SEO-Константа
Яндекс.Директ + оптимизация
Прежде, чем мы перейдем к более детальному исследованию алгоритма SpamRank, давайте еще раз вспомним основы классической модели Google RageRank, а также некоторые особенности эволюционных моделей веба. Представим интернет в виде графа, в котором HTML-страницы является вершинами, а гиперссылки — ребрами между ними. Стохастическую матрицу, соответствующую случайному блужданию для данного графа обозначим за А, то есть:
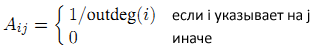
Вектор PageRank p = (p1,…,pN) определяется как решение следующего уравнения [1]:
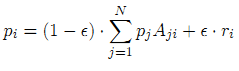
, где r = (r1,…,rN) вектор телепортации, а ε — ее вероятность. В том случае, если r является равномерным, то есть ri =1/N для всех i, тогда p является PageRank. При неравномерной телепортации, p называется персонализированным PageRank; в дальнейшем будем обозначать PPR(r). Очевидно, что PPR(r) является линейной комбинацией векторов r [2], в частности:
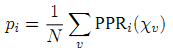
, где xu вектор телепортации, состоящий из нулевых значений за исключением узла u, где Xu(u) = 1. Исходя из данного уравнения можно сказать, что Google PageRank страницы i создается из того значения персонализации, которую вкладывают в нее более конкретные документы-саппортеры u c высоким PPRi(Xu). Независимые наблюдения [3,2] показали, что персонализированный PR вершины равен вероятности случайного блуждания, завершающегося в данной вершине с расстоянием, следующим из геометрического распределения: мы останавливаемся на шаге t с вероятностью ε⋅(1-ε)t. Необходимо также отметить, что PageRank можно переписать в виде степенного ряда.
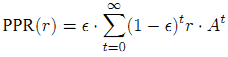
, где r⋅At соответствует случайному блужданию с расстоянием t, а ε⋅(1-ε)t — вероятность остановки. Мы генерируем достаточно большое количество случайных блужданий для имитации данных из изучаемой генеральной совокупности, начиная с вершины j, а также добавляя вероятности ε⋅(1-ε)t к их концевым точкам i; по результатам подсчетов мы получаем Supportj,i в качестве несмещённой оценки (не сильно отличающейся от среднего значения) PPR(Xj)i. В экспериментах [4] говорится, что 1,000 статистических испытаний по методу Монте-Карло, вполне достаточно для того, чтобы разделить высоко- и низкоранжирумеые страницы.
Полностью автоматическая детекция множества спамденсинг-саппортеров является важнейшей составляющей алгоритма SpamRank, по этой причине мы даем краткое описание двух ключевых компонентов данного интуитивного подхода:
Мы опираемся на общепризнанные эволюционные модели интернета [5,6], которые описывают нам такие глобальные его свойства, как степенное распределение и/или возникновение интернет-сообществ. В них нам говорится то, что общая гиперссылочная структура является следствием проставления ссылок на страницы веб-сайтов в зависимости от их популярности. В качестве наглядного примера может послужить модель [6], описывающая процесс цитирования страниц со схожей тематикой, по истечению которого «богатые становится еще более богатыми» в соответствии со степенным законом распределения. Как было замечено в [7] не только распределение Google PageRank, но и полустепень захода вершины (то есть количество входящих в нее ребер ) имеет очень схожее поведение по причине прямой зависимости между этими двумя показателями. Например, если мы взглянем на цифры, то, несмотря на приближение ряда значений корреляции к 0, более частым является наблюдение показателей близких 0.5. Так, авторы [8] корректируют первоначально обнаруженную корреляцию с низких значений до 0.34.
Если мы будем заниматься исследованием только единичных документов и/или малых наборов, мы не увидим какой-либо связи с вышеупомянутым степенным законом распределения PageRank. Однако на практике в больших выборках мы можем наблюдать достаточно отчетливое самоподобие, а посему мы предполагаем, что массовое интернет-окружение спамденсинга будет отличаться от качественных страниц своей искусственной ссылочной природой и, вполне вероятно, проставляемые на их целевые документы ссылки будут исходить из групп несколько однородных объектов.
Как мы уже писали в предыдущей части нашего с вами материала, посвященного детекции поискового спама, алгоритм SpamRank (его прямым аналогом является Google BadRank, который персонализировано рассчитывается по обнаруженным спам-документам на интернет-графе с инверсировано-направленными ребрами) представляет собой значение, оценивающее незаслуженный PageRank интернет-страниц. Первый его этап можно схематично представить следующим образом (Рис. 42):

Для начала, с помощью нового алгоритма Монте-Карло из [4] мы вычисляем аппроксимированные значения персонализированного PageRank для всех страниц j; его настройки позволяют вычислять наборы, состоящие из 1000 узлов i вместе с весом Supportj,i. Этот вес может быть интерпретирован как вероятность того, что в модели случайного блуждания, шаг начинается с точки j, а закончится на концевой вершине в точке i. В целях экономии оперативной памяти мы инвертируем наши данные посредством алгоритма внешней сортировки, и для всякой страницы i рассматриваем такой список страниц j, где i ранжируется выше нежели чем при персонализации по j. Обратите внимание, что Supportj,i следует из имитационного моделирования по методу Монте-Карло и, поэтому, его значение равно 0 для всех j с несущественным значением персонализированного PR. Для заданной страницы i, штрафные санкции назначаются с учетом гистограммы PageRank всех i с весом Supportj,i > 0. Те веб-старницы, которые имеют менее чем n0 саппортеров (в нашем эксперименте n0=1000) — игнорируются, поскольку в случае распространения персонализированного PR саппортеров к своим целям с менее чем n0 входящих путей, сила их негативного влияния не столь ощутима.

Рис. 43 Два варианта расчета штрафных санкций для страниц
Основу нашего алгоритма составляет идентификация аномального распределения PageRank саппортеров. Учитывая такие показатели, как p≤1, где p=1 означало бы наличие идеальной статистической закономерности, мы приступаем к наложению штрафных санкций для всех саппортеров пропорционально (p0-p), то есть в том случае, если показатель оказывается ниже предельно допустимого порогового значения p0, мы накладываем штраф. В том варианте наших экспериментов, где наложение санкции также осуществлялось пропорционально той поддержке, которое оказывали саппортеры для страниц интернет-сайтов ((p0-p)⋅Supportj,i), оказывалось еще более эффективным. Для наказания одной страницы мы также установили верхний предел в 1; однако в случае наказания некоторого множества документов штрафы аккумулируются.

Рис. 44 Два варианта вычисления отклонений для страницы i
В соответствии со схемой, указанной на Рисунке 44, мы можем сравнивать гистограмму PageRank всех саппортеров j всякой страницы i либо с Supporti,j > 0, либо с результатом Supporti,j⋅PageRankj для всех цифровых документов. Вопреки мнимой софистики второго варианта, для наших исследований более предпочтительным представляется именно первый случай. Для того чтобы проверить наши данные на соответствие закону распределения, мы разобьем все наши интернет-документы по PR-блокам, возрастающим в геометрической прогрессии как a⋅bk (a=0.1 и b=0.7). Теоретически размер блока k для степенного закона распределения голосующей способности будет иметь вид:
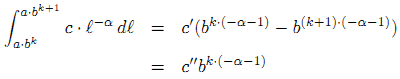
Конкретно для этого примера, наложение штрафных санкций осуществляться пропорционально линейному коэффициенту корреляции Пирсона между безразмерным индексом (его значения варьируют в диапазоне от -1,0 до 1,0 включительно) и логарифмом подсчета значений PageRank в обозначенных блоках.
Данные были любезно предоставлены Torsten Suel и Yen-Yu Chen, и включали в себя интернет-граф с набором URL-адресов, извлеченных из 31.2 млн. отсканированных документов краулером Polybot в доменной зоны .DE в апреле 2004 года. Полученный немецкий граф был достаточно плотным, то есть количество соединений у него было несколько большим нежели чем у обычных веб-графов, так он имел 962 млн. ребер, что подразумевало среднее значение полуисхода вершины в 30.82. Несмотря на то, что все приведенные нами методы относились к алгоритмам внешней сортировки, мы применили методологию простого сжатия нашего графа (после чего его размер составил 1.3 Гб) для ускорения наших экспериментов посредством использования внутренней памяти. Вычисление персонализированного PageRank методом Монте-Карло для всех узлов в общей сложности заняло у нас 17 часов, создание инвертированной базы данных PPR отняло 4 часа, и в результате наша база данных составила 14 Гб. Определение персонализированного вектора SpamRank заняло 20 минут, по истечению которых еще 20 минут ушло на вычисление Google PageRank простым степенным методом.
Для оценки сигналов, подаваемых SpamRank, мы выбрали подмножество методов, представленных в [9]. Вначале мы упорядочили все страницы в соответствии с их показателями Google PR и разместили их в 20 блоков, каждый из которых содержал в себе по 5% их общей голосующей способности, при этом в первом блоке располагались документы с самым высоким значением PageRank. В случайном порядке из каждого созданного блока равномерно избиралось по 50 URL-адресов, в результате чего мы имели сильное смещение для 1000 страниц-образцов в сторону документов с высоким PR. Далее мы в ручную отнесли 400 страниц к следующим категориям: трастовые сайты, веб организации, реклама, спам, несуществующий ресурс, пустое содержимое, зеркала сайтов и неизвестное содержимое [9]. При использовании каппа-статистики мы наблюдали крайне низкий Κ-коэффициент [10], составляющий 0.45 для более чем 100 пар URL-адресов. Большинство расхождений, которое не попадало под категорию случайностей, во многом можно было объяснить отличающимися рейтингами веб-страниц по причине их участия в различных партнерских программах, сервисах по «накрутке» кликов и т.д. Надо сказать, что это служит наглядным доказательством того, что задача оценки ссылочного спама является нетривиальной также и для человеческого ума. Поэтому мы пересмотрели классификацию для нашего полного набора, состоящего из 1000 страниц-образцов, с учетом всех полученных замечаний и накопленного опыта. Также необходимо заметить, что за период наших наблюдений данные о спам-ресурсах очень быстро менялись, в частности многие из них переходили в категорию «несуществующие» (Рис. 45).
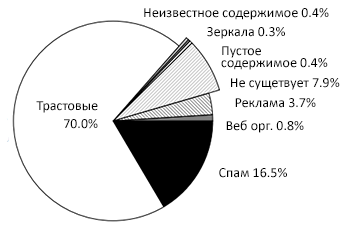
Рис. 45 Распределение документов по категориям на апрель 2004
После исключения из дальнейшего рассмотрения зеркал сайтов, несуществующих документов, а также тех, которые имели пустое содержимое, наша выборка состояла уже из 910 страниц-образцов. Обратите внимание на то, что по причине плотного графа и значительной активности компаний, осуществляющих продвижение сайтов в зоне .DE [12], доля спама в ней несколько больше, чем в предыдущих исследованиях [9,11]. Вследствие большого объема страниц (0.8 млн.), относящихся к домену eBay.de и определенными затруднениями, касательно их корректного анализа, мы решили выделить для него отдельную категорию, которая будет отображена в дальнейшем.
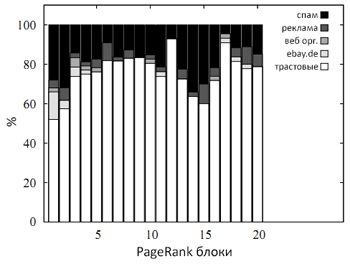
Рис. 46 Распределение категорий по PR-блокам
Глядя на рисунок 46 можно увидеть, что на первые два блока приходится достаточно большое количество спама, и их доля даже более значительна, чем в нашей исходной выборке. Далее мы размещаем все наши HTML-страницы по 20 SpamRank-блокам, каждый из которых содержит точно такое же количество документов, что и при размещении по голосующей способности.
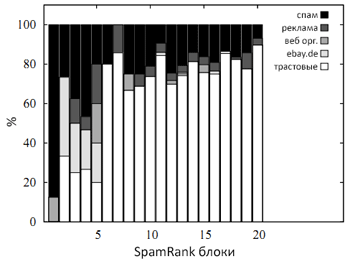
Рис. 47 Аналогичное распределение категорий по SR-блокам.
Рисунок 47 демонстрирует нам выборку, стратифицированную посредством Google PageRank, в которой первые четыре блока содержит очень большое число спам-страниц при крайне низком показателе наличия качественных документов, не относящихся к ресурсу eBay.de. Так как наш метод существенно отличается от того же самого Google RageRank, мы не смогли применить к нему такие распространенные метрики оценки качества, которое используются для подавляющего большинства алгоритмов извлечения информации, как точность (precision) и полнота (recall). Ниже (рис. 48) приводится результат распределения категорий внутри ТОП5 SP-блоков для нашей новой выборки:
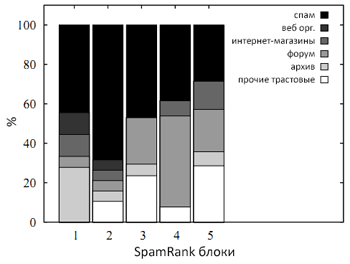
Рис. 48 Распределение категорий внутри ТОП5 SP-блоков
Несмотря на то, что более чем половина страниц из представленных SP-блоков не относится к спамденсингу, последующая мануальная проверка выявила их принадлежность к сайтам с очень плотной и шаблонной внутренней структурой. Среди них были форумы, он-лайн каталоги розничных продаж и структурированные архивы документов. С точки зрения Google PageRank, автоматическая генерация внутренней ссылочной структуры создает некое подобие ссылочных ферм, по этой самой причине (нравится ли вам это или нет) мы считаем вполне справедливым отнесение всех вышеуказанных сайтов к схемам манипуляции алгоритмом авторитетности PR.
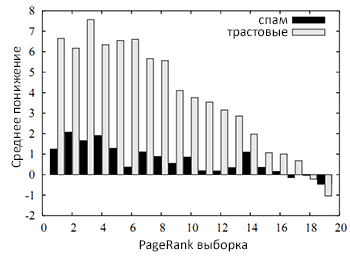
Рис. 49. Среднее понижение
На рисунке 49 мы показали вам среднюю разницу между количеством интернет-документов в PageRank и SpamRank блоках, которые были отнесенны к спаму и трасту (включая eBay.de), со стратификацией по Google PageRank. Как вы можете видеть, среднее понижение доли трастовых сайтов для SpamRank существенно превышает PR, а незначительное положительное понижение для спам документов объясняется наличием в новом наборе (см. Рис. 48) некоторого числа свежих некачественных страниц, не участвовавших в нашей первоначальной выборке.
Когда мы подробно описывали вам работу алгоритма Google TrustRank, мы выяснили, что его расчет начинается с заданного множества web-документов, которые имеют ручную отметку как «траст», далее совершается случайное блуждание в некоторое количество шагов (как правило, порядка 20) с последующим возвратом к первоначальной трастовой выборке с определенной вероятностью на всяком шагу (как правило 0.15). Полученная вероятность достижения документа и является его оценкой. Соответственно, при низком показателе трастовости интернет-страницы вкупе с высокими показателями ее Google PageRank, мы считаем ресурс подозрительным. В алгоритме Anti-TrustRank используется схожий интуитивный подход, но в несколько ином виде. Как и в Google TrustRank, мы также исходим из принципа аппроксимирующей изоляции качественных и плохих веб-сайтов. Иными словами, крайне маловероятно, чтобы хороший, трастовый документ ссылался из своего содержимого на спам-ресурс. Однако в то время как расчет алгоритма TrustRank начинается с установленного набора трастовых сайтов (например, каталог DMOZ) и распространяет свое доверие по исходящим ссылкам, Anti-TrustRank распространяется инверсивно по входящим ссылкам, начиная с установленного набора некачественных страниц. В том случае, если значение показателя недоверия превышает предельно допустимое пороговое значение, мы можем классифицировать данную страницу как спам. При другом варианте, мы можем просто возвратить список топовых n-страниц на основании предположения нашего алгоритма о том, что все они являются носителями спама. Интересно то, что ни Google TrustRank, ни Anti-TrustRank не могут в одиночку решать такие специфические задачи, как, например, распознавание естественных и «продажных» ссылок на конкретных страницах. Тем не менее, принцип аппроксимирующей изоляции позволяет достаточно хорошо отличать качественные веб-сайты от ярко выраженных спам-документов с присущими им тематиками.
Если говорить о выборе спам-страниц для нашего Seed Set, то как и в [9] мы имеем ряд сложностей, касательно подбора документов для нашего первоначального набора. Во-первых, по нашему замыслу он должен быть достаточно большим с минимальным количеством шагов, совершаемых в случайном блуждании, а во-вторых, должен включать в себя даже спам-страницы с относительно высокими показателями Google PageRank. Сам алгоритм недоверия Anti-TrustRank может быть представлен следующим образом:
Первоначально, мы равномерно распределяем значения Anti-TrustRank между всеми документами из нашего исходного набора. Дальнейшие вычисления сводятся к простому расчету инверсивного Google PageRank (учитываем не входящие ссылки на сайт, а исходящие, отдающие голосующую способность) с Teleport Set. Схематично, процесс пропагации недоверия представлен на Рисунке 50. Как вы можете видеть, случаи цитирования хорошими страницами некачественных веб-узлов относительно редки. Кроме этого, по мере отдаления от исходного спам-набора показатель данного недоверия будет затухать, поэтому даже при наличии ссылки на подозрительную страницу наш замечательный во всех отношениях сайт (узел 6) получит не столь высокое приращение Anti-TrustRank.
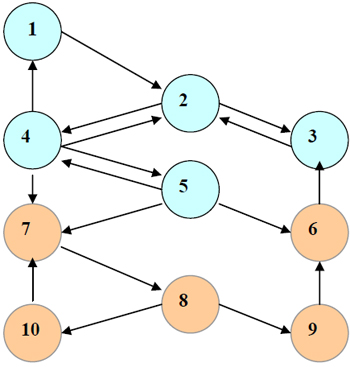
Рис. 50 Схема распространения недоверия для 10 веб-узлов, расположеных по принципу аппроксимирующей изоляции. Оранжевым цветом обозначены трастовые страницы, а синим — спам-узлы.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации