SEO-Константа
Яндекс.Директ + оптимизация
Настоящая работа посвящена извлечению ссылочного спама (в том числе, ссылочных ферм и обмена гиперссылками между веб-сайтами) из выборки форумов по поисковой оптимизации (SEO). Для того чтобы обеспечить высокое качество предоставляемых услуг, системам информационного поиска крайне важно идентифицировать поисковый спам. Ряд таких анти-спам технологий, как алгоритм TrustRank, BadRank и SpamRank были разработаны исключительно для решения упомянутой задачи. Посредством обнаружения определенных гиперссылочных паттернов, большинство из этих методологий пытаются минимизировать тот эффект, который оказывают на результаты органической выдачи некачественные интернет-ресурсы. Однако сейчас мы наблюдаем появление тех спам-сайтов, которые все в большей степени имитируют гиперссылочную структуру ординарных или даже хороших сайтов, посредством модификации применяемых ими манипулятивных схем. Вследствие чего, задача их автоматической идентификации на веб-графе становится крайне трудоемкой. В текущей работе мы предлагаем иной подход к обнаружению поискового спама, который вычисляет ссылочный спам посредством наблюдения за тем, как взаимодействуют между собой спамеры при создании схем манипуляции алгоритмами гиперссылочного анализа. Мы обнаружили, что для достижения своих индивидуальных целей веб-спамеры обычно объединяются в комьюнити, а SEO-форумы выступают в качестве одного из основных средств (или, можно сказать, площадок) для формирования подобного рода альянсов. Исходя из этого предположения, мы предлагаем извлекать подозрительные гиперссылки напрямую из тех постов, что создаются на SEO-форумах. Тем не менее, указанная задача представляется нетривиальной по той простой причине, что кроме тех подсказок, которые указали бы нам на гиперссылочный спам, размещаемая в тех постах информация может содержать прочие, не интересующие нас данные или даже различного рода шум. Для ее реализации мы, для начала, извлечем все URL-адреса, содержащиеся в созданных постах на SEO-форумах. Вторым шагом является извлечение особенностей URL-адресов, на основании тех сообщений, в которых они фигурируют, авторов постов (потенциальных спамеров), а также гиперссылочной структуры, сформировавшейся вокруг заданных URL на реальном веб-графе. В-третьих, мы создали фреймворк, в основе которого лежит полуконтролируемое обучение, для расчета спам-оценок, присуждаемых URL-адресам, который кодирует ряд таких эвристик, как, например, наличие аппроксимирующей изоляции среди хороших веб-сайтов, которые редко ссылаются на некачественные ресурсы, в то время как некачественные сайты имеют тенденцию к активному цитированию себе подобных. Мы протестировали наш подход на семи наиболее популярных форумах, посвященных поисковой оптимизации. Нами было идентифицировано большое количество спам-ресурсов, существенная часть из которых не могла быть обнаружена традиционными анти-спам методологиями. Это свидетельствует о том, что предложенный нами подход может быть хорошим дополнением к уже существующим технологиям противодействия поисковому спаму.
Возрастающая необходимость увеличивать видимость коммерческих интернет-ресурсов в системах информационного поиска привела к возникновению различных спам-технологий [8]. К поисковому спаму относятся действия, нацеленные на манипуляцию алгоритмами ранжирования и приводящие к незаслуженному увеличению позиций одной или нескольких страниц в результатах органической выдачи по определенным пользовательским запросам. Очевидно, что поисковый спам доставляет неудобства как самим интернет-пользователям, так и поисковым системам. Среди различных манипулятивных практик особенно выделяется ссылочный спам [8], включающий в себя обмен гиперссылками между сайтами и создание ссылочных ферм, который широко распространен в среде поисковой оптимизации и которой относительно трудно поддается вычислению на автоматическом уровне. Его широкое применение отчасти объясняется тем, что в поисковых машинах крайне важную роль играет анализ гиперссылочной структуры, а частично тем фактом, что подобные махинации со структурой ссылочного графа не столь заметны для рядовых пользователей систем информационного поиска, нежели чем манипуляции с содержимым веб-сайтов. Для противодействия ссылочному спаму и уменьшения его давления на результаты органического поиска были предложено множество анти-манипулятивных технологий, в том числе такие ссылочные алгоритмы как TrustRank [11], BadRank [15] и SpamRank [2]. Большинство из них пытаются идентифицировать определенные гиперссылочные паттерны, указывающие на поисковый спам. Однако, как было отмечено в [19], сегодня, с учетом эволюции запрещенных технологий поисковой оптимизации и продвижения сайтов, появляются такие некачественные ресурсы, которые все в большей степени имитируют гиперссылочную структуру ординарных или даже качественных веб-сайтов. Например, вместо создания плотносвязанных ферм локального масштаба с целью улучшения видимости целевых страниц в результатах органической выдачи, спамеры могут объединяться с достаточно большим числом других оптимизаторов для формирования «глобальной» ссылочной фермы, с топологией и распределением степеней практически ничем не отличимых от естественных веб-сайтов. Вследствие чего, задача вычисления ссылочного спама на реальном веб-графе становится все более трудоемкой. Для решения этой проблемы в нашем исследовании предлагается отличный подход, позволяющий идентифицировать ссылочный спам. В его основе положена идея, предполагающая не столько фокусировку на том, насколько гиперссылочная структура некачественных сайтов схожа по своей форме, сколько смещающая акцент на сам процесс ее формирования. Согласно предыдущим исследованиям [19], для улучшения видимости целевого веб-сайта очень часто поисковые оптимизаторы работают сообща, вместо того, чтобы заниматься его выводом на первую страницу органической выдачи поодиночке, с использованием только своих собственных ограниченных ресурсов. Существуют определенные сообщества, в которых спамеры могут обмениваться опытом и ресурсами, а также проводить свое время в обсуждении манипулятивных технологий. К числу виртуальных сообществ спамеров можно отнести такие форумы по поисковой оптимизации (SEO) как Digital Point, а также некоторые форумы по веб-мастерингу, которые также содержат ветки для обсуждения SEO или спам-технологий. Данные форумы предоставляют поисковым оптимизаторам площадку для поиска партнеров по обмену гиперссылками, а также для развития ссылочных ферм.

Рисунок 1. Пример топика, взятого с форума по поисковой оптимизации.
На Рисунке 1 мы приводим очевидный пример поиска партнеров по обмену ссылками, который был взят с форума Digital Point. Здесь можно увидеть, что пользователь форума опубликовал топик, в котором он предлагает обменяться ссылками с его/ее веб-сайтом, а ряд других пользователи далее отвечают на его/ее запрос. В ответах некоторых форумчан фигурируют URL-адреса на их собственные веб-сайты, в то время как прочие пользователи предпочли поделиться с топикстартером ссылкой на свой интернет-ресурс посредством отправки личного сообщения (использована аббревиатура «ЛС.»). Отметим, что в приведенном примере»PR» обозначает тулбарное значение Google PageRank. Например, PR3 означает, что показатель голосующей способности страницы по данным тулбара Google составляет 3. При дальнейшем исследовании мы обнаружили, что относительно этого топика действительно был осуществлен обмен ссылками между некоторыми сайтами, в том числе mobicreed.com (Пост #1) и thebestdigital.com (Пост #2), что отражено на Рисунке 2.
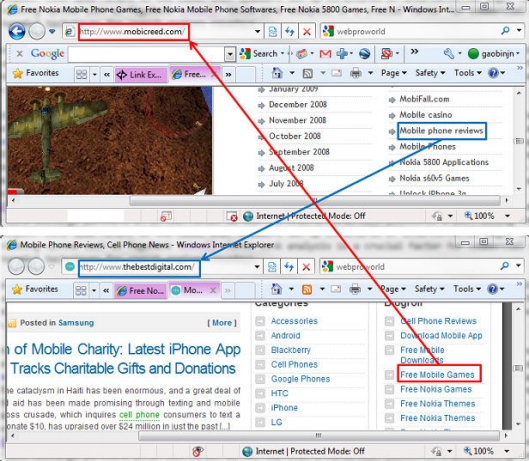
Рисунок 2. Пример состоявшегося ссылочного обмена между веб-сайтами
Помимо приведенного выше примера, мы также обнаружили несколько случаев формирования ссылочной фермы, а также простой торговли гиперссылками. Во всех этих случаях, владельцы веб-сайтов, публикуя свои сообщения на форумах, стремились увеличить показатели своих интернет-проектов с помощью запрещенных ссылочных технологий. Некоторые вебмастера успешно достигали своих целей, в то время как другие терпели фиаско в силу ряда причин. Однако засвидетельствованные нами веб-сайты могут рассматриваться как недобропорядочные постольку, поскольку их владельцы по крайней мере пытались совершить противоправные (на худой конец, нечестные) действия по отношению к алгоритмам ранжирования и тем сайтам, которые продвигаются легальными способами. В том случае, если мы сумеем извлекать указанные интернет-ресурсы из форумов по поисковой оптимизации, мы получим коллекцию сайтов, которые потенциально используют гиперссылочный спам. По мере быстрого увеличения количества SEO-форумов [19], мы также должны быть в состоянии собирать большое разнообразие ссылок, подозреваемых в участии в манипулятивных схемах. Так как подавляющая доля этих спам-сайтов не может быть вычислена традиционными анти-спам алгоритмами (что будет продемонстрировано в ходе наших экспериментов, которым посвящен Раздел 5), де-факто мы предлагаем метод, дополняющий уже существующие анти-спам технологии. Однако задача аккуратного извлечения спам URL 3 из форумов по поисковой оптимизации является нетривиальной. Первая причина ее нетривиальности заключается в том, что далеко не все URL-адреса, размещаемые в постах, могут быть отнесены к поисковому спаму. Например, в посте может быть сказано: «подобный обмен ссылками может продвинуть ваш сайт в органическом поиске google.com». В этом случае, интернет-адрес google.com, который хоть и содержится в указанном сообщении, очевидно, не может быть отнесен к поисковому спаму. В иных случаях мы можем иметь дело с навигационными гиперссылками по самому форуму, а также с рядом информационных ссылок, которые пользователи SEO-форумов, например, проставляют в своих подписях. Вторая причина заключается в том, что не все URL-адреса, казалось бы, вовлеченные в манипулятивные схемы, одинаково подозрительны. Например, те URL-адреса, которые размещаются активными пользователями должны рассматриваться с большим приоритетом для признания их спамом, нежели чем те, что были размещены неактивными пользователям форумов; URL-адреса тех сайтов, которые уже имеют на веб-графе взаимное цитирование с другими ресурсами, имеют большую вероятность оказаться спамом, нежели чем те, что еще не обзавелись взаимным цитированием. Подытоживая вышесказанное, в целях аккуратного извлечения URL-адресов, нам необходимо учитывать множество факторов, а не заниматься простым извлечением URL из тех постов, что размещаются на SEO-форумах. Опираясь на изложенные обсуждения, в текущей работе, мы предлагаем следующий подход к извлечению спам URL из форумов по поисковой оптимизации. Для начала, мы собираем URL-адреса, которые содержатся в сообщениях на SEO-форумах. Во-вторых, мы извлекаем особенности каждого URL-адреса, на основании тех постов, в которых они фигурируют, авторов сообщений, а также гиперссылочной структуры, сформировавшейся вокруг заданного URL-адреса на реальном веб-графе. В-третьих, мы используем фреймворк, использующий полуконтролируемое обучение, для расчета спам-оценок, присуждаемых URL-адресам. Этот фреймворк не только усиливает особенности URL, но также кодирует ряд таких эвристик, как наличие аппроксимирующей изоляции среди хороших сайтов, которые редко ссылаются на некачественные ресурсы, в то время как некачественные сайты имеют тенденцию к активному цитированию себе подобных. Мы применили предложенный нами подход к семи основным форумам по поисковой оптимизации, и извлекли большое количество URL-адресов, подозреваемых в поисковом спаме. В ходе интенсивных эмпирических исследований было обнаружено, что множество извлеченных нами URL действительно относились к ссылочному спаму, подавляющая доля которых не могла быть идентифицирована традиционными методологиями. Резюмируя, основной вклад нашей работы заключается в следующем:
Последующая часть материала организована следующим образом. В Разделе 2 мы знакомим вас со смежными работами, затрагивающих анти-спам технологии. В Разделе 3 мы представляем комплексный анализ информации, содержащейся на форумах по поисковой оптимизации и продвижению сайтов. Предложенная методология идентификации ссылочного спама, основанная на полуконтролируемом обучении, обсуждается в Разделе 4. В Разделе 5 приведены результаты наших экспериментов. Последний раздел подводит итоги текущей, а также намечает направления для будущих работ.
Все больше пользовательского трафика приходится на системы информационного поиска. Очень часто для коммерческих веб-сайтов пользовательский трафик напрямую связан с получением дохода. По этой причине нет ничего удивительного в том, что многие владельцы интернет-ресурсов пытаются продвинуть свои сайты в индексе поисковых машин с помощью инструментов поискового спама. На количество случаев проявления поискового спама, фиксируемое за определенные временные интервалы, а также его давление на качество органического поиска, исследовательские сообщества обратили свое внимание всего лишь несколько лет назад, признав его серьезной проблемой. В своей работе [8] Gyongyi и Garcia-Molina предложили хороший обзор спам-технологий, который дал научному сообществу четкое представление об известных на тот момент манипулятивных практиках. Грубо говоря, в их работе спам-технологии были разделены на две основные категории: ссылочный спам и спам, относящийся к содержимому. Целью контентного спама является манипуляция такими алгоритмами текстового соответствия документа и пользовательского запроса, как tf-idf [1]. Типичные приемы контентного спама включают в себя повторение ключевых слов, выгрузка большого количества несвязанных ключевых слов, а также вплетение ключевых фраз в скопированное извне содержимое. Для того чтобы скрыть следы контентного спама, также существует ряд технологий сокрытия, в том числе использование цветовых схем, скриптов или нескольких видов клоакинга [8]. Fetterly и др. [6, 7, 14] предложили достаточно большое количество особенностей веб-страниц, которые могут быть использованы для вычисления контентного спама. Ссылочный спам нацелен на манипуляцию алгоритмами гиперссылочного анализа. Типичными практиками данной категории спама являются ссылочные фермы, обмен гиперссылками между сайтами и т.д. В дополнению к этому, возможна покупка большого количества входящих ссылок у различных спамеров, после чего идентификация его/ее манипулятивной схемы представляется затруднительной даже для эксперта. Для противодействия поисковому спаму были предложены модели доверия, которые распространяют репутацию по ссылочному графу. К данного рода алгоритмам доверия/недоверия относятся TrustRank [11] и BadRank [15], которым необходим исходный набор интернет-страниц, промаркированных на предмет доверия или недоверия с последующей пропагации данных меток по всему ссылочному графу. Для идентификации ссылочного спама методы иного рода используют ряд статистических особенностей гиперссылочной структуры, например [5]. Кроме того, Benczur и др. [2] разработали алгоритм под названием SpamRank, который пессимизирует подозрительные документы при подсчете PageRank. Относительно недавно, исследователи стали изучать конкретные типы спама с использованием дополнительной информацией. Dai и др. [4] и Chung и др. [3] предложили рассматривать при классификации спам-страниц историческую информацию. Ma и др. [13] использовали некоторые особенности URL-адресов в задачах идентификации поискового спама. Если говорить о самых последних веяниях, то исследователи стали уделять куда более пристальное внимание на деятельность спамеров в таких социальных сервисах, как форумы, блоги и сайты микроблоггинга. Отметим, что приведенный выше обзор смежных работ достаточно ограничен рамками настоящего исследования. Больше исследований можно найти в серии семинаров AIRWeb [17]. Обратите внимание на то, что спамеры стремятся сохранить действенные на сегодняшний день манипулятивные схемы в тайне. Поэтому научное сообщество не располагает достаточным количеством информации о самых передовых видах спам-технологий, и у него впереди еще долгий путь по разработке анти-спам методов, отвечающим реалиям сегодняшних дней.
Как уже упоминалось в нашей вводной части, SEO-форумы являются одной из основных площадок, на которых спамеры создают между собой всевозможные альянсы для реализации своих манипуляций с алгоритмами ранжирования. Для лучше понимания того, как это осуществляется на практике, мы провели тщательное исследование данных, содержащихся на форумах по поисковой оптимизации и продвижения сайтов. Здесь основным источником данных послужили публичные посты, размещенные на семи наиболее известных SEO-форумах (см. Таблицу 1). Мы отсканировали эти посты в декабре 2009 года. В общей сложности, нашему анализу подверглось более чем 50000 URL-адресов различных веб-сайтов и около 27000 участников указанных форумов.
Мы организовали посты по топикам, которые создавались для обсуждения тех или иных вопросов, а также извлекли из них пары «пользователь → URL». Топик T состоит из последовательности постов k, то есть T={p1,p2,…,pk}. Каждый пост соответствует своему пользователю (автору), а некоторые из них содержат в себе URL-адреса. Относительно топиков, постов и пользователей форумов мы будем использовать следующие определения:
Определение 1. Корневой пост / Ответный пост. Первое опубликованное в топике сообщение, которое начинает собой обсуждение того или иного вопроса, называется корневым, в то время как все последующие за ним посты называются ответными.
Определение 2. Топикстартер (ТС). Если какой-либо пользователь инициирует обсуждение некоторой темы, а именно становится автором корневого поста, мы называем его/ее топикстартером.
Определение 3. Размещенный URL / Владелец URL-адреса. Если в опубликованном сообщении пользователя содержится URL-адрес, то такой URL называется размещенным, а запостивший его пользователь — владельцем URL-адреса.
Определение 4. Ответчик. Если пользователь, просматривая обсуждение какой-либо темы, в дальнейшем решает опубликовать ответный пост, мы называем его/ее ответчиком. Здесь не важно, содержит ли его/ее сообщение URL-адрес или нет.
| Название форума | Digital Point | iWebTool | SubmitExpress | Switchboards | Top25Web | Webmaster-Talk | WebProWorld |
| число топиков | 41851 | 585 | 2065 | 760 | 1884 | 9157 | 2099 |
| число постов | 3188815 | 2084 | 5096 | 6044 | 4456 | 31051 | 11340 |
| число корневых постов с размещенными URL | 21017 | 410 | 1542 | 516 | 1482 | 5509 | 1393 |
| число ответных постов с размещенными URL | 47528 | 501 | 2200 | 2497 | 1040 | 6665 | 3139 |
| число размещенных URL | 117184 | 2286 | 7428 | 3341 | 4966 | 27853 | 8074 |
| число уникальных размещенных URL | 31728 | 1200 | 3197 | 975 | 2331 | 8484 | 2619 |
| число пользователей | 316391 | 603 | 1817 | 826 | 1257 | 4189 | 1844 |
Статистические данные, относительно топиков, постов, URL-адресов и пользователей семи SEO-форумов приведены в Таблице 1.
Таблица 1. Статистические данные по семи SEO-форумам
На Рисунке 3 (1) мы построили распределение постов (a) и размещенных URL (b) по соответствующим топикам.
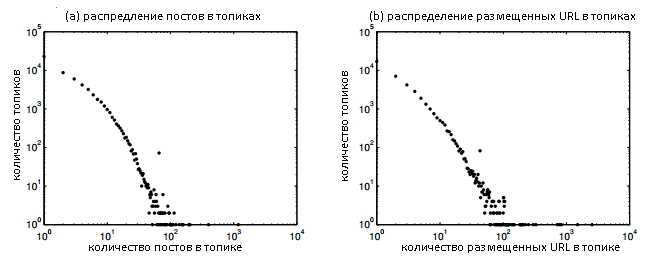
Рисунок 3 (1) Распределение постов (a) и размещенных URL (b)
Глядя на обе части нашего с вами рисунка видно, что все они следуют степенному закону распределения. Отметим, что далеко не все топики содержат в себе размещенные URL-адреса. В нашем наборе данных имеется порядка 18000 топиков, которые не содержат каких-либо ссылок. Отчасти это может быть объяснено тем, что некоторые осторожные спамеры не желают раскрывать свои сайты публично, предпочитая общаться друг с другом с помощью более безопасных средств связи (например, используя личные сообщения). Мы извлекли все пары «пользователь → URL» по имеющимся топикам. В качестве примера давайте еще раз возьмем топик из Рисунка 1, где мы можем извлечь следующие пары: «cutechuskay → mobicreed.com», «appleiphone → thebestdigital.com» и «F–K → mobifunda.com». Исходя из извлеченных нами пар, между пользователем и URL-адресом обычно существует три типа взаимоотношений:
На Рисунке 3 (2) мы построили распределение постов (c) и размещенных URL (d) пользователями SEO-форумов.
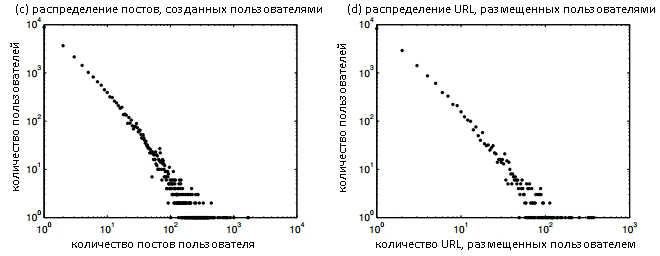
Рисунок 3 (2) Распределение постов (c) и размещенных URL (d)
Видно, что ряд пользователей форумов проявляют высокую активность в плане размещения URL-адресов, и некоторые из этих URL размещаются не одним владельцем, а большим числом всевозможных пользователей.
Мы создали случайную выборку, которая была сформирована из 100 топиков по семи SEO-форумам, и попросили наших опытных аналитиков провести последующее исследование полученных данных. После чего, в нашей выборке было обнаружено 903 поста, 1044 уникальных URL и 565 пользователей.
Все 903 поста были разделены на пять классов, относительно тех целей с которыми они были созданы пользователями форумов. Интуитивно, на SEO-формах пользователи выполняют различные роли и отличаться друг от друга своим поведением. Некоторые из них размещают URL-адреса своих веб-сайтов и открыто занимаются поиском партнеров для ссылочного обмена. Подобного рода посты соответствуют категории Открытого двухстороннего обмена ссылками. Некоторые пользователи не желают публиковать свои URL-адреса, предпочитая заключать сделки с использованием личных сообщений. Подобного рода посты соответствуют категории Скрытого двухстороннего ссылочного обмена. Прочие же пользователи будут искать партнеров для своей ссылочной фермы или для трехстороннего обмена ссылками, посты которых относятся к категории Трехстороннего ссылочного обмена или Ссылочных ферм (в том числе, псевдо-каталогов). Наконец, другие посты содержать общие обсуждения каких-либо вопросов и ряд бессмысленных ответов. Статистические данные по отнесению постов в ту или иную категорию приведены в Таблице 2.
| Категория | Число постов | Процент |
| Открытый двухсторонний обмен ссылками | 336 | 37.21% |
| Скрытый двухсторонний обмен ссылками | 307 | 34.00% |
| Трехсторонний обмен ссылками | 5 | 0.55% |
| Ссылочные фермы (в том числе, псевдо-каталоги) | 23 | 2.55% |
| Прочие | 232 | 25.7% |
Таблица 2. Статистика отнесения постов по соответствующим категориям
Исходя из приведенных выше статистических данных, мы наблюдаем следующее:
Наши аналитики также выполнили исследование, касающееся 1044 размещенных URL-адресов, и разделили их на шесть категорий. Для того чтобы определить, является ли тот или иной URL-адрес спамом или был размещен с иной целью, они внимательно ознакомились с текстом каждого поста, вникнув в их смысл. Статистические данные по отнесению URL-адресов в ту или иную категорию приведены в Таблице 3.
| Категория | Количество URL | Процент | ||||||
| Размещенные с нелегальными целями | Обмен ссылками / линкофармы в содержимом поста | 622 | 601 | 59.6% | 57.6% | |||
| Обмен ссылками / линкофармы в подписи форумчан | 21 | 2.0% | ||||||
| Размещенные с легальными целями | Отсутсвие в содержимом поста информации по обмену ссылками / линкофармам | Навигационные ссылки | 422 | 91 | 21 | 40.4% | 8.7% | 2.0% |
| Ссылки на популярные сайты | 7 | 0.7% | ||||||
| Указание источника при цитировании контента | 63 | 6.0% | ||||||
| Отсутсвие в подписи участника форума информации по обмену ссылками / линкофармам | 331 | 31.7% | ||||||
Таблица 3. Статистика отнесения размещенных URL по соответствующим категориям.
В данной таблице те URL-адреса, которые размещались в постах, а также значились в подписях участников форумов, предлагая гиперссылочный обмен / участие в ссылочных фермах, идентифицировались нами как размещенные с целью участия в манипулятивных схемах. Прочие же URL, такие как навигационные линки по форуму, ссылки на популярные веб-сайты; гиперссылки, проставляемые в качестве источника при цитировании информации (такого рода URL-адреса извлекались из своего первоначального поста и в дальнейшем не рассматривались нами повторно), а также гиперссылки, указанные в подписях участников, но не относящиеся к обмену ссылками / линкофермам, к поисковому спаму отнесены не были. Дальнейшее изучение URL-адресов, размещенных с целью участия в манипулятивных схемах (то есть тех, что значились в подписях участников, а также размещались в постах, предлагающих обмен ссылками / участие в ссылочных фермах, суммарное число которых, в соответствии с Таблицей 3, составило 622 линка) было направлено на ознакомление с внешним видом и на определение качества данных веб-сайтов.
| Категория | Число URL-адресов | Процент |
| Низкокачественные сайты | 358 | 57.6% |
| Сайты среднего уровня | 174 | 28.0% |
| Высококачественные сайты | 90 | 14.4% |
| Итого | 622 | 100% |
Таблица 4. Качество сайтов, URL-адреса которых были размещены с манипулятивными целями.
В Таблице 4 приведены результаты анализа качественной составляющей извлеченных сайтов. Низкокачественные сайты отличаются неопрятным внешним видом и плохим взаимодействием с пользователем. К высококачественным интернет-ресурсам относятся те сайты, что имеют хороший дизайн и верстку. Соответственно среднее качество присваивается тем ординарные веб-сайтам, которые находятся в промежуточном, пограничном состоянии между низкокачественными и высококачественными ресурсами. Исходя из приведенных выше статистических данных, мы наблюдаем следующее:
Исследование, которое мы провели в Разделе 3 показывает, что форумы по поисковой оптимизации содержат богатый исходный материал, который может быть использован в качестве информации по вычислению поискового спама. В этом разделе мы рассмотрим то, каким образом можно эффективно извлекать гиперссылочный спам, посредством анализа данного рода, пока еще сырой информации. Для простоты обсуждения и реализации в текущей работе мы предположим, что совпадение никнеймов пользователей разных форумов будет указывать на одного и того же человека; мы также рассматриваем топики и посты с разных SEO-форумов как эквивалентно значимые в нашем анализе. Другими словами, мы просто объединяем отсканированные данные по всем семи SEO-форумам в единую совокупность. Для того чтобы внести ясность в последующее изложение нашего материала, в Таблице 5 мы даем основные обозначения с соответствующими комментариями.
| Обозначения | Пояснения | Обозначения | Пояснения |
| n | количество размещенных URL-адресов | I | единичная матрица |
| m | количество пользователей | P | подссылочная матрица для n размещенных URL-адресов |
| k | количество особенностей URL-адресов | A | матрица ссылочного обмена, извлеченная из P |
| pi | i-ый размещенный URL | L1 | лапласиан S |
| uj | j-ый пользователь | L2 | лапласиан A |
| xi | спам-оценка URL-адреса pi | D1 = diag(di) | диагональная матрица, расчитанная из S |
| yi | k-мерный вектор особенностей для URL-адреса pi | D2 | диагональная матрица, расчитанная из A |
| Y | kxn матрица особенностей для всех URL | D3 | диагональная матрица, расчитанная из P |
| ω | k-мерный вектор параметров для yi | D4 | диагональная матрица, расчитанная из PT |
| ω* | вектор оптимальных параметров ω | Q(1) = {qij(1)} | нормированная матрица P |
| ti | спам/НЕ-спам метка URL-адреса pi | Q(2) = {qij(2)} | нормированная матрица pT |
| НR = {ri} | матрица корреляции пары «пользователь-URL» | H | см. формулу (13) |
| S = {sij} | матрица подобия URL | h | см. формулу (14) |
| e | n-мерный вектор со всеми 1s | H* | см. формулу (15) |
| x~ | линейное преобразование x | α, β, γ, η | неотрицательные коэффициенты |
Таблица 5. Обозначения и пояснения.
Предположим, что имеется n размещенных URL-адресов p1, p2,…,pn и m пользователей u1, u2,…,um в наших совокупных данных. Наша задача состоит в том, чтобы вычислить спам-оценки xi (-1 ≤ xi ≤ 1, i = 1,2,…, n) по всем размещенным URL. Чем выше показатель xi, тем более вероятно то, что pi является спамом. Прямой подход заключается в подсчете частотности размещенных URL-адресов с последующим рассмотрением наиболее частотных ссылок как наиболее подозрительных с точки зрения их отношения к спаму. Однако, как обсуждалось нами в Разделе 3, не все URL-адреса относятся к спамденсингу. Как следствие этого, простой подсчет частотности может не сработать (см. наши эксперименты в Разделе 5) и здесь нам потребуется передовая технология майнинга данных. Поэтому для того чтобы решить эту сложнейшую задачу, в этом разделе мы предлагаем метод, основанный на полуконтролируемом обучении. В следующих подразделах мы займемся введением в нашу модель целевой функции, применяемой в этом алгоритме, а также обсудим пути ее эффективной оптимизации.
В предложенной нами методологии целевая функция содержит параметр ошибок и параметр регуляризации. Параметр ошибок включает маркированные учителем спам-данные, а параметр регуляризации накладывает ограничения на спам-оценки различных сайтов без учителя. Именно по этой причине наш алгоритм относится к полуконтролируемой методологии.
Мы определяем параметр ошибок (loss term) исходя из разницы между предсказанными спам-оценками и истинными отметками в обучаемой выборке. Мы рассматриваем спам-оценки как сгенерированные посредством комбинации набора особенностей, извлеченных из форумов по поисковой оптимизации, а также из прочих источников. В частности, мы выделяем три категории особенностей каждого URL:
Предположим, что в общей сложности существует k особенностей для каждого URL pi, обозначенные как yi. Тогда Y = (y1, y2,…, yn) является kхn матрицей особенностей по всем веб-сайтам. На основании указанных особенностей мы определяем спам-оценку каждого URL следующим образом,
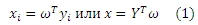
,где ω является k-мерной комбинацией вектора параметров. Допустим, мы имеем спам/НЕ-спам метки ti на части размещенных URL-адресов,

Затем, мы определяем параметр ошибок следующим образом,
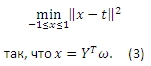
При определении параметра регуляризации (regularization term) мы рассматриваем следующие эвристики:
(i) Сходство на двудольном графе пары «Пользователь-URL»
Для обнаружения латентных взаимоотношений между размещенным на форумах по поисковой оптимизации и раскрутки сайтов URL-адресов, мы рассчитываем имеющиеся между ними сходства (similarities) на основании связанных с ними пользователей в соответствующих топиках, и используем это сходство для регуляризации спам-оценок. Для этой цели мы построили двудольный граф пары пользователь-URL , используя пары «пользователь → URL», которые были извлечены нами из SEO-форумов. На текущем графе пользовательский узел соответствует уникальному пользователю форума, а URL-узел соответствует уникальному размещенному URL-адресу; между ними существует ребро в том случае, если наличествует пара «пользователь → URL». Веса ребер задаются следующим образом. Как уже упоминалось в подразделе 3.1, существует три типа взаимоотношений, наблюдающихся между пользователем и URL-адресом. Исходя из этого, мы присваиваем различные веса различным типам описанных ранее взаимоотношений. Здесь мы просто устанавливаем веса тем URL-адресам, что были размещены в корневом сообщении, размещены в ответном сообщении и, наконец, просматривались по предыдущим постам равными 3, 2 и 1 соответственно. Далее, вес ребра устанавливается в соответствии с весом взаимоотношений между пользователем форума и URL-адресом. В том случае, если ребро соответствует нескольким отношениям, его вес определяется как сумма всех связанных весов. Например, если ребро соответствует 4 парам «пользователь → URL» в том URL-адресе, который был размещен в корневом сообщении, 5 парам в том URL-адресе, который был размещен в ответном сообщений и, наконец, 6 парам просмотренных URL-адресов в предыдущих постах, его вес может быть рассчитан как 4 х 3 + 5 х 2 + 6 х 1 = 28. Пускай R = (r1, r2,…, rn) является взвешенной mхn матрицей корреляции двудольного графа пары «пользователь-URL». Если используем пользователя для представления URL-адресов, мы получаем m-мерный вектор rj в качестве представления URL pj. Далее, мы можем рассчитать матрицу подобия URL, обозначенную как S = {sij},(i,j =1,2,…, n), используя метод случайного блуждания, подобный SimRank [10]. Мы предполагаем, что те размещенные на форумах URL-адреса, которые подобны между собой на приведенным ранее двудольном графе должны иметь схожие спам-оценки. Данная эвристика может быть закодирована в минимизации xTL1x, где L1 является Лапласианом матрицы подобия URL,
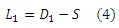
Здесь D1 является диагональной матрицей, элементы диагонали которой равны сумме всех элементов в соответствующей строке S. Обозначим D1 = diag(di), i = 1,2,…, n; следующее уравнение дает интерпретацию того, почему минимизация Лапласиана может соответствовать целям приведенной выше эвристике:
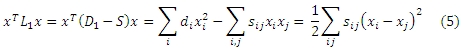
Приведенный выше Лапласиан для оценки подобия широко используется в качестве параметра сглаживания (smooth term) в задачах полуконтролируемой классификации [16]. Интуитивно, посредством минимизации Лапласиана, те URL-адреса, которые имеют высокую степень сходства, согласно sij, вероятней всего, получат схожие спам-оценки.
(ii) Взаимные ссылки на веб-графе
Кроме разработанного двудольного графа пары пользователь-URL, для того, чтобы определить был ли де-факто осуществлен ссылочный обмен между сайтами, мы предлагаем учитывать гиперссылочную структуру между размещенными URL-адресами. Для этих целей мы используем веб-граф, полученный из коммерческой системы информационного поиска. Пускай nxn матрица P является подссылочной матрицей для n размещенных URL-адресов, извлеченных из веб-графа, то есть Pij имеет ненулевое значение в том случае, если существует ссылка из pi к pj; в противном случае, Pij = 0. Обратите внимание, что набор всех Pii = 1 во избежание возможных нулевых сумм строк и столбцов на шаге нормализации. Обозначим А как матрицу, которая содержит информацию по гиперссылочному обмену в P,
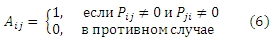
Мы полагаем, что те размещенные URL-адреса, которые действительно участвовали в ссылочном обмене по данным веб-графа, должны иметь схожие спам-оценки. Аналогично эвристике, использованной в паре «пользователь-URL», эта эвристика может быть включена в минимизацию xTL2x, где
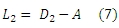
D2 является диагональной матрицей с диагональными элементами равными сумме всех элементов в соответствующей строке матрицы A. Аналогично Уравнению (5), посредством минимизации Лапласиана, те URL-адреса, что участвовали в обмене ссылками, согласно Aij, вероятней всего, получат схожие спам-оценки.
(iii) Однонаправленные ссылки на веб-графе
Интуитивно, если веб-сайт ссылается на некоторое множество некачественных интернет-ресурсов, с высокой долей вероятностей он также окажется некачественным. Однако если веб-сайт ссылается на множество качественных сайтов, этот факт еще не дает на основания считать его столь же качественным постольку, поскольку иногда спам-ресурсы также создают искусственные гиперлинки, указывающие на качественные сайты. С другой стороны, если на веб-сайт ведут ссылки с множества хороших интернет-ресурсов, мы также рассматриваем его качественным с высокой долей вероятности. Однако, в том случае, если сайт цитируется большим числом спам-сайтов, из этого еще не следует то, что мы должны рассматривать его как некачественный постольку, поскольку иногда спамеры могут также ссылаться на хорошие ресурсы с целью введение в заблуждение алгоритмы ранжирования систем информационного поиска. Чтобы закодировать описанные выше эвристики, мы определяем D3 и D4 как диагональные матрицы, чьи диагональные элементы равны сумме всех элементов в соответствующих строках P и PT. Далее, мы можем получить Q(1) = {qij(1)} = D3−1P и Q(2) = {qij(2)} =D4−1PT, являющиеся нормализированными матрицами P и PT. Для простоты изложения мы изменим диапазон спам-оценок от [−1,1] до [0,1] посредством следующего преобразования, в котором e является n-мерным вектором, все элементы которого равны 1.
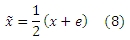
Тогда, мы имеем:
Подводя итог, нам необходимо добавить следующую формулу к регуляризации целевой функции:
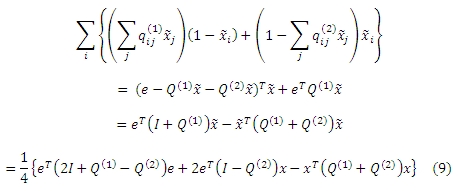
Учитывая все компоненты целевой функции, введенную в предыдущем разделе нашего исследования, мы приходим к следующей задаче полуконтролируемого обучения,
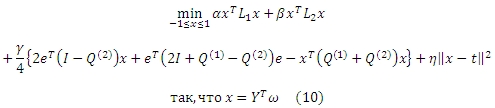
,где α, β, γ и η являются неотрицательными коэффициентами и они удовлетворяют α + β + γ + η = 1. Учитывая ||x − t||2 = (x − t)T(x − t) с помощью ряда простых математических преобразований, мы можем получить эквивалентную форму Задачи (10),
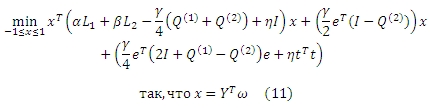
Поскольку (γ/4 eT(2I + Q(1) − Q(2))e + ηtTt) является константой, она может быть удалена из целевой функции. Затем, вышеуказанную задачу можно записать следующим образом:
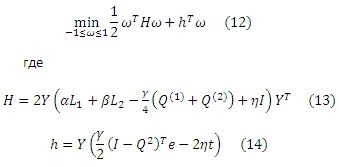
Это типичная задача квадратичного программирования, в которой H является kxk матрицей, а h — k-мерным вектором. Отметим, что H является асимметричной матрицей, и мы используем следующее преобразование для приведения QP задачи к стандартной форме. То есть, поскольку ωTHω является скалярной величиной, мы имеем:
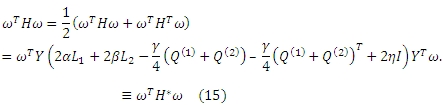
Чтобы H* была положительно полуопределенной матрицей, мы установим η ≥ γ. Поскольку размер k векторного параметра ω обычно слишком мал, задача может быть решена крайне эффективным способом. После того, как мы получим вектор оптимальных параметров ω* мы можем использовать следующую оценочную функцию x = YTω* для расчета спам-оценок размещенных URL-адресов. Сайты с высокими спам-оценками будут рассматриваться как некачественные и пессимизированы в результатах органической выдачи.
В текущем разделе мы оценим эффективность предложенного нами подхода по извлечению спама из форумов по поисковой оптимизации и продвижению сайтов.
Как уже было указано в Разделе 3, в своих экспериментах мы используем отсканированный набор данных семи форумам по поисковой оптимизации и продвижению сайтов. После объединения данных всех семи форумов вместе, мы получили 50534 уникальных URL-адресов интернет-сайтов и 26927 различных пользователей. Мы также получили ссылочный граф сайтов по данным коммерческой поисковой системы, который был отсканирован в ноябре 2009 года и содержал 120699329 веб-сайтов. Мы использовали этот граф для извлечения подссылочной матрицы P для размещенных на форумах URL-адресов. Среди 50534 размещенных на форумах URL, 34979 совпали с предоставленным нам ссылочным графом. Для тех веб-сайтов, что выпадали из нашего графа, мы просто установили Pii=1 и Pij=0, i≠j во избежание нулевых строк и столбцов в матрице P. Мы рандомно извлекли из 50534 сайтов 300 интернет-ресурсов и попросили трех подготовленных экспертов провести их асессорскую оценку на предмет наличия в них спама, в соответствии с критериями оценками Web Spam Challenge [20]. В результате, приблизительно 60% (208/300) сайтов получили отметку спам, в то время как оставшиеся были промаркированы как НЕ-спам ресурсы. Далее помеченный набор данных был рандомно разбит на две выборки: первая для обучения (с 187 спам-ресурсами и 32 НЕ-спам сайтами) и вторая для проверки (с 21 спам-ресурсами и 60 НЕ-спам сайтами). Мы использовали обучающую выборку для построения параметра ошибки, а проверочная выборка была задействована в оценке производительности предложенного нами подхода. Мы извлекли 14 особенностей из всего того множества характеристик, что были описаны в подразделе 4.1.1 для каждого веб-сайта; в целевой функции коэффициенты α = β = γ = η = 1/4 в соответствии с двумя ограничениями α + β + γ + η = 1 и η ≥ γ.
В нашем сравнении производительности алгоритмов мы использовали три следующих базиса. Первым базисом являлся подсчет частоты встречаемости размещенных на форуме URL-адресов и маркировка интернет-сайтов с частотностью выше предельно допустимой как спамерские, который, по сути, представляется прямым подходом в том случае, когда обыватели размышляют об извлечении спама из форумов по поисковой оптимизации. Вторым базисом являлся метод, основанный на классификации. В частности, в качестве классификатора мы использовали SVM-light [18] для комбинации извлеченных нами 14 особенностей форумов по поисковой оптимизации и поисковому продвижению сайтов. Третьим базисом стал алгоритм доверия TrustRankm, который основывается исключительно на данных гиперссылочного веб-графа и может рассматриваться нами как представитель типичных анти-спам технологий. Для простоты мы обозначим упомянутые выше три базиса, а также предложенный нами метод как Frequency, SVM, TrustRank и SemiSupervised соответственно. Мы запустили все четыре алгоритма и сравнили их производительность на проверочной выборке с помощью метрик точности, полноты и F1 [12]. Результаты этого эксперимента представлены в Таблице 6.
| Методология | Точность | Полнота | F1 |
| Frequency | 27.3% | 44.4% | 33.8% |
| SVM | 50.0% | 76.2% | 60.4% |
| TrustRank | 66.0% | 50.4% | 57.1% |
| SemiSupervised | 81.1% | 83.3% | 82.2% |
Таблица 6. Производительность алгоритмов по вычислению спама.
Из таблицы видно, что наихудшую производительность получает Frequency. В действительности, это не вызывает каких-либо удивлений с нашей стороны с учетом предыдущих обсуждений. Некоторые URL-адреса, хоть и были размещены на форуме единожды, тем не менее, их владельцы являлись активными спамерами, которые размещали их исключительно с целью построения манипулятивных схем. С другой стороны, ряд URL имеют высокую частоту цитирования, но при этом они относятся к известным веб-сайтам, которые постоянно упоминаются в процессе тех или иных обсуждений; к нами также относятся навигационные гиперссылки. Обратим ваше внимание на то, что для алгоритма Frequency мы де факто использовали различные предельно-допустимые пороговые значения, однако его результаты на всем протяжении нашего эксперименты были наихудшими по сравнению с прочими подходами. Тот результат, который продемонстрирован для него в Таблице 6 относится к тому случаю, когда предельно-допустимое пороговое значение равнялось 2. Производительность машины опорных векторов (SVM) оказалось несколько лучшей, нежели чем Frequency. Это в некоторой степени подтверждает эффективность тех особенностей, которые мы извлекли из SEO-форумов. Однако SVM значительно уступает SemiSupervised. Это является наглядным свидетельством преимущества используемых нами эвристик, которые обсуждались в Разделе 4. Они добавляют собственное значение к параметру ошибок, являющийся, как и параметр регуляризации, одной из двух составляющих нашей целевой функции, а также могут распространять размеченную информацию по большему количеству URL-адресов. Таким образом, они помогают улучшить способность к обобщению данной методологии, и привносят существенный вклад в идентификацию значительного объема спам-сайтов по информации размещенных URL-адресов. Алгоритм TrustRank показывает лучшую производительность, нежели чем Frequency и SVM по метрике точности, но уступают SemiSupervised. Это можно объяснить следующим образом. Поскольку URL-адреса, содержащиеся в нашем проверочном наборе, собирались по SEO-форумам, значительная их доля отличается не настолько типичными ссылочными паттернами, которые смогли быть идентифицированы алгоритмом доверия TrustRank. Следовательно, TrustRank оказывается бессилен в плане идентификации их как некачественных. Учитывая, что предложенный нами подход может успешно обнаруживать подобного рода спам, мы считаем, что наша методология может быть хорошим дополнением к уже существующим технологиям противодействия поисковому спаму.
Далее приведем несколько примеров, демонстрирующих эффективность предложенного нами метода извлечения спама.
Первый пример демонстрирует, что предложенный нами алгоритм полуконтролируемого обучения может вычислять ссылочные фермы. При просмотре топа отранжированных по спам-оценкам URL-адресов, возвращенных предложенной методологией 5, мы обнаружили достаточно большое число URL, часть строки которых содержали слово «отель», например madridhotelsweb.com, amsterdamhotelsweb.com и warsawhotelsweb.com. Последующий осмотр ссылочного веб-графа позволил обнаружить, что среди топ 200 URL-адресов, возвращенных нашим алгоритмом наличествовало 43 сайтов (включая указанные три ресурса), которые действительно ссылались друг на друга, то есть имело место быть 682 взаимных гиперссылок между этими 43 интернет-сайтами. Многие из них имели схожий дизайн, что наталкивало на мысль, что все они принадлежат ссылочной ферме. При проверке исходного материала, мы обнаружили пост submitexpress.com/bbs/about6102.html&sid=7a45d35d77735c185fdc6a449e94941d, в котором пользователь форума искал партнеров для участия в данной ссылочной ферме. На Рисунке 4 представлен скриншот этого поста.
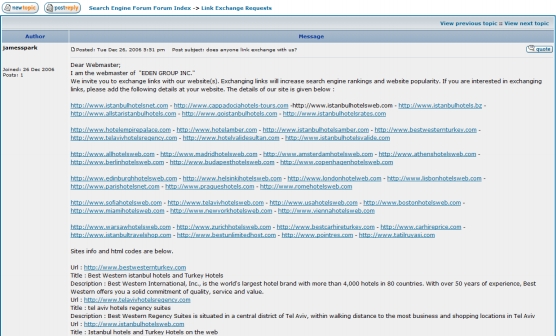
Рисунок 4. Пост, связанный с линкофармом
Это является очевидным доказательством того, что владелец указанных веб-сайтов участвовал в строительстве ссылочной фермы, и по причине плотной гиперссылочной связанности данные интернет-ресурсы должны быть пессимизированы. Еще одним примером поста, относящегося к ссылочной ферме, может быть top25web.com/bbs/viewtopic.php?f=73&t=2063&sid=677ff6b24fc7ba95ed394b9530b66cfd и webmaster-talk.com/relevant-link-exchangeforum/50551-looking-for-link-partners.html. По причине ограниченного объема нашей работы, мы не будем проводить детальное обсуждение двух последних примеров.
Второй пример демонстрирует, что предложенный нами алгоритм полуконтролируемого обучения может вычислять ссылочный обмен. В топе отранжированных по спам-оценкам URL, возвращенных нашим алгоритмом, мы обнаружили сайт shopping-heaven.com, который является интернет-магазином по продаже сигарет. Кроме ссылочного обмена с другим сайтами аналогичной тематики, такими как cigline.net и topcigarettes.net, мы обнаружили, что ресурс также проводит агрессивный ссылочный обмен с множеством сайтов, которые не имеют ничего общего с тематикой реализации сигарет через интернет, такими как ecobaby.co.uk, flash-template-design. com и crazydating.net. В соответствии с гиперссылочным веб-графом, эти сайты обменивались ссылками с 22 прочими интернет-ресурсами. При проверке исходного материала, мы обнаружили, что этот URL был размещен по крайне мере на трех SEO-форумах, то есть на Digital Point 6, Top25Web 7 и WebmasterTalk 8. Просматривая топики указанных постов мы обнаружили, что (1) несмотря на то, что URL был размещен на разных форумах, автором всех постов был один единственный пользователь с никнеймом «cigara»; (2) все посты были посвящены обмену ссылками с URL-адресом shopping-heaven.com; (3) Многие из 22 прочих веб-сайтов, которые имели взаимные ссылки с shopping-heaven.com, были обнаружены в ответных сообщениях исследуемых топиков. Эти наблюдения за SEO-форумами свидетельствуют о том, что на сегодняшний день использование ссылочного обмена для раскрутки интернет-сайтов представляется для пользователей SEO-форумов эффективной спам-технологией, а также показывает, что активные спамеры будут искать сообщников не на одном, а не нескольких SEO-форумах. В этом отношении, для извлечения спама имеет смысл проводить соанализ по разным форумам, посвященных раскрутке сайтов; кроме того, следует уделять внимание схожим никнеймам пользователям, несмотря на то, что форумы могут быть разными. Другие примеры вычисления URL-адресов, участвовавших в ссылочном обмене, включают сайты bestcarhireturkey.com и amitbhawani.com. По причине ограниченного объема нашей работы, мы не будем проводить детальное обсуждение двух последних примеров.
Третий пример демонстрирует, что предложенный полуконтролируемый алгоритм может вычислять спам-сайты, которые по своей форме являются высококачественными, но идентификация которых, вместе с тем, была бы затруднительной для традиционных анти-спам технологий, таких как TrustRank. К примеру, сайт phplinkdirectory.com имеет хороший дизайн, и алгоритм TrustRank назначает ему высокую доверительную оценку, то есть он ставит его на 82 место в рейтинге 34979 URL-адресов, совпадающих с предоставленным нам гиперссылочным веб-графом. Однако мы обнаруживаем, что предложенный нами алгоритм назначает ему высокую спам-оценку, то есть помещает его на 130 место в рейтинге 34979 URL-адресов. При проверке исходного материала, мы обнаружили, что этот URL был размещен по крайне мере на двух SEO-форумах, то есть на Digital Point 9 и Webmaster-Talk 10. Автором обоих постов являлся некий пользователь с никнеймом «dvduval», который, как думается, и являлся владельцем веб-сайта phplinkdirectory.com (если кликнуть по его никнейму над тем постом, который был размещен на форуме Digital Point и выбрать «Посетить домашнюю страницу dvduval!», мы попадаем прямо на сайт phplinkdirectory.com). Исследуя эту пару корневых постов мы нашли множество ответных сообщений от пользователей форумов, в том числе мы обнаружили 138 URL-адресов, желавших обменяться ссылками с phplinkdirectory.com (сравнивая данные предоставленного в наше распоряжение ссылочного веб-графа, оказалось, что ряд из них уже обменялись ссылками с phplinkdirectory.com). Текущий пример показывает, что предложенный алгоритм может обнаруживать спам-сайты, которые по своему внешнему виду выглядят качественными и способны успешно вводить традиционные анти-спам технологии, такие как TrustRank, в заблуждение. Другие примеры вычисления URL-адресов, относящихся к «высококачественным» спам-сайтам, включают ресурсы adbrite.com и linkmarket.com. По причине ограниченного объема нашей работы, мы не будем проводить детальное обсуждение двух последних примеров.
Подводя итог, экспериментальные результаты и разбор конкретных случаев, осуществленный в данном разделе, подтверждают, что предложенный нами алгоритм отличается высокой эффективностью и может быть хорошим дополнением к уже существующим технологиям противодействия поисковому спаму.
В текущей работе мы предложили способ извлечения ссылок, подозреваемых в использовании манипулятивных схем, которые размещаются на форумах по поисковой оптимизации и продвижению сайтов. По данным нашего исследования, спамер часто используют SEO-форумы для обсуждения и обмена информацией, касающейся обмена ссылками и линкофарминга. В том случае, если можем эффективно извлекать указанные спам-ресурсы из постов, то, тем самым, мы открываем новый источник вычисления спамденсинга, который может считаться хорошим дополнением к уже существующим технологиям противодействия поисковому спаму. Для реализации этой задачи, мы предлагаем подход, основанный на полуконтролируемом обучении для классификации размещенных URL-адресов на спам или НЕ-спам, посредством учета информации, содержащейся как на SEO-форумах, так и вне их среды. Результаты наших экспериментов демонстрируют, что предложенный здесь подход может извлекать большое количество некачественных сайтов, чего не могут выполнить традиционные анти-спам алгоритмы.
В будущем мы планируем исследовать следующие аспекты. Во-первых, в целях расширения набора данных и обнаружения большего числа спам-сайтов, мы бы хотели изучить вопрос автоматической детекции SEO-форумов/подфорумов в рамках предложенного метода. Во-вторых, мы будем рассматривать весовые значения SEO-форумов по-разному, в зависимости от их популярности и влияния на сообщества вебмастеров и поисковых оптимизаторов. В-третьих, мы разработаем более продвинутые способы объединения одних и тех же пользователей, зарегистрированных на разных форумах. В-четвертых, мы попытаемся использовать большее число особенностей (в том числе, время размещения поста, регистрация доменного имени сайта), а также, в целях последующего улучшения производительности предложенного нами метода, попробуем использовать различные комбинации весовых значений наших эвристик в целевой функции.
Перевод материала «Let Web Spammers Expose Themselves» выполнил Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации