SEO-Константа
Яндекс.Директ + оптимизация
Важность веб-страницы является по своей сути субъективным термином, который зависит от читательской заинтересованности, знаний и отношения. Однако можно найти много объективных характеристик относительной важности веб-страниц. В данной статье описывается PageRank – метод оценки веб-страниц основанный на автоматическом, объективном и эффективном измерении общественного интереса и уделенного страницам внимания.
Мы сравниваем PageRank с идеальным случайным пользователем Интернета. Мы покажем, как эффективно вычислить PageRank для большого количества страниц и как можно применить PageRank для поиска и навигации пользователя.
Всемирная паутина создает множество новых проблем в задаче поиска информации. Сеть весьма велика и неоднородна по своей структуре. По текущим оценкам (1998 г.) существует более 150 миллионов веб-страниц, количество которых удваивается меньше чем за год. Более того, веб-страницы чрезвычайно разнообразны, начиная с таких как «Что у Джо сегодня на обед?» до журналов об информационном поиске. В дополнение к этим серьезным проблемам, поисковые системы в Интернете также должны бороться с неопытными пользователями и страницами, разработанными с целью манипуляции функцией ранжирования поисковой системы.
Однако в отличие от однородных коллекций документов, Всемирная паутина является гипертекстом и имеет дополнительную информацию вне текста веб-страницы, такую как структуру ссылок и текст ссылки. В этой статье мы используем структуру ссылок в Интернете, чтобы глобально ранжировать каждую веб-страницу по «важности». Этот тип ранжирования называется PageRank. Он помогает поисковым системам и пользователям быстро разобраться в огромной неоднородности Всемирной паутины.
1.1. Разнообразие веб-страниц
Хотя существует много научных работ по анализу цитирования, есть ряд существенных отличий между веб-страницами и научными изданиями. В отличие от научных изданий, которые тщательно проверяются, веб-страницы размещают без рецензирования и издательских издержек. С помощью простой программы можно легко создать огромное количество страниц и искусственным путем увеличить их цитируемость. Поскольку в веб-среде содержатся конкурирующие в прибыли предприятия, то возникли стратегии привлечения внимания в ответ на алгоритмы поиска. По этой причине, любая оценка стратегии, которая подсчитывает воспроизводимые особенности веб-страниц, уязвима для манипуляций. Кроме того, исследовательские работы создаются по чётко определённым стандартам научных публикаций, примерно одинакового качества и степени цитирования, а так же с одинаковой целью расширения глобальной совокупности знаний. Веб-страницы имеют намного больше отличий по своему качеству, целевому использованию, цитированию и размеру, чем научные работы. Взятое наугад из архива сообщение с мелким вопросом о компьютере IBM радикально отличается от домашней страницы компании IBM. Научная статья о влиянии сотовых телефонов на внимание водителей сильно отличается от рекламы конкретного сотового оператора. Среднее качество веб-страницы, воспринимаемое пользователем, выше, нежели качество типичной интернет-страницы. Все дело в том, что простота создания и публикации веб-страниц приводит к большому количеству низкокачественных веб-страниц, которые пользователи, скорее всего, не будут читать.
Веб-страницы можно дифференцировать по многим признакам. В данной работе мы имеем дело лишь с одним – аппроксимацией общей относительной важности веб-страниц.
1.2. PageRank
Для измерения относительной важности веб-страниц мы предлагаем использовать PageRank, методику вычисления ранга каждой веб-страницы на основе графа Сети. PageRank применяется в поисковых процессах, просмотре информации, а также для оценки трафика.
В Разделе 2 приводится математическое описание и обоснование PageRank. В Разделе 3 мы покажем как эффективно вычислить PageRank для целых 518 миллионов гиперссылок. Чтобы узнать, насколько полезен PageRank для поиска, мы разрабатываем интернет-поисковую систему Google (Раздел 5). Мы продемонстрируем вам то, каким образом PageRank может оказаться полезным пользователю при просмотре веб-страниц в Разделе 7.3.
2.1. Смежные работы
Существует много научных публикаций об анализе цитирования [Gar95]. Гофман [Gof71] опубликовал интересную теорию распространения информации в научном сообществе, представив информационный поток в виде эпидемического процесса.
В последнее время появилось значительное количество публикаций о том, как можно использовать ссылочную структуру крупной гипертекстовой системы, такой как Интернет. Недавно Джеймс Питков закончил написание кандидатской диссертации на тему «Характеризация Интернет-экологии» [Pit97, PPR96] с широким разнообразием анализов ссылочной структуры. Вайс изучал методы кластеризации, учитывающие ссылочную структуру [WVS+ 96]. Спертус [Spe97] рассматривает различные области применения информации, которую можно получить из ссылочной структуры. Качественная визуализация сетевой иерархии требует использование структуры гипертекста [MFH95, MF95]. Недавно Клейнберг [Kle98] разработал интересную модель Интернета с хабами и авторитетными документами, которая основана на подсчете собственного вектора матрицы обоюдного цитирования.
Наконец, библиотечное сообщество проявило интерес к определению понятия «качества» в Сети [Til].
Очевидной является попытка использовать стандартный метод анализа цитирования для ссылочной структуры гипертекстовой среды Интернета. Можно представить каждую ссылку как простую цитату. Следовательно, такая важная страница как yahoo.com будет иметь десятки тысяч внешних входящих ссылок (т.е. цитат), которые указывают на неё.
Тот факт, что домашняя страница Yahoo имеет так много внешних входящих ссылок, указывает на её важность. Действительно, многие поисковые системы подсчитывают внешние входящие ссылки, чтобы определить более важные и качественные интернет-страницы в их базах данных. Однако простой подсчет этих ссылок встречает несколько проблем в Интернете. Некоторые из этих проблем имеют отношение к свойствам Интернета, которые отсутствуют в обычных базах данных научного цитирования.
2.2. Ссылочная структура Интернета
На данный момент веб-граф содержит приблизительно 150 миллионов узлов (страниц) и 1,7 миллиардов рёбер (ссылок). Каждая страница имеет определенное количество внешних прямых и обратных рёбер, т.е. исходящих и входящих ссылок, соответственно (рис. 1). Мы никогда не можем узнать нашли ли мы все внешние входящие ссылки определенной страницы, но в тоже время, если мы загрузим её, мы узнаем все её исходящие ссылки.
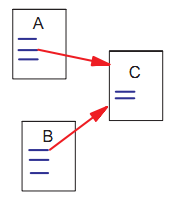
Рисунок 1. A и B – входящие ссылки C.
Интернет-страницы сильно различаются с точки зрения количества входящих ссылок. Например, домашняя страница Netscape имеет 62 804 входящие ссылки в нашей текущей базе данных по сравнению с большинством страниц, которые имеют всего несколько входящих ссылок. Как правило, страницы, имеющие много ссылок, более «важные», чем страницы с несколькими ссылками. Простой подсчет цитат использовался для выбора будущих лауреатов Нобелевской премии [San95]. PageRank обеспечивает более сложный метод подсчета цитат.
Причиной возникшего интереса к PageRank являются многие случаи, когда простой подсчет цитат не соответствовал нашему общему понятию важности. Например, если интернет-страница имеет ссылку от домашней страницы Yahoo, это может быть только одна ссылка, но оно очень важная. Эта страница должна быть оценена выше, чем многие другие страницы с большим количеством ссылок от ненадежных источников. PageRank является попыткой увидеть, насколько хорошо можно получить аппроксимацию к понятию «важности» только от ссылочной структуры.
2.3. Пропагация ранга через ссылки
На основании вышесказанного, мы приведем следующее наглядное описание PageRank: страница имеет высокий ранг, если сумма рангов своих входящих ссылок высокая. Это касается тех случаев, когда страница имеет много входящих ссылок и когда страница имеет несколько обратных ссылок с высоким рейтингом.
2.4. Определение PageRank
Пусть u будет интернет-страницей. Затем пусть Fu будет набором страниц, на которые указывает страница u, и Bu будет набором страниц, указывающих на страницу u. Пусть Nu = |Fu| будет количеством ссылок от u и пусть c будет нормированным множителем, так чтобы общий ранг всех интернет-страниц был постоянным. Мы начинаем с определения простого ранга R, который является слегка упрощенной версией PageRank:
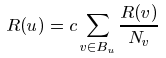
Это формализует сказанное в предыдущем разделе. Обратите внимание, что ранг страницы равномерно делится среди своих исходящих ссылок, тем самым распространяя свой ранг на ранги страниц, на которые она указывает. Необходимо отметить, что с < 1, потому что существуют некоторые страницы без исходящих ссылок и их вес не учитывается системой (см. раздел 2.7.). Уравнение является рекурсивным, но оно может быть вычислено исходя из любого набора рангов и при помощи итерации вычисления до его сходимости. На рисунке 2 показано распространение ранга от одной пары страницы к другой. На рисунке 3 показано последовательное стационарное решение для набора страниц.
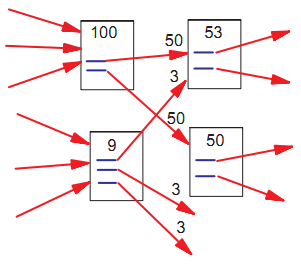
Рисунок 2. Упрощенное вычисление PageRank.
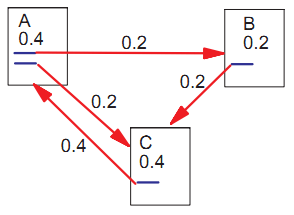
Рисунок 3. Упрощенное вычисление PageRank.
Иначе говоря, пусть A будет квадратной матрицей, строки и столбцы которой соответствуют интернет-страницам. Пусть Au,v= 1/Nu, если есть ребро от u к v и Au,v = 0, если нет. Если мы рассматриваем R в качестве вектора интернет-страниц, то мы получаем R = cAR. Значит R является собственным вектором A с характеристическим числом c. Получается, что нам нужен доминантный собственный вектор A. Его можно вычислить повторным использованием A к любому невырожденному начальному вектору.
Упрощенный способ вычисления ранга имеет маленький недостаток. Рассмотрим две интернет-страницы, которые ссылаются друг на друга и ни на какие больше другие страницы И предположим, что существует некая интернет-страница, которая ссылается на них. Затем в процессе итерации эта петля будет накапливать ранг, но никогда не будет распределять его, так как исходящие ссылки отсутствуют. Петля создает один из видов ошибок, который мы называем локальным понижением ранга.
Чтобы решить проблему локального понижения ранга, мы вводим понятие источника ранга:
Определение 1. Пусть E(u)
будет некоторым вектором интернет-страниц, которая соответствует источнику
ранга. Затем, PageRank
набора интернет-страниц присваивается, R΄, к
интернет-страницам, которые удовлетворяют уравнению:
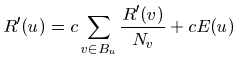
так что c максимизировано и ||R΄||1 = 1, (||R΄||1 обозначает L1 нормой R΄).
Где E(u) является некоторым вектором интернет-страниц, которые соответствуют источнику ранга (см. раздел 6). Обратите внимание, что если E полностью положительное, c должно уменьшаться, чтобы сбалансировать уравнение. Следовательно, этот метод соответствует коэффициенту затухания. В матричной форме мы имеем R` = c(AR`+E). Так как ||R`||1 = 1, мы можем переписать это как R`= c(A+Ex1)R`, где 1 является вектором с единичными компонентами. Таким образом, R` является собственным вектором (A+Ex1).
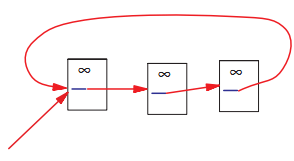
Рисунок 4. Петля, которая понижает ранг.
2.5. Модель случайного блуждания
Вышеизложенное определение PageRank основывается на другом «интуитивном предположении» в модели случайного блуждания по графах. Упрощенная версия соответствует постоянному распределению вероятностей случайного блуждания по графу в Интернете. Наглядно это можно рассматривать как моделирование поведения «случайного пользователя». «Случайный пользователь» просто поочередно выбирает случайные ссылки. Однако если реальный интернет-пользователь когда-либо попадает в небольшую петлю интернет-страниц, то маловероятно, что он будет находиться в петле постоянно. Вместо этого пользователь перейдет на другую страницу. Дополнительный фактор E можно рассматривать как способ моделирования этого поведения: пользователю периодически «становится скучно» и переходит к случайно выбранной странице на основе распределения E.
До сих пор мы использовали Е в качестве произвольного параметра. В большинстве тестов мы сделали E одинаковым для всех интернет-страниц со значением α. Тем не менее, в разделе 6 мы покажем, как различные значения E могут создавать «индивидуальные» ранги страниц.
2.6. Вычисление PageRank
Вычисление PageRank упрощается, если мы не учитываем масштаб. Пусть S будет каким-нибудь вектором интернет-страниц (например, E). Тогда PageRank можно вычислить следующим образом:
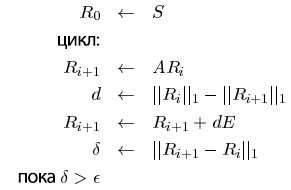
Следует отметить, что коэффициент d увеличивает скорость сходимости и поддерживает ||R||1. Альтернативной нормализацией
является умножение R на соответствующий коэффициент. Использование d может незначительное изменять влияние E.
2.7. Висячие ссылки
Один из вопросов, связанных с этой моделью, являются висячие ссылки. Висячие ссылки — это ссылки, которые указывают на любую страницу без исходящих ссылок. Они влияют на модель, потому что их много и не ясно, как их вес должен быть распределен. Часто эти ссылки являются просто ещё не загруженными в индекс страницами, так как трудно обработать весь Веб. На данный момент у нас загружено 24 миллиона страниц, а 51 миллион URL-адресов ещё не загружены, т.е. являются висячими ссылками. Поскольку висячие ссылки не влияют напрямую на рейтинг любой другой страницы, мы просто удаляем их из системы, пока все PageRank не будут рассчитаны. После того как все PageRank будут вычислены, они могут быть добавлены обратно, значительно ничего не изменяя. Обратите внимание, что нормализация других ссылок той же страницы, что и удаленной ссылки, изменится незначительно, но это не окажет большого влияния.
В рамках проекта Stanford WebBase [PB98], мы создали полную систему сканирования и индексирования с текущим хранилищем в 24 миллиона интернет-страниц. Любой поисковый робот должен содержать базу данных URL, так чтобы он был способен обнаружить все URL-адреса в Интернете. Для реализации PageRank, интернет-сканеры просто должны создавать индексы ссылок во время сканирования. Вроде бы простая задача, но значимая из-за задействованных огромных объемов. Например, чтобы проиндексировать имеющиеся в базе данных 24 миллиона страниц в течение примерно пяти дней, мы должны обрабатывать около 50 веб-страниц в секунду. Поскольку в среднем страница имеет примерно 11 ссылок, мы должны обработать 550 ссылок в секунду. Кроме того, наша база данных из 24 миллионов страниц ссылается на более 75 миллионов уникальных URL, каждая ссылка которого должна быть сравнена.
Много времени было потрачено на создание системы, устойчивой ко многим помехам Интернета, где находятся бесконечно большие сайты, страницы и даже URL. Большая часть интернет-страниц имеет ошибочный HTML, что затрудняет создание парсера. Для улучшения процесса сканирования используются запутанные эвристические процедуры. Например, мы не индексируем директорию /cgi-bin/. Конечно, невозможно целиком скопировать Интернет, поскольку он постоянно меняется. Сайты иногда недоступны, а некоторые люди не позволяют индексировать свои сайты. Несмотря на все это, мы считаем, что создали объективное представление фактической ссылочной структуры общедоступного Интернета.
3.1. Реализация PageRank
Мы преобразовываем каждый URL в уникальную целочисленную переменную и сохраняем каждую гиперссылку в базе данных с использованием этой переменной для идентификации страниц. Подробная информация о нашей реализации приведена в работе [PB98]. В общем, мы реализовали PageRank следующим образом. Во-первых, мы отсортировали ссылочную структуру по родительскому ID. Затем удалили висячие ссылки из базы данных ссылок по причинам, изложенным выше (несколько итераций удаляют большинство висячих ссылок). Нам обязательно требуется провести начальное распределение рангов. Это распределение можно осуществить при помощи одной из нескольких стратегий. При проведении итерации до сходимости начальные значения не повлияют на окончательные, только на степень сходимости. Но мы можем ускорить сходимость, выбрав подходящее начальное распределение рангов. Мы считаем, что тщательный выбор начального распределения и небольшого количества итераций может привести к отличным результатам и улучшенной производительности.
Память отводится для весов каждой страницы. Так как мы используем число одинарной точности с плавающей запятой в 4 байта, то для наших 75 миллионов URL это значение составляет 300 мегабайт. Если не хватает доступного ОЗУ для хранения всех весов, можно проделать многократную процедуру (наша реализация использует в два раза меньше памяти и задействует два повтора операции). Веса от текущего временного интервала сохраняются в памяти, а предыдущие веса — на диске с линейным доступом. Кроме того, весь доступ к каналу базы данных (А) является линейным, поскольку она отсортирована. Таким образом, А может также храниться на диске. Хотя эти структуры данных являются достаточно большими, линейный доступ к диску позволяет завершать каждую итерацию на обычной рабочей станции в течении 6 минут. После сходимости весов мы возвращаем в базу висячие ссылки и пересчитываем ранг. Обратите внимание, что после обратного добавления висячих ссылок, нам нужно провести столько итераций, сколько требовалось для удаления висячих ссылок. В противном случае некоторые висячие ссылки будут иметь нулевой вес. В текущей реализации весь этот процесс занимает около пяти часов. Расчет может происходить гораздо быстрее с менее строгим критерием сходимости и большей оптимизацией или при использовании более эффективных методов оценки собственных векторов. Тем не менее, следует отметить, что затраты, требуемые для вычисления PageRank, незначительны по сравнению с затратами, необходимыми для создания полнотекстового индекса.
Как можно увидеть на Графике 5, PageRank для большой базы данных из 322 миллионов ссылок сходится с умеренной погрешностью примерно за 52 итерации. Для сходимости половины данных необходимо примерно 45 итераций. Этот график показывает, что PageRank будет масштабироваться очень хорошо даже для достаточно больших коллекций, так как масштабирующий множитель линейно зависит от log n.
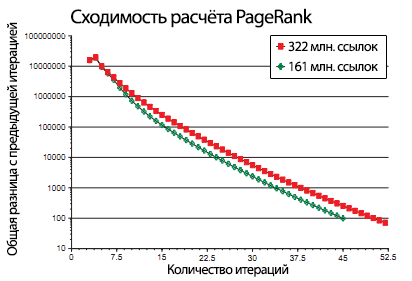
Рисунок 5. Степень сходимости для полного и половинного размеров ссылочной базы данных.
Одним из интересных последствий того, что вычисление PageRank быстро сходится, состоит в том, что Интернет является расширяющимся графом. Для лучшего понимания, мы дадим краткий обзор теории случайного блуждания по графам, см. Мотвани-Рагхавана [MR95] для дополнительных сведений. Случайное блуждание по графу является стохастическим процессом, когда в любой момент времени мы находимся в конкретном узле графа и непрерывно выбираем случайную исходящую ссылку для определения узла, который посетим в следующий момент времени. Граф называется расширяющимся, в случае, когда каждый (не слишком большой) поднабор узлов S имеет окружение (множество вершин, доступное через исходящие ссылки узлов в S) больше некоторых факторов |S| в α раз (здесь α является коэффициентом расширения). В этом случае граф имеет достаточный фактор расширения лишь тогда, когда наибольшее собственное знание существенно больше второго по величине собственного значения. Говорят, что случайное блуждание по графу имеет высокую скорость сходимости к равновесию, если оно быстро (время, логарифмически зависящее от размера графа) сходится к предельному распределению по набору узлов графа. Случайное блуждание имеет высокую скорость сходимости к равновесию по графу в том случае, когда граф является расширяющимся или имеет собственное значение разделения.
Чтобы связать все это с вычислением PageRank, отметим, что необходимо определить предельное распределение случайного блуждания по графу. Ранжирование узла по степени важности является, фактически, предельной вероятностью того, что случайное блуждание по этому узлу будет длиться в течении достаточно длительного времени. Дело в том, что вычисление PageRank приводит к логарифмической зависимости времени, что эквивалентно тому, что случайное блуждание имеет высокую скорость сходимости к равновесию или тому, что основной граф имеет достаточный коэффициент расширения. Расширяющиеся графы имеют многие желательные свойства, которые мы сможем использовать в будущем в расчетах, связанных с графами.
Основное применение PageRank заключается в поиске. Мы реализовали две поисковые системы, которые используют PageRank. Одна из них является простой поисковой системой, которая проводит поиск по названию заголовков (title-based search engine). Вторая поисковая система является полнотекстовой и называется Google [BP]. Google использует ряд факторов при ранжировании результатов поиска, включая стандартные критерии информационного поиска, релевантность, анкор (текст ссылок, указывающих на интернет-страницы) и PageRank. В то время как комплексное исследование преимущества PageRank выходит за рамки данной статьи, мы провели некоторые сравнительные эксперименты и представили некоторые результаты выборки в этой статье.
Преимущество PageRank заключается в умении выдавать результаты на недостаточно определенные запросы. Например, для запроса «Стэнфордский университет» обычная поисковая система может выдать любое количество интернет-страниц, которые упоминают о Стэнфорде (такие, как перечень изданий), но при использованием PageRank, первой в списке будет домашняя страница университета.
5.1. Поиск по заголовкам
Чтобы проверить полезность PageRank для поиска мы реализовали поисковую систему, которая при поиске использовала только заголовки 16 миллионов интернет-страниц. Для ответа на запрос, поисковая система находила все интернет-страницы, в названиях которых содержались все слова запроса. Затем все результаты сортировались по PageRank. Реализация такой поисковой система была простой и недорогой. В ходе неофициального испытания она отлично показала себя. Как видно из рисунка 6, поиск по запросу «Университет» выдает список лучших университетов. Этот рисунок показывает нашу MultiQuery систему, которая позволяет пользователю запрашивать две поисковые машины одновременно. Слева показана поисковая машина, которая проводит поиск по заголовкам, с использованием PageRank. Приведенные гистограммы и процентное соотношение являются логарифмами фактического PageRank, где страница с наибольшим рангом приведена к 100%, а не процентилями, которые используются в данной статье в остальных случаях. Справа показана поисковая машина Altavista. Вы видите, что Altavista выдает случайно найденные интернет-страницы, которые соответствуют запросу «Университет» и корневой странице сервера (Altavista, похоже, использует длину URL как эвристику качества).
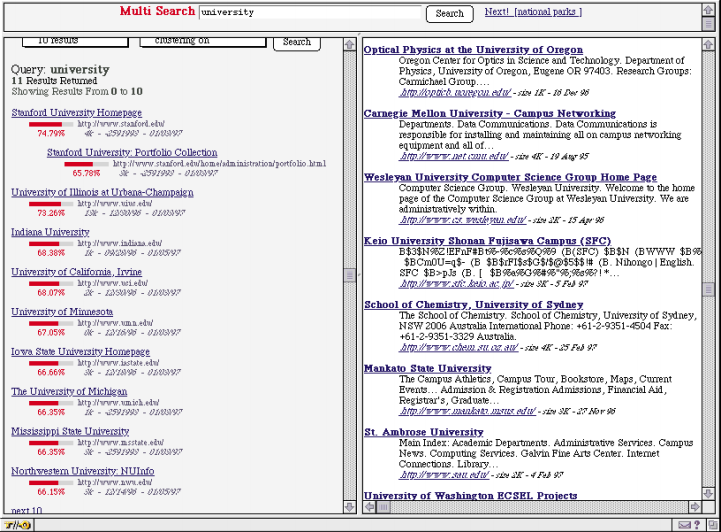
Рисунок 6. Сравнение результатов по запросу «Университет».
5.2. Слияние рангов
Причина в том, что система, проводящая поиск по заголовкам с использованием PageRank работает так хорошо заключается в том, что совпадение заголовка обеспечивает высокую точность результатов, а PageRank отвечает за высокое качество выдачи. Когда найдено совпадение по запросу типа «Университет» в Интернете, полнота результатов не очень важна, потому что пользователю есть еще много на что смотреть. Для более узконаправленного поиска, когда полнота важна, объединяют работу полнотекстовой поисковой машины и алгоритма PageRank. Наша система Google проводит такое слияние рангов. Как известно слияние рангов является довольно сложной задачей, и мы должны приложить значительные дополнительные усилия, прежде чем мы сможем провести адекватную оценку этих типов запросов. Тем не менее, мы надеемся, что использование PageRank для таких запросов будет весьма полезным.
5.3. Некоторые примеры результатов
Мы много экспериментировали с Google (полнотекстовой поисковой системой, которая использует PageRank). Так как полномасштабное исследование выходит за рамки данной статьи, мы приводим пример запроса в приложении А. Для дополнительной информации мы рекомендуем читателю лично поработать с Google [BP].
В таблице 1 показаны 15 страниц с наивысшим PageRank. Данный список был создан в июле 1996 года. В более недавнем расчёте PageRank страница Microsoft вытеснила страницу Netscape по самому высокому PageRank.
| Интернет-страница | PageRank (в среднем 1,0) |
| Скачать программное обеспечение Netscape | 11589.00 |
| http://www.w3.org/ | 10717.70 |
| Добро пожаловать в Netscape | 8673.5 1 |
| Point: именно то, что вы ищете | 7930.92 |
| Домашняя страница Web-Counter (счетчика посещений) | 7254.97 |
| The Blue Ribbon Campaign for Online Free Speech (кампания «голубой ленты») | 7010.39 |
| Добро пожаловать в ЦЕРН | 6562.49 |
| Yahoo! | 6561.80 |
| Добро пожаловать в Netscape | 6203.47 |
| Wusage 4.1: Система статистики использования для веб-серверов | 5963.27 |
| Консорциум Всемирной паутины (W3C) | 5672.21 |
| Домашняя страница Lycos, Inc. | 4683.31 |
| Отправная точка | 4501.98 |
| Добро пожаловать в Magellan! | 3866.82 |
| Корпорация Oracle | 3587.63 |
5.4. Общий случай
Одной из целей разработки PageRank было обеспечение обработки обобщённых запросов. Например, пользователь искал «wolverine» (росомаха), помня, что административную информационную систему Мичиганского университета студенты прозвали как-то похоже на «wolverine». Наша поисковая система, основанная на поиске по заголовку, с использованием PageRank выдала результат «Wolverine Access» в качестве первой страницы. Это логично, так как все студенты регулярно используют эту систему, и случайный пользователь, скорее всего, будет искать ее, вводя запрос «wolverine». Дело в том, что сайт Wolverine Access является хорошим примером общего случая, который нельзя определить из HTML этой страницы. Даже если бы существовал способ определения качественной мета-информации такого типа в пределах страницы, то такое оценивание было бы проблематичным, так как автору страницы нельзя доверять. Многие авторы интернет-страниц просто утверждают, что их страницы самые лучшие и наиболее используемые.
Важно отметить, что цель поиска сайта, который содержит большое количество информации о росомахах (wolverines), совсем другая, чем цель найти общий случай для сайтов на запрос «wolverine». Существует интересная система [Mar97], которая пытается найти сайты с подробным обсуждением какой-либо темы через пропагацию оценки текстового совпадения по ссылочной структуре Интернета. Она пытается вернуть страницу на самом центральном пути. Это приводит к хорошим результатам для запросов типа «цветок». Система вернет качественные навигационные страницы с сайтов, которые связаны с детальным описанием темы «цветы». Сравните это с подходом общего случая, когда может вернуться широко используемый коммерческий сайт, который имеет мало информации кроме той, как купить цветы на этом сайте. Мы считаем, что обе эти задачи важны, и поисковая машина общего назначения должна автоматически выдавать результаты, которые удовлетворяют потребностям обеих этих задач. В этой статье мы концентрируемся только на подходе общего случая.
5.5. Подкомпонент общего случая
Полезно рассмотреть какой тип сценария общего случая сможет отобразить PageRank. Кроме того, часто используемую страницу, например сайт Wolverine Access, PageRank также может представить совместимостью понятий авторитетности и доверия. Например, пользователь может предпочесть новость просто потому, что на неё дана ссылка напрямую с домашней страницы New York Times. Конечно, такая страница получит достаточно высокий PageRank просто потому, что она процитирована очень важной страницей. Это похоже на, своего рода, захват совместного доверия, так как если страница была упомянута надежным или авторитетным источником, то она, скорее всего, тоже будет надежной и авторитетной. Точно так же качество или важность, очевидно, укладывается в, своего рода, порочный круг.
Важным компонентом расчета PageRank является вектор (Е) интернет-страниц, который используется в качестве источника ранга, чтобы компенсировать падение (затухание) рангов, как в случае с отсутствием исходящих ссылок (см. раздел 2.4). Тем не менее, кроме как решением проблемы падения рангов, E оказывается функциональным параметром для корректировки рангов страниц. Вектор Е наглядно соответствует распределению веб-страниц, к которым периодически переходит случайный пользователь. Как мы увидим далее, это может быть использовано для более обширных представлений об Интернете, которые персонализированы и сосредоточены на конкретного человека.
Мы провели большинство экспериментов с вектором Е при ||E||1 = 0:15 для всех веб-страниц. Это соответствует тому, что случайный пользователь периодически переходит к случайной интернет-странице. Это очень демократичный выбор для E, так как все веб-страницы оцениваются просто потому, что они существуют. Хотя эта техника была довольно успешной, у нее есть важный недостаток. Некоторые веб-страницы с большим количеством входящих ссылок получают чрезмерно высокий рейтинг. Примерами являются предупреждения об авторских правах, условия предоставления использования информации и тесно взаимосвязанные архивы списков рассылки.
Другой крайний случай – когда E состоит только из одной веб-страницы. Мы протестировали два таких Е – домашнюю страницу Netscape и домашнюю страницу известного ученого в области информатики Джона МакКарти. Для домашней страницы Netscape, мы пытаемся создать ранги страниц с точки зрения начинающего пользователя, который установил Netscape в качестве домашней страницы по умолчанию. В случае домашней страницы Джона Маккарти мы хотим вычислить ранги страниц с точки зрения человека, который дал нам значительную контекстную информацию на основе ссылок на его домашнюю страницу.
В обоих случаях проблемы со списками рассылки, упомянутой выше, не произошло. И в обоих случаях, соответствующая домашняя страница получила самый высокий PageRank и непосредственно на нее начали ссылаться. За счет этого уменьшилась диспарантность. В таблице 2 мы покажем полученные результаты ранга страниц в перцентилях для разных страниц. Страницы, связанные с компьютерными науками, имеют более высокий ранг по МакКарти, чем по Netscape, и страницы, связанные с компьютерными науками в Стэнфорде имеют значительно более высокий ранг по МакКарти. Например, ранг по Маккарти интернет-страницы другого преподавателя факультета компьютерных наук Стэнфордского университета более чем на шесть перцентилей выше ранга по Netscape. Обратите внимание, что ранги страниц отображаются в перцентилях. Это имеет эффект сжатия большого различия в верхней части диапазона PageRank.
| Заголовок Интернет-страницы (Title) | PageRank по Джону МакКарти, % | PageRank по Netscape,% |
| Домашняя страница Джона Маккарти | 100,00 | 99,23 |
| Джон Митчелл (Stanford CS Theory Group) | 100,00 | 93,89 |
| Venture Law (Местная юридическая фирма) | 99,94 | 99,82 |
| Домашняя страница Stanford CS | 100,00 | 99,83 |
| Лаборатория исследований от обучения роботов и машинного зрения до создания новых компьютеров | 99,95 | 99,94 |
| Факультет компьютерных наук Торонтского университета | 99,99 | 99,09 |
| Stanford CS Theory Group | 99,99 | 99,05 |
| Leadershape Institute | 95,96 | 97,1 |
Такие персонализированные ранги страниц могут иметь ряд применений, в том числе в персональных поисковых системах. Эти поисковые системы могли бы лишить пользователей большинства неприятностей за счет эффективного предположения большей части их интересов, например, исходя из их закладок или домашних страниц. Мы покажем пример по запросу «Митчелл» в приложении А. В этом примере мы покажем, что в то время как существует много людей в Интернете с именем Митчелл, главным результатом поиска будет домашняя страница коллеги Джон МакКарти по имени Джон Митчелл.
6.1. Манипуляции, связанные с коммерческими интересами
Такие типы персонализированных PageRank практически невосприимчивы к манипуляциям ради коммерческих интересов. Для того, чтобы страница получила высокий PageRank, она должна иметь подтверждение от важной страницы или многих не-важных страниц, которые ссылаются на нее. В худшем случае, продвижение сайтов может принимать форму покупки рекламы (ссылок) на важных веб-сайтах. Но это находится под определённым контролем, так как стоит денег. Этот иммунитет к манипуляциям является чрезвычайно важным свойством. Такой вид коммерческих манипуляций создает большие неприятности для поисковых систем, и делает трудоемкой реализацию многих полезных нововведений. Например, быстрое обновление документов является очень желательным нововведением, но им злоупотребляют люди, которые хотят манипулировать результатами поиска.
Компромисс между этими двумя крайностями универсальным (одинаковым для всех страниц) и индивидуальным E заключается в том, чтобы позволить E состоять из всех страниц корневых уровней всех веб-серверов. Заметим, что это позволит проводить некоторые манипуляции с PageRank. Тот, кто желает манипулировать этой системой может просто создать большое количество серверов корневых уровней, которые указывают на конкретный сайт.
7.1. Оценка интернет-трафика
Так как PageRank примерно соответствует случайному веб-пользователю (см. раздел 2.5), интересно посмотреть, как PageRank соответствует фактическому пользованию вебом. Мы использовали количество обращений к веб-страницам из прокси-кэша NLANR [NLA] и сравнили их с PageRank. Данные NLANR были извлечены из нескольких национальных прокси-кэшэй за период в несколько месяцев и состояли из 11817665 уникальных URL с наибольшим количеством обращений к Altavista, составляющих 638657 обращений. 2,6 миллионов страниц пересекались с кэшированными данными и нашей базой данных в 75 миллионов URL. Чрезвычайно трудно аналитически сравнить эти наборы данных по ряду причин. Многие из URL-адресов в кэше данных доступа являются пользователями, которые читают свою личную почту на бесплатных почтовых сервисах. Дубликаты имен серверов и страниц являются серьезной проблемой. Неполнота и предвзятость к проблеме представляют собой данные PageRank и данные по использованию веба. Тем не менее, мы увидели некоторые интересные тенденции в данных пользования вебом. Так, данные в кэше часто содержали порнографические сайты, но эти сайты, как правило, имели низкий PageRank. Мы считаем, что это происходит потому, что люди не хотят размещать ссылки на порнографические сайты на собственных веб-страницах. Используя этот подход для поиска различий между PageRank и реальным использованием веба, можно найти вещи, которые люди любят просматривать, но не хотят упоминать на своих веб-страницах. Есть несколько сайтов, которые очень часто используются, но имеют низкий PageRank, например, netscape.yahoo.com. Мы считаем, что, вероятно, существуют значимые обратные ссылки, которые просто исключают из нашей базы данных, и в наших расчетах участвует только частичная гиперссылочная структура. Можно использовать данные использования веба в качестве начального вектора PageRank, а затем провести итерацию PageRank несколько раз. Это может позволить заполнить пропуски в данных пользования. В любом случае, эти типы сравнений являются интересной темой для будущих исследований.
7.2. PageRank как предиктор обратной ссылки
Одним из обоснований PageRank является то, что он выступает предиктором обратных ссылок. В работе [CGMP98] мы исследуем вопрос о том, как эффективно сканировать Интернет, стараясь сканировать в первую очередь лучшие документы. Мы обнаружили при тестировании Интернета в Стэнфорде, что PageRank является лучшим прогнозом количества цитирований, чем сам подсчет цитирования.
Эксперимент предполагает, что система начинает работать только с одним URL и больше никакой другой информацией. Цель заключается в попытке сканирования страниц в наиболее оптимальном порядке. Оптимальное упорядочивание состоит в том, чтобы сканировать страницы в точности с их рангом в соответствии с вычислительной функцией. Для этих целей вычислительная функция является просто количеством цитирований, учитывая полную информацию. Загвоздка в том, что вся информация для расчета вычислительной функции недоступна, пока все документы не будут просканированы. Получается, что используются неполные данные. Поэтому PageRank является более эффективным способом упорядочивания сканирования, чем подсчет известных цитирований. Другими словами, PageRank является лучшим прогнозом, чем подсчет цитат, даже когда мерой является количество цитирований! Кажется, что объяснением этому служит то, что PageRank позволяет избежать локальных максимумов, в отличие от подсчета цитат. Например, подсчет цитат имеет тенденцию застревать в локальных коллекциях, таких как веб-страницы факультета компьютерных наук Стэнфордского университета, тратя много времени на расширение и поиск весьма цитируемых страниц в других областях. PageRank быстро определяет домашнюю страницу Стэнфордского университета важной, и отдает предпочтение ее дочерним ресурсам, что приводит к эффективному широкому поиску.
Эта способность PageRank прогнозировать количество цитирований является значимым обоснованием использования PageRank. Так как очень трудно отобразить полную ссылочную структуру Интернета, PageRank может быть даже лучшей аппроксимацией количества цитат, чем сам подсчет цитирований.
7.3. Навигация пользователя: прокси-сервер PageRank
Мы разработали интернет-приложение прокси-сервера, который дает примечание каждой ссылке, которую видит пользователь, с ее PageRank. Это вполне полезно, потому что пользователь получает некоторую информацию о ссылке, прежде чем он выберет ее. На рисунке 7 показан скриншот прокси-сервера. Длина красных диаграмм является логарифмом PageRank URL. Как видно, крупные организации, такие как Стэнфордский университет, получили очень большой ранг от научно-исследовательской группы. Среди людей наивысший ранг по шкале был у профессоров. И заметьте, что ACM имеет довольно большой PageRank, но не такой высокий как у Стэнфордского университета. Интересно, что такой аннотированный вид PageRank на страницу делает очевидные ошибки в URL для одного из профессоров, так как он имеет поразительно низкий PageRank. Следовательно, этот инструмент представляется полезным для подсчёта авторитетности страниц, также как и для навигации. Этот прокси-сервер очень полезнен для просмотра результатов других поисковых систем, и страниц с большим количеством ссылок, таких как номенклатура Yahoo. Прокси-сервер может помочь пользователям решить, какие ссылки в длинном списке, скорее всего, будут интересными. Или, если пользователь имеет некоторое представление о том, куда ссылка, которую он ищет, должна попасть в распределении «важности», то они должны найти информацию гораздо быстрее, используя прокси-сервер.
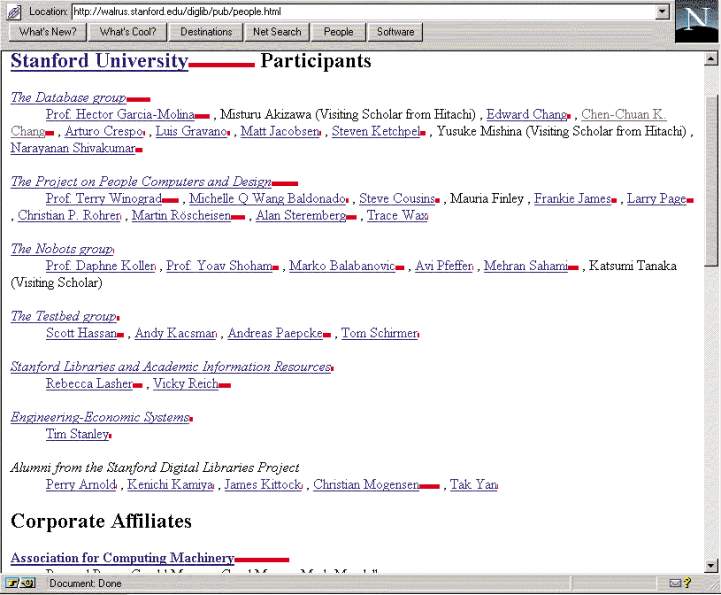
Рисунок 7. Прокси-сервер PageRank.
7.4. Другое применение PageRank
Первоначальной целью создания PageRank был способ сортировки обратных ссылок, так что если у документа имелось большое количество обратных ссылок, то «лучшие» из них будут показаны в первую очередь. Мы ввели такую систему. Оказывается, что упорядочивание обратных ссылок с помощью PageRank может быть очень полезным, для понимания своих конкурентов. Например, люди, которые посещают сайты новостей, всегда хотят отслеживать любые значимые обратные ссылки. Кроме того, PageRank может помочь пользователю решить является ли сайт надежным или нет. Например, пользователь может быть склонен доверять информации, которая непосредственно процитирована на домашней странице Стэнфордского университета.
В этой статье мы взяли на себя смелую задачу по конвертированию каждой страницы Интернета в отдельное число — PageRank. PageRank является глобальным ранжированием всех веб-страниц, независимо от их содержания, основываясь исключительно на их положении в графовой структуре Интернета.
Используя PageRank, мы можем упорядочить результаты поиска так, чтобы отдавать предпочтение более важным и основным веб-страницам. Эксперименты показали, что это может обеспечить более высокое качество результатов поиска для пользователей. Интуиция подсказывает, что PageRank использует информацию, которая является внешней по отношению к веб-страницам (их обратные ссылки), и этим обеспечивает своего рода экспертную оценку. Кроме того, обратные ссылки «важных» страниц более значимы, чем обратные ссылки обычных страниц. Это охватывается рекурсивным определением PageRank (Раздел 2.4.).
PageRank можно использовать для разделения небольшого набора наиболее часто используемых документов, которые могут дать ответ на большинство запросов. Полная база данных нуждается лишь в совете, тогда как небольшая база данных не пригодна для ответов на запрос. Наконец, PageRank может быть хорошим способом, чтобы провести выборку страниц из группировки.
Мы нашли ряд применений для PageRank помимо поиска, которые включают в себя оценку трафика и навигацию пользователя. Кроме того, мы можем образовывать персонализированные PageRank, которые могут создать представление об Интернете с определенной перспективой.
В целом, наши эксперименты с PageRank дали понять, что структура веб-графа является очень полезной для задачи поиска различной информации.
Приложение А.
Данное приложение содержит несколько примеров результатов запроса, полученных с помощью Google. Первым является запрос “Цифровые библиотеки”, при этом использовалось общее значение E. Следующий запрос был «Митчелл», для него использовался Е, включающий в себя домашнюю страницу Джона Маккарти.
Перевод материала «The PageRank Citation Ranking: Bringing Order to The Web» выполнил Сергей Неиленко
Полезная информация по продвижению сайтов:
Перейти ко всей информации