SEO-Константа
Яндекс.Директ + оптимизация
К поисковому спаму относятся действия, направленные на введение в заблуждение ранжирующие алгоритмы систем информационного поиска, с целью получения некоторыми интернет-документами незаслуженно высокого рейтинга. Вследствие резкого увеличения объемов поискового спама, пришедшегося на последнее время, качество органического поиска ухудшается. Данный материал представляет собой исчерпывающую таксономию текущих манипулятивных технологий, которая, как мы полагаем, поможет в разработке соответствующих контрмер, связанных с противодействием известным обманным практикам.
Сегодня, все больше людей полагаются на огромные объемы информации, которая представлена в свободном доступе в Глобальной паутине, усиление давления на которую, следовательно, может принести существенные финансовые прибыли для коммерческих организаций. Чаще всего, средством выходом в Сеть являются системы информационного поиска. Именно по этой причине, некоторые люди пытаются ввести в заблуждение ранжирующие механизмы поисковых машин таким образом, чтобы продвигаемые ими документы получили более высокий рейтинг в результатах органического поиска и, таким образом, привлекли внимание пользователя. Следовательно, мы можем расценивать попытки загрязнения веб-спамом окружающей интернет-среды аналогично наводнению нашей электронный почты спам-корреспонденцией. Так или иначе, на выходе мы имеем ухудшение качество результатов органического поиска. Например, по запросу «аптека кайзер» в числе первых десяти результатов, возвращенных крупнейшей поисковой системой (12 марта 2004 года) содержалось 7 страниц, которые не имели ничего общего с аптеками, связанных с системой обеспечения здоровья Кайзер Перманент. Напротив, первая страница органической выдачи фактически отправляла пользователей на сомнительные интернет-ресурсы, продающие «дешевые» медицинские препараты для похудения и продукцию для улучшения мужской потенции со «скидкой». Ряд прочих результатов пытались заманить пользователей поиска предложениями по работе в аптечных сетях или привлечь их внимание страницами сайтов, посвященных анекдотам про пенсионеров. Ясно, что для обеспечения качественного поиска информации, поисковым машинам крайне важно идентифицировать поисковый спам. В настоящее время системы информационного поиска осуществляют противодействие манипулятивным практикам чаще всего именно в ручном режиме, однако, насколько нам известно, они до сих пор не располагают полностью эффективным набором инструментов, способных решить данную задачу. Мы полагаем, что первым шагом в борьбе с поисковым спамом должно явиться понимание его природы, а именно анализ тех манипулятивных технологий, посредством которых спамеры вводят в заблуждение ранжирующие алгоритмы поисковых систем. Надлежащее понимание спамденсинга поможет разработчикам поиска выбрать верное направление для реализации соответствующих контрмер. Исходя из всего этого, в данной статье мы систематизируем используемые спам-технологии, что может послужить фреймворком для противодействия обманным практикам. В научной литературе [4] вкратце обсуждалась проблема поискового спама. Некоторые детали, касающиеся нескольких определенных манипулятивных технологий, мы также можем обнаружить в интернете (например, ссылка [9]).Тем не менее, мы полагаем, что настоящий материал является первой исчерпывающей таксономией всех известных на сегодняшний день спам-технологий. Для того чтобы создать данную таксономию мы не только тесно сотрудничали с экспертами одной из крупнейших систем информационного поиска, опираясь на их практические знания, но и занимались изучением всевозможных случаев манипулятивных технологий самостоятельно. Ряд читателей могут задать нам вопрос, касающийся целесообразности раскрытия подобного рода конфиденциальной информации, связанной с манипулятивными практикам, беспокоясь о том, что это может подстегнуть веб-мастеров к еще использованию указанных приемов и, следовательно, увеличить объемы спама в Сети. Мы хотим заверить наших читателей, что ни одна из описанных далее технологий не является для мошенников какой-либо тайной, а вот большинство пользователей, непосвященных в данные методы, найдут здесь ответы на множество своих вопросов. Более того, мы полагаем, что публикуя данный материал, мы подстегнем исследователей к разработке соответствующих контрмер.
Целью системы информационного поиска является обеспечение высококачественных результатов поисковой выдачи, посредством корректной идентификации всех интернет-страниц, релевантных определенному пользовательскому запросу, и предложение пользователю поиска наиболее авторитетных страниц из всего множества релевантных документов. Релевантность определяется текстовым соответствием между пользовательским запросом и интернет-страницей. Страницам могут быть присвоены запросо-зависимые числовые оценки релевантности: чем выше численное значение, тем большая релевантность документу присваивается по заданному запросу. Авторитетность определяется глобальной (запросо-независимой) популярностью страницы, которая часто следует из гиперссылочной структуры (например, страницы со множеством входящих внешних гиперссылок признаются более авторитетными); также возможны и другие независящие от запросов показатели. На практике, поисковые машины обычно комбинируют релевантность и авторитетность, рассчитывая, таким образом, комбинированное значение ранга, которое используется для упорядочивания результатов органической выдачи, предлагаемых пользователю. Для обозначения любого преднамеренного действия человека, направленного на создание неоправданно благоприятной релевантности или авторитетности отдельных интернет-документов, идущих в разрез истинной ценностью страниц, мы используем термин спам (также как и сманденсинг). Для того чтобы пометить все те объекты (элементы содержимого веб-документа или гиперссылок), которые являются следствием той или иной формы спама мы будем использовать слово «спам» в качестве прилагательного. Людей, которые занимаются спамом бы будем соответственно называть спамерами.
В интернете можно также найти и другие определения поискового спама. Например, некоторые определения (см.[10]) оказываются очень близки к тем, что даны в текущем материале, заявляющие нам о том, что в качестве спама необходимо рассматривать любые модификации, связанные со страницей, исходящие из предположения о существовании систем информационного поиска. Некоторые организации или группы интернет-пользователей (например, [7]) склоняются к тому определению спама, которое включает в себя некоторые из тех манипулятивных технологий, что будут представлены нами в Разделах 3 и 4. Не последнее место в области определения поисковых манипуляций занимают такие компании, занимающиеся поисковой оптимизацией сайтов, как SEO Inc. (seoinc.com) или «SEO константа» (wseob.ru). Большинство компаний по поисковой оптимизации утверждают, что спам только увеличивает релевантность документа пользовательским запросам, не связанную с темой (темами) документа. В то же самое время, множество поисковых оптимизаторов неявно поддерживают, а также активно практикуют методологии, оказывающие воздействие на присваиваемые поисковой машиной оценки авторитетности, называя это «этичными методами» или белой оптимизацией. Обратите внимание, что в соответствии с нашим определением, исключительно все действия, направленные на улучшения ранжирования страницы в результатах органического поиска, без соответствующего улучшения ее истинной ценности, расцениваются нами в качестве спама.
Мы разделяем спам-технологии на две категории. Первая категория включает в себя техники бустинга (boosting techniques), то есть методы, посредством применения которых спамеры стремятся достичь более высокой релевантности и/или авторитетности ряда страниц. Вторая категория включает в себя техники сокрытия (hiding techniques) — методы, которые сами по себе не влияют на алгоритмы ранжирования, но вместе с тем используются спамерами для сокрытия от глаз интернет-пользователей тех практик, которые попадают в первую категорию, то есть бустинга. В последующих двух разделах мы рассмотрим каждую из этих двух категорий более детально.
В данном разделе мы представим манипулятивные практики, которые относятся к технике бустинга [не путать с процедурой бустинга, которая используется в построении композиций алгоритмов машинного обучения — прим. перев.] и оказывают воздействие на ранжирующие механизмы систем информационного поиска. На Рисунке 1 изображена наша таксономия, которой мы будем руководствоваться в своих последующих рассуждениях.
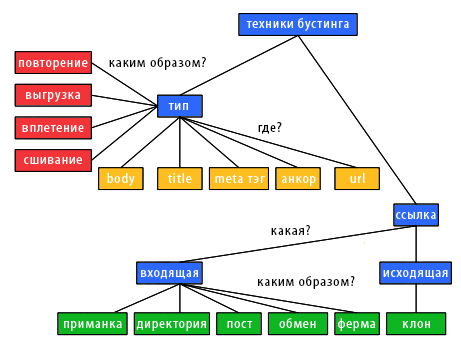
Рисунок 1. Техники бустинга
В задачах оценки текстовой релевантности относительно пользовательского запроса, системы информационного поиска анализируют встречаемость фраз, составляющих пользовательский запрос, в локациях определенного типа. Каждый тип называется полем (или секцией). К общим текстовым полям интернет-странички p относятся: отображаемое содержимое документа (BODY), заголовок документа (TITLE), различные МЕТА-теги, включенные в контейнер HEAD, а также URL-адрес страницы p. Кроме того, также исследуются текст ссылочных анкоров, ассоциированных с теми URL-адресами, которые ссылаются на наш с вами документ p; поскольку они очень часто служат в качестве достаточного описания содержимого страницы p, поля текстовых анкоров рассматриваются в качестве принадлежащих именно документу p. Используемые в текстовых полях документа p слова используются для определения его релевантности определенным пользовательским запросам (группы пользовательских запросов); чаще всего словам, перечисленным в различных полях, назначаются и различные весовые значения. Текстовой спам (term spamming) использует такие манипулятивные практики, которые адаптируют содержимое заданных HTML-секций для увеличения релевантности некачественной страницы некоторым пользовательским запросам.
3.1.1 Алгоритмы, которыми манипулирует текстовой спам
Алгоритмы, с помощью которых системы информационного поиска ранжируют интернет-страницы на основании их текстовых полей, применяют всевозможные модификации фундаментальной метрики TF-IDF, широко используемой в задачах информационного поиска и текстового анализа [1]. Пусть дано некоторое определенное текстовое поле, тогда для каждого слова t, являющегося общим как для самого поля, так и для пользовательского запроса q, TF(t) является частотой данного слова в этом текстовом поле. Например, если слово «яблоко» встречается в теле документа (BODY) 6 раз, который в общей сложности включает в себя 30 слов, тогда частота слова (TF(t)) «яблоко» составит 6/30=0.2. Обратная частота документа для слова t (IDF(t)), связана с количеством документов в нашей с вами коллекции, которые содержат искомое слово t. Например, если слово «яблоко» встречается в 4 из 40 документов, составляющих нашу коллекцию, значение IDF(t) для слова «яблоко» составит 10. Далее значение метрики TF-IDF страницы p относительно пользовательского запроса q, рассчитывается по всем общим для них словам t:
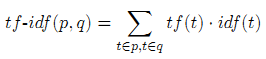
Учитывая показатель TF-IDF, спамеры могут преследовать две цели: либо создать такую страницу, которая будет релевантна большому числу пользовательских запросов (то есть, получить ненулевой показатель TF-IDF), либо спроектировать документ, высокорелевантный определенному пользовательскому запросу (то есть, получить высокий показатель TF-IDF). Для достижения первой цели в содержимое документа включается большое число всевозможных слов. Для достижения второй цели некоторые «целевые» слова повторяются многократно. (Мы можем предположить, что спамеры реально не контролируют меру TF-IDF. Следовательно, единственный способ увеличения оценок TF-IDF заключается в увеличении частоты употребления слов в указанных текстовых полях документа.)
3.1.2 Манипулятивные техники
Спам, относящийся к текстовому содержимому документа, может быть сгруппирован на основании тех текстовых полей, которые используют спамеры для осуществления своих манипуляций. Следовательно, мы выделяем:
Очень часто манипулятивные техники комбинируются. Например, анкорный текст гиперссылки и указанный выше спам в URL-адресах часто можно обнаружить в сочетании с ссылочным спамом, который мы будем обсуждать в Разделе 3.2.2
Еще один способ группирования технологий текстового спама может быть выполнен по типу реализации ключевых слов в текстовых полях. Соответственно, здесь мы имеем:
Кроме использования метрик релевантности по текстовому содержимому, поисковые машины для определения авторитетности интернет-страниц также полагаются на гиперссылочную информацию. Следовательно, спамеры достаточно часто создают гиперссылочную структуру в надежде увеличения авторитетности одного или нескольких продвигаемых документов.
3.2.1 Алгоритмы, которыми манипулирует ссылочный спам
Прежде, чем мы обсудим алгоритмы, которые манипулируются ссылочным спамом, давайте используем следующую модель. Спамер различает три типа интернет-страниц, а именно:
Приняв данную модель, сейчас мы переходим к обсуждению двух известных алгоритмов, которые используют при расчете оценок авторитетности гиперссылочную информацию.
HITS. Оригинальный алгоритм ссылочного ранжирования HITS, представленный в [5] сортирует интернет-страницы в соответствии с определенной темой. Тем не менее, на практике, указанный алгоритм присваивает глобальные посреднические оценки (hub scores), а также оценки авторитетности (authority scores) каждому документу в Сети. В соответствии с официальным определением алгоритма HITS, ценными хаб-страницами являются те документы, которые ссылаются на множество значимых авторити-документов, в то самое время, как ценными авторити-страницами считаются такие, которые цитируются множеством хаб-документов. Система информационного поиска, использующая в качестве ранжирующего механизма алгоритм HITS, возвращает в качестве результата поиска сочетание документов, имеющих наиболее высокие значения оценок посредничества и авторитетности. Манипуляция посредническими оценками представляется достаточно простой задачей, которая реализуется посредством проставления исходящих гиперссылок на большое множество известных страниц, имеющих хорошую репутацию в глазах поисковой системы, таких как cnn.com или mit.edu. Следовательно, для увеличения посреднической оценки раскручиваемого документа t, спамеру всего лишь достаточно проставить множество исходящих гиперссылок из его содержимого на всевозможные качественные ресурсы. Получение высоких оценок авторитетности представляется более трудоемкой задачей, поскольку она предполагает наличие множества внешних входящих гиперссылок, ведущих на целевой документ t с потенциально значимых хабов.
Однако спамер может увеличить посреднические оценки своих собственных O документов (опять же, проставив из их содержимого множество исходящих гиперссылок), а затем процитировать ими свою целевую страницу. Цитирование значимыми и, самое главное, доступными хаб-страницами может увеличить оценку авторитетности его целевого документа в еще большей степени. Следовательно, здесь действует старое правило «чем больше, тем лучше»: располагая ограниченным бюджетом, спамеру достаточно включить в данную манипулятивную схему все собственные, а также доступные страницы, для того чтобы раскрутить с их помощью целевой документ. Напомним, что все его нецелевые собственные страницы также должны по возможности цитировать максимально большое количество прочих (достоверно значимых) авторити-документов.
PageRank. Как описывается в работе [8], для расчета глобальных оценок авторитетности по всем интернет-страницам, содержащихся в Сети, Google PageRank использует информацию входящих гиперссылок. Это предполагает прямую зависимость между количеством входящих гиперссылок и популярностью данной странички среди рядовых интернет-пользователей (как правлю, люди цитируют те цифровые документы, которые находят для себя авторитетными). Интуиция, положенная в алгоритм Google PageRank, предполагает, что веб-страница является авторитетной в том случае, если она цитируется рядом прочих авторитетных документов в Сети. Соответственно, PageRank основан на взаимном усилении, наблюдающимся между документами: авторитетность определенной страницы рекурсивно определяется авторитетностью прочих документов в Глобальной паутине. Недавно проведенный анализ данного алгоритма [2,6] показал, что итоговая оценка PageRank rtotal группы документов (в крайнем случае, единственной страницы) зависит от четырех факторов:
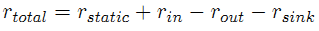
где rstatic является накопленным показателем статического распределения оценок (операции телепортации); rin является значением голосующей способности, передающейся нашему документу по входящим гиперссылкам от его внешнего ссылочного окружения; rout является значением голосующей способности, передающейся по исходящим гиперссылкам нашего документа сторонним веб-страницам; rsink является утраченным «голосом» по причине наличия в общей группе цифровых документов стоковой страницы (то есть, висячей страницы без исходящих гиперссылок).
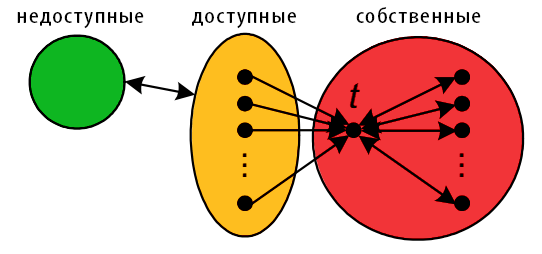
Рисунок 2. Оптимальная гиперссылочная структура, максимизирующая голосующую способность целевого документа t.
Предыдущая формула приводит нашу модель к классу оптимальных гиперссылочных структур, максимизирующих оценку целевого документа t. Одна из них представлена на Рисунке 2. Данная структура обладает необходимыми для нас свойствами, а именно, во-первых, учитывает достижимость всех собственных страниц от доступных для модификаций документов (таким образом, все они могут быть беспрепятственно сканироваться агентами накопления данных систем информационного поиска); во-вторых, содержит минимальное количество ссылок. Для указанной структуры мы использовали следующую стратегию, которая позволила бы максимизировать итоговую оценку PageRank этой спам-фермы и, в частности, нашего целевого документа t:
А вот сейчас, придерживаясь перечисленных далее правил, с помощью гиперссылочной структуры, которую получила созданная нами спам-ферма, давайте максимизируем оценку целевого документа t:
Как вы можете видеть, исходя из Рисунка 2, все тоже старое правило «чем больше, тем лучше», распространяется и на алгоритм Google PageRank. Поэтому создание софистической гиперссылочной структуры в рамках спам-фермы не улучшит ранжирование целевой страницы t в поиске. Следовательно, спамер может получить большее значение PageRank посредством накопления множества входящих гиперссылок с доступных страниц; и/или создания больших спам-ферм, в которых все документы указывали бы на целевой URL. Соответствующие манипулятивные техники представлены далее.
3.2.2 Манипулятивные техники
Мы группируем техники ссылочного спама на основании того, занимается ли спамер проставлением многочисленных исходящих гиперссылок, ведущих на популярные страницы, или накапливает множество входящих ссылок на единственную целевую интернет-страницу/группу страниц.
Исходящие ссылки. Спамер может проставить некоторое количество исходящих гиперссылок в мануальном режиме на известные и авторитетные документы, в надежде увеличить посредническую оценку своего URL-адреса. В то же самое время, наиболее распространенной практикой создания массивного числа исходящих линков заключается в репликации интернет-каталогов: в интернете можно обнаружить ряд сайтов-каталогов, начиная от таких больших и популярных, как DMOZ Open Directory Project (dmoz.org) или Yahoo! Directory (dir.yahoo.com), и заканчивая более малыми и менее известными (например, Librarian’s Index to the Internet, lii.org). Задачей указанных интернет-каталогов является тематическая и типовая классификация интернет-среды, а также создание представительных выборок веб-сайтов в каждом классе. Спамеры часто создают копии всех или отдельных страниц интернет-каталогов, таким образом быстро создавая большое число исходящих гиперссылок.
Входящие ссылки. Для того чтобы аккумулировать необходимое количество входящих гиперссылок на единственную целевую страницу или набор таких документов, спамер может использовать некоторые из перечисленных ниже стратегий:
Для спамеров очень типично поведение, заключающееся в том, чтобы скрыть от интернет-пользователей явные признаки (например, многократное повторение одного или нескольких ключевых слов, длинный перечень гиперссылок) своей псевдооптимизации. Поэтому они используют ряд технологий, позволяющих скрывать злоупотребления поисковой оптимизацией от веб-пользователей, регулярно посещающих их спам-страницы, или асессоров систем информационного поиска, пытающихся распознать случаи применения запрещенных SEO-практик. Данный раздел нашего материала посвящен обзору наиболее распространенных технологий сокрытия, которые сведены на Рисунке 3.
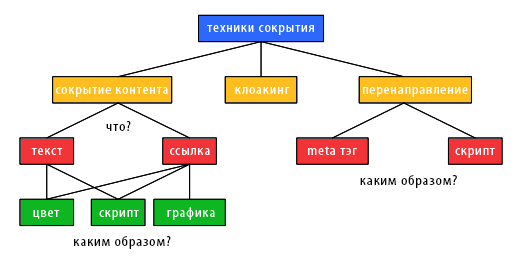
Рисунок 3. Технологии сокрытия
Ключевые фразы или гиперссылки можно сделать невидимыми для интернет-обозревателя пользователя. Одна из распространенных техник заключается в использовании манипулятивной цветовой схемы: слова, размещенные в элементе BODY исходного кода нашего документа окажутся невидимыми для браузера в том случае, если их цвет совпадает с цветом фона HTML-страницы. Покажем это на простом примере:

Аналогичным образом, спам-ссылки могут быть скрыты посредством исключения анкорного текста. Вместо этого, спамеры чаще всего создают крошечное анкорное изображение размером 1×1 пиксель, которое либо делается прозрачным, либо соответствует цвету фона страницы: <a href=»target.html»><img src=»tinyimage.gif»></a>. Мошенники также часто используют скрипты для сокрытия некоторых визуальных элементов интернет-документа, например, посредством установки видимого атрибута HTML-стиля ложным.
Если спамеры способны четко идентифицировать из ряда клиентов агентов накопления данных, они могут использовать следующую стратегию, которая называется клоакингом: для заданного URL-адреса, веб-сервер возвращает обычному веб-браузеру пользователя одну версию HTML-документа, в то время как агенту накопления данных возвращается отличный документ. Таким образом, спамер может предложить своим пользователям исключительно легальное содержимое (без каких-либо следов мошенничества) и, в тоже время, отправить на индексацию поисковой системе откровенно некачественный документ. Идентификация агентов накопления данных может быть реализована двумя способами. С одной стороны, некоторые спамеры ведут реестр IP-адресов, которые используют поисковые машины, а потому в случае совпадения по IP-адресу могут легко идентифицировать поискового робота. С другой стороны, веб-сервер может идентифицировать посетителя на основании информации запрашиваемого клиентского приложения User Agent, текстовая строка которого является частью HTTP-запроса. Например, для следующего HTTP-запроса поле User Agent, содержащее информацию о пользовательском агенте, сообщает серверу об использовании браузера Microsoft Internet Explorer 6:

Строка User Agent не является строго стандартизированной, и она действительна для запрашиваемого клиентского приложения, являющегося частью HTTP-запроса. Тем не менее, сканеры поисковых машин обычно идентифицируют себя по строке User Agent, отличной от тех, что используются в традиционных клиентских приложениях (браузерах), тем самым, имея под собой исключительно благие намерения, а именно, позволяя раскрыть себя законопослушным оптимизаторам. Например, некоторые сайты предлагают поисковым системам такую версию своих страниц, которая очищена от навигационных ссылок, рекламы и прочих визуальных элементов, относящихся к внешней стороне вопроса, но сохраняющих свое содержимое неизменным. Такого рода практика приветствуется системами информационного поиска, поскольку помогает индексировать только полезную для их пользователей информацию.
Еще один способ скрыть свое истинное содержимое заключается в автоматической переадресации браузера пользователя на сторонний URL-адрес как только цифровой документ будет загружен. Таким образом, указанная страница будет по-прежнему индексироваться поисковой машиной, однако сам пользователь никогда ее не увидит — документы, использующие перенаправления, выступают в данной модели в качестве промежуточных звеньев (или прокси, дорвеев), уводящих пользователя к конечной цели; спамеры пытаются использовать подобные странички для переадресации пользователей поисковых систем на свои веб-сайты. Перенаправление может быть реализовано несколькими способами. Самый простой из них заключается в использовании инструкции http-equiv=»refresh», которая относится к числу содержащихся в контейнере HEAD мета-тегов. Устанавливая параметр seconds равным нулю, а параметр URL-to-redirect на тот целевой документ, куда необходимо переадресовать пользователя, наш с вами спамер перенаправит нас на сторонний URL-адрес как только интернет-страница будет загружена браузером:
<meta http-equiv=»refresh» content=»0;url=target.html»>
Несмотря на то, что описанный выше подход достаточно прост в реализации, поисковые системы могут без особого труда идентифицировать данные перенаправления посредством парсинга мета-тегов. Более продвинутые спамеры реализуют автоматическое перенаправление как часть используемого на веб-странице некоторого скрипта, а скрипты, как известно, не могут исполняться сканерами поисковых машин:

В данной работе нами были представлены различные широко-используемые в среде оптимизации и веб-мастеринга манипулятивные технологии, которые были подвергнуты таксономической процедуре. Мы полагаем, что данное структурированное обсуждения позволит улучшить осведомленность научного сообщества, относительно поднятой нами темы. Было бы вполне естественным, если бы наша таксономия поискового спама привела к аналогичной таксономии методов противодействия мошенническим технологиям. Соответственно, мы выделяем следующие два подхода, которые поисковые машины могут использовать в качестве инструментов сопротивления веб-спаму. С одной стороны, в целях противодействия манипуляциям можно обратиться к каждой из представленной технологии бустинга и скрытия по отдельности, которые, соответственно, были представлены в Разделах 3 и 4. В соответствии с первым подходом, было бы вполне возможно:
С другой стороны, в целях противодействия манипуляциям можно обратиться проблеме поискового спама комплексно, не делая существенных различий между отельными мошенническими технологиями. Данный подход основывается на идентификации некоторых общих характеристиках спам-документов. Например, методы вычисления поискового спама, представленные в [3] используют аппроксимацию отчуждения (изолированности) авторитетных, НЕ-спам страниц: авторитетные интернет-документы редко цитируют некачественные страницы. Следовательно, можно использовать адекватные алгоритмы ссылочного анализа с целью сепарации качественных страниц от документов, использующих ту или иную форму поискового спама, без инспектирования каждой манипулятивной технологии по отдельности.
Данная работа является результатом занимательных дискуссий, проведенных с одним из наших коллег по работе в крупнейшей поисковой системе, но который, в свою очередь, пожелал остаться анонимным. Мы хотели бы поблагодарить этого человека за его пояснения и приведенные им примеры, которые помогли нам представить в формализованном виде таксономию поискового спама.
Перевод материала «Web Spam Taxonomy» выполнил: Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации