SEO-Константа
Яндекс.Директ + оптимизация
В 2002 году проблема обнаружения и нейтрализации спама в результатах органической выдачи была признана в качестве одной из первоочередных для всех крупнейших систем информационного поиска [1]. Позже, руководитель службы поиска Google Амит Сингхал (Amit Singhal) подсчитал, что в том случае, если бы спамденсингу удалось бы манипулировать результатами поиска по всем коммерческим запросам, то в 2004 году индустрия поискового спама могла бы получить годовой доход на сумму 4.5 млрд. долл [2]. Поскольку нахождение на первых позициях рейтинга дает возможность веб-мастерам и владельцам веб-сайтов получать постоянные и всевозрастающие прибыли, нет ничего удивительного в том, что в практике искусственного воздействия на результаты поиска задействовано огромное количество финансовых, машинных и человеческих ресурсов. Далее мы сосредоточимся на определении страниц, которые имеют обратные входящие ссылки с некоторого множества интернет-документов, созданных для обмана ранжирующих механизмов поисковых систем. Для каждой страницы веб-сайта мы будем вычислять значения SpamRank, измеряющего незаслуженно высокий PageRank [3] документа. Отметим, что текущий подход не видит принципиального отличия между непреднамеренными или, например, какими-то «белыми методами» наращивания ссылочной массы и злоумышленными практиками, и любая страница с большим количеством входящих ссылок, скорее всего, будет оценена нашим алгоритмом как спам-документ. Для того же, чтобы понять суть ссылочного спама, давайте обратимся к отличительным свойствам естественной ссылки, данной в [4]: «гиперссылочная структура включает в себя огромное число латентных человеческих аннотаций, которые могут быть чрезвычайно полезны для автоматического определения человеческих суждений об авторитетности». Аналогично вышеописанному представлению об авторитетности документа, мы должны говорить о страницах с высоким значением Google PR только в том случае, если они действительно заслужили свою голосующую способность, а не достигли ее каким-либо специальными приемами и техниками, коих на сегодняшний день существует великое множество. И прежде чем мы перейдем к рассмотрению алгоритма SpamRank, мы подробно познакомим вас с некоторыми из них, в частности здесь мы коснемся темы ссылочного непотизма или кумовства, а также тех методов, которые позволяют эффективно справляться с его воздействием на показатели интернет-ресурсов.
Алгоритмы ссылочного анализа и популярности в значительной степени основываются на исследовании ссылок, указывающих на тот или иной документ. Поскольку ценность странички будет напрямую зависеть от того объема входящих ссылок, которые на нее указывают, многие веб-мастера используют всевозможные методы для наращивания ссылочной массы своего ресурса. Поисковые машины признают наличие проблемы непотизма в среде веб-мастеров и желают максимального снижения возможного влияния подобного рода инструментов на результаты их органической выдачи, а также на голосующую способность веб-страниц. В то время, как типичное определение кумовства включает в себя фаворитизм по отношению к родственникам, мы используем более широкое толкование, а именно «дарование покровительства по причине родственных отношений, а не заслуг» (C. & G. Merriam Co. 1913). В этой связи мы решили отнести в данную категорию не только ссылки между теми интернет-документами, которые имеют общего владельца, но также и проставляемые на коммерческой основе, то есть рекламные и платные. Непотистские ссылки, как правило, считаются нежелательными, и поэтому их принято удалять до начала расчета ссылочной популярности и ранга страницы. Заметим, что несмотря на то, что некоторые службы (например, DirectHit (Ask Jeeves, Inc. 2000), применяемый на Lycos, HotBot и MSN Search) собирают и анализируют пользовательскую популярность, учет которой позволил бы нам расширить наши представления о непотистском спаме, здесь мы не будем рассматривать последствия кумовства для данного вида популярности.
Как мы уже писали чуть ранее, ссылочный статус документа в значительной степени основывается на количестве входящих ссылок, однако в случае учета абсолютно всех ссылок, ведущих на интересующую нас страничку, результаты нашего подсчета будут искажены, и во многом это произойдет по следующим причинам:
Вторая причина попадает под более широкое понятие «поискового спама», с которым поисковые машины ведут дорогостоящую и изнурительную войну, закономерным следствием которой становится выработка иммунитета ко всевозможным его проявлениям. Большие успехи достигнуты в части того спамденсинга, который относится к текстовому содержимому страницы (нерелевантные ключевые слова, а также их перечисления, невидимый / слабо видимый текст и т.д.), однако в вопросах ссылочного спама дела обстоят на порядок хуже. Результат от ссылочного воздействия может быть обнаружен на самых разных веб-сайтах, предлагающих своим пользователям абсолютно разный уровень контента. Используем для своего примера внешне качественный по всем
своим меркам ресурс about.com, который, вместе с тем, имеет не только интегрированное в шаблон дизайна навигационное меню, но и размещает большую часть своего содержимого на различных хостах. Было ли это сделано умышленно или нет, нам не известно, но в любом случае такая организация информации на сайте влечет за собою
увеличение объема страниц, заносимых в индексную базу поискового механизма. Мы также видим повышение релевантности по тем поисковым запросам, которые соответствуют ключевым словам в именах хостов, посредством использования коих данному ресурсу удается ввести в заблуждение простейшие эвристические алгоритмы, учитывающие внутренние ссылки веб-сайтов. Так, в органической выдаче Google в ТОП 200 URL-адресов, ссылающихся на about.com, только 5 из них имели отличный от него домен. Все остальные тематически относились к самому сайту, например: #108:
billiardspool.about.com/sports/ billiardspool/mbody.htm. В качестве примера иного рода могут быть веб-сайты, которые состоят из большого набора ссылающихся друг на друга цифровых-документов, но вместе с тем предлагающих своим пользователям либо отличное по своей тематике содержимое, либо просто пустой контент с очевидными вкраплениями ключевых фраз и/или ссылками на рекламодателей. Очень часто мы имеем дело с переадресацией на целевой ресурс посредством методологии тайпсквотинга. Для тех кто не знаком с понятием тайпсквотнинга поясним, что для увеличения посещаемости своих ресурсов многие хитрые web-мастера регистрируют на себя доменные имена созвучные с доменами известных организаций. Хотя вопрос увеличения посещаемости и манипулирования соответствующими факторами не входит задачи нашего материала, посвященного детекции поискового (ссылочного) спама, скажем, что в силу некоторых психологических особенностей, а также близкого расположения некоторых букв на клавиатуре компьютера, люди часто ошибаются при прописании «n» и «m» (yandex.ru и yamdex.ru); «w» и «v»/ «s» и «c» (wseob.ru и wceob.ru ) – затруднительно воспринимаются на слух при неверном произношении) и т.д.; опечатки могут наблюдаться в прописании доменных зон (vk.ru и vk.com); пропуска точки после «WWW» (www.google.ru wwwgoogle.ru) и т.д. Существует ряд общих подходов к учету подобного рода обманных технологий, в том числе:
Несмотря на то, что мы не располагаем всей полнотой информацией касательно того, какие же именно подходы используют в своей штатной работе поисковые системы, подавляющее большинство исследователей (в том числе и Клейнберг, 1998 г.) склоняются ко второму варианту. Вы конечно спросите, чем же ему уступает лист исключений? Отвечаем, что в него могут вноситься какие-либо формы непот-спама только после самого факта их непосредственного обнаружения. К сожалению, даже простейший эвристический подход нуждается в ряде существенных исключений. Например:
Основная проблема заключается даже не в идентификации внутренних ссылок веб-сайта, а в том, какие из них нам следует учитывать в расчетах популярности интернет-страницы, а какие (например, рекламные и приобретенные на коммерческой основе через автоматического брокера их купли/продажи), напротив, игнорировать. Зачастую это означает то, что, с одной стороны, нам необходимо сохранить ссылки между документами двух отличных людей/групп/владельцев, а с другой — удалить их между теми HTML-страницами, которые управляются единым владельцем, вне зависимости от того, совпадают ли в данном случае доменные имена, контент страниц и т.д. В том случае, если мы используем вариант с удалением ненужных для нас ссылок, то наш интернет граф становится меньше и, следовательно, процесс данного анализа протекает быстрее. Иная практика заключается в значительном понижении их весов, однако такой вопрос представляется еще более сложным, нежели чем их полное исключение из расчета популярности. В ссылочном анализе ссылки между двумя документами часто рассматриваются как рекомендации (голос) веб-мастера посетить соседа по сети, и, несмотря на то, что в теории решение проставить ссылку должно быть объективным и беспристрастным, на практике, во-первых, существуют как внешние, так и внутренние системы по их приращению, а во-вторых, мы можем иметь дело с аффилированными бизнесами, корпоративными поглощениями организаций, их сайтов и т.д.
Для того, чтобы оценить потенциальную возможность автоматического обнаружения непотистских ссылок, мы провели серию предварительных экспериментов с помощью алгоритма построения деревьев решений C 4.5, который был разработан и предложен Джоном Квинланом (John Ross Quinlan). Мы выбрали данный алгоритм по той причине, что он является самым популярным и, наверное, лучшим из всех существующих методов по построению деревьев принятия решений. Используя два набора, для первого из них мы в ручную отметили 1536 ссылок (пар ссылающихся друг на друга страниц), которые выбирали случайным образом для того, чтобы включить в наше множество значения разнотипных интернет-документов, а затем обработали их таким образом, чтобы всякая ссылка имела только одну уточняющую отметку, подтверждающую или опровергающую факт наличия или отсутствия непотизма. Далее мы создали второй набор, который включал в себя данные о более 7 млн. страниц из индекса поисковой системы DiscoWeb (Davison et al. 1999), и вручную пометили в нем 750 ссылок. Несмотря на то, что во втором случае, выборка получилась менее предвзятой, в ней, скорее всего, было представлено более однотипные страницы по причине ее относительно незначительного объема. В целом, вероятность классов для двух наборов данных отличаются следующим образом: в качестве непотистских ссылок в первом из них было помечено 89.5%линков, против 72.8% непот-ссылок для второго. При описании всех возможных отличительных характеристик (даны ниже) первая выборка содержала 255 уникальных случая, против 535 зафиксированных случая для второй, из которых под категорию непотизма попадали 72.1% и 78.6% случая соответственно.
Ниже дан неполный набор, состоящий из 75 бинарных характеристик, с помощью которых мы распознаем непотиский спам:
Вышеописанные характеристики подбирались с расчетом на их последующее расширение посредством включения дополнительных параметров, которые бы могли поспособствовать нашему исследованию ссылок на предмет кумовства. В качестве примера таких характеристик, использованных при построении дерева решения можно привести Рис. 38, где каждая линия показывает нам условие (проверку), а в конечных узлах дерева (листьях) содержатся результаты классификации: непотистские помечаются как 1, а хорошие помечаются как -1.

Рис. 38 Пример дерева решения, созданного с помощью алгоритма C4.5
Прежде чем начать процесс подбора характеристик, мы предварительно разместили их по следующим группам:
Данные группы приблизительно соответствуют тому количеству времени, которое требуется для их оценки. В то время как основной набор включает в себя только URL-адреса, а информация для второй (основной набор + ссылки) и третей (основной набор + текст) группы может быть извлечена из индекса поисковых систем, для последнего набора, который уже содержит в себе все характеристики трех предыдущих групп, нам потребуется обращение к базам данных регистраторов доменных имен. Для достижения большей точности мы также вручную сформировали дополнительный пятый набор, использующего 1/3 имеющихся характеристик.
Как уже писалось выше, эксперименты для каждого набора характеристик проводились с использованием алгоритма C4.5 (параметры были установлены по умолчанию, отсечение ветвей не выполнялось). Рисунок 39 показывает нам частоту появления ошибок при построении дерева решения на этапе перехода от одной выборки к следующей.
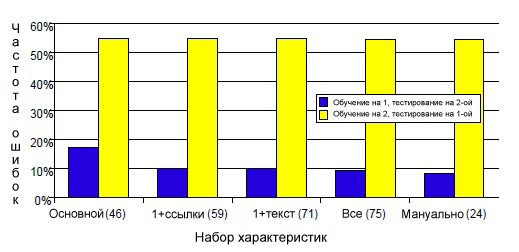
Рис. 39 Коэффициент ошибок единичного дерева решения для каждого из пяти набора (в скобках указано количество характеристик)
Следующая диаграмма (рисунок 40) демонстрирует нам результаты экспериментов с применением 10-fold кросс-валидации для обеих выборок (как по отдельности, так и в их комбинации). Как вы можете видеть, наиболее высокая средняя точность (>97%) была получена на первой выборке, а вот по второй и комбинированной она составляла только >91% и >93% соответственно.
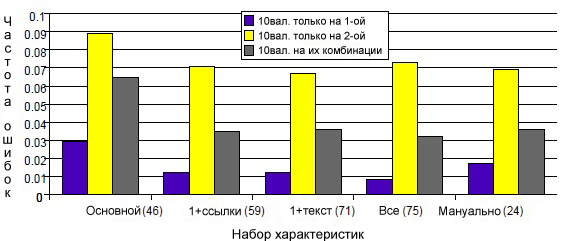
Рис. 40 Средняя частота появления ошибок 10-fold кросс-валидации для каждого из пяти набора (в скобках указано количество характеристик)
Также для сравнения мы использовали простую эвристику. Так, при маркировке непот-ссылки, содержащей требуемые нам имена хостов, общая частота появления ошибок для первой выборки составила 64% против 18% для второй. Распределение ошибок дано ниже в Таблице 16:
| Первая | Выборка | Вторая | ||
| (a) | (b) | <= классифицировано как => | (a) | (b) |
| 140 | 21 | (a): хорошие ссылки | 203 | 1 |
| 963 | 412 | (b): непотистские ссылки | 134 | 412 |
При аналогичной попытке обнаружения непотизма применительно к доменным именам общая частота появления ошибок для первой выборки составила 60.6% против 14.4% для второй. Распределение ошибок дано ниже в Таблице 17:
| Первая | Выборка | Вторая | ||
| (a) | (b) | <= классифицировано как => | (a) | (b) |
| 121 | 40 | (a): хорошие ссылки | 201 | 3 |
| 892 | 483 | (b): непотистские ссылки | 103 | 443 |
Мы полагаем, что спам-документ имеет аномальное распределение саппортеров, искусственно завышающих его Google PageRank. Как будет показано далее, голосующая способность веб-узла равна среднему значению его полного персонализированного PageRank, рассчитываемого для всех интернет-страниц. Новейший алгоритм [5] позволяет осуществить приближенный расчет всех этих показателей (аппроксимированные значения персонализированного PR хранятся в разреженной матрице в компактной форме) в целях определения подавляющего большинства источников, вызывающих приращение в каком-либо узле значения его PageRank. Нашим основным интуитивным предположением является то, что саппортеры хорошей страницы не будут иметь между собой сильной связанности, то есть они будут распределены по источникам, которые имеют отличные друг от друга качественные характеристики. Аналогично всему вебу, распределение голосующей способности хорошего множества саппортеров будет поддаваться степенному закону. Конкретным примером, при котором мы можем подозревать страницу в использовании манипулятивных техник, может служить приращение Google PR только за счет низкоранжируемых документов. Дополнительным поводом к проявлению нашего пристального внимания может послужить их массовость, которая является попыткой компенсировать отсутствие качественных саппортеров. Другим примером может стать наличие некоторого множества саппортеров с очень узким диапазоном их голосующей способности, поскольку в данном случае мы имеем набор однородных объектов, который наблюдается при возникновении каких-либо сеток и коопераций между сайтами/веб-мастерами. Одним из примеров такого сотрудничества могут являться ссылочные фермы, о которых мы вам уже неоднократно рассказывали в предыдущих частях нашего материала, посвященного детекции поискового спама. Для вычисления каких-либо манипулятивных схем (продвижение сайта предполагает применение огромного количества практик, каждая из которых может быть уникальна по своей форме, но не по содержанию), завышающих показатели Google PageRank, используются два важных обстоятельства:
Соответственно, если обрисовать вам форму идеального поискового спама, то им будет являться полная реплика Глобальной Сети, то есть настолько качественная ее копия, что автоматические методы ссылочного анализа не смогут отличить ее от оригинала. Наш метод нацелен на выявление недостающих статистических особенностей множества подозрительных документов. Одной из таких особенностью в наших экспериментах является степенной закон распределения (заметим, что на практике, во избежание обмана алгоритмов ранжирования, поисковые машины используют комбинации большого числа особенностей, которых, вероятней всего, не следует так уж сильно относить к алгоритмам анализа ссылок). Наш алгоритм SpamRank, представляющий собой значение, оценивающее незаслуженный Google PageRank документа, состоит из трех основных шагов, каждый из которых мы подробно опишем в нашем следующем материале, а его общую структуру можно представить следующим образом (Рис. 41):

Сначала для всякой имеющейся страницы мы выбираем саппортеров с помощью имитационного моделирования персонализированного PageRank по методу Монте-Карло. Затем, на втором этапе мы штрафуем документы, которые участвуют в создании подозрительного Google PR, иными словами их персонализированный PageRank распределяется с зависимостью по подозрительным целям. Как было предложено в [6, 7], мы последовательно сравниваем сходство диаграммы PR источников с идеальной моделью распределения по степенному закону. На третьем шаге мы просто персонализируем Google PageRank по вектору санкций. Здесь вся подозрительная активность концентрируется на их целях; в ином виде, мы определяем алгоритм SpamRank как метод прямых и обратных итераций в разреженной матрице между целями и источниками.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации