SEO-Константа
Яндекс.Директ + оптимизация
В данном материале мы продолжаем наше исследование, начатое в работе [8], на предмет поискового спама — попавших в индекс поисковой машины искусственно созданных страниц, основная цель которых заключается в манипуляции результатами органического поиска, привлечения трафика на определенные страницы сайтов как в задачах извлечения прибылей, так и потехи ради. Эта статья рассматривает некоторые ранее неописанные методы автоматического определения спам-документов, анализируется их эффективность как в случае их комбинирования, так и по отдельности. При их комбинации, мы корректно идентифицируем 2037 (86.2%) из 2364 спам-страниц (13.8%) в нашей общей коллекции, всего содержащей 17.168 документов, в то время как ошибочное отнесение к спам-классу качественных веб-документов составляет 526 (3.1%) страниц.
С момента возникновения интернета как системы передачи информации, доступной лишь ограниченному числу научных учреждений, интернет развился до поистине глобальных масштабов, став во главу угла нашей культурной, образовательной, а в особенности коммерческой жизни. Сегодня миллионы пользователей совершают различные финансовые операции на страницах интернет-сайтов начиная от бытовых, в том числе покупку всевозможных товаров, бронирование отелей и поездок, и заканчивая подачей заявок на выпуск банковских карт, оформление ипотеки и т.д. Для того чтобы найти всю необходимую для себя информацию в огромном объеме имеющихся интернет данных, веб-пользователи обычно используют поисковые системы. Учитывая пользовательский запрос, подобного рода поисковая машина определяет наиболее релевантные документы, которые предварительно скачиваются ее агентами накопления данных (роботами), и предлагает их пользователю в порядке убывающей полезности. Как правило, страница выдачи результатов содержит в себе от 10 до 20 ссылок, которые ведут на документ-оригинал. В последние несколько лет модель нахождения релевантной информации посредством применения систем информационного поиска стала повсеместной и крайне востребованной. По нескольким сайтам мы наблюдаем увеличение трафика, поступающего из реферальных поисковых систем. Так, например, ресурс «HypertextNow» (Jacob Nielsen) получает около 1/3 своего трафика через реферальный поиск [23], который увеличился с 2003 по 2004 год примерно на 9%. Интересно отметить, что основной рост пришелся на Google и Bing (16% и 4% соответственно) , в то время как трафик с Yahoo!, Ask и Lycos сократился. Для многих коммерческих веб-сайтов увеличение количества обращений с систем информационного поиска имеет прямую корреляцию с увеличением объема продаж продукции и/или услуг, выручки и, будем наедятся, прибылей. По данным «Бюро переписи населения» США, в 2004 году общий оборот в сфере электронной коммерции составил 96.2 млрд. долл. (или 1.9% от общего оборота в США); примечателен также тот факт, что электронная коммерция продолжает расти со скоростью 7.8% в год [6]. Американское независимое исследовательское агентство Forrester Research предсказывало, что в 2005 году онлайн бизнес между компаниями и физическими лицами (Business-to-Consumer) по реализации товаров, проведению аукционов и путешествиям должен составит порядка 172 млрд. долл. [18], и вырасти к 2010 году до 329 млрд. долл., что эквивалентно 13% всех розничных продаж, осуществляемых в США. Следовательно, для того, чтобы коммерческие сайты смогли воспользоваться прогнозируемым ростом электронной коммерции им необходимо увеличить приток пользователей со стороны поисковых систем, а достигается именно в том случае, если они отыскиваются по релевантным им поисковым запросам на первой странице органической выдачи. Действительно, учитывая то, что, во-первых, большая часть интернет-трафика следует с поисковых систем, а во-вторых, он может быть монетизирован, неудивительно, что некоторые веб-мастера стараются манипулировать позиционированием страниц своих сайтов в результатах поиска в той или иной степени. С одной стороны, некоторые из них реализуют вышеуказанные манипуляции посредством ряда этических средств, а именно: создания положительного имиджа, технологии белой оптимизации, улучшения качественных составляющих текстового и графического содержимого, а также предложения востребованной и полезной, сточки зрения их посетителей, информации. Однако с другой стороны мы видим множество веб-мастеров, которые не чураются применять агрессивные инструменты манипулирования функциями ранжирования за счет использования серых (этически не приветствующихся) и черных (откровенно запрещенных) SEO-схем. Подобного рода практики включают в себя создание дорвейных страниц, переадресующих пользователей на целевой ресурс и/или содержащих в своем контенте некоторую массу исходящих ссылок. Используя «нашпигованные» исходящими линками страницы, веб-сайт может увеличивать авторитетность целевого узла в глазах поисковой машины, а именно посредством воздействия на алгоритмы ссылочного ранжирования. Контент страниц в случае обманной технологии может быть «спроектирован» таким образом, чтобы привлекать как можно большее количество трафика — такой метод более известен как переоптимизация содержимого ключевыми словами. В данном случае мы наблюдаем надежду на то, что целевой узел будет иметь более высокие позиции в результатах поиска по интересующим запросам и, следовательно, иметь высокую посещаемость. Практика разработки веб-сайтов/страниц с единственной целью, заключающейся в увеличении позиций в рейтинге, без соответствующего улучшения качественной их составляющей для пользователя, называется «веб-спамом». На Рисунке 1 представлен типичный документ-представитель обманной технологии.
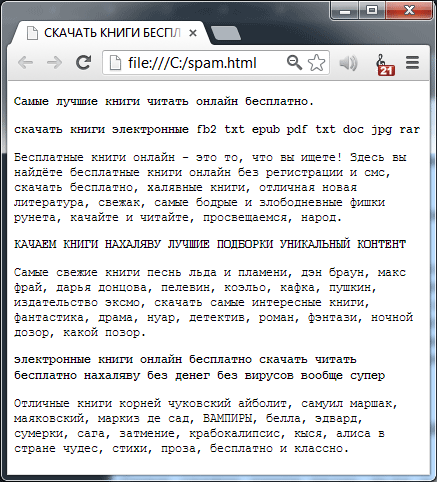
Рисунок 1. Пример типичной спам-страницы; она содержит популярные поисковые запросы, однако создана не для человека, а для поисковых роботов.
В контексте систем информационного поиска спамденсинг наносит ущерб механизмам ранжирования по нескольким причинам. Во-первых, спам-ресурсы лишают веб-мастеров, занимающихся продвижением сайтов в органическом поиске легальными методами, вполне законного дохода, который они могли бы иметь в том случае, если бы проблемы спама не существовало. Пренебрегая рекомендациями поисковых машин, даже добропорядочные сайты оказываются вольно или невольно замешанными в данной борьбе, становясь жертвами разрабатываемых анти-спам алгоритмов. Во-вторых, если поисковая система возвращает своим
пользователям нерелевантные ответы, то это незамедлительно отобразится на их отношении к поисковику и уменьшит их аудиторию, что будет являться следствием глубокого разочарования и неудовлетворенности результатами органического поиска. Наконец, сама поисковая система тратит огромные финансовые ресурсы на противодействие спам-технологиям. Детекция некачественного документа ухудшает пропускную способность сети, его обработка приводит к излишней нагрузке на центральный процессор (ЦП), а индексация идет в ущерб объему памяти. Учитывая количество спама в интернете (по нашим оценкам 13.8% англоязычных документов классифицируются как спам, что будет показано в Разделе 3), та поисковая система, которая не распознает некачественные страницы, отдает 1/7 своих ресурсов спаму.
Создание эффективных методов обнаружения спама представляется достаточно трудоемкой задачей, и учитывая размер веба, такие методы должны быть полностью автоматизированы. Тем не менее, при обнаружении спамденсинга мы должны быть уверенными в том, что наша технология способна корректно вычислять подобного рода некачественные документы и не классифицировать как спам страницы добропорядочные сайты. В то же время, с нашей точки зрения, наиболее успешным методом является тот, который позволяет вычислять спам документ как можно раньше, «еще на подлете» и, безусловно, до обработки пользовательского запроса. Таким образом, мы можем направить процесс сканирования, обработки и индексирования исключительно на качественные сайты, используя имеющиеся у нас ресурсы с большей эффективностью. В данном материале мы исследуем различные методы обнаружения поискового спама, каждый из которых отлично подходит для распараллеливания, может работать за время, пропорциональное размеру документа; распознает наличие в содержимом элементов запрещенных технологий посредством контентного анализа всякой отсканированной страницы. Мы предлагаем вам ознакомиться с результатами экспериментов, выполненных на подмножестве отсканированных узлов поисковой системы MSN (далее — Bing), демонстрирующих относительные достоинства каждого из предлагаемых нами методов. Мы также покажем вам, каким образом можно использовать машинное обучение для объединения отдельных технологий в высокоэффективный и достаточно аккуратный алгоритм обнаружения спама. Подходы, описанные в настоящем материале расширяют нашу предыдущую работу по вычислению спамденсинга [8,9]. Остальная часть нашей работы построена следующим образом: в Разделе 2 мы описываем нашу экспериментальную основу и реальный набор данных, использованный в настоящем исследовании. В Разделе 3 мы оцениваем распространение спама в отобранных из нашей выборки доменных зонах, а также среди числа веб-страниц, имеющих ту или иную языковую принадлежность. В Разделе 4 мы описываем и анализируем анти-спам технологии, а в Разделе 5 рассматриваем эффективность их использования в случае комбинирования. В Разделах 6 и 7 мы соответственно обсуждаем смежные работы по актуальной для нас теме, а также делаем необходимые выводы и определяем ключевые направления для предстоящих работ.
Для того чтобы разработать и оценить наш алгоритм обнаружения спамденсинга мы использовали коллекцию документов за август 2004 года, состоящую из 105484446 произвольно взятых интернет-страниц, отсканированных веб-краулером поисковой системы Bing [22]. Индексатор Bing обнаруживает новые документы преимущественно через поиск в ширину и применяет различные оценки авторитетности для планирования процедуры переиндексации уже найденных HTML-страниц. Вследствие применения такой политики сканирования, индексирование страниц может быть затруднено при равномерном случайном распределении, а именно сканер Bing отдает приоритет тем веб-графам, которые имеют сильную связанность, авторитетным и высококачественным узлам. В дополнение к этому, индексирующий механизм поисковой машины Bing уже использует всевозможные эвристические подходы для обнаружения спам-страниц, в том числе многие из тех, что были описаны нами в предыдущей работе [8]. Несмотря на то обстоятельство, что наш набор данных может не соответствовать т.н. «случайной сетевой выборке», мы полагаем, что используемые нами методы и количественные показатели, приводимые в настоящей статье могут быть чрезвычайно полезными для практического применения. Во-первых, хотя наш сканер акцентируется на авторитетные документы и веб-графы, обладающие сильной связанностью, данные страницы, как правило, отыскиваются в первых результатах органической выдачи, а следовательно результаты нашей работы незамедлительно скажутся на улучшении качества поиска с точки зрения его пользователей. Во-вторых, поскольку из поисковой базы некоторые некачественные документы уже могли быть исключены или пессимизированы, цифры и показатели, которые мы будем приводить в последующих разделах будут являться консервативной оценкой давления спамденсинга на результаты поиска. В следующем разделе мы рассмотрим распространение спама в вебе более подробно, и только после этого представим на ваш суд методологию его вычисления.
В этом разделе мы постараемся, во-первых, детально разобраться в проблеме распространения спама в Глобальной паутине, а во-вторых, попытаемся ответить на вопрос, какие страницы имеют большую вероятность оказаться некачественными с точки зрения поисковых алгоритмов, а какие наоборот, авторитетными узлами. Для того чтобы решить поставленные перед нами задачи мы провели два эксперимента. В ходе первого эксперимента, в котором мы исследовали доменные зоны, мы обнаружили, что некоторые из них имеют большую предрасположенность к спаму, чем прочие. С целью выявления данной закономерности, для каждого из восьми наиболее популярных доменов верхнего уровня, которые в своей совокупности дают 80% от всего объема интернет-страниц, содержащихся в нашей коллекции, мы создали случайные выборки различного размера с равномерным распределением веб-узлов во всякой из них. Каждая страница была классифицирована нами в мануальном режиме как спам или НЕ-спам. На Рисунке 2 показаны результаты описанного выше опыта.
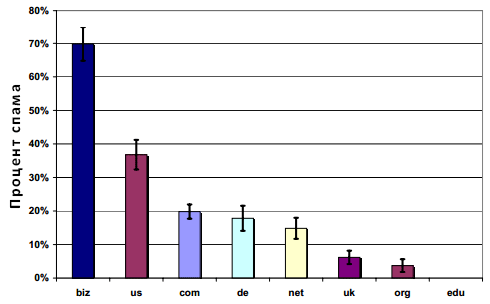
Рисунок 2. Распределение спама для доменов верхнего уровня (TLD) из нашего набора данных
По оси абсцисс отмечены домены верхнего уровня, а по оси ординат — доля спама в каждом из них; информация на данном графике отображаются с 95% интервалом доверия, представленный Т-образными вертикальными линиями. Доверительные интервалы различаются по своему размеру по причине различного объема выборок для каждой доменной зоны. Рисунок 2 демонстрирует, что домены верхнего уровня с наибольшим содержанием спам-документов относятся к .BIZ и .US (приблизительно 70% и 35% всех некачественных страниц соответственно). Как и следовало ожидать, в выборке, относящейся к .EDU спам отсутствует полностью. В нашем втором эксперименте мы пытались выявить связь между качеством страниц интернет сайтов и их языковой принадлежностью. Для реализации этого опыта мы избрали случайным образом документы, относящиеся к пяти наиболее популярным языкам из нашей интернет коллекции, которые в общей сложности дают 84% от всего объема страниц. Рисунок 3 демонстрирует результаты данного эксперимента.
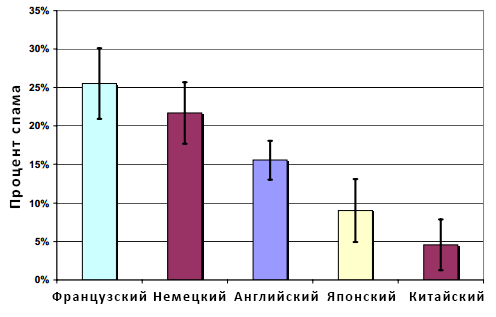
Рисунок 3. Распределение спама и языковая принадлежность страниц из нашего набора данных
По оси абсцисс отмечена языковая принадлежность документа, а по оси ординат — доля спама в каждой языковой группе. Как и прежде, все данные приведены с 95% интервалом доверия. Как вы можете видеть из графика, 25% страниц, написанных на французском языке классифицируются как спам; порядка 22% немецкоязычных документов также попадает под эту категорию. Отсюда мы видим, что доля некачественных с точки зрения поисковых алгоритмов сайтов в интернете достаточно велика. Кроме этого, в некоторых доменных зонах (например, .BIZ ) буквально изобилуют сайтами, использующие обманные практики и манипулятивные технологии. Все вышеуказанные наблюдения, естественным образом, приводят нас к поиску наиболее эффективных методов обнаружения спамденсинга, которые мы опишем в следующем разделе.
В нашей предыдущей работе WebDB [8], мы рассмотрели ряд эвристик, позволяющих эффективно обнаруживать спам, относящийся к содержимому интернет-страниц. Некоторые из них полностью не зависят от контента страниц (вместо использования таких характеристик, как гиперссылочная структура между документами и DNS-записи хостов), в то время как другие перерабатывают слова как неинтерпретированные токены (например, путем кластеризации схожих страниц в соответствующие наборы, а также посредством измерения скорости эволюции документа). В текущем материале мы рассмотрим дополнительный набор эвристик, каждая из которых базируется на содержимом веб-документа. Некоторые из них не зависят от языковой принадлежности сайта, другие же, наоборот, учитывают тот язык, на котором набран текст страницы. Синтаксический анализатор, применяемый в поиске Bing определил (краулер поискового механизма Bing использует собственные алгоритмы для определения языка документа, которые предполагают анализ не только мета информации), что в нашем наборе данных подавляющее большинство документов (порядка 54%) написаны на английском языке. Мы собрали равномерную случайную выборку (именуемую в дальнейшем DS), состоящую из 17168 англоязычных страниц от всего имеющегося объема в 105 млн. Мы также проводили соответствующие оценки для документов, написанных на французском и немецком языке, однако по причине нехватки места мы не включили их рассмотрение в настоящую работу. Хотя полученные результаты с англоязычными сайтами более-менее совпадают с теми данными, которые мы получили для прочих языков, некоторые особенности все-таки имеют место быть. Далее, мы вручную проверили каждый документ-эталон и сделали соответствующие отметки на предмет наличия или отсутствия в них спама, в том числе: 2364 страниц (13.8%) в выборке DS классифицировались нами как некачественные страницы, а 14804 (86.2%) — не имели отметки «спам». Далее мы детально исследуем большинство эвристик, базирующихся на содержимое интернет-страниц сайтов.
Одной из наиболее популярных обманных практик является дополнение содержимого веб-документа ключевыми фразами. Подобного рода технология предполагает пополнение (или, можно сказать даже более грубо, «шпигование») уже существующего контента некоторым числом высоко популярных ключевых фраз, которые нерелевантны оставшейся части страницы. В данном варианте, псевдо-оптимизатор надеется на то, что посредством смешивания посторонних слов с легитимным содержимым, спам-документ окажется релевантным большему количеству пользовательских запросов и, тем самым, увеличит приток трафика на страницы своего сайта. В большинстве случаев, для того, чтобы максимизировать свои шансы на возвращение документа пользователям, такой некачественный документ дополняется контентом с десятками, а иногда даже сотнями посторонних слов. В первом эксперименте мы попытаемся проверить, является ли само по себе избыточное употребление слов в документе (за исключением разметки) хорошим индикатором спама. Для этой цели мы учтем распределение числа слов для всякой интернет-страницы в имеющемся у нас наборе данных. Полученные результаты демонстрирует Рисунок 4.
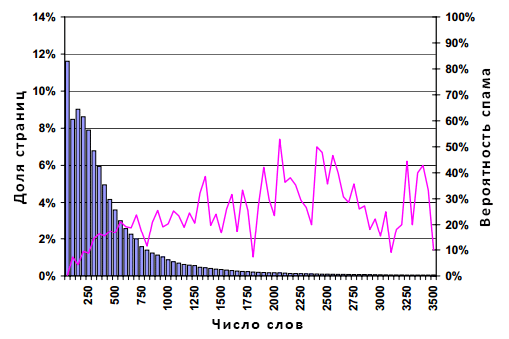
Рисунок 4. Распространение спама в зависимости от количества слов в документе
Данная фигура, как и все последующие, состоит из гистограммы и линейного графика. Гистограмма показывает распределение определенных аспектов (в нашем случае, количества неразмеченных слов) англоязычных страниц в 105 млн. коллекции. По оси абсцисс отмечен набор диапазона значений (на Рис. 4 первый диапазон содержит страницы, содержащие от 1 до 50 слов). Левая шкала оси ординат относится к гистограмме и изображает процент документов в англоязычной коллекции, которая попадает под заданный диапазон. Правая же шкала относится к линейному графику и изображает долю типовых страниц в каждом диапазоне, уличенных в применении манипулятивных практик. Как можно видеть из данного рисунка, более половины всех проанализированных документов содержат менее 300 слов, и только 12.7% всех страниц имеют контент объемом в 1000 слов. Наша гистограмма имеет смутное пуассоновское распределение с модой в 2 слова, медианой в 281 слово и средним значением в 429.2 слова. Распространенность некачественных страниц оказывается выше для документов с большим количеством слов в содержимом, хотя линейный график становится более зашумленным в правой части рисунка, что обусловлено меньшим количеством типовых страниц с большим объемом контента. В то время, как существует четкая корреляция между количеством слов и распространением спама, использование в своей работе исключительно подсчет их количества не позволяет говорить нам о хорошей эвристике, поскольку это влечет за собой крайне высокий уровень ложных срабатываний нашего алгоритма: практически для всех диапазонов доля спама оказывается ниже 50%.
Благодаря тому, что ориентируясь на TITLE веб-документа пользователь обнаруживает для себя релевантную информацию на странице результатов органической выдачи, а также по той простой причине, что некоторые поисковые машины придают больший вес тем страницам, в заголовке которых встречаются слова из пользовательского запроса, не менее популярной обманной технологией является перенасыщение ключевыми фразами и этого тега. В данном эксперименте, мы постараемся выяснить, является ли избыточное наличие ключевых слов сигналом о том, что перед нами некачественный документ. Иными словами, мы повторили предыдущий эксперимент с тем исключением, что на этот раз мы анализируем распределение количества слов включенных в TITLE страницы, игнорируя сам контент. Полученные результаты демонстрирует Рисунок 5.
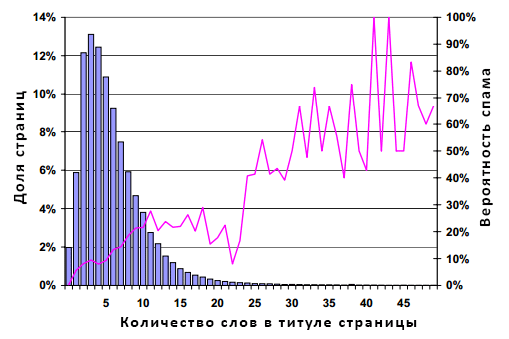
Рисунок 5. Распространение спама в зависимости от количества слов, входящих в TITLE страницы
Распределение здесь является логарифмически нормальным с модой в 3 слова, медианой порядка 5 слов и, наконец, средним значением в 5.96 слов. Как и в предыдущий раз, распространение некачественных документов оказывается выше для тех из страниц, которые имеют большее количество слов в TITLE; линейный график также становится более зашумленным в правой части рисунка. Примечателен разрыв между длинной заголовка страниц в 24 слова и более; документы со столь длинными названиями, скорее всего, следует отнести к спаму, однако, к сожалению, на них приходится лишь 1.2% от всего объема страниц, содержащихся в нашей выборке. Если сравнить самую крайнюю правую часть рисунков 4 и 5 можно обнаружить, что избыточное употребление слов в TITLE документа представляется для нас куда более лучшим индикатором некачественного ресурса, нежели чем подсчет общего количества слов на странице.
Одной из достаточно редких манипулятивных практик, которую нам довелось наблюдать в мануально помеченных документах из нашего набора данных, является применение «сложных» слов в контенте некачественных страниц. Эта техника представляет собой переоптимизацию в более развитом смысле, посредством объединения небольшого числа простых слов (2-4) в более длинные сложные слова. В качестве примера можно привести выражения «скачатьвидео», «mp3бесплатно» и т.п. Как вы наверное сами догадались, такая спам страница ориентируется на определенный класс запросов, введенных в строку поиска с опечаткой, а именно тот случай, когда пользователь забывает поставить пробел между словами, составляющих его вопрос. Для того, чтобы исследовать это явление, далее мы вычислили среднюю длину (в символах) неразмеченных слов во всяком документе, получив следующее распределение (см. Рисунок 6).
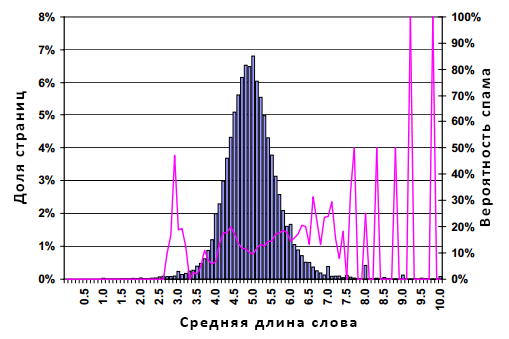
Рисунок 6. Распространение спама в зависимости от средней длины слов на странице
Ось абсцисс на рисунке представляет собой среднюю длину слов на странице. Здесь распределение имеет колоколообразную форму с модой, медианой и средним значением в 5.0. Для большинства документов, имеющих среднюю длину слова в диапазоне между 4 и 6, характерно распространение спама в масштабе от 10 до 20%. Однако рисунок 6 демонстрирует прямую корреляцию между средней длиной слова и вероятностью нахождения спамденсинга. Поэтому, 50% страниц со средней длиной слова в 8 относятся к подозрительным страницам, а со средней длиной слова в 10 — все эталонные документы оказываются спамом.
Другой распространенной практикой в системах информационного поиска, является использование текста анкоров внешних входящих ссылок в качестве аннотации, описывающих содержимое целевого документа и/или веб-сайта. Основная идея заключается здесь в том, что если страница А имеет исходящий линк на документ B, где в качестве ссылочного анкора используется слово «компьютеры», то логическим умозаключением машина приходит к тому, что страница B посвящена компьютерам, даже в том случае, когда данное слово не встречается на целевом документе. Некоторые поисковые системы учитывают ссылочные анкоры при ранжировании сайтов в результатах органической выдачи и могут возвращать страницу B в числе результатов по вышеуказанному запросу, особенно в том случае, если удовлетворение подобного пользовательского запроса представляется достаточно трудным. Следовательно, определенное число спам-документов существуют исключительно для того, чтобы, посредством проставления исходящих ссылок на сторонние сайты, реализовывать данную манипулятивную технологию. К подобного рода некачественным страницам чаще всего относятся каталоги ссылок, цитирующих из своего содержимого всевозможные инетрнет-ресурсы. Для исследования спама, играющего с анкорами линков, мы решили провести следующий эксперимент: для каждой веб-страницы из нашей выборки мы рассчитали долю всех слов из содержимого (за исключением разметки), относящихся к тексту ссылочных анкоров, а затем построили график распределения соответствующих им фракций. Полученные результаты демонстрирует Рисунок 7.
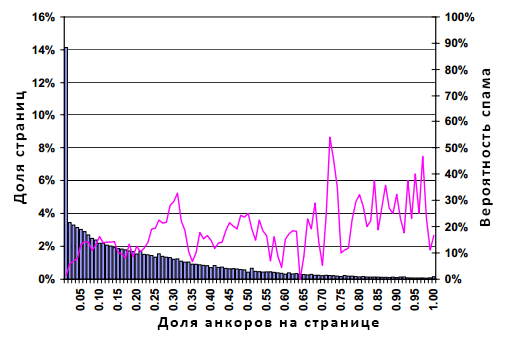
Рисунок 7. Распространение спама в зависимости от количества текста ссылочных анкоров на странице
Ось абсцисс на рисунке включает в себя диапазоны процента ссылочных анкоров (например, 5% — 5.99% анкорного текста). Самый высокий бар в левой части гистограммы означает, что контент 14.1% страниц содержит менее 1% текста ссылочных анкоров. Рассмотрение баров, смещающихся в правую сторону графика, указывают на постепенное снижение доли аналогичных документов, схожее с экспоненциальным затуханием, вплоть до достижения такого естественного максимального значения, при котором весь текст страницы представляется анкором гиперссылок. Модой распределения является 0%, медианой и средним значением 5% и 21% соответственно. Несмотря на присутствующую тенденциозность, кривая вероятности проявления спамденсинга, к большому сожалению, имеет не столь критический наклон. В целом, возрастающая доля ссылочных анкоров в тексте интернет-страницы может указывать на более высокую вероятность распространения спама, но, как и в разделе 4.1, полагание исключительно данного фактора в качестве индикатора некачественных страниц, может привести к большому числу ложных срабатываний нашего алгоритма, а потому не может считаться ключевым моментом настоящего анализа.
Для обеспечения более релевантной выдачи, некоторые поисковые машины используют при ранжировании сайтов информацию из определенных HTML-элементов, не отображаемых в интернет-обозревателях. К таким элементам можно отнести, например, МЕТА-теги в секции HEADER, комментарии в теле документа или атрибут ALT, устанавливающий альтернативный текст для изображений сайта. Подобного рода элементы имеют своей целью подсказки, которые наносит вебмастер, для указания агентам накопления данных на природу созданного им веб-документа, однако не менее часто они применяются для переоптимизации спам-страниц. Для того, чтобы разоблачить значимость той роли скрытого содержимого, которую он играет в среде некачественных ресурсов, мы подсчитали долю видимого контента среди всего числа наших страниц в имеющемся наборе данных. Рисунок 8 демонстрирует распределение долей видимого содержимого.
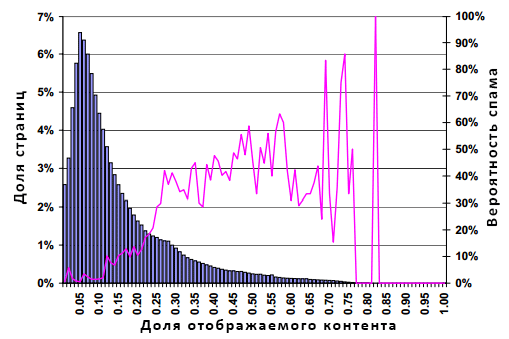
Рисунок 8. Распространение спама в зависимости от процента видимого контента страницы
Аналогично пятому графику, гистограмма имеет смутное логнормальное распределение с модой в 4%, медианой порядка 10% и средним значением в около 14%. Наш график показывает, что большинство страниц в подавляющем своем большинстве состоят из разметки, включающей в себя скрипты и блоки CSS. Очевидно, что данное распределение имеет тяжелый правый хвост, по сравнению с прочими графиками. Линейный график растет по мере увеличения доли видимого контента, обрываясь на доли видимого контента в 82% по той простой причине, что в данном наборе данных документов с большей фракцией не существовало. Отсюда можно сделать вывод о том, что в отличие от качественных страниц, многие спам-ресурсы содержать меньшую долю разметки. Это имеет интуитивный смысл: многие некачественные сайты создаются для поисковых роботов, а не для своих пользователей, используя всю ту же практику насыщения своего содержимого ключевыми словами. Следовательно, псевдо-оптимизаторы крайне мало уделяют внимания на эстетический аспект своего дела.
Некоторые поисковые системы придают больший вес страницам, имеющим многократные вхождения ключевых фраз в содержимое документа. Например, страница, которая имеет десять вхождений поискового запроса «продвижение сайтов«, будет ранжироваться выше, нежели чем однократное вхождение данной ключевой фразы. Для того чтобы реализовать эту технологию и занять более высокие позиции в результатах органической выдачи, некоторые некачественные сайты копируют содержимое своих страниц несколько раз. Существует множество методов улавливания повторяющегося текста или слов в пределах страницы, начиная от расчета распределения частоты слова в документе и заканчивая алгоритмом шинглов (см. работу [9]), позволяющего отыскивать дубликаты текста в содержимом цифрового документа. Для определения избыточного содержимого в пределах одной страницы, наш подход предполагает компрессию документа; для экономии пространства в хранилище индекса, а также при сохранении самих страниц, поисковые машины часто применяют компрессию документов после их соответствующего сканирования, но прежде процесса кэширования. Мы оцениваем избыточность веб-страницы посредством коэффициента компрессии; размера «сырого материала», поделенного на размер компрессированного документа. В качестве быстрого и эффективного алгоритма компрессии мы будем использовать функцию сжатия GZIP [14]. На Рисунке 9 отображена корреляция между коэффициентом компрессии и вероятностью того, что страница является некачественной.
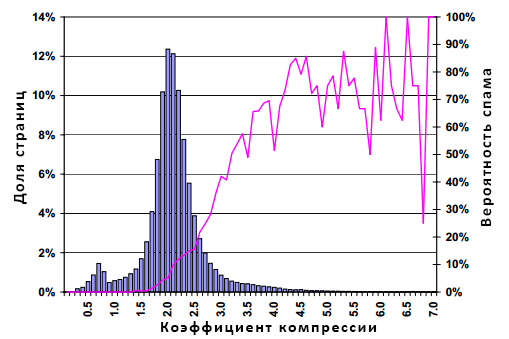
Рисунок 9. Распространение спама в зависимости от коэффициента компрессии
Распределение на полученной гистограмме снова имеет колоколообразную форму с модой в 2.0, медианой в 2.1 и средним значением в 2.11. Отметим, что в ходе реализации процесса сжатия, вес 4.8% страниц был увеличен. Вышеуказанная декомпрессия в компрессируемом потоке данных была связана с тем, что, несмотря на малый размер этих документов, произошло включение мета информации из секции HEADER и начального словаря. Линейный график, отображающий распространение спама, имеет тенденцию к постепенному росту в правой части нашего рисунка, а также демонстрирует зашумленность за пределами значения коэффициента компрессии, равного 4.0., что является следствием малого количества документов-образцов в заданном диапазоне. Тем не менее, в общей совокупности, 70% всех эталонных документов со значением коэффициента компрессии не меньшего 4.0 признаются нами некачественными.
В предыдущих разделах мы представили вам всевозможные варианты реализации технологии внедрения в контент страницы ключевых фраз. Однако по-прежнему остается открытым вопрос, из какого источника наш спам-документ «нашпиговывается» ключевыми выражениями? Берутся ли они вообще случайным образом из всего множества слов, существующих в английском языке, или при их отборе учитывается характерный набор типичных пользовательских запросов? Пример данного феномена был продемонстрирован на Рисунке 1, где генерируемые фразы, брались из определенного словаря, без учета тех артиклей и союзов, которые изредка обнаруживаются в поисковых запросах. Чтобы попытаться разобраться в этой проблеме, мы решили рассмотреть страницы на предмет избытка или дефицита ряда стоп-слов. Для начала мы определили в нашем корпусе N наиболее частотных слов, а затем рассчитали для всякой страницы их процент. Мы повторили эту процедуру для нескольких вариантов N; в настоящем разделе мы покажем вам результатирующий график только для N=200. Графики для N=100, 500 и 1000 по своим качественным параметрам представляются схожими с используемым здесь N=200.
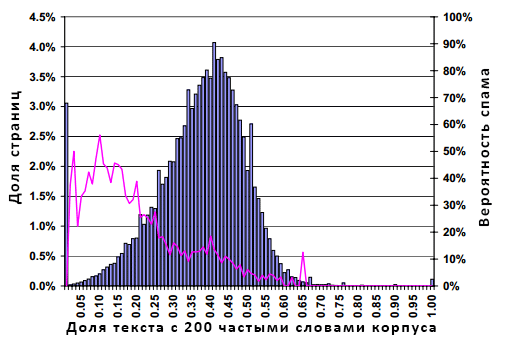
Рисунок 10. Распространение спама в зависимости от доли слов на странице, которые относятся к 200 наиболее частотным словам корпуса.
График 10 основывается на доле тех стоп-слов, которые содержатся в наборе из 200 наиболее частотных слов, встречающихся среди всех англоязычных страниц, представленных в нашей исходной коллекции из 105 млн. документов. Гистограмма имеет смутное гауссовское распределение с модой в 40%, медианой порядка 38% и средним значением в 36.2%. Линейный график возрастает в левой части нашего с вами рисунка, что свидетельствует о некотором классе некачественных страниц, генерирующихся не в соответствии с естественной частотой распределения слов в английском языке, а с использованием словаря в случайном равномерном порядке.
В разделе 4.7 мы изучили распространение спама среди интернет-страниц посредством рассмотрения доли стоп-слов в их содержимом. Надо сказать, что одним из элементарнейших способов, позволяющим обмануть нашу метрику является такая схема, которая предполагала бы включение в контент документа единичного стоп-слова n-е количество раз, поэтому в целях предупреждения этого потенциального шага черных оптимизаторов сейчас мы также измерим долю N самых употребляемых слов в контексте каждой конкретной страницы. Хотя на первый взгляд обе эти метрики могут показаться вам схожими по своей сути, в действительности между ними существует большое отличие. Для его объяснения давайте приведем следующий пример: допустим, что неопределенный артикль «a» является одним из наиболее популярных 500 слов английского языка. Если вернутся к метрике из раздела 4.7, то получается ситуация, при которой, если веб-документ содержит всего одно слово, и им является неопределенный артикль «а», тогда этот документ получает оценку 1, поскольку 100% слов на данной страничке было из разряда часто употребляемых. В случае второй метрики, если бы та же самая страница имела в своем контенте только одно слово, коим бы является артикль «а», тогда она получила бы оценку 1/500, поскольку только 1 стоп-слово из имеющихся 500 было бы обнаружено нашим анализатором контента. Основная интуиция в настоящем подходе заключается в том, что вопреки логическому утверждению о необходимости содержания в тексте документа некоторого количества стоп-слов, они должны быть относительно разнообразны.
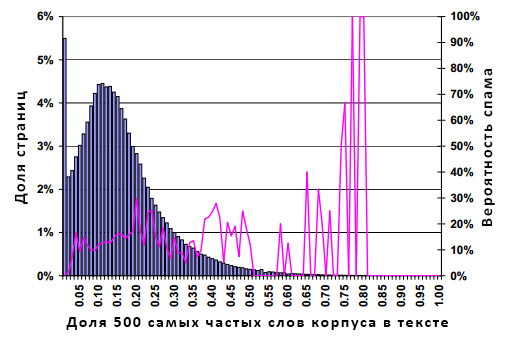
Рисунок 11. Распространение спама в зависимости от доли слов на странице, которые относятся к 500 наиболее частотным словам корпуса.
Рисунок 11 исходит из доли 500 наиболее употребляемых слов в содержимом документе. Гистограмма демонстрирует гауссовское распределение, усеченное в левой части рисунка. Распределение имеет моду в 0%, медиану в 13% и среднее значение в 14.9%. Распространение некачественных документов представляется незначительным на всем диапазоне, с резким всплеском среди тех нескольких страничек, где обнаруживается более 75% стоп-слов.
Достаточное количество спам-страниц содержит в себе набор слов, реализованных с помощью словаря более / менее случайным образом. Если использование слов в тексте страницы поддается случайному равномерному распределению, тогда технология, описанная нами в Разделе 4.7, сможет отметить эти некачественные документы надлежащим образом, однако в том случае, если распределение слов отражает естественную частоту слов в том или ином национальном языке, тогда вышеуказанная метрика оказывается бессильной. В идеале, мы бы хотели провести анализ содержимого документа на предмет его грамматической и семантической корректности, однако использование существующих технологий NLP представляется для нас чересчур дорогостоящим. Альтернативный, более мягкий подход заключается в применении статистических методов, отыскивающих вероятностную локальную согласованность. Говоря более конкретно, мы сегментируем всякую страничку из нашего большого корпуса на n-граммы n согласованных слов (типичные значениями для n являются 3 или 4). Мы определили вероятность n-грамм wi+1 … wi+n начиная со слова i+1 следующим образом:
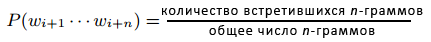
Обратите внимание, что n-граммы перекрываются; например, третье слово документа, перекрывается первым, вторым и третьим три-граммом (при том условии, что страница имеет не менее 5 слов). Однако мы делаем такое упрощающее предположение, при котором n-граммы выбираются независимо друг от друга. Данное предположение позволяет нам снизить потребление ресурсов памяти при расчете безусловной вероятности всех n-грамм. Тогда, вероятность страницы с k n-граммами (и, следовательно, k + n − 1 слов) является произведением безусловных вероятностей. Мы можем осуществить нормализацию по длине документа, извлекая k-ый корень произведения или, иными словами, посредством подсчета среднегеометрического безусловных вероятностей n-грамм:
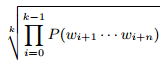
Мы можем минимизировать вычислительные затраты и избежать потери значимых разрядов посредством расчета логарифма, позволяющего переписать вышеуказанную формулу следующим образом:
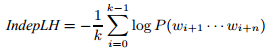
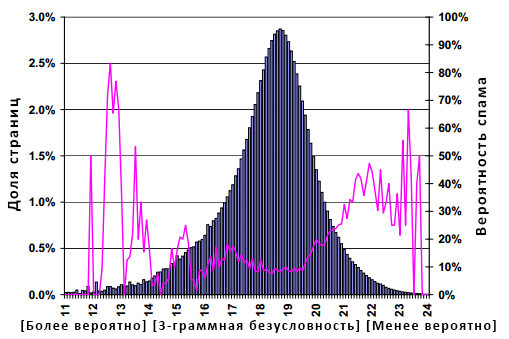
Рисунок 12. Распространение спама в зависимости от безусловной вероятности 3-граммного слова на странице.
Мы называем данную метрику безусловной вероятностью страницы; документы с высоким значением IndepLH состоят из редко встречающихся n-грамм. На Рисунке 12 отображена взаимосвязь между распределением безусловных вероятностей документа и вероятностью обнаружения среди их числа некачественной страницы. Как и на более ранних графиках, гистограмма имеет колоколообразную форму с модой 18.7, медианой 18.5 и средним значением 17.7. Поскольку линейный график возрастает как в правой, так и в левой части рисунка, то отсюда можно сделать выводы о том, что страницы, состоящие из часто встречающихся n-грамм, скорее всего, являются спамом (предположительно, это связано с самоповторяющейся природой некоторых некачественных документов); страницы, состоящие из неправдоподобных n-грамм, с большей достоверностью, являются спам-документами (предположительно, это связано с грамматической неестественностью рандомно сгенерированного текста).
Как уже упоминалось выше, метрика безусловной вероятности из раздела 4.9 основывается на том предположении, которое упрощает оценку вероятности отдельных n-грамм, рассматривая их независимо друг от друга. Для моделирования гораздо лучшим, но куда более затратным с точки зрения вычислительных процессов, является подсчет вероятности n-грамма по условию наличия префикса его (n – 1)-ого слова:
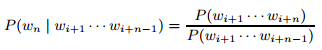
Используя это определение, а также выполняя аналогичные Разделу 4.9 преобразования, мы можем определить условную вероятность документа следующим образом:
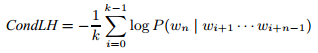
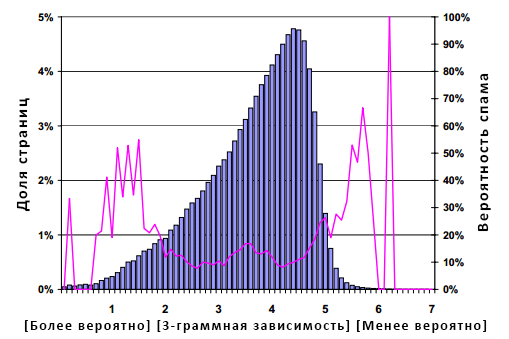
Рисунок 13. Распространение спама в зависимости от условной вероятности 3-граммного слова на странице.
На Рисунке 13 представлена взаимосвязь между распределением условной вероятности документа и вероятностью того, что он является спамом. Гистограмма напоминает реверсивное логарифмически нормальное распределение с модой в 4.4, медианой в 3.9 и средним значением в 3.53; линейный график аналогичен тому, что изображен на Рисунке 12.
В предыдущем разделе мы представили вам ряд эвристик для определения некачественного контента интернет-страниц. То есть, мы измерили несколько характеристик веб-документов, и определили диапазоны тех особенностей, которые имеют корреляцию со спам-страницей. Тем не менее, при применении наших эвристик по отдельности, ни одна из представленных технологий не позволяет выявлять подавляющую долю подозрительных страниц в имеющемся наборе данных. Например, рассматривая наиболее перспективный эвристический подход, описанный в Разделе 4.6, которая заключалась в расчете коэффициента компрессии, средняя вероятность спама для диапазона в 4.2 и выше составляет 72%. Однако к вышеуказанному диапазону относится только порядка 1.5% всех документов. Это значение существенно меньше 13.8% некачественных страниц, которые мы определили в нашей коллекции. Поэтому, в текущем разделе мы попытаемся выяснить, возможно ли увеличить эффективность детекции спама посредством комбинирования наших эвристик. Мы искренне надеемся, что в случае использования некоторого набора эвристических методов, с последующей их комбинацией мы сможем не только увеличить процент обнаруженных некачественных страниц, но и повысить аккуратность их отнесения к соответствующему классу. Одним из способов комбинирования наших эвристических алгоритмов является рассмотрение проблемы вычисления спама как типичную задачу классификации. В этом случае, нам необходимо создать классификационную модель (или, говоря проще, классификатор), которая будет использовать некоторый набор особенностей интернет-страниц для их корректной (как мы надеемся) классификации по следующим двум классам: спам или НЕ-спам. В общих чертах построение классификатора включает в себя этап обучения, в ходе которого мы определяем параметры классификации, и тестирования, где мы оцениваем его производительность. Для обучения нашего классификатора мы использовали мануально отклассифицированный набор данных DS, который и будет служить нам обучающей выборкой. Для нашего набора характеристик мы использовали метрики, описанные в Разделе 4, в том числе их вариации (например, мы рассчитали n-граммы для n=2,4 и 5 в соответствии с 3-граммами); 20 бинарных метрик, оценивающих случай вхождения таких специфичных выражений, как «Политика конфиденциальности», «Служба поддержки клиентов» и пр.; 8 особенностей, извлекаемых из содержимого документа, которые были описаны нами в WebDB в работе [8]. Для каждой веб-страницы из набора DS мы рассчитали соответствующий показатель для всякой характеристики с тем, чтобы в дальнейшем использовать эти полученные значения наряду с классификационной меткой при обучении нашего классификатора.
После экспериментов с различными технологиями классификации, в том числе мы исследовали алгоритмы построения деревьев решений, нейронные сети и машину опорных векторов, мы пришли к выводу, что деревья решения являются наиболее эффективным подходом, хотя прочие методы не столь существенно уступают в случае реализации наших задач классификации посредством их использования. По причине нехватки места в настоящей работе мы приведем вам результаты классификации, полученные в ходе применения алгоритма построения деревьев решений C 4.5 [26]. Точность прочих классификаторов оказалась ниже, нежели чем у алгоритма C 4.5, который работает следующим образом: с учетом обучающей выборки и набором характеристик, он создает блок-схему, подобную древовидной структуре. Листья нашего дерева соответствуют классам; во внутренних узлах содержатся атрибуты, по которым различаются случаи, а по ветвям мы спускаемся для соответствующей классификации того или иного случая. Поскольку мы говорим о построении оптимального дерева принятия решения, в алгоритме C 4.5 выбор всякого атрибута осуществляется посредством нормализованного прироста информации. В принципе более подробную информацию, касающуюся алгоритма C 4.5, пытливый читатель сможет получить в работе его разработчика Джона Квинлана [26]. Мы обучали наш классификатор на выборке DS. Фрагмент построенного нами классификационного дерева вы можете увидеть на Рисунке 14.

Рисунок 14. Фрагмент дерева принятия решений, построенного с применением алгоритма C4.5, которое мы используем для вычисления спама.
Для всякой веб-страницы мы осуществляем проверку значения характеристики, указанной в корневом узле дерева, и сравниваем ее с предельно допустимым пороговым показателем, ассоциированным с исходящими ребрами. В зависимости от полученного результата мы следуем по левой или правой ветви, а затем повторяем процедуру вплоть до достижения конечного узла, присваивающего текущему документу соответствующий класс. Например, некоторая страница, имеющая значение безусловной вероятности 5-грамм (см. Раздел 4.9) менее 13.73, и которая содержит не более 62 из 1000 используемых нами стоп-слов, классифицируется нами как НЕ-спам. Для того чтобы оценить аккуратность нашего классификатора, мы использовали технику 10-fold кросс-валидации. При 10-кратном скользящем контроле выборка разбивается на 10 непересекающихся блоков примерно одинакового объема, проводится 10 обучающих/проверочных шагов, каждый из которых использует 9 блоков для обучения классификатора, а оставшийся блок для проверки его эффективности. Используя классификатор C 4.5 и 10-fold кросс-валидацию, мы оцениваем каждую эвристику из Раздела 4 по отдельности. Эвристический подход, заключающийся в компрессии, который был описан нами в Разделе 4.6, показал лучший результат, корректно идентифицировав 660 (27.9%) спам-страниц в нашей коллекции, в то время как ошибка в распознавании составила 2068 (12.0%) всех исследуемых документов. Применяя все вышеперечисленные характеристики, аккуратность классификации после 10-кратного скользящего контроля составила: 95.4% всех исследуемых страниц, идентифицированных надлежащим образом, в то время как некорректно было распознано 4.6%. В частности, для класса некачественных документов 1940 из 2364 страниц были классифицированы нами правильно; для класса качественных документов корректно было классифицировано 14440 из 14804 страниц. Следовательно, ошибочно классифицировалось 788 веб-документов. Мы можем подвести итог производительности нашего классификатора используя матрицу точности-полноты. Эта матрица отражает полноту (то есть, процент страниц имеющих истинное отношение к искомому классу относительно всех страниц, соотнесенных с данным классом), а также точность (то есть, процент классифицированных интернет-страниц, принадлежащих к классу относительно всех веб-документов искомого класса, имеющихся в тестовой выборке):
| Класс | Полнота | Точность |
| Спам | 82.1% | 84.2% |
| НЕ-спам | 97.5% | 97.1% |
Полученные результаты выглядят обнадеживающе по двум причинам. Во-первых, посредством классификатора, позволившего комбинировать наши эвристические алгоритмы из Раздела 4, наша полнота для спам-страниц составила 82.1%, а точность оказалось столь же высокой и составила 84.2%. Во-вторых, наш классификатор очень хорошо распознал документы, имеющие качественное содержимое (полнота и точность для них составила 97.5% и 97.1% соответственно), то есть наказанию подверглась крайне незначительное число НЕ-спам страниц.
В целях улучшения аккуратности нашего классификатора, мы также проводили эксперименты с различными технологиями, способных выполнить данную задачу. Здесь мы сообщим вам о тех результатах, которые мы смогли получить, посредством реализации двух наиболее популярных алгоритмов — беггинга [5] и бустинга [10]. Обе технологии по существу создают набор классификаторов, которые затем комбинируются для получения композиций. В большинстве случаев, композитный классификатор работает лучше, нежели чем любой из них по отдельности. В самых общих чертах, алгоритм беггинга работает следующим образом: для данного обучающего набора DS мы создаем N обучающих множеств или, как их еще называют, бутстреп-выборки, состоящих из n случайных элементов без повторов (так как некоторые образцы могут встречаться в обучающем наборе многократно). Для каждого N множества мы создаем классификатор, получая, в конечном счете, аналогичное количество N классификаторов; выходы всех классификаторов объединяются (агрегируются) посредством простого голосования. Более подробную информацию, касательно алгоритма беггинга вы можете получить в [5,27]. Каждое обучающее множество имело размер 15453, а для тестирования было оставлено 1717 элементов. Мы выбрали N = 10 и n=15453, то есть равное по размеру обучающему множеству. После применения беггинга к классификатору C 4.5, описанному в предыдущем разделе, мы получаем следующие значения точности/полноты:
| Класс | Полнота | Точность |
| Спам | 84.4% | 91.2% |
| НЕ-спам | 98.7% | 97.5% |
Таблица 2. Точность и полнота после беггинга
Как вы можете видеть, алгоритм беггинга улучшает аккуратность классификации. Если касаться страниц, отнесенных к классу некачественных документов, то 1995 из 2364 были отнесены к данной категории абсолютно верно. Для класса качественных страниц, корректное отнесение составило 14611 из 14804 документов. Следовательно, некорректно классифицировались только 562 документа, объем которых без применения беггинга, как вы наверно помните, составлял 788 единиц.
Вторая технология, повышающая аккуратность нашего классификатора, называется бустинг, и она работает следующим образом. Мы присваиваем веса каждому элементу в нашей обучающей выборке. В начале все элементы имеют весовое значение равное 1/n, где n является размером обучающего множества (в нашем случае n=15453). На каждой итерации алгоритма бустинга, обучающая выборка вместе с присвоенными весовыми значениями используется для создания последующего классификатора. Для каждого ошибочно классифицированного элемента в обучающем наборе, мы изменяем его вес таким образом, что его значение возрастает, то есть он получает добавочное весовое приращение, а веса правильно классифицированных элементов, наоборот, уменьшаются. Таким образом, для последующего классификатора наибольший приоритет будут иметь некорректно распознанные элементы, и обучение на которых позволит исправить ошибки предыдущего классификатора. Более подробную информацию, касательно алгоритма бустинга заинтересованный читатель сможет получить в [10, 27]. Для нашего случая мы снова выбираем N=10. После применения бустинга к классификатору C 4.5 мы получаем следующие значения точности/полноты:
| Класс | Полнота | Точность |
| Спам | 86.2% | 91.1% |
| НЕ-спам | 98.7% | 97.8% |
Таблица 3. Точность и полнота после бустинга
Как вы можете видеть, здесь мы смогли корректно классифицировать 2037 из 2364 документов относящихся к классу некачественных страниц. Аналогично, нам удалось корректно классифицировать 14605 из 14804 качественных документов. То есть, некорректно классифицированными остались 526 интернет-страниц, в то время как в случае использования алгоритма беггинга значение составляло 562. Следовательно, имеем небольшое улучшение, которое в условиях реального веб-поиска может оказаться кране значительным.
Явление веб-спама столь же старо, как и сам интернет. Однако наибольшего своего распространения он достиг именно за последние несколько лет, по той простой причине, что все большее число веб-мастеров стало применять его в качестве средства для достижения более высоких позиций в органическом поиске, увеличения трафика и, следовательно, достижения большего дохода. Вместе с тем, со стороны научного сообщества данная проблематика получило свое пристальное внимание относительно недавно. Далее мы рассмотрим ряд предшествующих нашей работе исследований, которые пересекаются с текущим материалом. Технологии машинного обучения, аналогичные классификатору C4.5, который мы использовали в Разделе 5, успешно применяются для фильтрации почтового спама (например, работы [16,28]. Здесь мы подтверждаем высокий потенциал машинного обучения в задачах определения спама, но именно в нашем случае мы фокусируемся на ортогональной проблеме веб-спама, где контент страниц предназначается не для человека, а для поисковых роботов. Что же касается общей роли и механизма поискового спама, то Henzinger и др. в [15] признают давление некачественных ресурсов на качество систем информационного поиска. Perkins в работе [25], пропагандирующей этическое поведение, описывает ряд манипулятивных технологий. Gyongyi и Garcia-Molina [13] дают более формальную таксономию веб-спама. Metaxas и DeStefano [20] указывают на взаимосвязь между поисковым спамом и источниками недостоверной информации, называемой пропагандой. В целом, данные исследования позволяют распознать и решить три основных вида поискового спама: ссылочный спам, клоакинг и спам, относящийся к содержимому страницы. Давайте теперь остановимся на каждом из них немного подробнее.
Под ссылочным спамом подразумевается практика проставления неестественных и вводящих в заблуждение линков на интернет-страницы, или добавление в поисковый индекс документов, содержащих только гиперссылки. К самой ранней работе, посвященной исследованию ссылочного спама, можно отнести Davison [7], в которой автор рассматривает непотистские (кумовские) ссылки. С момента ее публикации, последующие работы были сфокусированы на ссылочном спаме и методах его обнаружения, а также не модификациях уже существующих ссылочных алгоритмов ранжирования. Для того, чтобы вычислить ссылочный спам, Amitay и др. [2] включили связующие особенности интернет-страниц в классификатор, основанный на правилах. Baeza-Yates и др. [3] представили исследование топологического сговора, создаваемого для завышения значения Google PageRank [24], в то время как Adali и др. [1] показали, что массовая генерация документов, которые ссылаются на одну единственную целевую страницу, является самым эффективным инструментом манипулирования ссылочными алгоритмами ранжирования. С этой целю, Zhang и др. [31] показали, каким образом сделать классический алгоритм Google pageRank устойчивым к подобного рода атакам; Gyongyi и др. в своей работе [11] представили алгоритм доверия, называемый TrustRank, и который обнаруживает качественные страницы посредством следования по исходящим ссылкам из начального множества трастовых документов. Benczur и др. [4] продемонстрировали. каким образом осуществлять штрафование тех веб-страниц, что увеличили свою голосующую способность с применением «подозрительных методов». Вычислением ссылочных ферм (то есть веб-сайтов, осуществляющих взаимовыгодный обмен линками) занимались Wu и Davison в [29] и Gyongyi и Garcia-Molina в [12]. В нашей предыдущей работе [8] мы показали вам способ обнаружения ссылочного спама, который базируется на отслеживании отклонений в распределении веб-сайтов от степенного закона. Наконец, для вычисления ссылочного спама в комментариях блогов, Mishne и др. [21] представили вероятностный алгоритм, использующий данные о частотах слов. Поскольку в текущей работе мы фокусировались на вычислении контентного спама, который противопоставляется ссылочным практикам, то можно сказать, что она не развивает, а только дополняет все указанные выше исследования.
Под контентным спамом подразумевают такую технологию «разработки» содержимого, которая позволяет веб-документу быть релевантным популярным пользовательским запросам. В своей предыдущей работе [8] мы изучали распространение спама посредством учета определенных свойств интернет-страниц, относящихся к контенту. Мы обнаружили, что такие характеристики, как длина имен хостов, а также наличие в них обильного числа тире, точек и цифр; незначительные различия в количестве слов каждой отдельной странице веб-сайта; частое и существенное обновление контента в промежутках между успешными заходами на ресурс, в большинстве своем случаев могут служить хорошими индикаторами неестественной природы цифрового документа. В своей последующей работе [9] мы исследовали частный случай контентного спама, который предполагает наполнение страниц некачественного сайта текстовыми фрагментами с различных качественных ресурсов, то есть в этим варианте мы имеем посюсторонний мозайчатый контент, составленный из потустороннего оригинального содержимого. Там же представлены методы для обнаружения данного спама, посредством идентификации популярных шинглов. В текущей работе мы представили вам различные методы вычисления контентного спама, которые значительно расширяют наши предыдущие исследования [8,9].
Наконец, под клоакингом понимается практика отдачи пользователям и поисковым работам отличного содержимого. В работе Gyongyi и Garcia-Molina [13] представлен обзор современных методов клоакинга. Wu и Davison [30] продемонстрировали эффективность вычисления клоакинга, посредством применения такого метода, который основывается на подсчете общих слов между тремя отдельными копиями интернет-страницы. Здесь необходимо отметить, что в ряде случаев, клоакинг имеет своей целью не введение в заблуждение пользователей и агентов накопления данных, а реализацию вполне полезной функции, например, при возврате поисковой системе копии веб-документа без разметки, которая уменьшает нагрузку на Сеть и затраты на хранение информации.
Мы исследовали различные аспекты контентного спама во Всемирной паутине, используя реальный набор данных поисковой системы Bing. Мы представили ряд эвристических алгоритмов для вычисления некачественного содержимого. Некоторые из предложенных нами методов оказались более эффективными по сравнению с прочими алгоритмами, однако, при их отдельном применении, ни один из них не смог достичь столь впечатляющих результатов, какие были получены при их определенной комбинации. Именно по этой причине мы объединили все наши методы обнаружения спама для создания сверх аккуратного классификатора C 4.5. Наш композитный классификатор может корректно идентифицировать 86.2% всех спам-страниц, в то время как некорректное отнесение к классу некачественных документов страниц с легитимным содержимым составляет абсолютно незначительный процент. Сейчас мы вкратце обсудим некоторые направления для наших последующих работ. Мы прекрасно понимаем, что ряд наших анти-спам алгоритмов можно легко обмануть, однако в случае их комбинации с прочими метриками это сделать значительно трудней, хотя мы не исключаем того, что с течением времени производительность нашего классификатора будет ухудшаться. Чтобы приспособиться к постоянно изменяющимся условиям, мы планируем изучить вопрос применения естественно-языковых систем [19] для распознания искусственно-сгенерированного текста. В дополнение к этому, представленные в настоящей работе эвристические алгоритмы могут достаточно успешно использоваться в качестве элемента «многослойной» системы обнаружения спама. В первом слое мы можем использовать наименее затратные методы, представленные в текущем исследовании, для захвата подавляющей части некачественных страниц. После этого мы могли бы подключить более ресурсоемкие технологии (такие, как в [9]), или ссылочные анализаторы для захвата оставшейся части поискового спама. Таким образом, мы планируем исследовать возможность построения и оценки подобного рода многоуровневой анти-спам системы. Обнаружение поискового спама, по сути, является неким аналогом «гонки вооружений», которую ведут системы информационного поиска с одной стороны и поисковые оптимизаторы, а также веб-мастера сайтов с другой. Поэтому, мы более чем уверены в том, что в перспективе наши методы должны быть адаптированы к новым реалиям веба и совершенствующимся манипулятивным практикам. Мы надеемся, что наша работа поможет пользователям поисковых систем наслаждаться более качественным поиском. Победа над веб-спамом не требует наличия совершенного механизма ранжирования, а лишь предполагает более высокий уровень детекции, который делает все дальнейшие попытки потенциальных спамеров воздействовать на механизм поиска экономически нецелесообразными. Наоборот, мы искренне надеемся, что продолжение исследований в этом направлении позволит создать такую ситуацию, при которой создание качественного сайта будет обходиться дешевле, нежели чем применение эффективных схем манипуляций.
Перевод материала «Detecting Spam Web Pages through Content Analysis» выполнил Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации