SEO-Константа
Яндекс.Директ + оптимизация
Целью систем информационного поиска является нахождение всех документов в коллекции, релевантных запросу пользователя. Десятилетия изучения информационного поиска привели к разработке и совершенствованию техник, основанных исключительно на использовании слов (см. [2]). С появлением возможности создавать новые источники информации, одна из них стала основываться на анализе гиперссылках между документами и записями поведения пользователей. Уточним, что гипертекст (то есть коллекция документов, соединённых гиперссылками) существовал и изучался уже долгое время. Новым стало то, что огромное количество гиперссылок, создавалось независимыми лицами. Гиперссылки же являются ценным источником данных для систем информационного поиска, что будет показано в данной статье. Эта область информационного поиска обычно называется ссылочным анализом. По какой причине мы ожидаем, что гиперссылочный анализ будет для нас полезен? Допустим, что некая страница А ссылается на веб-документ B; соответственно при прохождении по данной ссылке, интернет-обозреватель пользователя отображает страницу B. Сам по себе этот функционал бесполезен в информационном поиске. Однако тот факт, что гиперссылки обычно используются веб-мастерами, может дать для нас ценную информацию. Например, обычно авторы страниц создают ссылки постольку, поскольку они предполагают их полезность для своих читателей. Поэтому ссылки обычно либо являются навигационными элементами, к примеру, возвращая читателя на главную страницу интернет-сайта, либо ведут на страницы, содержимое которых дополняет содержимое текущего документа. Второй тип гиперссылок обычно ведёт к высококачественным страницам, которые могут принадлежать той же теме, что и страница, содержащая ссылку.
Основываясь на этой мотивации, ссылочный анализ влечет за собой следующие упрощённые предположения:
Гиперссылочный анализ успешно используется при определении того, какие страницы добавить в коллекцию документов (то есть, какие страницы индексировать), и как упорядочить документы, соответствующие запросу пользователя (то есть, как ранжировать страницы). Текущий анализ также может использоваться при распределении страниц по категориям; поиске документов, связанных с данными страницами; обнаружении дубликатов веб-сайтов, а также других задач, связанных с информационным поиском. Нужно заметить, что идея изучения «рефералов» не нова. Подраздел классического информационного поиска информации, называемый библиометрией, занимается анализом цитат (см. [19, 14, 29, 15]). Направление социометрии, разработало алгоритмы [20, 25], очень схожие с алгоритмами Google PageRank и HITS, описанных ниже. Некоторые алгоритмы ссылочного анализа также можно рассматривать как методологию совместного фильтрования: каждая ссылка представляет собой мнение, и нашей целью здесь является сбор некоторого множества мнений для улучшения качества поисковой выдачи.
Данная статья имеет следующую структуру. Сперва мы опишем представление веба в виде ссылочного графа (раздел 2). В Разделе 3 мы опишем два типа схем ранжирования, основанных на гиперссылочной связанности: запросо-независимый подход, где оценка, определяющая внутреннее качество страницы, присваивается каждой странице без определённого пользовательского запроса, и запросо-зависимый подход, где оценка, определяющая качество и релевантность страницы заданному пользовательскому запросу, назначается каким-либо документам. В Разделе 4 описываются другие способы применения гиперссылочного анализа.
Чтобы упростить описание нижеследующих алгоритмов, мы представим Сеть в виде графа. Это может быть сделано различными способами. Техники ранжирования, основанные на ссылочной связанности, обычно предполагают буквально следующее представление: узлам графа соответствует всякая страница u, и существует ориентированное ребро (u,v) в том и только в том случае, когда страница u содержит ссылку на страницу v. Назовём этот ориентированный граф ссылочным графом G. Некоторые алгоритмы используют неориентированный граф со-цитирования: как и прежде, нашим интернет-страницам соответствуют узлы графа. Узлы u и v связаны ненаправленным ребром в том, и только в том случае, если существует третий узел x, соединённый и с u и с v. Ссылочный граф используется для ранжирования, поиска связанных страниц и различных других задач. Граф со-цитирования используется при поиске связанных страниц, а также их классификации.
При запросо-независимом ранжировании оценка присваивается каждой странице без учёта определённого пользовательского запроса с целью измерения внутреннего качества страницы. Во время запроса эта оценка используется с/без каких-либо запросо-зависимых критериев для ранжирования всех документов, соответствующих пользовательскому запросу. Предположение методов, основанных на связанности, сразу приводит к простому независимому от запроса критерию: чем больше количество гиперссылок указывает на страницу, тем лучше сама страница. Главным минусом такого подхода является то, что все ссылки должны расцениваться как равнозначно важные. Он не может провести различие между качеством страницы, на которую даются ссылки с низкокачественных веб-документов и качеством той страницы, на которую указывает то же количество высококачественных страниц. Очевидно, что в задачах продвижения сайтов веб-мастера могут легко придать HTML-странице вид высококачественной, просто создав множество других ссылающихся на нее страниц. Для решения изложенной проблемы Брин и Пейдж [5, 26] ввели оценку PageRank. Google PageRank страницы вычисляется через присваивание веса каждой гиперссылке пропорционального качеству страницы, содержащей гиперссылку. Чтобы определить качество ссылающейся страницы, вычисление её голосующей способности выполняется рекурсивно. Это приводит к следующему нахождению PageRank R(p) страницы p:
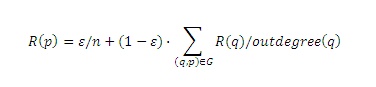
где: ε — коэффициент затухания, обычно задаваемый от 0.1 до 0.2: n – количество узлов в G; outdegree(q) — количество рёбер, исходящих из p, то есть количество гиперссылок на страницу q. Альтернативно PageRank может быть определён как стационарное распределение следующего бесконечного случайного блуждания p1, p2, p3, …, где pi — это узел в G: любой узел может быть первым узлом p1 с одинаковой вероятностью. Для определения узла pi+1, где i>0 бросаем несимметричную монету: с вероятностью ε узел pi+1 выбирается случайным равномерным образом из всех узлов G; с вероятностью 1-ε узел pi+1 выбирается случайным равномерным образом из всех узлов q, у которых существует ребро (pi,q) в G. PageRank является доминантным собственным вектором матрицы вероятностных переходов данного случайного блуждания. Это подразумевает, что во время итеративного вычисления Google PageRank, согласно вышеприведенному уравнению, вычисления в конечном счете будут сходиться при некоторых незначительных допущениях в значениях матрицы переходных вероятностей. Неизвестны чёткие границы количества итераций, но на практике хватает примерно 100. Оценка PageRank хорошо работает при различении высококачественных и низкокачественных страниц и используется в поисковой системе Google. Алгоритм PageRank присваивает оценку каждому документу независимо от конкретного запроса. Это даёт преимущество в том, что анализ ссылок совершается единожды и впоследствии его результаты могут быть использованы при ранжировании для всех последующих запросов.
При запросо-зависимом ранжировании оценка, измеряющая качество и релевантность страницы, относительно поискового запроса, присваивается некоторым определенным страницам. Carriere и Kazman [11] предложили технологию ранжирования, основанное на полустепени захода вершины графа для комбинирования ссылочного анализа с пользовательским запросом. Для каждого запроса строится подграф ссылочного графа G, ограниченный тематическими для данного запроса страницами. Если точнее, то они использовали следующий запросо-зависимый граф соседства. Начальный набор документов, подходящих под запрос, извлекается из поисковой системы (допустим, первые 200 результатов). Этот набор расширяется за счет своего ссылочного окружения, которое также имеет вид множества веб-документов, ссылающегося на первоначальный набор страниц или, наоборот, цитируемого им. Поскольку полустепень захода узлов может быть очень большой, на практике в наборы включается ограниченное количество документов-предшественников (допустим, 50). Граф соседства является подграфом G, содержащий в себе документы из начального и расширенного наборов. Это означает, что каждый такой документ представлен узлом u и существует ребро между двумя узлами u и v в графе соседства тогда и только тогда, когда между ними существует гиперссылка. Метод, использующий полустепень захода, затем ранжирует узлы по их полустепени захода в графе соседства. Как обсуждалось ранее, этот подход имеет проблему того, что каждая ссылка имеет одинаковый все.
Чтобы решить эту проблему, Kleinberg [21] ввёл алгоритм HITS. Учитывая запрос пользователя алгоритм сперва итеративно вычисляет посредническую оценку (hub score) и оценку авторитетности (authority score) каждого узла в графе соседства1 . Далее документы ранжируются по посредническим оценкам и оценкам авторитетности, соответственно. Ожидается, что узлы, то есть документы с высокой оценкой авторитетности будут иметь релевантное содержимое, а документы с высокой посреднической оценкой будут содержать гиперссылки, указывающие на релевантное содержимое. Интуиция заключается в следующем. Документ, ссылающийся на множество других страниц, может быть хорошим посредником, а интернет-страница на которую указывает множество сторонних документов, может быть весьма авторитетной. Рекурсивно, документ, указывающий на множество хороших авторитетных страниц, может быть лучшим посредником; аналогично и документ, на который указывает множество хороших посредников, может иметь лучший авторитет. Это приводит нас к следующему алгоритму.

Поскольку алгоритм вычисляет доминантные собственные векторы двух матриц, то вектора H и A в конечном счете сходятся, но предел количества вычислений неизвестен. На практике, векторы имеют быструю сходимость. Заметим, что алгоритм не претендует на нахождение всех ценных для запроса страниц. Пропуск может возникать по той простой причине, что вопреки хорошему содержимому, данные документы могут иметь низкое цитирование со стороны авторитетных страниц, либо не принадлежащих графу соседства.
В этом методе есть две проблемы: во-первых, поскольку он принимает во внимание только малую часть веб-графа, то добавление рёбер даже к нескольким узлам потенциально может значительно изменить результирующие оценки авторитетности и посредничества. Поэтому веб-мастерам проще управлять оценками авторитетности и посредничества, чем манипулировать оценкой Google PageRank. Более подробно эта проблема описана в [23]. Во-вторых, если граф соседства содержит больше нетематических для запроса страниц, то может случиться так, что приоритет будет отдан посредникам и авторитетным страницам, отличным от данной темы. Эта проблема была названа смещением темы. Для решения этих проблем различные работы [7, 8, 4] предлагают использовать реберный вес и анализ содержимого документов или текст анкоров. В исследовании [4] было показано, что это может значительно улучшить качество результатов. Относительно недавняя статья Lempel и Moran [23] даёт интересное свидетельство того, что вариант с использованием полустепени захода даёт лучшие результаты, чем алгоритм HITS. Они вычислили стационарное распределение случайного блуждания по вспомогательному графу. Это соответствует масштабированию полустепени захода узла u в ссылочном графе по относительной величине компоненты связанности узла u в графе со-цитирования и количеству ребёр в компоненте узла u во вспомогательном графе. Получается, что каждой ссылке присваивается вес, и качество страницы является суммарным весом ссылок, ведущих на неё. Однако, всё ещё необходимы дополнительные эксперименты для оценки эффективности этого метода.
Amento, Terveen и Hill [1] оценивали различные критерии ссылочного ранжирования на графе, похожему на граф соседства. Они начали с первоначального набора релевантных страниц по заданному запросу, а их целью было ранжирование данных документов по качеству с использованием различных критериев. Этот исходный набор имеет такое свойство, что ни один url в нём не является префиксом какого-либо другого. Они рассматривают эти url-адреса как корневые url сайтов: все страницы, содержащие корневой url-адрес в качестве префикса, принадлежат сайту данного корневого url. Затем они выполняют шаг по расширению исходного набора с помощью эвристического подхода, учитывающего схожесть ссылок и текста, и ограничивают его расширение до страниц вышеописанных сайтов. Для анализа они используют этот граф, называемый графом сайтов, где все страницы сайта собраны в один узел. Заметим, что множество узлов на графе сайтов полностью определяется начальным набором, и шаг по расширению используется только для определения его рёбер.
Далее они используют пять метрик, основанных на ссылках (полустепень захода, полустепень исхода; оценка авторитетности и посредническая оценка, присваиваемые алгоритмом HITS; и Google PageRank), а также некоторые другие метрики для ранжирования корневых url-адресов, используя оценку, назначаемую либо корневому url (на графе страниц), либо интернет-сайту (на графе сайтов). Интересно, что ранжирование, выполненное на графе сайтов оказалось лучшим, нежели чем то, что было выполнено на графе страниц. Более того, имеется существенное перекрытие и корреляция в ранжировании по полустепени захода, оценке авторитетности по алгоритму HITS и PageRanks, и эти три метрики справились примерно одинаково хорошо. Также они превзошли другие метрики качества, включая простые метрики, подсчитывающие количество страниц на сайте, принадлежащего графу. Заметим, что они выполнили расчет Google PageRank на малом графе, в то время как вычисление PageRank, описанное выше, исполнялось на всем ссылочном графе, а значит итоговые значения PageRank могут значительно различаться.
Кроме задачи ранжирования, анализ ссылок может использоваться для решения того, какие именно веб-страницы следует добавлять в коллекцию документов, то есть которые из них надлежит проиндексировать поисковому роботу. Индексатор (или робот, краулер) выполняет обход веб-графа с целью обнаружения документов высокого качества. После вызова страницы, он должен решить, какой следующий документ из непроиндексированного множества необходимо вызвать. Один из способов — индексация страниц с наибольшим количеством ссылок, исходящих из уже отсканированных документов. Cho и др. предложили посещать страницы в порядке их PageRank [10]. Ссылочный анализ также использовался в поиске-по-образцу: имея одну релевантную страницу, найти страницы, релевантные ей. Kleinberg [21] предложил использовать алгоритм HITS, а Dean и Henzinger [12] продемонстрировали, что и алгоритм HITS и простой алгоритм со-цитирования справляются очень хорошо. Идея последнего алгоритма заключается в том, что частое со-цитирование является хорошим индикатором родства, и поэтому рёбра с большим весом на графе со-цитирования имеет тенденцию соединять родственные узлы. Расширенные алгоритмы HITS и PageRank были использованы Rafiei и Mendelzon при вычислении репутации веб-страницы [27] и Sarukkai в предсказательных моделях персонализированного пользования вебом [28].
Почти полностью «отзеркаленные» веб-хосты создают проблемы у поисковых систем: они отнимают место в структуре индексных данных и могут привести к дублирующимся результатам. Bharat [3] показал, что использование комбинации анализа по IP-адресу, анализа паттернов URL и анализа гиперссылочной структуры помогает выявить большинство «зеркал». Идея заключается в том, что зеркала имеют очень похожую ссылочную структуру как внутри хоста, так и по отношению к другим хостам. Chakrabarti и др. [9] сделали первые шаги к использованию структуры ссылок для категоризации веб-страниц. В [17, 18] применялась модель случайного блуждания, подобная используемой в PageRank, для отбора страниц соразмерно распределению их голосующей способности и равномерному распределению, соответственно. Целью являлся сбор статистической информации по веб-страницам и сравнение их качества соответственно количеству документов в индексах различных коммерческих поисковых систем. Buyukkokten [6] и Ding [13] классифицировали веб-страницы по их географическому охвату, анализируя ссылки, указывающие на эти страницы.
Основное применение ссылочный анализ находит в построении результатов органического поиска. Также ссылочный анализ оказался полезным при индексировании, обнаружении связанных страниц, вычислении репутации веб-страниц и географического охвата, предсказательных ссылочных моделях, поиске отзеркаленных хостов, в категоризации веб-страниц, а также при сборе статистической информации по веб-страницам и поисковым системам. Впрочем, исследование гиперссылочной структуры сети только начинается, и необходимо будет достичь более глубокого её понимания.
Перевод материала «Link Analysis in Web Information Retrieval» выполнил Максим Евмещенко
Полезная информация по продвижению сайтов:
Перейти ко всей информации