SEO-Константа
Яндекс.Директ + оптимизация
Современные поисковые технологи дополняют привычное соответствие текстового содержимого страниц и пользовательского запроса глобальным понятием «важности», основанной на гиперссылочной структуре веба, в качестве примера можно привести алгоритм ранжирования Google PageRank. В задачах создания более совершенного по своему качеству поиска, это глобальное понятие важности (авторитетности) может быть сужено до создания персонального взгляда на авторитетность. Например, показатель важности может быть смещен в соответствии с набором первоначально интересных страниц, указанных самим пользователем. Вычисление и хранение всех возможных персонализированных представлений об авторитетности априори является непрактичным; персонализированные предпочтения вычисляются во время выполнения пользовательского запроса, поскольку вычисления каждого пользовательского суждения требует итеративного исчисления по всему веб-графу. В настоящей работе мы представляем новые графо-теоретические результаты, а также новую методику, основанную на этих результатах, которая кодирует персонализированные представления об авторитетности в качестве частичных векторов. Частичные вектора разделяются между несколькими персонализированными представлениями, а соответствующие затраты на вычисление и хранение хорошо масштабируются с их количеством. Наш подход позволяет проводить расчеты с помощью приращений таким образом, что создание персонализированного мнения из частичных векторов происходит практических во время запроса. Мы представляем эффективные алгоритмы динамического программирования для вычисления частичных векторов, алгоритм построения персонализированных представлений об авторитетности из частичных векторов, и экспериментальные результаты, демонстрирующие эффективность и масштабируемость наших методик.
В самом общем виде, веб-поиск преимущественно осуществляется с помощью текстовых запросов, адресуемых интернет-пользователями системам информационного поиска. Вследствие значительного размера Глобальной паутины одного только текстового соответствия документа пользовательскому запросу, как правило, оказывается не достаточно для того, чтобы ограничить количество ответов поисковых машин до приемлемого размера. Наряду с прочими методологиями [8], был предложен алгоритм PageRank [10] (и реализован на поиске Google [1]), использующий гиперссылочную структуру веба, чтобы вычислять глобальное значение «важности» (авторитетности), которое, в свою очередь, может использоваться в качестве инструмента воздействия при ранжировании результатов органического поиска. Чтобы охватить различные представления об авторитетности разных веб-пользователей и запросов, базовая модель алгоритма PageRank может быть изменена в целях создания «персонализированного представления» о Глобальной паутине, пересматривая указанную авторитетность в соответствии с пользовательскими предпочтениями. Например, пользователь может пожелать, чтобы интернет-документы, сохраненные в его закладках, выполняли роль наборов предпочтительных страниц, оказывая на поиск такое влияние, при котором любые ответы поисковой машины, которые имеют авторитет, относительно документов, перечисленных в его закладках, получали бы более высокий рейтинг. В то время как эксперименты с использованием персонализированного PageRank продемонстрировали свою полезность и перспективность [5, 10], размеры веба делают его практическую реализацию чрезвычайно трудоемкой задачей. Чтобы понять, почему это так, давайте рассмотрим интуицию, положенную в алгоритм PageRank, а также расширение, необходимое для перехода к персонализации.
Основная мотивация, положенная в Google PageRank, состоит в том, что важными страницами являются те, что связаны гиперлинками со множеством прочих авторитетных страниц. Например, некоторая интернет-страница, которая имеет всего лишь пару входящих гиперссылок, вряд ли покажется нам авторитетной, однако она действительно может оказаться таковой, если этими двумя страницами будут Yahoo! и Netscape, которые сами по себе являются важными документами, поскольку имеют многочисленные входящие внешние гиперссылки. Одним из способов формализации этого рекурсивного понятия является использование модели «случайного блуждания», представленной в литературе [10]. Представьте себе, что триллионы случайных серферов просматривают всевозможные интернет-страницы: если на некотором шаге серфер просматривает страницу р, то на следующем шаге он переходит на случайный документ, соседствующий с нашей страницей p. С течением времени, ожидаемый процент серферов на каждой странице р сходится (при определенных условиях) к пределу r(p), который не зависит от распределения начальных точек. Интуитивно, этот предел и есть PageRank страницы р, и принимается равным показателю авторитетности р, так как она отражает количество серферов, которые будут просматривать документ p в любой момент времени.
Значение PageRank r(p) отражает «демократическую» важность, которая не отдает предпочтения каким-то конкретным страницам. На самом деле, пользователь может иметь набор предпочтительных страниц Р (таких, например, которые перечислены в его закладках), которые он считает более интересными. Мы можем подсчитать предпочтительные страницы в модели случайного блуждания путем введения вероятности «телепортации» с: на каждом шаге, серфер переходит обратно к случайной странице из набора P с вероятностью с, и с вероятностью 1-с продолжает следовать по гиперссылкам. Предельное распределение серферов в этой модели будет предпочитать страницы из набора P; страницы, которые ссылаются на P; страницы, на которые ссылаются Р, и т.д. Мы представляем это распределение как персонализированный вектор PageRank (PPV), который персонализирован по множеству P. Неформально PPV является персонализированным суждением об авторитетности страниц в интернете. Вместо глобального распределения авторитетности, результаты ранжирования в соответствии с текстовой релевантностью документа пользовательскому запросу могут быть смещены, относительно PPV.
Каждый PPV имеет длину n, где n это количество страниц в интернете. Простое вычисление PPV с использованием итерации до достижения точки конвергенции требует многократного сканирования веб-графа [10], что делает невозможным онлайновое вычисление в процессе ответа на вопрос пользователя. С другой стороны, оффлайн вычисления и хранение PPV по всем предпочтительным наборам, из которых имеется 2n, представляются для нас слишком громоздкими. Мы представляем метод кодирования частично вычисленных, общих векторов PPV, что практично использовать для расчета и хранения в оффлайне, из которых PPV можно быстро вычислить в процессе пользовательского запроса. В нашем подходе мы ограничили предпочтительный набор Р подмножеством выборки страниц-хабов Н, выбранных по той причине, что они представляют наибольший интерес для персонализации. На практике, мы ожидаем, что множество страниц H будет иметь высокий PageRank («важные страницы»); среди них будут страницы, перечисленные в таких модерируемых каталогах как Yahoo! или Open Directory [2]; или важные страницы для конкретного предприятия или приложения. Размер H можно рассматривать как доступную степень персонализации. Мы представляем алгоритмы, которые, в отличие от предыдущих работ [5, 10], хорошо масштабируются в зависимости от размера H. Более того, эти же методы могут обеспечить аппроксимацию к гораздо более широкому множеству всех PPV, что позволит, по крайней мере, перенести некоторый уровень персонализации на произвольные предпочтительные множества. Основной вклад текущей работы заключается в следующем:
В Разделе 2 вводятся обозначения, используемые в данной работе, а также приводится математическая формализация персонализированного PageRank. В Разделе 3 представлены базисные вектора — первый шаг к кодированию PPV в качестве общих компонентов. Полное кодирование представлено в Разделе 4. В Разделе 5 обсуждается вычисление парциальных величин. Экспериментальные результаты представлены в Разделе 6. Смежные работы обсуждаются в Разделе 7. Раздел 8 резюмирует положения данной статьи. Дополнительный материал, и в первую очередь доказательства теорем, находится в Приложениях.
Пусть G = (V,E) обозначает веб-граф, в котором V является множеством всех веб-страниц, а E содержит ориентированное ребро <p, q>, если страница р ссылается на страницу q. Обозначим для страницы р через I(p) и O(p) множество соседних входящих и соседних исходящих ссылок p соответственно. Индивидуальные соседние входящие ссылки обозначаются как Ii(p) (1 ≤i ≤ |I(p)|), а индивидуальные соседние исходящие ссылки обозначаются аналогично. Для удобства, страницы пронумерованы от 1 до n, и мы считаем страницу p и связанные с ней числа i взаимозаменяемыми. Для вектора v, v(p) обозначим элемент р, р-ый компонент v. Все вектора в данной работе, являются n-мерными и имеют неотрицательные элементы. Их можно рассматривать больше как распределения случайной величины, а не как направленные отрезки. Величина вектора v определяется как ∑ni=1 v(i) и записывается |v|. В данной работе, векторные величины всегда находятся в [0,1]. В реализации, вектор может быть представлен как список его ненулевых элементов, поэтому еще одной полезной мерой является размер v (количество ненулевых элементов в v).
Мы обобщаем набор предпочтений P, описанный в Разделе 1, по вектору предпочтений u, где |u| =1, а u(p) обозначает количество предпочтений к странице p. Например, пользователь, который хочет, чтобы те страницы, что указаны в его закладках, P персонализировались равномерно, будет иметь такое u, где u(p) =1/|P|, если p ∈ P и u(p) = 0, если p ∉ P. Мы формализуем значение
персонализированного PageRank, используя векторно-матричные уравнения. Пусть A будет матрицей, которая соответствует веб-графу G, где Aij =1/|O(j)|, если страница j ссылается на страницу i, и Aij = 0 в противном случае. Для простоты изложения будем считать, что каждая страница имеет хотя бы одну соседнюю исходящую ссылку, что может быть обеспечено путем добавления ссылок «на самих себя» к страницам без исходящих ссылок. Полученные результаты могут быть скорректированы с учетом (незначительных) воздействий на эту модификацию, в соответствии с Приложением С.2. Для данной u, уравнение персонализированного PageRank можно записать как:
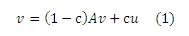
где c ∈ (0, 1) является постоянной «телепортации», о которой говорилось в Разделе 1. Обычно c ≈ 0,15, и эксперименты показали, что небольшие изменения в c оказывают незначительное практическое воздействие [10]. Решение v в уравнении (1) представляет собой стационарное распределение случайных серферов по модели, которая обсуждалась в Разделе 1, где на каждом шагу пользователь переходил на страницу с вероятностью c⋅u(p) и (р), или, в противном случае, следует по случайной соседней исходящей гиперссылке [10]. Согласно Теории Маркова, решение v с |v| = 1 всегда является единственным [9] 2. Оно является вектором персонализированного PageRank (PPV) для вектора предпочтений u. Если u является равномерным распределением вектора u = [1/n, … , 1/n], то соответствующее решение v является глобальным вектором PageRank [10], который не дает предпочтения ни одной странице.
Для удобства читателям в Таблице 1 перечислены ключевые термины, которые будут активно использоваться в последующих разделах.
| Ключевые термины | Определение | Раздел |
| Множество хабов Н | Подмножество интернет-страниц | 1 |
| Предпочтительный набор P | Множество страниц по которым выполняется персонализация (ограниченные в данной статье подмножеством H) | 1 |
| Вектор предпочтений u | Предпочтительный набор с весами | 2 |
| Вектор персонализированного PageRank (PPV) | Распределение авторитетности, индуцированное вектором предпочтений | 2 |
| Базисный вектор rp (или ri) | PPV для вектора предпочтений с единственным ненулевым элементом в p (или i) | 3 |
| Вектор хаба rp | Базисный вектор для хаба страницы p ∈ H | 3 |
| Частичный вектор (rp −rpH) | Используется со скелетом хабов для построения хаб-вектора | 4.2 |
| Скелет хабов S | Используется с частичными векторами для построения хаб-вектора | 4.3 |
| Сетевой скелет | Разложение скелета хабов для включения страниц не входящих в H | 4.4.3 |
| Парциальные величины | Частичные вектора и хабы, сетевой скелет | |
| Промежуточные результаты | Сверяются в течение итеративных вычислений | 5.2 |
Таблица 1. Ключевые термины и их определение
Мы представляем первый шаг к кодированию PPV в качестве общих компонентов. Мотивация, положенная в кодирование, основано на простом наблюдении линейности PPV и может быть формализована посредством следующей теоремы. 3
Теорема (Линейности). Для любых векторов предпочтений u1 и u2, если v1 и v2 являются двумя соответствующими PPV, то для любых констант α1, α2 ≥ 0, так что α1 + α2 = 1,
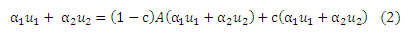
Неформально, согласно Теореме Линейности решение линейной комбинации векторов предпочтений u1 и u2 такое же, как и линейной комбинации соответствующих PPV v1 и v2. Доказательство приводится в Приложении А. Пусть x1, . . . , xn будут единичными векторами в каждой размерности, так что для каждого i, xi имеет значение 1 для элемента i и 0 для остальных. Пусть ri будет PPV, которое соответствует xi. Каждый базисный вектор ri дает распределение случайных серферов по модели, согласно которой на каждом шаге серфер телепортируется обратно к странице i с вероятностью с. Это может рассматриваться как представление о странице i в интернете, когда элемент j вектора ri является авторитетностью j в представлении i. Следует отметить, что глобальный вектор PageRank является 1/n(r1 + ⋅⋅⋅ + rn), средним представлением о каждой странице. Произвольный вектор персонализации u можно записать как взвешенную сумму единичных векторов xi:
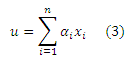
для некоторых констант α1, . . . , αn. Согласно Теореме Линейности,
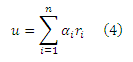
является соответствующим PPV, представленным в качестве линейной комбинации базисных векторов ri. Вспомним из Раздела 1, что предпочтительные наборы (теперь вектора предпочтений), ограничивается подмножеством выборки страниц-хабов H. Если базисный вектор хаба (или далее вектор хаба) для каждого р∈ H был вычислен и сохранен, то любой PPV, соответствующий предпочтительным наборам P размера k (вектор предпочтений с k ненулевыми элементами), может быть вычислен путем суммирования k, соответствующих векторов хаба rp с соответствующими весами αp. Каждый вектор хаба можно вычислить с помощью наивного алгоритма вычисления с фиксированной точкой (см. литературу [10]). Тем не менее, каждое вычисление с фиксированной точкой является дорогим и требует нескольких обходов веб-графа, а время вычисления (а также стоимость хранения) линейно возрастает с количеством векторов хабов |H|. В следующем разделе мы представим более масштабируемые вычисления, построив вектора хабов из общих компонентов.
В Разделе 3 мы представили PPV в качестве линейной комбинации |H| векторов хаба rp, по одному для каждого p ∈ H. Любой PPV, который базируется на страницах хаба, можно быстро построить из множества предварительно вычисленных хаб-векторов, но вычисление и хранение всех хаб-векторов является нецелесообразным. Для эффективного вычисления значительного количества векторов хаба мы разлагаем их на частичные вектора и скелет хабов, т.е на те компоненты, из которых можно быстро построить хаб-вектора во время запроса. Представление векторов хаба в виде частичных векторов и скелета хабов сокращает время вычисления и место для хранения благодаря распределению компонентов между векторами хабов. Однако следует отметить, что в зависимости от имеющихся ресурсов и требований приложений, векторы хабов могут также быть построены оффлайново. Таким образом, «время запроса» можно рассматривать в целом как «время построения вектора».
Вычислим один частичный вектор для каждой хаб-страницы р, который, главным образом, кодирует часть вектора хаба rp, уникального для р таким образом, что компоненты, распределенные между векторами хабов, не вычисляются и сохраняются в резерве. Дополнением к частичным векторам является скелет хабов, который лаконично отражает взаимосвязь между векторами хабов. По этому «сценарию», как мы увидим в подразделе 4.3, частичные вектора формируют хаб-вектор. Математический аппарат, который используется для формализации этого разложения, представлен далее. 4
Для формализации связей между векторами хабов, мы сопоставим значение персонализированного PageRank, представленное как PPV, к инверсивному P-расстоянию на веб-графе согласно концепции, основанной на ожидаемых f-расстояниях, которая приведена в работе [7]. Пусть p, q ∈ V. Мы определяем инверсивное P-расстояние r’p(q) от p к q как
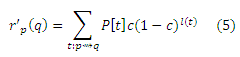
где суммирование ведется по всем маршрутам t (путям, которые могут содержать циклы), начиная от p и заканчивая в q, возможно возвращаясь к p или q несколько раз. Для маршрута t = <w1, . . . , wk>, длина l(t) является k−1, количеством ребер в t. Член P[t], который должен интерпретироваться как «вероятность передвижения t», определяется как
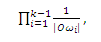
или 1, если l(t)=0. Если нет маршрута от p к q, суммирование принимается равным 0 5. Обратите внимание, что r’p(q) инверсно измеряет расстояния: оно выше для узлов q, которые «ближе» к p. Как следует из обозначения и доказательства в Приложении C, r’p(q) = rp(q) для всех p, q ∈ V, поэтому мы будем использовать rp(q), чтобы обозначить как инверсивное P-расстояние, так и значение персонализированного PageRank. Таким образом, значение PageRank можно рассматривать как инверсивное измерение расстояния. Пусть H ⊆ V будет некоторым непустым множеством страниц. Для p, q ∈ V, определим rpH(q)как ограничение rp(q), которое учитывает только маршруты, что проходят через некоторую страницу h ∈ H в уравнении (5). То есть, страница h ∈ H должна появиться в любом месте t кроме конечных точек. В точности rpH(q) описывается так:
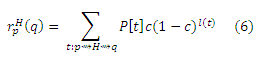
где обозначение t: p ∼> H ∼> q напоминает нам, что t проходит через некоторую страницу в H. Заметим, что t должен иметь длину не менее 2. В этой статье H всегда является набором хабов, и, как правило, р является хабом (пока мы не обсудим сетевой скелет подразделе 4.4.3).
Интуитивно, rpH(q) определенное в уравнении (6) служит влиянием p на q по всему H. В частности, если все пути от p к q проходят через страницы в H, то H отделяет p и q, и получаем rpH(q)= rp(q). Для хорошо подобранных множеств H (обсуждается в подразделе 4.4.2) будет верным то, что rp(q) − rpH(q) = 0 для многих страниц p, q. Наш алгоритм заключается в использовании этого свойства для разбивки rp на два компонента: (rp − rpH) и rpH, с помощью уравнения
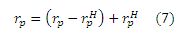
Сначала мы проводим предварительное вычисление и сохранение частичного вектора (rp − rpH) вместо полного вектора хаба rp. Частичные вектора вычислять и хранить дешевле, чем полные вектора хабов, предполагая, что они представлены в виде списка своих ненулевых элементов. Кроме того, размер каждого частичного вектора уменьшается при увеличении |H|, что делает этот подход особенно масштабируемым. Затем мы снова добавляем rpH ко времени выполнения запроса для вычисления полного вектора хаба. Тем не менее, вычисление и хранения rpH явно может быть таким же дорогим, как и для самого rp. В следующем разделе мы покажем, как кодировать rpH, чтобы вычислять и хранить его с максимальной эффективностью.
Дадим краткий обзор того, на чем мы остановились: в Разделе 3 мы представили PPV в качестве линейных комбинаций векторов хабов rp, по одному для каждого p ∈ H. И теперь мы можем быстро построить PPV во время выполнения запроса, если мы предварительно вычислили вектора хабов с учетом относительно небольшого подмножества PPV. Для эффективного кодирования векторов хабов, в подразделе 4.2 мы сказали, что вместо полных векторов хабов rp, мы сперва вычислили и сохранили лишь частичные вектора (rp − rpH), которые интуитивно учитывают лишь те пути, что не проходят через страницу в H (т. е. распределение «заблокировано» множеством H). Эффективное вычисление и хранение разности векторов rpH является темой данного подраздела. Получается, что вектор rpH можно обозначить через частичные вектора (rh − rhH), для h ∈ H, согласно следующей теореме. Напомним, из Раздела 3, что xh имеет значение 1 в h и 0 в остальных случаях.
Теорема (Хабов). Для любых p ∈ V, H ⊆ V,
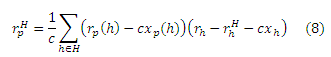
Что касается инверсивного P-расстояния (подраздел 4.1), Теорема Хабов гласит, что расстояние от страницы р к любой странице q ∈ V через H является расстоянием rp(h) от р к каждой h ∈ H, которая выражает расстояние во времени rh(q) от h к q, делая поправку на пути между хабами по rhH(q). Члены cxp(h) и cxh рассматриваются в особых случаях, когда p или q находятся в H. Доказательство, довольно трудное, приводится в Приложении D. Величина (rh − rhH), которая появляется в правой части уравнения (8),в сущности, является частичными векторами, которые обсуждались в подразделе 4.2. Предположим, мы вычислили rp(H) = {(h,rp(h)) | h ∈ H} для хаб-страницы p. Подставляя Теорему Хабов в уравнение (7), мы получаем следующее Уравнение Хабов для построения вектора хаба rp из частичных векторов:
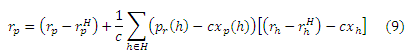
Это центральное уравнение для построения векторов хабов из частичных векторов. Множество rp(H) имеет размер не более чем |H|, и намного меньше, чем полный вектор хабов rp, который может иметь до n ненулевых элементов. Кроме того, вклад каждого элемента rp(h) в сумму не больше, чем у самого rp(h) (обычно даже намного меньше), так что малыми значениями rp(h) можно пренебречь с минимальной потерей точности (Раздел 6) . Множество S = {rp(H) | p ∈ H} образует скелет хабов, устанавливая взаимосвязи между частичными векторами.
Интуитивное представление о кодировании и построении векторов хабов, предложенное Уравнением Хабов (9) показано на рисунке 1. В верхней части рисунка, каждый частичный вектор (rh − rhH), в том числе (rp − rpH), изображается в виде треугольника с зазубринами, обозначая h у вершин. Треугольник можно рассматривать в качестве представляющих путей, которые начинаются с h, хотя, точнее, это представляет собой распределение значения авторитетности, рассчитанное на основе путей (см. обсуждение в подразделе 4.1). Зазубрина в треугольнике показывает, где вычисление частичных векторов «обрывается» на другом хабе. В центре рисунка изображается часть скелета хабов rp(H) в виде дерева, так что можно представить «скопление» вектора хаба. Вектор хаба создается при помощи логического соединения частичных векторов, используя соответствующие веса в скелете хабов, как показано в нижней части рисунка.
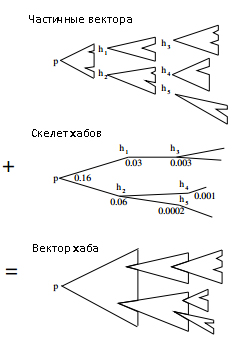
Рисунок 1: Интуитивное представление о кодировании и построении векторов хабов из частичных векторов и скелета хабов.
4.4.1 Резюме
Таким образом, вектора хабов являются составными компонентами для PPV и соответствуют векторам предпочтения, которые основываются на хабах. Частичные вектора, вместе со скелетом хабов, являются составными компонентами для векторов хабов. Исходя из транзитивного соотношения, частичные вектора и скелет хабов являются «строительными блоками» PPV: они могут быть использованы для построения PPV без первых материализованных векторов хаба в качестве промежуточного этапа (подраздел 5.4). Заметим, что для векторов предпочтения, базирующихся на множественных хаб-страницах, построение соответствующего PPV непосредственно из частичных векторов может привести к значительной экономии по сравнению с построением из векторов хабов, поскольку частичные вектора являются общими для множественных хаб-векторов.
4.4.2 Выбор множества H
До сих пор мы не сделали никаких предположений о множестве хабов H. Не удивительно, что выбор хабов может значительно повлиять на результаты поиска, в зависимости от расположения хабов в общей структуре графа. В частности, размер частичных векторов будет меньшим, если страницы в Н имеют более высокий PageRank, поскольку страницы с высоким PageRank в среднем близки к другим страницам относительно инверсивного P-расстояния (подраздел 4.1), а размер частичных векторов связан с инверсивным P-расстоянием между хабами и любыми другими страницами в соответствии с Теоремой Хабов. Интуиция подсказывает, что страницы с высоким PageRank, как правило, более интересные для персонализации при в любой ситуации. Но в случае, когда предназначенные хабы не имеют высокого PageRank, может быть полезным простое включение некоторых страниц с высоким PageRank в H для улучшения поиска. Мы провели эксперименты, подтверждающие, что размер частичных векторов намного меньше в случае использования страниц с высоким PageRank в качестве хабов, чем при использовании случайных страниц.
4.4.3 Сетевой скелет
Методы, используемые при построении векторов хабов, могут быть усовершенствованы для того, чтобы хотя бы аппроксимировать персонализацию по произвольным векторам предпочтения, которые не обязательно учитывают H. Предположим, мы хотим персонализироваться по странице p ∉ H. Уравнение хабов можно использовать для построения rpH из частичных векторов, учитывая, что мы вычислили rp(H). Как отмечалось в подразделе 4.3., затраты на вычисление и хранение rp(H) на несколько порядков меньше, чем rp. Хотя rpH является всего лишь аппроксимацией rp, он все же может зафиксировать основную информацию персонализации для правильно подобранного множества хабов H. Так как rpH можно рассматривать в качестве «проекции» rp на H. Например, если H содержит страницы из Open Directory, rpH может зафиксировать информацию, касающуюся общей темы rp. Изучение целесообразности сетевого скелета W = {rp(H) | p ∈ V } является целью будущей работы.
В Разделе 4 мы представили способ построения векторов хабов из частичных векторов (rp − rpH), для p ∈ H и скелета хабов S = {rp(H) | p ∈ H}. Мы также описали сетевой скелет W={rp(H)|p∈V}. Простое вычисление этих парциальных величин с использованием итерации до достижения точки конвергенции [10] для каждой р будет плохо масштабироваться с числом хабов. Здесь представлены масштабируемые алгоритмы, которые эффективно вычисляют данные величины с помощью динамического программирования для установления взаимосвязи между ними. Также показано, как PPV может быть построен из частичных векторов и скелета хабов непосредственно во время самого запроса. Все наши алгоритмы обладают таким свойством, что они могут быть остановлены в любой момент времени (например, когда ресурсы будут исчерпаны), так что можно использовать текущие «лучшие результаты» в качестве аппроксимации или возобновить вычисление позже для повышения точности при возобновлении ресурсов.
Подраздел 5.1 мы начинаем с представления теоремы, лежащей в основе всех представленных алгоритмов (также как и связи между PageRank и инверсивным P-расстоянием, показанное в Приложении C). В подразделе 5.2 мы представим три алгоритма, основанных на этой теореме, для вычисления общих базисных векторов. Алгоритмы в подразделе 5.2 не предназначены для развертывания, но они используются в качестве основы алгоритмов, описываемых в подразделе 5.3 для вычисления парциальных величин. Подраздел 5.4 описывает построение PPV из частичных векторов и скелета хабов.
Вспомним модель случайного блуждания, описанную в Разделе 1. С ее помощью создается вектор предпочтения u = xp (для просмотра страницы р в вебе). На каждом шагу, серфер s телепортируется на страницу p с вероятностью c. Если s находится на р, то на следующем шаге, s с вероятностью 1 − c он перейдет на случайного соседа страницы p. То есть, в отрезок времени (1 − c)1/(|O(p)|), серфер s будет на любом соседе страницы р через шаг после телепортации на р. Такое поведение поразительно похоже на модель создания вектора предпочтения
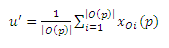
,где серферы телепортируются непосредственно к каждой Oi(p) с равной вероятностью 1/(|O(p)|). Подобие формализовано при помощи следующей теоремы.
Теорема (Разложения). Для любых p ∈ V,
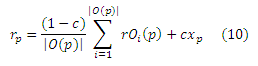
Теорема Разложения гласит, что базисный вектор rp для р является средним значением базисных векторов rOi(p) соседей, на которые попадает серфер после посещения данной страницы, а также поправочным коэффициентом cxp. Доказательство приведено в Приложении B. Теорема Разложения дает иное представление о PPV. Она гласит, что просмотр страницы p в Глобальной паутине (rp) является средним значением просмотров ее соседей, на которые попадает серфер после посещения данной страницы, но с дополнительной авторитетностью, присваиваемой самой себе р. То есть, авторитетность страниц при просмотре р зависит либо непосредственно от самой р, либо авторитетность задается ссылочным окружением р, которое в случае исходящей с данной страницы гиперссылки «одобряется» этой р. По сути, это рекурсивная интуиция создает эквивалентные способ формализации значения персонализированного PageRank: базисные вектора можно определить как вектора, удовлетворяющие Теорему Разложения. В то время как Теорема Разложения определяет зависимость между базисными векторами, вопрос вычисления базисных векторов rp в связанных подзадачах для динамического программирования не склонен определять зависимости. Например, можно сначала вычислить некоторые базисные вектора, а затем определить остальные, используя первые в качестве решенных подзадач. Тем не менее, наличие циклов в графе делает этот подход неэффективным. Вместо этого, наш алгоритм заключается в рассмотрении вычисления вектора с меньшей точностью в качестве подзадачи. Например, имея вычисленный rOi(p) с определенной точностью, мы можем использовать Теорему Разложения, чтобы объединить rOi(p) для вычисления rp с большей точностью. Этот подход имеет преимущество в том, что не требуется фиксировать точность заранее: процесс может быть остановлен в любое время для использования текущего лучшего ответа.
Мы представляем в общем контексте три алгоритма вычисления полных базисных векторов. Эти алгоритмы разработаны, в первую очередь, для того, чтобы усовершенствовать наши алгоритмы вычисления парциальных величин, представленных в подразделе 5.3. Все три алгоритма вычисляются итерационно с фиксированной точкой и сохраняют множество промежуточных результатов (Dk[∗], Ek[∗]). Для каждой р, Dk[p] является низкой аппроксимацией rp на итерации k, т. е Dk[p](q) ≤ rp(q) для всех q ∈ V. Мы строим решения Dk[p] (k = 0, 1, 2, . . .), которые имеют лучшую аппроксимацию к rp, и одновременно вычисляют компоненты ошибки Ek[p], где Ek[p], является «проекцией» вектора (rp − Dk[p]) на базисные вектора. То есть, мы сохраняем инвариант для всех k ≥ 0 и для всех p ∈ V,
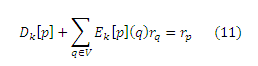
Таким образом, Dk[p]является низкой аппроксимацией rp с ошибкой |Σq∈VEk[p](q)rq|= |Ek[p]|. Мы начинаем с того, что D0[p] = 0 и E0[p] = xp таким образом, что становится логичным, что изначально аппроксимация равна 0, а ошибкой является rp. Для эффективного хранения Ek[p]и Dk[p], мы можем при реализации представить их как список их ненулевых элементов. Хотя все три алгоритма используют эти промежуточные результаты, они различаются в том, как каждый из них использует Теорему Разложения для уточнения промежуточных результатов в последовательных итерациях. Важно отметить, что алгоритмы, представленные в этом подразделе, и их производные в подразделе 5.3 вычисляют вектора с произвольной точностью (без аппроксимации). На практике желаемая точность может изменяться в зависимости от применения. Мы делаем упор на алгоритмы, которые являются эффективными и масштабируются с количеством векторов хабов, независимо от точности, с которой вычисляются вектора.
5.2.1 Базовый алгоритм динамического программирования
В базовом алгоритме динамического программирования, новый базисный вектор для каждой страницы p вычисляется на каждой итерации с помощью векторов, вычисленных для исходящего окружения страницы р на предыдущей итерации с помощью Теоремы Разложения. На итерации k, получаем (Dk+1[p], Ek+1[p]) от (Dk[p], Ek[p]) с помощью уравнений:
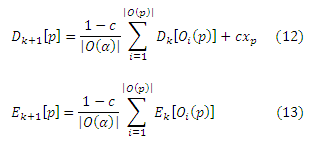
Доказательство корректности алгоритма приведено в приложении Е, где показана ошибка |Ek[p]|, которая уменьшается коэффициентом 1−c на каждой итерации. Заметим, что хотя значения Ek[∗]помогают нам увидеть корректность алгоритма, они не используются в расчетах Dk[∗] и их можно опустить в реализации (хотя они будут использоваться для вычисления парциальных величин в подразделе 5.3). Размеры Dk[р] и Ek[P] увеличиваются с числом итераций, и в пределе они достигают размера rp, который является количество страниц доступных р. Промежуточные значения (Dk[∗], Ek[∗]), вероятно, будут гораздо большими, чем объем доступной основной памяти, а в реализации (Dk[∗], Ek[∗]) можно считать с диска и (Dk+1[∗], Ek+1[∗]) записывается на диск на каждой итерации. Когда данные для одной итерации вычислены, данные из предыдущей итерации могут быть удалены. Конкретные детали нашей реализации обсуждаются в Разделе 6.
5.2.2 Алгоритм избирательного распространения
Алгоритм избирательного распространения главным образом является версией упрощенного алгоритма, который можно полностью модифицировать, чтобы вычислить частичные вектора, как мы увидим в подразделе 5.3.1. Выведем (Dk+1[p], Ek+1[p]) при помощи «разбрасывания» ошибки по каждой странице q (то есть, Ek[p](q)) для ее исходящего окружения по Теореме Разложения. Точнее, мы вычисляем результаты на k-итерации по формулам:
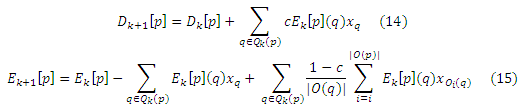
Для подмножества Qk(p) ⊆ V. Если Qk(p) = V для всех k, то ошибка снижается на коэффициент 1–c на каждой итерации, как в базовом алгоритме динамического программирования. Однако часто полезно выбирать выделенное подмножество V как Qk(р). Например, если Qk(р) содержит m страниц q, для которых ошибка Ek[p](q) является самой высокой, тогда эта топ-m схема устанавливает предельное число разложений и задерживает рост промежуточных результатов по размеру, в то же время, снижая значение ошибки. В подразделе 5.3.1, мы вычислим вектора хабов, выбрав Qk(p) = H. Справедливость избирательного распространения доказана в Приложении F.
5.2.3 Алгоритм быстрого возведения в степень
Алгоритм быстрого возведения в степень похож на алгоритм избирательного распространения, за исключением того, что вместо распространения (Dk+1[∗], Ek+1[∗]) с одним шагом с использованием уравнений (14) и (15), мы вычисляем, по существу, итерацию-2k результатов с использованием уравнений:
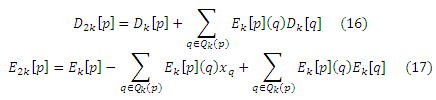
где Qk(p) ⊆ V. Пока мы можем предположить, что Qk(p) = V для всех р; мы установим Qk(p) = H для вычисления скелета хабов в подразделе 5.3.2. Правильность этих уравнений доказана в приложении G, где показано, что быстрое возведение в степень минимизирует ошибки гораздо быстрее, чем базовый алгоритм динамического программирования или алгоритмы избирательного распространения. Если Qk(p) = V, то ошибка возводится в квадрат на каждой итерации, а уравнение (17) сводится к:
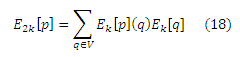
В качестве альтернативы принимаем Qk(p) = V. Мы также можем использовать схему с максимальным m (подраздел 5.2.2). Стоит отметить, что в то время как все три представленных алгоритма могут использоваться для вычисления множества всех базисных векторов, они отличаются своими требованиями по вычислению других векторов при вычислении rp: базисный алгоритм динамического программирования требует также вычисления векторов исходящего окружения со страницы р, алгоритм быстрого возведения в степень требует вычисления результатов (Dk[q], Ek[q]) для q таким образом, что Ek[p](q) > 0, а избирательное распространение вычисляет rp независимо.
В подразделе 5.2 представлены итеративные алгоритмы вычисления полных базисных векторов с произвольной точностью. Представляем вам модификации этих алгоритмов для вычисления парциальных величин:
Каждую парциальную величину можно вычислить по времени, не превышающей ее размер, который намного меньше размера векторов хабов.
5.3.1 Частичные вектора
Частичные вектора можно вычислить с помощью простой специализации алгоритма избирательного распространения (подраздел 5.2.2): Q0(p) = V и Qk(p) = V – H для k > 0, для всех p ∈ V. Это значит, что мы никогда не «раскладываем» страницы хабов после первого шага, поэтому маршруты, проходящие через страницу хаба H, никогда не принимаются во внимание. При таком выборе Qk(p), Dk[p] + cEk[p] сходится к (rp − rpH) для всех p ∈ V. Конечно, вычисляются только промежуточные результаты (Dk[p], Ek[p]) для p ∈ H. Доказательство приведено в Приложении H. Этот алгоритм дает понять, почему использование страниц с высоким PageRank в качестве хабов улучшает поиск: мы ожидаем перейти от страницы р к странице с высоким PageRank q быстрее, чем к любой случайной странице, так что разложение от р остановится раньше и приведет к образованию более короткого частичного вектора.
5.3.2 Скелет Хабов
Скелет хабов является подмножеством сетевого скелета и может быть вычислен с использованием алгоритмов, которые будут представлены в подразделе 5.3.3. Его можно вычислить гораздо быстрее, если мы не заинтересованы в вычислении полного сетевого скелета, или если желательна более высокая точность для скелета хабов, чем по всему сетевому скелету. Мы используем специализацию алгоритма быстрого возведения в степень (подраздел 5.2.3) для вычисления скелета хабов с использованием промежуточных результатов вычисления частичных векторов. Предположим, что(Dk[p], Ek[p]), для k ≥ 1, были рассчитаны по алгоритму, описанному в подразделе 5.3.1 так, что для некоторой ошибки ε
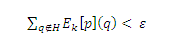
Мы применяем алгоритм быстрого возведения в степень для этих результатов, используя Qk(p) = H для всех последовательных итераций. Как показано в Приложении I, после i итераций быстрого возведения в степень, общая ошибка |Ei[p]| ограничена (1 − c)2i + ∊/c. Таким образом, изменяя k и i, rp(H) можно вычислить с произвольной точностью. Заметьте, что только промежуточные результаты (Dk[h], Ek[h]) для h ∈ H, которые иногда необходимы для обновления значения Dk[p], и только элементы первого Dk[h](q), Ek[h](q), для q ∈ H, используются для вычисления Dk[p](q). Поскольку нас интересуют только значения хаба Dk[p](q), мы можем просто отбросить все элементы, не касающиеся хаба, из промежуточных результатов. Время вычисления и хранение зависят только от размера rp(H), а не от длины всех векторов хабов rp. Если ограниченные промежуточные результаты размещаются в основной памяти, то можно отложить вычисление скелета хабов до времени запроса.
5.3.3 Сетевой скелет
Чтобы вычислить сетевой скелет полностью, мы изменим базисный алгоритм динамического программирования (подраздел 5.2.1) для вычисления только значений хаба rp(H) с соответствующей экономией времени и памяти. Мы ограничиваем вычисление путем устранения элементов q ∉ H из промежуточных результатов (Dk[p], Ek[p]), аналогично методу, используемому при вычислении скелета хабов. Обоснованием для этой модификации является то, что значение хаба Dk+1[p](h) подвергается влиянию только значениям хаба Dk[∗](h) из предыдущей итерации так, что Dk+1[p](h) в модифицированном алгоритме равен значению базисного алгоритма. Поскольку |H|, вероятно, будет на порядок меньше чем n, размер промежуточных результатов существенно уменьшается.
Наконец, давайте посмотрим, как можно непосредственно построить PPV по вектору предпочтения u из частичных векторов и скелета хабов с использованием Уравнения Хабов. (Построение единого вектора хаба является специализацией алгоритма, описанной здесь.) Пусть u = α1p1 + ⋅⋅⋅ + αzpz будет вектором предпочтения, где pi ∈ H для 1 ≤ i ≤ z. Пусть Q ⊆ H, и пусть
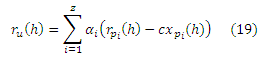
что можно вычислить из скелета хабов. Тогда PPV v для u можно построить как:
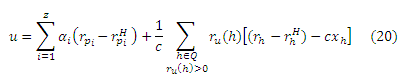
Оба условия (rpi − rpiH) и (rh − rhH) — частичные вектора, которые как мы приняли, были предварительно вычислены. Член cxh представляет собой простое вычитание из (rh − rhH). Если Q=Н, то уравнение (20) представляет собой полное построение v. Однако для некоторых применений будет достаточно использования только части скелета хабов, чтобы вычислить v с меньшей точностью. Например, мы можем принять, что Q будет m хабов h для которых ru(h) является наибольшим. Эксперименты с этой схемой будут обсуждаться в подразделе 6.3. С другой стороны, результат может быть улучшен постепенно (например, насколько позволяет время), используя небольшое подмножество Q, всякий раз аккумулируя полученные результаты.
Нами были проведены эксперименты на реальной коллекции данных Stanford’s WebBase [6] путем обхода веба, содержащего 120 миллионов страниц. Поскольку в итерационном вычислении PageRank не участвуют висячие страницы (то есть те, которые не имеют исходящих гиперссылок на свое ссылочное окружение), они могут быть удалены из графа, а потом добавлены обратно после нашего вычисления [10]. После удаления висячих страниц, наш граф состоял из 80 миллионов страниц. Веб-граф и промежуточные результаты(Dk[∗], Ek[∗]) были слишком велики, чтобы уместиться в оперативной памяти и была использована стратегия разбиения, основанная на данных, представленных в литературе [4], для разделения вычислений на порции, которые можно поместить в память. В частности, множество страниц V было разделено на k произвольных множеств P1, . . . , Pk одинакового размера (в наших экспериментах k = 10). Веб-граф, представленный в качестве списка ребер E, разбивается на k частей Ei (1 ≤ i ≤ k), где Ei содержит все ребра, для которых p ∈ Pi. Промежуточные результаты Dk[p] и Ek[p]были представлены в виде списка Lk[p] = <(q1, d1, e1), (q2, d2, e2), . . . >,где Dk[p](qz) = dz и Ek[p](qz) = ez, для z = 1, 2, . . . Были включены только страницы qz для которых либо dz> 0, либо ez> 0. Множество промежуточных результатов Lk[∗] было разбито на k2 частей Lk(i,j)[∗] так, что Lk(i,j)[p] содержало тройку (qz, dz, ez) из Lk[p], для которых p ∈ Pi и qz ∈ Pj. В каждом из алгоритмов вычисления парциальных величин, только один столбец Lk(*,j)[∗] хранился в памяти в любой фиксированный момент времени, а часть результатов следующей итерации Lk+1[∗] вычислялась путем последовательного считывания в отдельных компонентах графа или промежуточных результатах по необходимости. Каждая итерация требует только одного линейного сканирования промежуточных результатов и веб-графа, за исключением использования алгоритма быстрого возведения в степень, который явно не использует веб-граф.
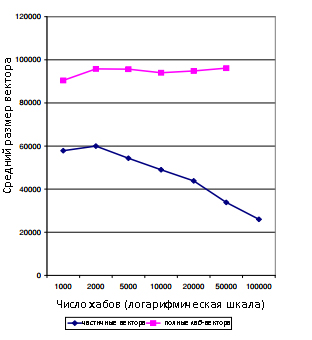
Рис. 2. Средний размер вектора в зависимости от количества хабов
Для сравнения, мы вычислили полные вектора хабов и частичные вектора для различных размеров H, используя алгоритм избирательного распространения с Qk(p) = V (полные вектора хабов) и Qk(p)=V−H (частичные вектора). Как отмечалось в подразделе 4.4.2, мы обнаружили, что метод с частичными векторами более эффективен в том случае, если H содержит страницы с высоким PageRank, а не просто случайные веб-документы. В наших экспериментах H колебалось от 1000 до 100 тысяч страниц с высоким PageRank. Постоянная c равнялась 0,15. Для оценки результатов и масштабируемости нашей стратегии независимо от реализации и платформы, мы ориентируемся на размер результатов, а не на время вычисления, которое линейно зависит от его размера. Из-за большого количества испытаний, которые мы должны были выполнить, и ограниченности ресурсов, мы вычислили результаты только до 6 итераций, при |H| до 100 тысяч. Рисунок 2 показывает средний размер (полных) векторов хабов и частичных векторов (напомним, что размер — это количество ненулевых элементов), который вычислен после 6 итераций алгоритма избирательного распространения, а для вычисления полных векторов хабов он эквивалентен алгоритму динамического программирования. Обратите внимание, что ось х на графике представлена в логарифмической шкале. Эксперименты были проведены с использованием процессора с частотой 1,4 ГГц на машине с объемом в 3,5 Гб памяти. Для |H| = 50 000, вычисление полных векторов хабов заняло около 2,8 секунды на вектор, и около 0,33 секунды на каждый частичный вектор. Нам не удалось вычислить полные вектора хабов для |H| = 100 000 в течение необходимого времени, хотя средний размер вектора, как ожидается, не изменяется значительно от |H| для полных векторов хабов. На рисунке 2 мы видим, что уменьшение размера при использовании нашего метода становится все более значительным при увеличении |H|, что свидетельствует о том, что наш метод хорошо масштабируется с |H|.
Мы вычислили скелет хабов |H| = 10, 000 при помощи алгоритма избирательного распространения для 6 итераций, используя Qk(p) = H, а затем использовали алгоритм быстрого возведения в степень для 10 итераций (подраздел 5.3.2), где Qk(p) выбрали как 50 лучших элементов по схеме top-m (подраздел 5.2.2). Средний размер скелета хабов равняется 9021 элементу. Каждая итерация алгоритма быстрого возведения в степень заняла около часа. Затраты времени зависят только от |H| и являются константой по отношению к точности, с которой вычисляются частичные вектора.
Затем мы проанализировали построение (полных) векторов хабов из частичных векторов и скелета хабов. Обратите внимание, что на практике мы можем построить PPV прямо из частичных векторов, как обсуждалось в подразделе 5.4. Тем не менее, построение в значительной степени будет зависеть от вектора предпочтений пользователя. Мы рассматриваем вычисление вектора хаба постольку, поскольку оно лучше показывает преимущество нашего подхода частичных векторов. Как отмечалось в подразделе 4.3, точность векторов хабов, построенных из частичных векторов, можно изменить во время исполнения запроса в зависимости от применения и требований к результату. То есть, вместо того чтобы использовать все множество rp(H) при построении rp, мы можем использовать только m элементы с самыми высокими значениями для m ≤ |H|. Рисунок 3 изображает средний размер и время, необходимое для построения полного вектора хаба из частичных векторов, в зависимости от m для |H| = 10 000. Результаты усреднены по 50 случайно выбранным векторам хабов. Следует отметить, что ось х представлена в логарифмической шкале.
Вспомним из подраздела 6.1, что частичные вектора, из которых состоят вектора хабов, были вычислены с использованием 6 итераций с предельной точностью. Таким образом, значения ошибок на рисунке 3 составляет примерно 16% (в пределах от 0,166 для m = 100 до 0,163 при m = 10,000). Тем не менее, эта ошибка намного меньше, чем при вычислении полных векторов хабов на 6 итерациях в подразделе 6.1, которые имеют ошибку (1 − c)6 = 38%. Однако следует отметить, что размер вектора является лучшим показателем высокой точности, чем его абсолютная величина потому, что, как правило, мы наиболее заинтересованы в числе страниц с ненулевыми элементами в векторе распределения. Полный вектор, вычисленный на 6 итерациях (из подраздела 6.1), для страницы р содержит ненулевые элементы для не более 6 ссылок, ведущих от р, что в среднем составляет 93993 страниц. В противоположность этому, на рисунке 3 видно, что вектор хаба, содержащий 14 миллионов ненулевых элементов, может быть построен из частичных векторов за 6 секунд.
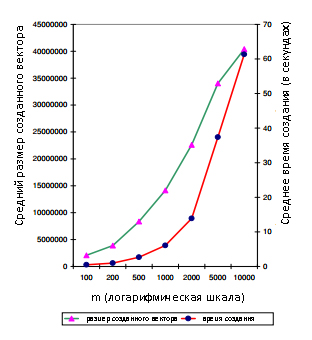
Рис.3.Среднее время построения и размер вектора в зависимости от части скелета хабов (m)
Использование персонализированного PageRank для персонализированного веб-поиска впервые было заявлено в работе [10], где он был предложен в качестве модификации алгоритма глобального PageRank, который вычисляет универсальное понятие авторитетности. Тогда вычисление значения (персонализированного) PageRank не было рассмотрено по причине использованной алгоритмической простоты. В работе [5], значение персонализированного PageRank использовались для создания веб-поиска, «чувствительного к тематической информации». В частности, заранее вычисленные вектора хабов, соответствующих общим категориям, представленных в Open Directory, были использованы для смещения показателей авторитетности, при котором вектора и веса выбирались в соответствии с текстом запроса. Эксперименты, описанные в работе [5],резюмировали, что использование значений персонализированного PageRank может улучшить веб-поиск, хотя на тот момент не учитывалось то, что эта модель может быть искажена технологиями продвижения сайтов, да и само количество использованных векторов хабов было ограничено до 16 в связи с вычислительными требованиями. Масштабирование более 16 хабов для более детальной персонализации является прямым приложением нашей работы. Другой метод вычисления важности веб-страницы — алгоритм HITS, был представлен в литературе [8]. В HITS итерационные вычисления близки по духу алгоритму PageRank и применяются во время выполнения запроса на подграфе, состоящим из страниц, соответствующих тексту запросу и близь отстоящих по смыслу. Персонализация, основанная на интернет-страницах, специфицируемых пользователем (и их ссылочной структуре веб-графа), не рассматривается алгоритмом HITS. Кроме того, количество страниц в подграфах, используемых в алгоритме HITS (порядка тысячи), намного меньше, нежели чем тот объем, что мы рассматриваем в этой статье (порядка миллионов), и вычисление с нуля в момент запроса в алгоритме HITS также плохо масштабируется. Другой алгоритм, который использует запросо-зависимые показатели авторитетности, чтобы улучшить глобальное значение важности, был представлен в работе [11]. Как и алгоритм HITS, он сначала ограничивает вычисление подграфом страниц, имеющего текстовую релевантность запросу. (Персонализация, базирующаяся на веб-страницах конкретного пользователя, не рассматривается.) В отличие от алгоритма HITS, в работе [11] авторы предположили, что значение важности необходимо вычислить заранее, оффлайново для каждого возможного текстового запроса, однако наличие огромного числа всевозможных вероятностей в такой модели делает этот подход трудно масштабируемым. Концепция применения на графе «хаб-узлов», использующая частично вычисленные решения в задачах облегчения поиска накратчайшего пути была реализована в работе [3] в контексте поиска по базе данных. Эта работа посвящена поиску по базах данных и масштабированию объектов, намного меньших, чем Глобальная паутина. Некоторые системные аспекты вычисления (глобального) PageRank были рассмотрены в работе [4]. Стратегия разделения данных на дисках, используемая в реализации нашего алгоритма, заимствованная оттуда. Наконец, концепция инверсивного P-расстояния, используемого в данной работе, основана на концепции ожидаемого- f расстоянии, которая приведена в работе [7], где она была представлена как интуитивная модель степени сходства в структурных особенностях графа.
Мы занялись решением проблемы масштабирования персонализированного веб-поиска:
Авторы благодарят Тахира Хавеливала за многочисленные полезные обсуждения и значительную помощь с реализацией.
Ссылки:
[1] google.com
[2] dmoz.org
[3] Roy Goldman, Narayanan Shivakumar, Suresh Venkatasubramanian, and Hector GarciaMolina. Proximity search in databases. In Proceedings of the Twenty-Fourth International Conference on Very Large Databases, New York, New York, August 1998.
[4] Taher H. Haveliwala. Efficient computation of PageRank. Technical report, Stanford University Database Group, 1999. dbpubs.stanford.edu/pub/1999-31.
[6] Jun Hirai, Sriram Raghavan, Andreas Paepcke, and Hector Garcia-Molina. WebBase: A repository of web pages. In Proceedings of the Ninth International World Wide Web Conference, Amsterdam, Netherlands, May 2000. www-diglib.stanford.edu/ ˜testbed/doc2/WebBase/.
[7] Glen Jeh and Jennifer Widom. SimRank: A measure of structural-context similarity. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, Alberta, Canada, July 2002.
[9] Rajeev Motwani and Prabhakar Raghavan. Randomized Algorithms. Cambridge University Press, United Kingdom, 1995.
[11] Matthew Richardson and Pedro Domingos. The intelligent surfer: Probabilistic combination of link and content information in PageRank. In Proceedings of Advances in Neural Information Processing Systems 14, Cambridge, Massachusetts, December 2002.
Теорема (Линейности). Для каких-либо векторов предпочтения u1и u2, если v1и v2являются двумя соответствующими PPV, то для каких-либо констант α1, α2 ≥ 0 так что α1 + α2 = 1,
Доказательство:
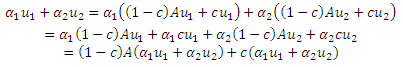
Теорема (Разложения). Для каких-либо p ∈ V,
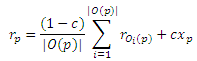
Доказательство: сначала перепишем уравнение (1) в эквивалентной форме. Для данного вектора предпочтения u, определим производную матрицу Au как
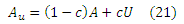
где U является n х n матрицей с Uij = ui для всех i,j. Если мы потребуем, чтобы |u| = 1, мы можем записать уравнение (1) как
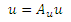
Не уменьшая общности, пусть соседние исходящие ссылки p будут 1, . . . , k. Пусть Ap будет производной матрицей, соответствующей xp, и пусть A1, . . . , Ak будут производными матрицами для u = x1, . . . , xk, соответственно. Пусть Up и U1, . . . , Uk соответствуют U в уравнении (21). Пусть
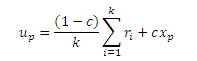
Ясно, что |vp| = 1. Нам необходимо показать, что Apvp = vp, в таком случае vp = rp, так как PPV уникальный (Раздел 1). Первое, что мы имеем:
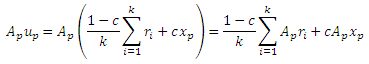
Используя тождественность
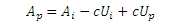
Получаем:
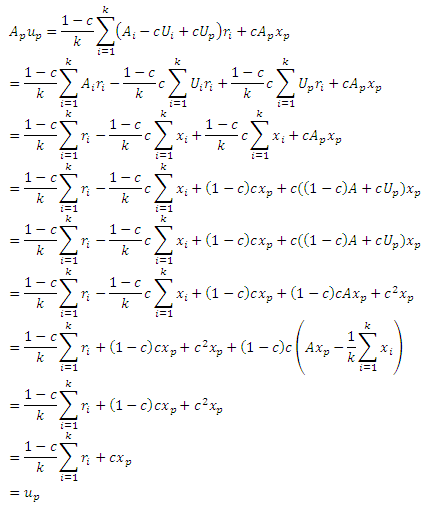
C.1 Взаимосвязь с персонализированным PageRank
Взаимосвязь между инверсивным P-расстоянием и значением персонализированного PageRank описывается следующей теоремой:
Теорема. Для всех p,q ∈ V,
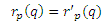
Доказательство: записывая Теорему Разложения в скалярной форме для страницы p, мы получим систему n уравнений, по одному для каждого q ∈ V, в таком виде
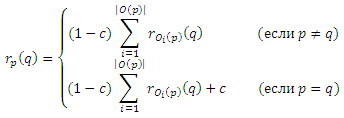
Зафиксируем теперь q и рассмотрим систему n уравнений, по одному для каждого p ∈ V в приведенной выше форме. Согласно доказательству очень похожему на приведенные в работе [7], можно доказать, что эти уравнения имеют единственное решение, так что нам нужно только показать, что r’p(q) также удовлетворяет этим уравнениям. Ясно, что если не существует пути от p к q, то rp(q) = r’p(q) = 0, и вероятно к q можно добраться от p. Рассмотрим маршруты t, начинающиеся в p и заканчивающиеся q, в которых первым шагом является соседняя исходящая ссылка Oz(p). Если p≠q, то существует взаимно-однозначное соответствие между такими t и маршрутами t’ из Oz(p) к q: для каждого t’ мы можем получить соответствующий t, добавляя в начале ребра < p, Oz(p) >. Пусть Т будет биекцией, которая принимает каждый t’ к соответствующему t. Если длина t’ равняется l, то длина t = T(t’) является l+1. Более того, вероятность перемещения t выражается как P[t] =(1/|O(p)|)P[t’]. Теперь можно разбить сумму в уравнении (5) в соответствии с первым шагом маршрута t и записать
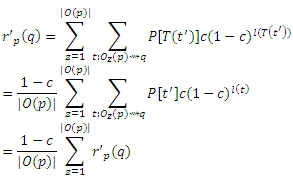
Если p = q, то имеет место тоже соответствие за исключением того, что присутствует дополнительный маршрут t от р к q = p, который не соответствует никаким маршрутам t’, начиная с Oz(p): маршрута нулевой длины t’ = ‹p›. Длина этого маршрута равна 0, и в этом случае P[t]c(1 − c)l(t) = c. Таким образом:
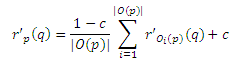
если p = q.
C.2 Фактор петли
Использование инверсивного P-расстояния дает нам понять справедливость значения PageRank. Поскольку глобальный PageRank для страницы q является просто равномерной суммой ∑n(p=1)rp(q)/n, мы видим, что PageRank страницы q является средним для всех страниц р, инверсным P-расстоянием от p к q. Интуиция подсказывает, что страницы с высоким PageRank в среднем «близки» к другим страницам в соответствии с настоящей мерой расстояния. Тем не менее, отметим, что суммирование в уравнении (5) берется по маршрутам, которые могут соприкоснуться с q несколько раз. Результат состоит в том, что страница q может влиять на ее собственный PageRank (менее чем 1/с раз) простым изменением ее исходящих ссылок. В частности, если страница q с PageRank PR(q) ссылается на каждую страницу р, для которой существует путь к q (как логически созданный для страниц без исходящих ссылок в работах [5, 10]), то ее PageRank будет иметь коэффициент c + (1 −c)PR(q), который меньше, чем если бы она ссылалась на саму себя и не на какие другие страницы. Этот «фактор петли» может быть определен количественно как rq(q): в соответствии с определением того, что маршруты t от p к q могут касаться q только один раз, rp(q) можно записать в виде:
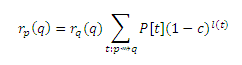
где суммирование не зависит от исходящих ссылок q. Это является ожидаемым- f расстоянием в работе [7] от p к q для f(x) = (1 − c)x. Подобное исключение петельного фактора (делением на rq(q), чтобы получить ожидаемое- f расстояние) может привести к более справедливому значению.
Теорема (Хабов). Для любых p ∈ V, H ⊆ V,
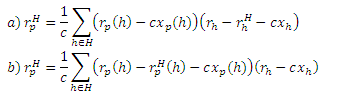
Доказательство (a): Идея состоит в том, чтобы разделить маршруты t, проходящие через H, на две части, все вплоть до последнего обнаружения страницы h ∈ H, и остальные. Пусть β(t), для маршрутов t: p ∼> H ∼> q, обозначает начало t до последнего обнаружения страницы h ∈ H, через которую проходит t, так что β(t) = <p, . . . , h>. Пусть γ(t) будет остальными маршрутами, так что γ(t) = <h, . . . , q>. Пусть π(t) = P [t]c(1 − c)l(t) для краткости. Пусть s(t) будет множеством страниц, через которые проходит t, так что rpH(q) можно записать в виде:
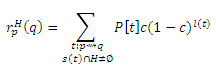
Давайте просуммируем первое разбиение в уравнении (6) согласно β(t):
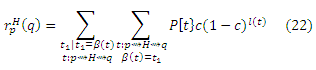
Для каждого t, β(t) является самим по себе маршрутом t’ : p ∼> h; и, наоборот, каждый t’ : p ∼> h является β(t) для некоторого t, за исключением маршрута нулевой длины t’ = <p> в частном случае, когда p ∈ H. Таким образом, мы можем сгруппировать маршруты по h и β(t), заканчивающихся в h, чтобы переписать уравнение (22) так:
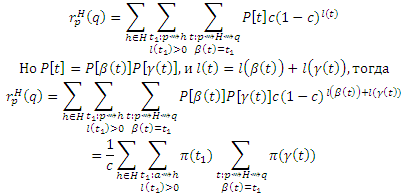
Существует каноническая биекция γt1 между маршрутами t : p ∼> H ∼> q с β(t) = t1 и маршрутами t’ : h ∼> q, которые не проходят через H (для которых s(t’) ∩ H = ∅), за исключением маршрутов нулевой длины <q> если q ∈ H. То есть, γt1(t) = γ(t) = t’, поэтому мы можем записать каждый маршрут t как t=γt1-1(t’). Замещая γ(t) в предыдущем γ(t) = γ(γt1-1(t’))=t’ и учитывая возможных маршрутов нулевой длины, получаем:
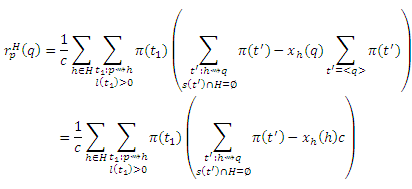
Но множество маршрутов t из h к q, которые не проходят через H, равняются множеству маршрутов от h к q минус множество маршрутов от h к q, которые проходят через H. Таким образом,
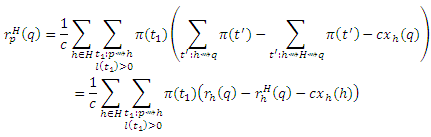
В результате,
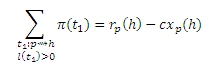
где cxp(h) учитывает возможность маршрутов t1= <p>, если p = h, для которых P[t1]c(1−c)l(t1) = c, и получаем:
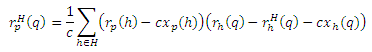
Это уравнение, записанное в векторной форме, является Теоремой (a).
Доказательство (b): Идея состоит в том, чтобы разделить маршруты t, которые проходят через H иначе: все, вплоть до первого (вместо последнего) обнаружения страницы h ∈ H, и остальные. Пусть β(t), для маршрутов t : p ∼> H ∼> q, обозначает начало t при первом обнаружении страницы h ∈ H, через которую проходит t, так что β(t) = <p, . . . , h>. Пусть γ(t) будет остальными маршрутами, так что γ(t) = <h, . . . , q>. Просуммируем первое разбиение в уравнении (6) согласно γ(t):
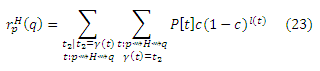
Для каждого t, γ(t) является самим по себе маршрутом t’: h ∼> q; и, наоборот, каждый t’: h ∼> q является γ(t) для некоторого t, за исключением маршрута нулевой длины t’ = <q> в частном случае, если q ∈ H. Таким образом, мы можем сгруппировать маршруты t по h и γ(t), начинающихся в h, чтобы переписать уравнение (23) как:
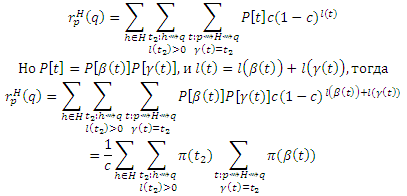
Существует каноническая биекция между βt2 маршрутами t : p ∼> H ∼> q с γ(t) = t2 и маршрутами t’ : a ∼> h, которые не проходят через H (для которых s(t’) ∩ H = ∅), за исключением маршрута нулевой длины
если p ∈ H. То есть, βt2(t) = β(t) = t’, поэтому мы можем записать каждый маршрут t как t = βt2-1t’). Замещая β(t) в предыдущем уравнении β(t) = β(βt1-1(t’)) = t’ и учитывая возможность маршрута нулевой длины, получаем:
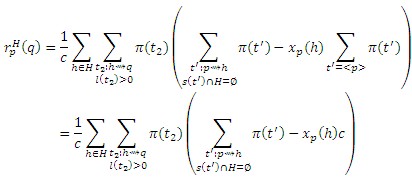
Но множество маршрутов t от p к h, которые не проходят через H, является множеством маршрутов от p к h минус множество маршрутов от p к h, которые проходят через H. Таким образом,
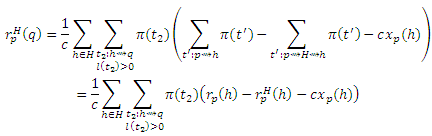
В результате,
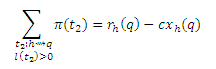
где cxh(q) учитывает возможность маршрута t2 = <q>, если q = h, для которого P[t2]c(1−c)l(t2) = c, и получаем
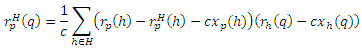
Это уравнение, записанное в векторной форме, является Теоремой Хабов (b).
Чтобы доказать корректность базового алгоритма динамического программирования, нам нужно показать, что для всех k ≥ 0 и p ∈ V, Dk[p]+Σq∈VEk+1[p](q)rq = rp, и что последовательность {Ek[P]} сходится к 0, как k стремится к бесконечности, откуда следует, что Dk[p] сходится к rp. Так, в частности, |Ek[p]| = (1 − c)k. Доказательство по индукции по k. Случай для k = 0 очевидный, поэтому предположим, что утверждение верно для k при некотором k ≥ 0. Сначала покажем, что Dk+1[p] + Σq∈VEk+1[p](q)rq = rp:
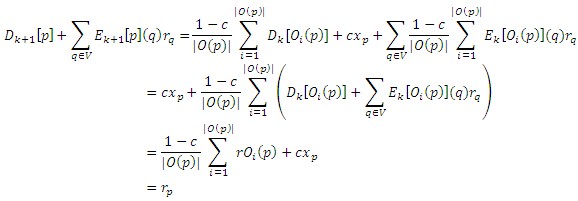
где последний шаг является обоснованием Теоремы Разложения. Теперь покажем, что |Ek+1[p]| =(1 − c)k+1:
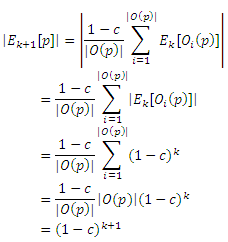
Как и в доказательстве базового алгоритма динамического программирования, сперва мы покажем, что Dk+1[p] + Σq∈VEk+1[p](q)rq = rp для любых произвольных Qk(p) ⊆ V:
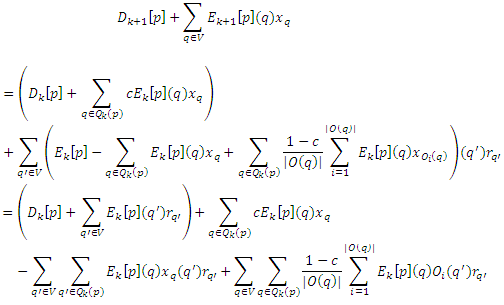
Согласно предположению индукции,
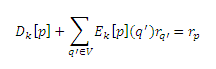
Так что нам необходимо всего лишь показать, что последние члены сокращаются. Так, что xq(q’) = 1, если q = q’ и 0 в противном случае, и подобно для xOi(q)(q’), получаем:
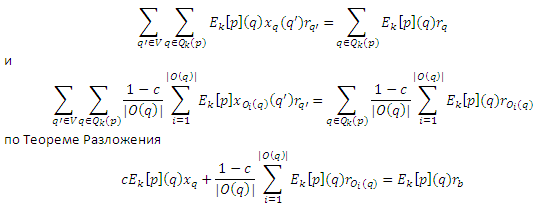
для всех q ∈ Qk(p), что показывает, что члены действительно сокращены. Поскольку |Dk[p]| увеличивается сΣq∈Qk(p)Ek[p](q) на каждой итерации, ошибка уменьшается на каждом ее шаге cΣq∈Qk(p)Ek[p](q) соответственно. Таким образом, любой выбор Qk(p), содержащий максимальную страницу q так, что Ek[p](q) = max{Ek[p](q) | q ∈ V} гарантирует, что ошибка стремится к 0. В частности, так обстоит дело, если Qk(p) = V или Qk(p) является топ m > 0 страниц q с самым высоким Ek[p](q).
Чтобы проверить правильность алгоритма быстрого возведения в степень, покажем, что
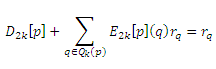
Для произвольного Qk(p) ⊆ V:
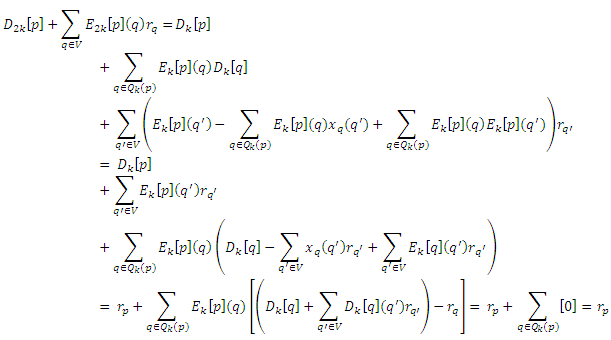
Как и в случае с доказательством алгоритма избирательного распространения, ошибка стремится к 0, если Qk(p) содержит топ m > 0 страниц q с наивысшим Ek[p](q). Если Qk(p) = V, ошибка является квадратичной на каждой итерации, если бы |Ek[∗]| = ε, используя уравнение 18 получаем:
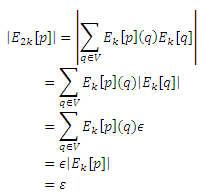
Ясно, что для первых двух итерациях, быстрое возведение в степень уменьшает ошибку больше, чем коэффициент затухания 1−c (для алгоритмов динамического программирования и избирательного распространения) если Qk(p) = V.
Сначала покажем, что следующее относится ко всем k ≥ 1 и p, q ∈ V:
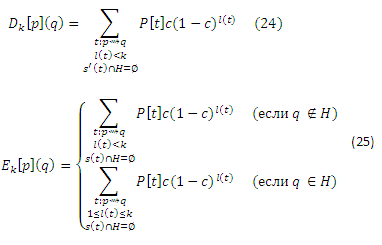
где s(t) является множеством страниц, которые появляются на t но не на концах (например, страницы, через которые проходит t) и s'(t) является множеством страниц, которые появляются на t но не в начале. Рассмотрим случай при к = 1 (напомним, что все страницы разложены на итерации 0). Только маршруты в уравнении (24) являются маршрутами нулевой длины t = <p> при p = q (которые не проходят через хабы), для которых P[t]c(1 − c)l(t) = c = D1[p](q). Только маршруты в уравнении (25) являются t = <p, q>, если q является исходящей соседней ссылкой р, для которой P[t](1 − c)l(t) = 1-c/|O(p)| = Ek[p](q). Теперь предположим для индукции, что уравнения (24) и (25) справедливы для некоторого k ≥ 1. Согласно уравнению (14) с Qk(p)=V−H, разница Dk+1[p](q) и Dk[p](q) для q ∉ H, равняется Dk+1[p](q)−Dk[p](q) = cE1[p](q). Согласно предположению индукции, эта разница может быть записана в виде:
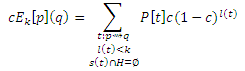
Так как q ∉ H, ограничение s(t) ∩ H = ∅ эквивалентно s'(t) ∩ H = ∅, так что
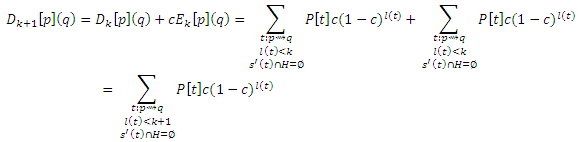
Если q ∈ H,
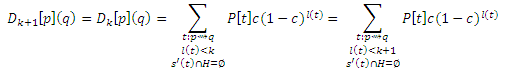
Так как здесь присутствует маршрут t: p ∼> q с l(t) > 0 для которого s'(t) ∩ H = ∅. Далее покажем, что
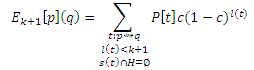
для q ∈ H. Согласно уравнению (15) с Qk(p) = V − H, получаем:
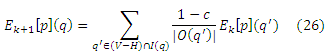
так как только разложение входящих соседних ссылок q может внести вклад в Ek+1[p](q), и из них будут разложены только те, которые не принадлежат H. Разложение Ek[p](q’) с помощью индукции (26) равняется
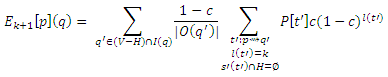
где мы заменили s(t’) в суммировании с s'(t́), так как q’ ∉ H. Мы хотим показать, что это равняется
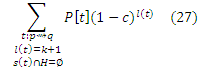
Рассмотрим множество маршрутов t : p ∼> q с l(t) = k + 1 и s(t) ∩ H = ∅, для которых последним шагом является переход от q’ ∈ (V − H) ∩ I(q) к q. Существует взаимно-однозначное соответствие между такими t и маршрутами: t’ : p ∼> q’ длины k с s’(t) ∩ H = ∅: для каждого t’ мы можем получить соответствующий t, добавляя ребра <q’,q> в конце. Пусть Т является биекцией, которая принимает каждый t’ к соответствующему t. Если длина t’ равняется l, то длина t = T (t’) есть l + 1. Более того, вероятность перехода t равняется P [t] = (1/|O(q’)|)P[t’]. Таким образом, мы можем разделить суммирование в уравнении (27) в соответствии с q’, чтобы записать его в виде:
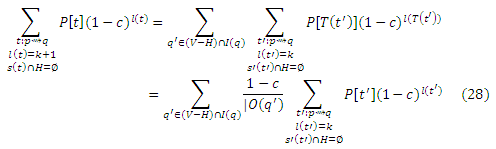
Именно в таком виде мы и хотели представить это уравнение. Покажем, что
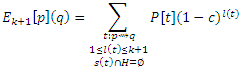
для q ∈ H. Согласно уравнению (15) с Qk(p) = V − H,
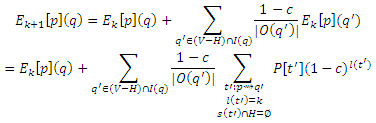
Все еще применяя Уравнение (28) получаем
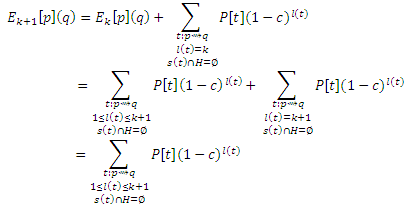
Что завершает доказательство уравнений (24) и (25).
Наконец, покажем, что для всех q ∈ V, Dk[p](q)+cEk[p](q) сходится к rp(q)−rpH(q) как k→∞. Если q ∉ H, тогда Ek[p](q) → 0 как k → ∞, и
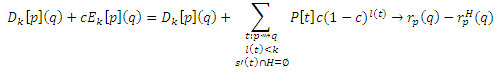
так как s’(t) ∩ H = s(t) ∩ H при q ∉ H. Если q ∈ H, то
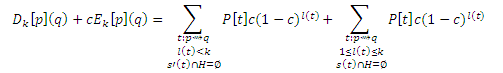
Если q ∈ H, s’(t) ∩ H ≠∅ за исключением случаев p = q и t = <p>. Следовательно,
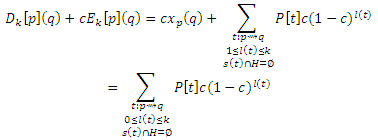
что сходится к rp(q)−rpH(q) как k → ∞.
Пусть (Di[p], Ei[p])обозначает результаты после i итераций быстрого возведения в степень, так что промежуточные результаты избирательного разложения соответствуют i = 0. Ошибка, первоначально ассоциированная со хаб-страницами Σh∉HE0[p](h) ограничена 1 – c потому что первый шаг избирательного разложения разлагает все страницы (подраздел 5.2.2). Согласно уравнению (17) с Qi(p)=H, ошибка, ассоциированная с хаб-страницами на итерации i ≥ 1 быстрого возведения в степень Σq∈HEi[p](q) ограничена (1−c)2i. Кроме того, ошибка, ассоциированная с не-хаб страницами Σq∉HEi[p](q) увеличивается не более чем на (1 − c)2i Σq∉HEi−1[p](q) по сравнению с предыдущей итерацией. Использование геометрической прогрессии к ограничению Σq∉HEi[p](q), общая ошибка |Ei[p]| итерации i ограничена (1 − c)2i + ε/c.
[1] Данная работаполучила грант Национального научного фонда IIS-9817799.
[2] В частности, v соответствует стационарному распределению эргодической апериодической цепи Маркова.
[3] Точнее, преобразование векторов персонализации u в их соответствующие вектора решения v является линейным.
[4] Обратите внимание, что в то время как математические и вычислительные алгоритмы представлены в этой статье в контексте веб-графа, они дают общие графо-теоретические результаты, которые можно применять в других сценариях, связанных со стохастическими процессами, среди которых PageRank является одним из примеров.
[5] Здесь определение инверсивных P-расстояний несколько отличается от концепции ожидаемого f–расстояния, описанного вработе [7], где маршруты не могут посещать q несколько раз. Заметьте, что общее ожидаемое f–расстояние, которое имеют вид ΣtP[t]f(l(t)); в нашем определении выражается так: f(x) = c(1 − c)x.
Перевод материала «Scaling Personalized Web Search» выполнил Сергей Неиленко
Полезная информация по продвижению сайтов:
Перейти ко всей информации