес этому, наш алгоритм доверия TrustRank призван различать качественные и некачественные ресурсы: мы ожидаем, что спам-сайты не получат существенно высокого TrustRank.
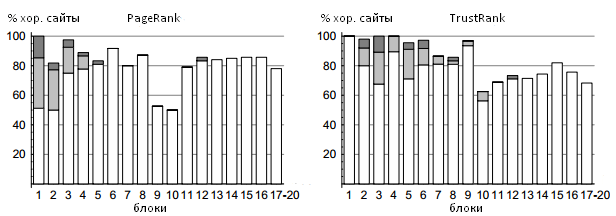
Рисунок 9. Качественные ресурсы в PageRank- и TrustRank-блоках
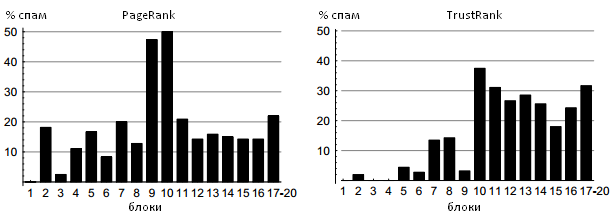
Рисунок 10. Некачественные ресурсы в PageRank- и TrustRank-блоках
Рисунки 9 и 10 демонстрируют наглядное сравнение Google PageRank и TrustRank относительно соотношения хороших и плохих сайтов во всяком блоке. PageRank-блоки были уже введены в настоящую работу чуть выше; сейчас мы определяем TrustRank-блоки как содержащие аналогичное число интернет-сайтов. Заметим, что мы объединяем 17-20 блоки для обоих алгоритмов. Последняя четверка блоков содержала более 13 млн. веб-ресурсов, не связанных гиперссылочной структурой. Эти сайты получили некоторое номинальное статистическое значение голосующей способности, которое дается всем интернет-страницам по праву их появления в Сети, при оценке доверия равной нулю, что не дает нам возможности произвести соответствующее ранжирование. На оси абсцисс Рисунков 9 и 10 отмечены PageRank — и TrustRank-блоки соответственно. Оси ординат первого рисунка соответствует трастовая доля во всяком заданном блоке, то есть количество хороших ресурсов, разделенного на общее число образцов в блоке. Обратите внимание на то, что реклама и сайты интернет-организаций помечены как качественные ресурсы; их относительный вклад отмечен белым, серым и темно-серым цветом соответственно. Оси ординат второго рисунка соответствует спам-доля во всяком заданном блоке. Например, из Рисунка 10 следует, что 31% веб-сайтов в одиннадцатом TrustRank-блоке являются некачественными объектами. Исходя из этих рисунков видно, что алгоритм TrustRank является разумным инструментом в задачах вычисления поискового спама. В частности, обратите внимание на то, что в первых пяти TrustRank- блоках практически нет некачественных сайтов, при существенном увеличении концентрации спама в последующих. При всем этом не может не вызывать удивления тот факт, что второй PageRank-блок более чем на 20% состоит из спама. Для алгоритма Google PageRank доля некачественных сайтов достигает своего пикового значения в 9 и 10 блоке (50% спама), указывая на то, насколько же сильным может быть манипулятивное воздействие на данную методологию.
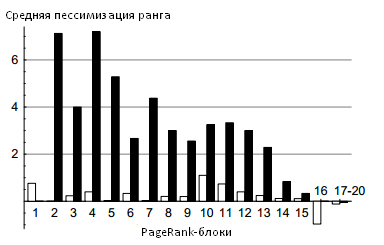
Рисунок 11. Пессимизация/увеличение рангов интернет-сайтов в PageRank-блоках алгоритмом TrustRank
Рисунок 11 предлагает нам иной взгляд на взаимоотношения между алгоритмами Google PageRank и TrustRank. Здесь вноситься понятие пессимизации ранга (demotion) — явление при котором некоторый интернет-ресурс, размещенный в блоках с высокой голосующей способностью, перемещается в блок, имеющий низкую доверительную оценку. Отрицательная пессимизация (увеличение ранга) рассматривает тот случай, при котором движение осуществляется из блока с низкой голосующей способностью в блок с высокой доверительной оценкой. Средняя пессимизация рангов некачественных интернет-сайтов является важным элементом нашей методологии, оценивающей производительность алгоритма TrustRank, так как она показывает нам успех (или его отсутствие) в вопросах урезания авторитетности поискового спама. На оси абсцисс Рисунка 11 отмечены PageRank-блоки. Ось ординат демонстрирует нам среднюю пессимизацию/увеличение рангов между PageRank- и TrustRank-блоками. Белые бары представляют собой трастовые сайты, в то время как черные бары обозначают спам-ресурсы (Отметим, что данный Рисунок не отображает ресурсы, связанные с рекламой и интернет-организациями). В качестве иллюстрации можно указать, что во втором PageRank-блоке рисунка 11 практически не оказалось ресурсов, ранг которых был увеличен. Наглядным примером отрицательной пессимизации может послужить шестнадцатый PageRank-блок. Этот рисунок демонстрирует нам, что алгоритм доверия TrustRank эффективно очищает подавляющее большинство некачественных ресурсов среди тех сайтов, что изначально имели высокие качественные оценки. Кроме того, он также показывает нам, что в большинстве случаев качественные сайты сохраняют свое первоначальное положение. Следовательно, мы утверждаем, что наш алгоритм доверия (в отличие от Google PageRank) гарантирует, что наиболее оцененные им сайты также являются качественными веб-ресурсами. Однако мы также заявляем, что TrustRank не в состоянии эффективно различать низкооцененные хорошие сайты от некачественных ресурсов по причине отсутствия на них отличительных признаков, а именно внешних входящих гиперссылок.
Здесь мы использовали метрику попарного ранжирования, представленную вам прежде, с целью оценки качества предложенной нами методологии ранжирования. Для проведения этого эксперимента, мы создали набор P всех возможных пар сайтов для нескольких подмножеств нашей оценочной выборки χ. Для начала мы использовали подмножество χ, состоящее из 100 сайтов с наибольшей голосующей способностью с целью оценки TrustRank на наиболее авторитетных интернет-ресурсах. Затем, мы постепенно добавляли все большее число сайтов в наше подмножество в порядке их убывающей голосующей способности. Наконец, мы использовали пары всех 748 образцов для расчета оценок попарного ранжирования.
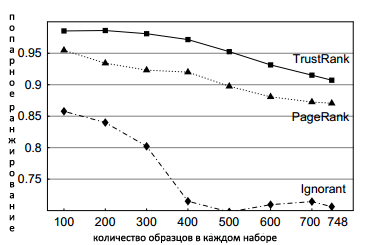
Рисунок 12. Попарное ранжирование
Рисунок 12 отображает результаты проведенного эксперимента. На оси абсцисс отмечено число образцов, использованных для оценок; ось ординат отражает оценки попарного ранжирования для каждого набора. Например, глядя на рисунок можно заключить, что для выборки, которую составляют 500 наиболее высокооцененных по методологии PageRank интернет-сайтов, оценка попарного ранжирования для TrustRank составляет 0.95. Рисунок также показывает оценки попарного ранжирования в случае использования методологии классического Google PageRank и Ignorant Trust-функции. Пять качественных ресурсов из нашего исходного набора S пересекаются с выборкой χ, таким образом все сайты, за исключением 5 эталонных ресурсов, получают оценку Ignorant Trust-функции равную 1/2. Следовательно, оценки попарного ранжирования в случае использования Ignorant Trust-функции отражают тот вариант, при котором у нас нет какой-либо существенной информации, касающейся качественной составляющей сайтов. Аналогично, оценки попарного ранжирования для Google PageRank указывают нам на то, насколько важным оказывается момент располагания информацией об авторитетности того или иного ресурса, помогающей различать хорошие сайты от некачественных. Как вы можете видеть, в ходе всех экспериментов алгоритм доверия превосходит как Ignorant Trust-функцию, так и классический Google PageRank.
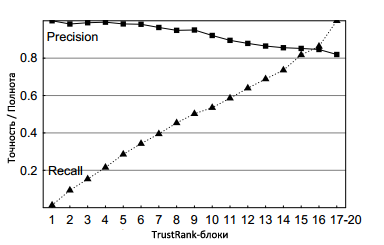
Рисунок 13.Точность и полнота
Результаты наших последних экспериментов приведены на Рисунке 13, отражающего производительность алгоритма TrustRank относительно метрик точности и полноты. В качестве предельно-допустимого порогового значения δ мы использовали пограничные доверительные оценки, которые сепарировали ресурсы по 17 TrustRank-блокам. Блоки, соответствующие каждому предельно допустимому пороговому значению, представлены на оси абсцисс; на оси ординат показаны показатели точности и полноты. Например, если все эталонные ресурсы первого TrustRank-блока превосходят предельно-допустимое пороговое значение δ = 10, тогда точность составляет 0.86, а полнота 0.55. Алгоритм TrustRank присваивает наиболее высокие оценки качественных сайтам, в то самое время, как доля некачественных ресурсов постепенно увеличивается по мере продвижения к тем блокам, что расположены в правой части нашего с вами рисунка. Следовательно, увеличение и уменьшение точности и полноты оказывается практически линейным. Обратите внимание на самый высокий показатель точности (0.82) для всего нашего набора: достижение такого значения было бы кране необычно в случае решения традиционных задач, связанных с информационным поиском, при которых мы, как правило, располагаем большим корпусом документов, среди которых только некоторое число из них релевантно какому-либо определенному запросу. Однако наша выборка состоит по большей части из качественных и, самое главное, релевантных документов. Именно поэтому базовый показатель точности для выборки S составляет 613/(613+135) = 0.82.
Уже знакомый нам алгоритм PageRank до сих пор остается отличной парадигмой для сортировки результатов в поисковой выдаче и так или иначе его модель применяют все без исключения поисковые системы, в том числе и Яндекс, алгоритмы которого зачастую могут опираться на значения предоставляемые Google PR. Иными словами, продвижение сайтов в поиске Яндекса также должно учитывать сей показатель. Однако, как мы с вами прекрасно понимаем, что непрекращающееся развитие интернета ведет к необходимости совершенствования тех математических методов программирования, с помощью которых будет осуществляться ранжирование сайтов и во второй части текущего материала мы начнем свое знакомство с двумя его модификациями (HostRank и DirRank), которые были разработаны в исследовательских лабораториях компании IBM и, как и рассмотренный выше алгоритм доверия TrustRank [2], являются инструментами для улучшения качества поиска, в том числе борьбы со спамом. Кроме всего прочего, в этом материале мы проанализируем возможность покрытия индексирующими механизмами эволюционирующего графа, а также влияние данного процесса на органический поиск, исследуем пути улучшения ранжирования в условиях все возрастающей массы мертвых (битых) ссылок и т.д. Напомним, что в основу присваемого документу веса Google PageRank легло стационарное, то есть не зависящее от времени, распределение цепи Маркова для случайного блуждания (серфинга) пользователя на интернет-графах. Логично предположить, что глобальный перерасчет сего показателя на все возрастающем вебе потребовал бы от нас огромных вычислительных затрат, однако в процессе работы нам удалось разработать ряд эффективных методик, касающихся разрешения проблемы висячих узлов и противодействия схемам манипуляции органического поиска.
Действительно, сам алгоритм Google PageRank достаточно прост. Дается ориентированный интернет-граф ζ = (υ, ξ), в котором голосующая способность xi всякой страницы i ∈ υ рекрусивно определяется голосующей способностью ссылающихся на нее документов:
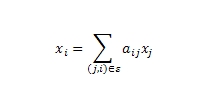
где aij — вероятность перехода пользователя со страницы i на страницу j. В матричном выражении аналогичная формула принимает вид: x = Аx, где х — является вектором рангов страниц; матрица А является стохастической матрицей (то есть, переходных вероятностей для цепи Маркова), поскольку ее элементами являются неотрицательные числа, а сумма элементов в каждом ее столбце равна единице. Отсюда, задача нахождения рангов страниц сводится к нахождению собственного вектора матрицы А для собственного значения λ =1. Если мы уверены в неразложимости матрицы А, то для нахождения ее собственного вектора мы можем применить степенной метод хк = Ахк-1. В идеале предполагается, что наш граф сильно связан и любая страница может быть достигнута посредством ссылочного прохождения через все последующие веб-документы, однако на практике наша матрица переходов между web-страничками может разложиться по причине висячих узлов, то есть ресурсов без исходящих ссылок. Если матрица будет разложимой, тогда она уже не будет Марковской, поскольку в ней будет содержаться нулевой столбец, а вышеупомянутый степенной метод не сойдется. Мы, конечно, можем отказаться от висячих узлов, но для гарантированной сходимости степенного метода и отсутствия нулевых элементов, мы должны рассчитать вероятностный переход на любую другую страницу из висячего документа (добавляется виртуальная ссылка и/или вводится операция телепортации, то есть прямой набор URL-адреса сайта в строке браузера). Чтобы наша матрица не была сильно разряженной, мы вводим в анализ следующую формулу:
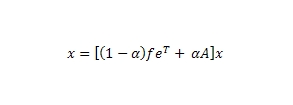
где α — вероятность прохождения по ссылке, (1- α) — вероятность использования телепортации, а f представляет собой стохастический вектор (то есть feT = 1). Эквивалентно можно описать дополнительный (виртуальный) узел n + 1:
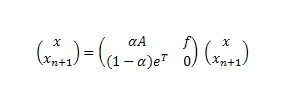
Надо заметить, что поскольку степенной метод сходится при любом векторе со скоростью λ2 = α, то на практике, как правило, показателю α устанавливается значение в 0.85. Предполагается, что оно является оптимальным для достижения быстрой конвергенции (сближения) и влечет за собой минимальные возмущения в поисковой выдаче. Кроме этого, мы не можем предугадать равномерность выбора вектора телепортации между всеми документами сети (то есть, f = e/n) с заданного висячего узла, поскольку пользователь может переместиться на какой-либо авторитетный ресурс; будет ли его выбор равномерно распределяться между страницами верхнего уровня или он перейдет на какие-то выборочные страницы, например, своего аккаунта в социальной сети и т.д.
В прошлом обработке висячих узлов уделялось достаточно мало внимания, хотя существует ряд модификаций алгоритма PageRank не столь чувствительного к данному влиянию, как, например,
[4]. Такое поверхностное отношение к упомянутой проблеме, на наш взгляд, во многом было обусловлено эпохой статичного веба, но мы также считаем, что на сегодняшний день фактор висячих страниц имеет более впечатляющее воздействие на органическую выдачу. В частности, мы уже имеем такую ситуацию, при которой сканирование проходит в условиях более высокого содержания висячих документов, нежели чем страниц с исходящими ссылками. Более того, различные классы висячих узлов могут сообщить разработчикам поисковых систем достаточно полезную информацию, которая позволила бы усовершенствовать качество ранжирования сайтов. Давайте теперь договоримся о том, что для обозначения всех видов окружающих нас висячих документов мы будем использовать понятие пограничного веба и будем использовать этот термин применительно ко всем страницам по тем или иным причинам выпадающим из нашей системы ранжирования.
Первые два вида висячих страниц могут иметь исходящие ссылки, однако в подавляющем большинстве случаев они не участвуют построении ранга. Начнем с того, что в эпоху создания классического алгоритма Google PageRank, когда большая часть индексируемых сайтов представляла собой множество статичных ресурсов, размещаемых на веб-серверах, слова о том, что поисковые системы должны стремиться к индексному покрытию практически всего интернета, прозвучали бы достаточно корректно. Однако в последние годы веб-ресурсы стали генерировать динамические страницы, используя для их создания базы данных. В [5] было подсчитано, что сейчас глобальный объем динамических страниц в интернете в 100 раз больше, нежели чем статичных, но, по нашему мнению, ситуация представляется куда более критической. Речь идет практически о бесконечном множестве URL-адресов, которое ограничивается только пространством имен (минимум 622000). Например, по причине того, что популярный портал amazon.com использует динамически создаваемые страницы с реализованными в их адресах идентификаторами сессий (&session_id=), индексирующий механизм поисковой системы воспринимает каждую такую страницу-дубликат как уникальную, а это влечет за собою накопление в его базе огромного массива копий, не говоря уже о создаваемой нагрузке на сервер. Кстати говоря, именно вследствие необходимости избавляться от дублирующего содержимого компаний Google было запущено несколько специальных алгоритмов, в том числе небезызвестный Panda 2.x от 2012 года, одной из основных функций которого и была борьба с копиями веб-информации. Работа этого алгоритма привела к массовой пессимизации огромного количества сайтов, использующих подобные параметры в URL. Однако когда мы рассуждаем о сканировании и ранжировании индексируемого веба, мы, прежде всего, должны научиться вычленять из него ту информацию, которая представляется для нас полезной. Так как сегодня слишком большое число сайтов применяют подобный вид генерации контента с использованием всевозможных технологий, то мы не имеем никакого права ставить в зависимость ранжирование качественного контента от наличия в его URL-адресе переменных.
Еще одной причиной создания висячих страниц является их запрет на сканирование посредством использования соответствующей директивы файла robots.txt. Мы все должны понимать, что несмотря на наложенные веб-мастером ограничения, подобные документы могут также содержать в себе полезную для пользователей поисковых машин информацию. Важно отметить, что вопреки запрету на сканирование документа, содержимое файла может быть распознано и участвовать в удовлетворении поисковых запросов наравне с прочими страницами на основании учета анкоров входящих ссылок. Понимание необходимости оценки относительного веса висячих страниц также следует из наших практических экспериментов по вычислению значения PageRank, по результатам которых несколько висячих документов, защищенных в robots.txt, оказались в ТОП 100 и прекрасно отвечали на вопрос пользователей. Как бы это не прозвучало странным, но быть может настала пора вычислять веса в том числе и отсутствующим в индексе по тем или иным юридическим и/или политическим мотивам веб-документам? Сканирование документа также может быть невозможным по причине требования сайтом аутенфикации, поскольку поисковые машины не занимаются индексацией глубинного веба; тех ошибок в коде статуса HTTP, которые могут быть на стороне сервера (5хх); ошибок в DNS; проблем с маршрутизацией, а также посредством реализации в исходном HTML-коде страницы соответствующего мета-тега, запрещающего краулеру следовать по его ссылкам (rel=»nofollow»). Если же говорить о тех видах висячих документов, которые действительно не имеют исходящих ссылок, но вместе с тем могут представлять для пользователей поиска достаточно высокий интерес, то к ним, прежде всего, относится подавляющее большинство PostScript и PDF-файлов, которые, как правило, несут в себе достаточно ценную для нас информацию.
Наши недавние эксперименты показали, что число известных нам страниц (4,475 млрд) значительно превышало количество отсканированных в ходе последнего обхода нашим роботом веб-документов (≈1 млрд.). Иными словами, на практике доля висячих страниц (75%), всегда будет более значительной, нежели чем тех документов, которые имеют исходящие ссылки на сторонние интернет-сайты. Из этого также следует, что, не учитывая в своей деятельности висячий фактор и не присваивая таким документам соответствующего ранга, поисковая машина, тем самым, пренебрегает их существенным влиянием на построение органической выдачи.
После того, как мы разобрались с понятием и видами висячих страниц, настало время перейти к методам их обработки. В оригинальной работе Sergey Brin и Lawrence Page, посвященной алгоритму PageRank предлагалось попусту удалять из графа те ссылки, которые ведут на висячие узлы, и только потом рассчитывать веса между оставшимися у нас web-страницами. После этого было высказано предположение, что они также могут учитываться в пересчете без какого-либо существенного влияния на построение выдачи и/или возвращаться на наш граф по истечению нескольких последних итераций. Обратите внимание, что, во-первых, полное исключение ссылок на висячие документы привело бы к некоторому искажению результатов органического поиска, а во-вторых, процесс их удаления может воспроизводить новые висячие страницы, и мы будем вынуждены многократно повторять данную процедуру до тех пор, пока у нас не останутся только связанные страницы. Так как целью нашего исследования все-таки является вычисление ранга висячих страниц, то в своих подсчетах мы решили пропустить вышеупомянутую итерацию и использовать один из альтернативных методов их обработки, суть которого сводится к телепортации из любого висячего узла на случайно выбранную страницу с вероятностью 1.
Предположим, что множество узлов V графа (n = |V|) можно разбить на два подмножества:
Помимо этого, отметим виртуальный (n+1)-й узел, с которого/на который мы можем осуществить свою телепортацию. Новое множество узлов обозначим, как V’ = V ∪ {n + 1}. Добавим новые ребра (i, n + 1) для i ∈ D и (n + 1, j) для j ∈ C. Обозначим расширенное множество ребер E’. Теперь PageRank узлов во множестве V’ может быть вычислен через нахождение собственного вектора матрицы всех его ссылок:
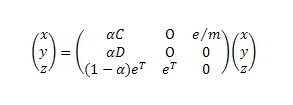
Где, если dj является полустепенью исхода узла j

и x, y, z являются размерностью C, D и 1, а e является вектором размерности 1. Продолжим:
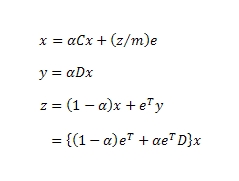
Имеем редуцированную матрицу переходов:
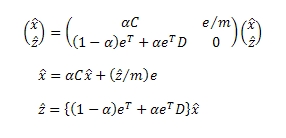
Используя метод степенных итераций:
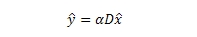
Видим, что x̂, ŷ, ẑ являются решением нашего уравнения, а также тождественны x, y, z. Имея x = x̂, мы можем выполнить одношговый подсчет веса узлов в D.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации