SEO-Константа
Яндекс.Директ + оптимизация
В данной части мы продолжим исследовать новые методы автоматического выявления ссылочных ферм и представим вам ряд следующих алгоритмов, основанных на анализе входящих и исходящих ссылок. Как уже мы неоднократно писали в предыдущих частях нашего с вами материала, посвященному детекции спама, именно желание коммерческих компаний любыми путями попасть в ТОП 10 результатов органического поиска, получить больший трафик и, как следствие, больший доход с web-ресурса привело к появлению схем манипуляции результатами поиска. Первоначально, когда поисковые машины использовали при подсчете релевантности документа поисковому запросу только такие традиционные статистические меры, как TF-IDF (Прямая частота вхождения термина в документ — Обратная частота документа относительно запроса — от англ. TF — term frequency, IDF — inverse document frequency), спамденсинг делал акцент на манипуляцию текстовыми особенностями веб-страниц, а именно: занимался переоптимизацией документа, то есть перенасыщал их ключевыми словами, работал с мета тегами, добавлял словари в подвалы сайтов и т.д. С появлением ссылочных алгоритмов ранжирования, большее внимание стало уделяться именно игре с ссылочной популярностью и линк фармы стали, наверное, самым главным инструментом для накрутки показателей авторитетности сайтов в глазах поисковиков. Сейчас, когда поисковые системы все в большей мере учитывают поведение посетителей, как на самом сайте, так и на странице представления результатов поиска, разработчики спама также начинают совершенствовать свои технологии, однако рассмотрение таких практик, как, например, эмуляция пользовательского поведения, выходит за рамки настоящего материала.
Ссылочные фермы являются ярким примером «эффекта групповой сплоченности» (TKC) [1], который может оказывать действительно пагубное воздействие на результаты органической выдачи (в этом мы убедимся несколько позже), а стало быть, нам необходимо максимально понизить их способность вмешиваться в алгоритмы поисковых машин. До того, как мы представим вам свои идеи, касательно создания некоторого набора спам-документов, с последующим его расширением и вычислением линк фармов с помощью разработанного нам алгоритма, мы хотим обратиться к таким хорошо-известным, простейшим мерам статистического учета ссылочной популярности, как Google PageRank [2] и HITS [3]. В частности мы рассмотрим одну из модификаций алгоритма PR, нацеленного на борьбу с поисковым спамом, а именно — BadRank. Если рассматривать интернет в виде графа, вершинами которого являются страницы сайтов, а ссылки между ними принимать за ориентированные ребра, соединяющие его вершины, тогда для мы можем применить матрицу смежности М в качестве его представления, а именно М[i,j] обозначаем за 1 в том случае, если имеется ссылка из документа i в j, в противном случае ставим 0. К числу ссылочных алгоритмов основанных на матрице смежности прежде всего принято относить Google PR и HITS. Для PageRank: предположим, что страница A имеет входящие линки со страниц T1, T2,…, Tn; C(A) является количеством исходящих ссылок с документа A, d — константа со значением от 0 до 1. Тогда, PageRank страницы A может быть подсчитан следующим образом:
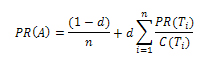
На практике PR каждого документа комбинируется с некоторыми прочими показателями, такими как оценка текстового соответствия двух документов, и страницы со схожей релевантностью поисковому запросу получают куда большую голосующую способность, нежели чем в обратном случае. Для HITS: множество страниц рассматривается как подмножество, небольшая часть от их общего числа во Всемирной паутине, тесно связанное с данным запросом [3]. Всякий документ u может выступать в качестве «хаба» h[u] или «авторити-документа» a[u]. Соответственно, высокий показатель авторитетности какого-либо документа автоматически влечет за собою повышение его значимости для данного запроса, а высокий показатель концентрации означает, что документ ссылается на множество авторитетных страниц в сети. Предположим, что E является матрицей смежности для этого подмножества, тогда имеем следующие уравнения:
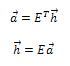
Итерации в обеих матрицах продолжаются до тех пор, пока вектора a→ и h→ не сойдутся к собственным векторам ETE и EET соответственно. Именно после оглушительного успеха ссылочных алгоритмов ранжирования страниц сайтов в органической выдаче, поисковые системы столкнулись с таким массовым явлением как продвижение сайтов, которые осуществляли SEO-компании. В результате чего, поисковые механизмы разработали алгоритмы для противодействия искусственным ссылочным массам, и одним из них стал BadRank, философия которого очень близка к предложенному нами решению.
В конце 2001 года поисковая система Google реализовала новый вид наказания веб-сайтов за использование web-мастерами сомнительных ссылочных методов поискового продвижения, который предполагает обнуление тулбарных значений PageRank. Обнуление PR страниц (одной или всего сайта целиком) выполняется вне зависимости от качества входящих ссылок, и при попадании веб-сайта под действие данного фильтра мы не видим его исчезновение из индекса поисковой машины, однако его позиции претерпевают колоссальное понижение, то есть происходит пессимизация страниц в результатах органической выдачи. Конечно, нулевой PR далеко не всегда может означать наложение фильтра, поскольку любая недавно появившаяся страница в интернете имеет Google PR=0. Куда более настораживающей является такая ситуация, при которой формально популярный интернет-документ, который до определенного момента имел и высокий PageRank, и занимал лидирующие позиции в рейтинге Google, вдруг демонстрирует утрату своего былого великолепия. Тогда, можно с определенной долей вероятности предполагать то, что к нему был применен спам-алгоритм (Рис. 29).
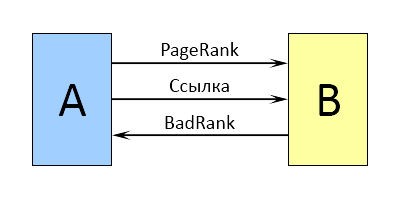
В данной части нашего с вами материала мы попытаемся описать теоретическую модель работы BadRank. В основу данного алгоритма положена идея «о плохом ссылочном окружении» интернет-сайта, иными словами: если страница А ссылается на страницу B, которая имеет высокое значение показателя Google BadRank, тогда первоначальный документ A получает его приращение в определенной пропорции. Несмотря на очевидное сходство с классическим PR, BadRank следует обратной логике, учитывающей не входящие ссылки, а исходящие, которые могут появиться только по воле владельцев интернет-ресурсов. Сама формула для алгоритма Google BadRank следующая:
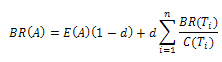
,где BR(A) является BadRank документа А; BR(Ti) — значение BadRank страниц Ti, за которые голосует документ А; C(Ti) — количество входящих ссылок на документ Ti; d — коэффициент затухания; E(A) — специальная оценка интернет-страниц, значение которого говорит нам о том, будет ли к тому или иному документу применен фильтр или нет. Без этой оценки, алгоритм BadRank превращается в еще один метод исследования топологии сети ссылок, не учитывающий в своей работе каких-либо дополнительных критериев. Сумма E(A) представляет собой оценку всех интернет-страниц, и в соответствии с производимыми итерациями алгоритма, значение BR должно распространяться не только на оштрафованный документ, но и следовать далее. Интересно то, что фактически алгоритм Google BadRank может идентифицировать целые интернет-зоны, которые, по его подсчетам, имеют высокий удельный вес некачественных ресурсов, точно также, как и классический PageRank учитывает наиболее качественные и авторитетные области.
Отсюда следует логический вывод, что голосуя за сайт, расположенный в неблагополучной зоне, например, существует ряд бесплатных доменных зон, к которым алгоритмы Google априори относятся с осторожностью (известен случай, когда в 2011 году из поискового индекса Google, по причине высокого содержания спама, была массово исключена доменная зона .CO.CC — свыше 11 млн. веб-ресурсов), владелец сайта рискует получить для своей странички прирост BR.
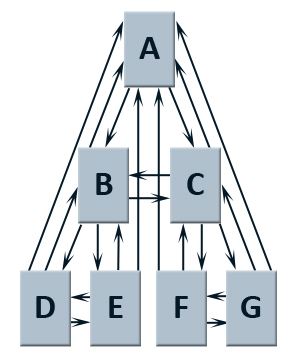
Рис. 30 Иерархическая структура HTML-документов с элементами связывания.
Глядя на Рис. 30, давайте составим Таблицу 7 , которая показала бы нам распределение входящих и исходящих ссылок:
| Уровень | Входящие ссылки | Исходящие ссылки |
| 0 | 6 | 2 |
| 1 | 4 | 4 |
| 2 | 2 | 3 |
Отметим, что в нашем примере количество внутренних входящих ссылок уменьшается по мере продвижения вниз по иерархии, а наибольшее число внутренних исходящих линков приходится на промежуточные звенья предложенной нами структуры сайта. В Таблице 8 мы добавим еще один уровень к нашему примеру:
| Уровень | Входящие ссылки | Исходящие ссылки |
| 0 | 14 | 2 |
| 1 | 8 | 4 |
| 2 | 4 | 5 |
| 3 | 2 | 4 |
Как вы можете наблюдать, максимальное количество внутренних исходящих ссылок снова пришлось на промежуточный, средний уровень, однако, самое важное заключается в том, что они распределяются более равномерно, нежели чем внутренние входящие ссылки. Теперь мы установим значение показателя E(A) для главной страницы нашего сайта в 100, а для всех прочих документов — 1. Тогда, если коэффициент затухания у нас составляет 0.85, то на выходе мы получаем следующее значение показателя Google BR (Табл. 9):
| Уровень | Входящие ссылки | Исходящие ссылки |
| 0 | 14 | 2 |
| 1 | 8 | 4 |
| 2 | 4 | 5 |
| 3 | 2 | 4 |
Как вы можете наблюдать, максимальное количество внутренних исходящих ссылок снова пришлось на промежуточный, средний уровень, однако, самое важное заключается в том, что они распределяются более равномерно, нежели чем внутренние входящие ссылки. Теперь мы установим значение показателя E(A) для главной страницы нашего сайта в 100, а для всех прочих документов — 1. Тогда, если коэффициент затухания у нас составляет 0.85, то на выходе мы получаем следующее значение показателя Google BR (Табл. 9):
| Документ | BadRank |
| A | 22.39 |
| B/C | 17.39 |
| D/E/F/G | 12.21 |
Видно, как главная страница веб-ресруса делится с прочими, связанными с ней документами своим первоначальным значением BadRank. Ниже мы также обсудим с вами взаимодействие BR и PageRank, но забегая вперед, скажем, что они могут замечательно нейтрализовывать друг друга, как в прямом, так и обратном направлении. Сейчас мы обыграем второй вариант, при котором нам необходимо сделать допущение, что страница G, указывает на вышестоящую по иерархии документ X с постоянным BadRank, а именно BR(X)=10. При этом: ссылка из содержимого документа G является единственной входящей ссылкой для Х; параметр E является одинаковым для всех страниц нашего сайта и равен единице; коэффициент затухания d=0.85. Имеем (Табл. 10):
| Документ | BadRank |
| A | 4.82 |
| B | 7.50 |
| C | 14.50 |
| D | 4.22 |
| E | 4.22 |
| F | 11.22 |
| G | 17.18 |
При таком варианте, как вы можете сами видеть из Таблицы 10, распространение Google BadRank является менее однородным. Также интересно заметить, что BR главной страницы имеет существенно меньшее значение, и действительно, на практике, когда веб-сайт наказывается за исходящую ссылку на некачественный ресурс, может складываться такая ситуация, при которой индексный документ будет показывать нам ненулевое значение, в отличие от прочих страниц ресурса. Отсюда, каждый веб-мастер должен отслеживать обнуление не только главной, но всех имеющихся на сайте HTML-страничек.
Если мы предположим, что верно описали вам модель алгоритма Google BadRank (все-таки поисковые системы очень неохотно делятся со своими пользователями информацией о работе своих алгоритмов), тогда возникает вполне закономерный вопрос, касательно объединения классического PR и анти-спам алгоритма для пессимизации сайтов-мошенников и, насколько это возможно, игнорирования добропорядочных ресурсов. Для начала предположим, что расчет показателя BadRank проводится непосредственно с вычислением голосующей способности страницы, и после первого подсчета BR, при каждой итерации PageRank, авторитетность нашей с вами любимой страницы разделяется на полученное значение BadRank. Соответственно, страница с высоким значением BR не будет передавать своим соседкам по сети голосующую способность PR, или передавать ее только в очень ограниченных долях. Вместе с тем, получается, что наличие одной единственной ссылки на какой-либо подозрительный сайт обязывает поисковую систему подозревать не только нас, но все цитирующее нас окружение! Надо сказать, что такая прямая взаимозависимость между расчетами PR и BR является очень рисковой, да и реальное воздействие BadRank на голосующую способность сайта в случае их одновременного подсчета не может быть просчитана нами заранее, поскольку, как известно, наличие висячих узлов (влияние висячих страниц на результаты поисковой выдачи, а также их обработку мы рассматривали в предыдущих частях нашего с вами материала, посвященного детекции поискового спама) вносит существенные коррективы в подсчеты классического PageRank.
Таким образом, куда более целесообразным представляется разграничение итераций для PageRank и BadRank, с последующим их объединением, которое может основываться на простейших арифметических операциях, и вычитание дает нам необходимый результат, при котором незначительное увеличение веса BR страниц не оказывает существенного влияния на высокий PageRank. Но даже в этом случае имеется проблема, заключающаяся в трудности достижения нулевого значения PR для большого объема интернет-страниц. Для того, чтобы обнулить голосующую способность всего сайта в целом, мы можем разделить PR на Google BadRank, но куда более привлекательный подход связан с тем, что нормализация и масштабирование может осуществляться в диапазоне от 0 до 1 таким образом, что «хорошие» документы имеют значение близкое к единице, а «плохие» — к нулю. Перемножая эти показатели с PageRank, мы получаем более точный результат.
В качестве эффективной и достаточно простой в своей реализации альтернативы может выступать пошаговое вычисление BadRank и PageRank, предполагающей обнуление голосующей способности веб-сайта в случае превышения некоторого порогового значения. Аналогично, если показатель или соотношение BadRank и Google PR оказывается ниже определенного уровня, какого-либо воздействия на показатели нашего web-ресурса оказываться не должно.
Конечно, то, каким образом поисковая система будет комбинировать свои алгоритмы является второстепенной проблемой, и куда большее количество вопросов возникает из-за отсутствия информации о реальном воздействии BadRank на голосующую способность сайта. Действительно, мы мало что можем заключить из тех данных, которые нам предоставляют обнуленные показатели тулбарного PR. До сих пор неясно, если какая-либо страница имеет высокий PageRank, то насколько сильное воздействие на него оказывает ссылка на подозрительный сайт? Возможно, что в этом случае влияние BadRank будет незначительным, но только до тех пор, пока наша страница не проставит, например, 20 таких исходящих ссылок из своего содержимого и т.д. В дальнейшем мы продемонстрируем вам алгоритм, который предлагает намного более гибкое решение в плане обработки спаммерских сайтов, а также сравним наш подход с Google BadRank, но прежде мы бы хотели продемонстрировать вам то, насколько сильное влияние оказывают ссылочные фермы на алгоритм HITS.
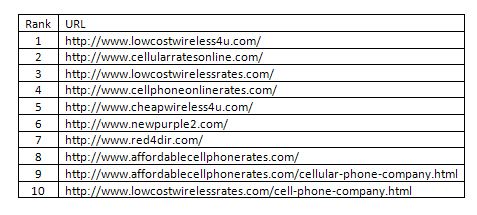
Ниже мы покажем вам то, как линк фармы вмешиваются в работу алгоритма Джона Клейнберга (Jon Kleinberg) HITS. Мы собрали набор данных для 412 запросов; использовали поиск Google и Yahoo! для извлечения ТОП 200 URL-ов в целях получения корневого набора, а также его последующего расширения за счет входящих ссылок и создания базового множества. Применив на нем алгоритм HITS мы обнаружили, что в наших результатах доминирует одна или несколько ссылочных ферм. Например, для запроса «компания по продаже беспроводных телефонов» первая десятка авторити-страниц (См. Рис 31-а) оказалось сильно связанной.
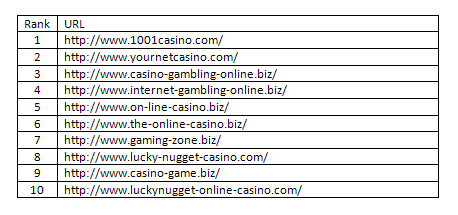
Аналогичная ситуация обстояла и с запросом «использование кредитной карты» (См. Рис 31-б), где преимущество отдавалось сильно связанному сообществу сайтов интернет-казино.
Для того чтобы определить насколько часто сайты-участники link farm появляются в лучших результатах органической выдачи мы провели простой эксперимент со 140 запросами на поисковом механизме Yahoo!. В том случае, если три домена, на которые ссылается наша страница, будут совпадать с тремя голосующими за нее доменами, мы будем считать такую веб-страницу участницей линк фарма. После того, как необходимый спам-страницы были отмечены надлежащим образом, мы стали расширять сформировавшееся множество за счет добавления к нему документов, имеющих по меньшей мере 3 исходящих линка на страницы, уже помеченные нами как спам. От себя добавим, что в текущих расчетах участвуют только ссылки с разных доменов (межсайтовые ссылки). Как вы можете увидеть в дальнейшем, посредством этого нехитрого подхода для выбранного списка запросов нам удалось обнаружить в ТОП 200 Yahoo! существенное количество некачественных веб-документов. В соответствии с Рис. 32 мы используем 6 уровней, описывающих нам существование спама в индексе поисковых машин. Ось x представляет собой минимальное число спам-страниц, которое нам удалось обнаружить в ТОП-N результатов, а ось y показывает, какой именно процент из этих запросов содержал в себе помеченные нами спам-документы.
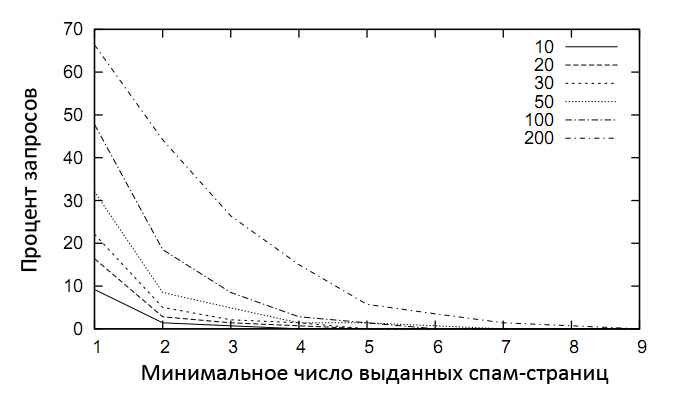
Каждая из шести кривых представляет собой ТОП 10 (самая нижняя), 20, 30, 50, 100 и 200 (самая верхняя) поисковых результатов. Как мы видим, для ТОП 200 около 68% запросов по меньшей мере содержат в себе минимум 1 спам-страницу, а порядка 2% запросов — 7 или более. Для ТОП 10, на которую чаще всего обращают внимание как и сами поисковые системы, так и их пользователи, для 9% запросов мы имеем минимум 1 некачественный ответ.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации