SEO-Константа
Яндекс.Директ + оптимизация
Задача обработки значительных объемов URL (прежде всего, это касается интернет-провайдеров и тех хостов, которые имеют миллионы, а может быть и триллионы возможных адресов) для представленного ранее алгоритма HostRank оказывается крайне трудоемкой. Тем не менее, в [1] предлагается сгруппировать единообразные локаторы ресурсов в т.н. «составные документы», которые отражают иерархическую структуру URL-адресов, и на основании полученных информационных блоков построить граф DirRank. Тогда узлам нашего графа будут соответствовать префиксы URL вплоть до последнего слэша (или иного разделителя), а ориентированным ребрам – наличие ссылки между URL-ми виртуальной директории источника и директории цели. Так называемые динамические URL-ы, содержащие параметр «?», будут выпадать из организации информации по иерархическому принципу, однако они связаны между собой единой базой данных, а потому нам следует расширять наши группы за счет включения такого рода адресов в общую модель. В конечном счете, мы получаем более детализированную картину, нежели чем при обращении к именам хостов, которая, при всем этом, сохраняет необходимую для нас иерархию. Как и в случае распределения числа URL-ов на хост, здесь мы также будем иметь распределение URL по виртуальным директориям с медленно убывающим хвостом.
Сравнение методов ранжирования веб-страниц осложняется тем обстоятельством, что в принципе не существует какого-либо общепризнанного показателя качества для статистического учета важности цифровых документов, за исключением, пожалуй, Google PageRank, который, в свою очередь, является только парадигмой, а не четко определенным алгоритмом. На практике поисковые системы используют целый набор всевозможных факторов, которые позволяют ранжировать страницы сайтов в соответствии с запросами пользователей, непосредственно самими пользователями, а также с учетом поискового контекста. Тем не менее, мы рассчитали несколько модифицированных версий PageRank на веб-графе, состоящем из первых 100 млн. страниц нашего 1 млрд. отсканированных документов, а также его классическую версию с помощью операции рандомной телепортации для 1.80 млрд. равномерно избираемых документов. После расчета HostRank мы рассчитали значения DirRank для нашего 1 млрд. интернет-страничек и после соответствующей обработки URL-ов в виртуальных директориях ресурсов, получили около 114 млн. узлов-директорий, а также 15 млрд. ребер-ссылок между ними. Иными словами, мы на порядок сократили количество узлов на нашем графе, а вот объем ссылок претерпел лишь незначительные изменения. Вполне предсказуемым оказалось то, что весовые значения полученные в ходе подсчета DirRank на данном графе интреполируют между полученными данными PageRank и HostRank за тем исключением, что в отличие от последнего алгоритма, DirRank обрабатывает URL до уровня более мелких структурных единиц. Следует упомянуть, что сам граф хостов содержал в себе только 19,7 млн. узлов с 1.1 млрд. ребер между ними.
Тем не менее, давайте попробуем оценить два метода ранжирования страниц сайтов с помощью метрик Кендалла и расстояния Спирмена, а также выяснить их принципиальные отличия друг от друга. Когда мы начинали наше исследование, мы предположили, что HostRank и DirRank будут хорошо аппроксимироваться с данными Google PageRank, а так как их вычисление потребует гораздо меньшее количество ресурсных затрат, то, следовательно, они будут куда более предпочтительны в практическом использовании при поиске. В действительности любые модификации, корректировавшие их работу, давали достаточно ощутимые различия в получаемых нами результатах. Само по себе это не так уж и плохо по той простой причине, что наша критика PR с равномерной телепортацией показала его высокую зависимость от ссылочных манипуляций и неэффективность в построении качественного ранга интернет-ресурсов. В свою очередь, вычислительные преимущества алгоритмов HostRank и DirRank, а также их повышенная устойчивость к спамденсингу (от англ. spamспам и indexиндекс), делает их очень привлекательными кандидатами для ранжирования сайтов в поиске или, на худой конец, их можно использовать в качестве «шлифования» уже полученных оценок. Например, одной из отличительных черт HostRank от классического PageRank является эффект «сопротивления ссылочной манипуляции». Полагаем, что во многом этот феномен можно объяснить, если более подробно проанализировать перераспределение голосующей способности в виртуальный узел, как в случае с алгоритмом Google PR, так и с нашим методом. Операция телепортации построена таким образом, что перемещение происходит на данный виртуальный узел, и именно он, в свою очередь, равномерно распространяет свою оценку на прочие случайные узлы. Оказывается, что по причине масштаба пограничного веба, виртуальный узел получает более существенный прирост голосующей способности, и в подсчете PR для наших 100 млн. веб-документов его голосующая способность составила 0.82. Мы уже знаем, что подавляющее большинство схем ссылочной манипуляции рейтингом страниц предполагает использование огромного набора интернет-документов для того, чтобы увеличить ссылочную популярность целевой страницы. По причине их массовости и равномерности распределения, вероятность перехода с виртуального узла на подобную спам-коллекцию является достаточно высокой. Поскольку алгоритм HostRank передает вероятность от виртуального узла к прочим узлам вне зависимости от количества документов в нем, то в этом смысле метод компенсирует действие подобных схем. Более того, так как граф хостов относительно мал, то, следовательно, его границы также сужаются, и сам виртуальный узел получает уже существенно меньшую вероятность, достигающую 0.17.
Понимая, что интернет позволяет достаточно эффективно сводить продавцов и покупателей всевозможных товаров и услуг, коммерческие организации вкладывают значительные финансовые средства в продвижение сайтов, обращаясь к специалистам по поисковой оптимизации и раскрутке, которые, в свою очередь, манипулируют результатами поисковой выдачи. Пытаясь противодействовать недобросовестным технологиям продвижения веб-сайтов, поисковые системы постоянно испытывают потребность в разработке таких алгоритмов, которые были бы устойчивы к подобным SEO-манипуляциям. Естественно, что основной мишенью для «накрутки» является классический алгоритм Google PR, что вполне явно отражено в результатах наших экспериментов, и по этой причине мы хотели бы озвучить результаты наших опытов, прежде всего, для этого повсеместно используемого метода. Так, в числе первых 20 URL-ов, изъятых из 100 млн. отсканированных веб-страниц (для подсчета PageRank использовалась рандомная телепортация), 11 имели содержимое взрослой тематики, использовавших для своего продвижения в поиске технологию создания дорвейных страниц, ссылающихся на целевой ресурс. Однако в случае трастовой телепортации с участием двух надежных веб-сайтов в первых 1000 страницах не оказалось ни одного спам-документа подобного рода. По этой причине мы считаем, что данный вид телепортации смог бы значительно снизить шумовой уровень спама в поисковой выдаче. По результатам же исчисления HostRank для взвешенного графа и операции рандомной телепортации, мы изучили ТОП-100 отранжированных хостов и обнаружили в их числе только 14 сомнительных сайтов, используемая спам-технология которых очень сильно напоминала схемы для манипулирования алгоритмом Google PageRank, в том числе: 2 оказались взрослой направленности, 6 предлагали услуги по обмену ссылками, а оставшиеся 5 оказались псевдо-корпоративными сайтами, использующих ссылочный спам. Отметим, что наши алгоритмы могут быть экстраполированы и на пространство доменных имен для успешного решения проблем манипуляции PR и на этом уровне.
Далее мы опишем методику автоматического обнаружения спамерских ссылок, а если говорить более точно, речь пойдет о группах активно ссылающихся друг на друга страниц веб-ресурсов с целью улучшения их видимости в органическом поиске. Как мы уже неоднократно упоминали, реализация тех или иных алгоритмов оказывается очень затруднительной, так как мы работаем с огромной коллекцией интернет-документов. Отличительной же чертой данного исследования является то, что для выявления спама мы исследуем топологию сети ссылок – интернет графа без анализа содержимого, сформировавшего его страницы. Для классификации ссылок на наличие спама мы используем ранговую пропагацию и вероятностный подсчет для вычисления необходимых для нас атрибутов веб-страниц. Построенный на данных атрибутах классификатор впоследствии испытывается на достаточно большой спам-коллекции и, после 10-fold кросс-валидации (количество блоков равноподеленного исходного множества равно десяти), мы можем обнаружить порядка 80% страниц, попадающих под категорию спама, при этом процент ложных срабатываний нашего алгоритма составляет только 2%. Это делает его достаточно конкурентоспособным по отношению к уже существующим атрибутным классификаторам спама, а также первым автоматическим классификатором, достигающим столь высокой точности при наличии только ссылочных данных.
Интернет является превосходной средой для передачи информации и, как мы уже писали ранее, превосходной платформой для реализации товаров и услуг, но так как выход на данные предложения осуществляется по большей части через системы информационного поиска, то каждый владелец стремится получить наиболее высокие позиции в результатах органической выдачи. Именно на этом этапе у веб-мастеров появляется соблазн добиться любыми путями «продающих позиций» поиска, даже если используемые ими методы противоречат требованиям поисковых машин. В результате мы имеем то явление, о котором сейчас и повествуем – поисковый спам или спамденсинг. На сегодняшний день поисковым системам необходимо учитывать то важное обстоятельство, что любая предложенная ими оценочная стратегия, основанная на подсчете каких-либо воспроизводимых характеристик интернет-документов подвержена манипуляциям [2]. На практике, подобного рода мошеннические инструменты широко распространены и во многих случаях имеют достаточно высокую эффективность, а, следовательно, и популярность.
В общих чертах, сейчас мы будем заниматься исследованием окружающей среды цифрового-документа с тем расчетом, чтобы определить возможное наличие в ней такой искусственной ссылочной структуры, которая была бы нацелена на повышение его ранга. Мы также хотим удостовериться в том, что работа по созданию подобной сети ссылок может быть оценена количественно, она ограничена определенной зоной веб-графа и находится под управлением одного единственного агента. Следовательно, мы должны решить две алгоритмические задачи: во-первых, как одновременно извлечь статистические данные об окружении интересующей нас страницы на огромном интернет-графе? Во-вторых, каким образом нам следует осуществлять обработку полученного в сыром виде материала, как применить его для целей обнаружения поискового спама и наложения санкций на некачественные документы? В текущей статье мы адаптировали два ссылочных алгоритма и применили их для детекции мошеннических ссылочных структур на большом графе, тем самым внеся следующий вклад в исследование данной проблемы:
Наши масштабируемые алгоритмы были протестированы на большой выборке доменов в зоне .UK, тысячи из которых были проверены и классифицированы вручную на наличие или отсутствие спама. Касаясь алгоритмического вклада нашего исследования, мы предложили такую интерпретацию приближенных вычислений, которую можно рассматривать в качестве образа ранговой пропагации. Это существенно упрощает ту методологию, которая была предложена в [4], предполагая что сама идея ранговой пропагации может быть рассмотрена в качестве фреймворка для обработки нескольких релевантных статистических данных в крупных сетях. Все наши алгоритмы также могут работать на графе потоков данных, то есть на таком ориентированном графе, вершины которого отражают операции, а соединяющие их ребра демонстрируют потоки данных между ними. Каждое вычисление производится посредством лимитированного повтора последовательного сканирования данных, хранящихся во вторичной памяти [5].
Сейчас мы рассмотрим характерные признаки спам-страниц, которые отличают их от качественных документов, а после сфокусируемся на описании и анализе двух основных алгоритмов, одним из которых является Truncated PageRank, а вторым – алгоритм Вероятностного Подсчёта. В конце мы опубликуем результаты их работы по обнаружению спама на нашей выборке и сделаем соответствующие выводы.
В [6] спаммингом называется любое преднамеренное действие вебмастера, манипулирующее алгоритмами ранжирования поисковой системы, в результате чего увеличивается релевантность документов по пользовательским запросам и/или их показателей, значение которых существенно отличается от истинного ранга. Спам-страницей считается такой цифровой документ, который используется для рассылки спама и/или получает увеличение своей голосующей способности за счет ее передачи от своего спам-окружения. Иное определение спама дается в [7], где говорится, что им является любая попытка обмануть алгоритм релевантности поискового механизма или, говоря более простым языком, рекомендуется вообразить себе такую ситуацию, при которой никаких поисковиков не существует в принципе!
На практике борьба со спамом идет не так гладко, как бы хотелось поисковым машинам, и внешне вполне нормальная HTML-страница, которая имеет всего лишь несколько исходящих ссылок, в действительности оказывается частью ссылочной фермы (link farm), суть которых заключается в том, чтобы создать сильную ссылочную связанность между некоторой группой сайтов и, тем самым, оказать явное воздействие на результаты органического поиска. В [8] такая схема называется «тайным сговором» и определяется как манипуляция ссылочной структурой, реализованная группой лиц с целью умышленного увеличения рейтинга одного из их участников. В данной работе нас будет интересовать, прежде всего, такой вид спама, и наши анти-спам алгоритмы заточены именно на обнаружение участников ссылочных ферм. Надо заметить, что вершина, участвующая в линк фармах, как правило, имеет очень высокую полустепень захода, однако она очень слабо связана с остальной частью графа, то есть наблюдается аппроксимация изоляции.
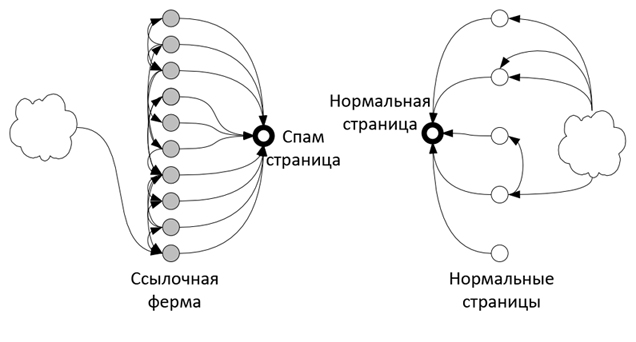
На Рис. 17 показана схема ссылочного окружения нормальной и спам-страницы. Ссылочные фермы могут также получать дополнительные ссылки посредством их покупки у автоматического брокера купли/продажи, через рекламу, приобретение истекших доменов вполне добропорядочных интернет-ресурсов. Мы также хотим отметить наличие несколько модифицированных и гибридных моделей спама, сочетающих в себе и ссылочные инструменты (для получения более высоких позиций в органическом поиске), какие мы можем наблюдать у линковых ферм, так и контентный спам, предполагающего проставление всего лишь незначительного количества исходящих ссылок (дабы не попасть под соответствующие фильтры поисковых машин) в текстовом содержимом интернет-сайта. На наш взгляд, учет не только контентных и ссылочных характеристик цифровых документов, но также и пользовательского поведения (данные могут собираться как из расширений для панели инструментов веб-браузеров, так и посредством отслеживания поведения пользователей на странице поисковых результатов), могли бы работать куда более эффективней, нежели чем только ссылочно-ориентированные алгоритмы обнаружения спама. Тем не менее, в текущей работе мы сосредоточимся на обнаружении ссылочных ферм преимущественно классического типа.
Мы будем рассматривать наш набор HTML-страничек в качестве интернет графа G=(V,E), в котором множество V соответствует интернет-документам в подмножестве веба, и каждая ссылка (x;y) ∈ Е соответствует гипперссылке из страницы x к документу y в данной коллекции. Если говорить более конкретно, то общее количество узлов N=|V| соответствует 1010 [9], а стандартное число ссылок на веб-документе составляет от 20 до 30 штук. Алгоритм анализа ссылок рассматривает каждую обнаруженную им гиперссылку как рекомендацию вебмастера посетить сторонний сайт (например, пройти по ссылке со страницы X на Y), то есть она выступает по некоему подобию индоссамента. Аналогично литературному источнику [10], х (supporter) поддерживает y на расстоянии d, если кратчайший путь из x к y, являющейся ссылкой в E, имеет длину d. Множеством саппортеров страницы называются все прочие связанные с ней документы, влияющие на ссылочные факторы ее поискового ранжирования. Как можно видеть из Рис. 17 ссылочные фермы могут иметь достаточно значительное число всевозможных саппортеров на коротких дистанциях, однако их количество будет гораздо меньше, нежели чем мы предполагали обнаружить на более существенных расстояниях.
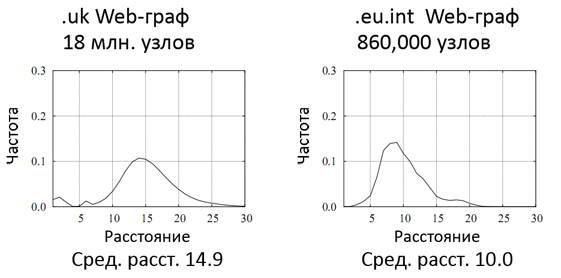
Рисунок 18 отражает распределение различных саппортеров для случайного набора узлов в двух подмножествах веба – данные взяты из Лаборатории Веб-Алгоритмики Миланского Университета. На нем прекрасно видно, что количество новых саппортеров возрастает до некоторого расстояния (между 8 и 12 линками на предложенных графах), а затем понижается. Мы ожидаем, что распределение саппортеров, полученное для страниц с более высокой голосующей способностью будет отличаться от распределения, получаемого за счет тех документов, которые имеют низкий ранг. Для этого мы рассчитали Google PageRank страниц в поддоменной зоне .EU.INT. Как вы понимаете, мы выбрали ее по той простой причине, что при ее масштабах, вероятность наличия спама на сайтах принадлежащих Европейскому Союзу будет минимальна. После того, как мы сгруппировали все наши документы по 10 блокам, отсортированных в соответствии с их значениями по шкале PR в Google Toolbar, мы получили распределение саппортеров (см. Рис. 19) по трем из этих блоков с высоким, средним и низким показателем голосующей способности интернет-страниц.
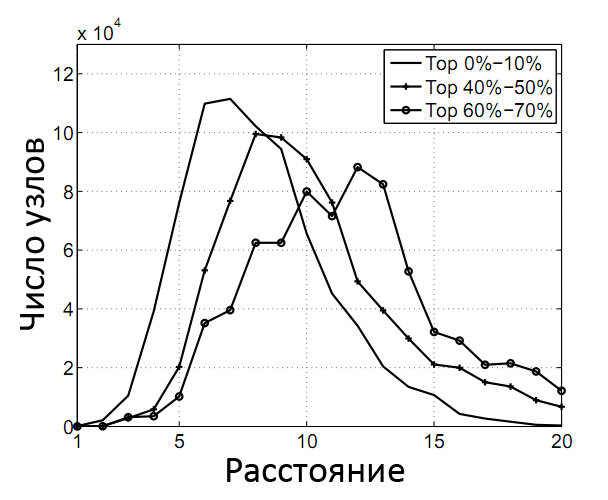
Как и следовало ожидать, по прохождению ряда уровней, документы с высоким рейтингом обладают большим числом саппортеров, чем их собратья с меньшей голосующей способностью. Обратите свое внимание на то обстоятельство, что если две странички являются компонентами сильно-связанного веба, то, в конечном счете, общее число их саппортеров будет иметь точку сходимости по истечении некоторого расстояния. В этом случае область под кривыми будет идентична. Возвращаясь к схеме манипуляции результатами поисковой выдачи Рисунка 17, мы ожидаем, что web-документы, которые являются участниками ссылочных ферм, будут демонстрировать аномальное распределение своих саппортеров. Так как вычисление распределения для всех узлов большого графа представляется нам крайне дорогой и трудоемкой операцией, то мы рассчитаем его только для саппортеров некоторого подмножества «подозрительных» сайтов, хотя априори отнесение какого либо ресурса к категории спама для нас также невозможно. О том, как нам удалось выйти из непростой ситуации мы расскажем вам несколько позже, а пока нас ждет увлекательная часть, посвященная ранговой пропагации.
Сейчас мы опишем алгоритм ссылочного ранжирования сайтов, который производит метрики, пригодные для определения ссылочного спама во всемирной паутине. Пусть AN x N будет ссылочной матрицей графа G = (V;E), то есть axy= 1 <=> (x,y) ∈ E. Пусть P будет такой нормализованной матрицей AN x N, в которой сумма элементов в каждом столбце равна единице, а нули в них заменены на 1=N, во избежание эффекта «утекающего» ранга.
Функциональное ранжирование представляет собой ссылочный алгоритм вычисления значения вектора W вида:
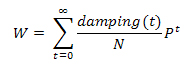
где damping(t) является убывающей функцией на t протяженности пути. В частности, наиболее известным функциональным рангом считается Google PageRank [22], в котором коэффициент затухания уменьшается экспоненциально, а если говорить более конкретно: damping(t) = (1 — α)αT, где α (от 0 до 1), как правило, составляет 0.85. Страница-участник ссылочной фермы может получать завышенное значение PR по той причине, что она имеет множество входящих внешних ссылок и, обычно, ее саппортеры топологически располагаются очень «близко» к данному целевому узлу. Следовательно, нам следует рассмотреть возможность пессимизации данных страниц за счет использования такого коэффициента затухания, который бы игнорировал прямое воздействие ссылок первого уровня, например:
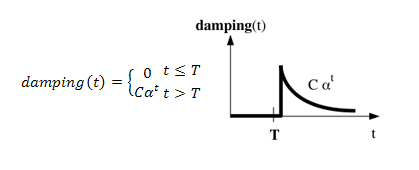
,где C является нормализующей константой, а α — коэффициент затухания, используемый в PR. Нормализирующая константа будет такой, что:
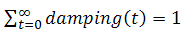
поэтому C = (1-α) / (αT+1). Эта функция предусматривает наказание интернет-страниц, получающих львиную долю своего Google PageRank от входящих гиперссылок нескольких первых уровней. Предложенный нами Truncated PageRank отличается от классической модели Google PR тем, что близкостоящему от целевого узла множеству саппортов не удается увеличивать его голосующую способность и влиять на результаты органической выдачи. Для расчета Truncated PageRank мы используем следующие вспомогательные переменные:
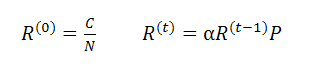
Теперь, подсчитаем Truncated PageRank:
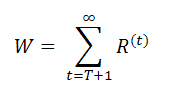

Сам алгоритм представлен на Рис. 20. Важно отметить, что при T=-1 мы вычисляем нормальный PageRank. Прописывая W в закрытой форме, имеем W = C/N (I-αP)-1 (αP)T+1, показывающее дополнительный коэффициент затухания при котором T > -1.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации