SEO-Константа
Яндекс.Директ + оптимизация
В этой статье мы рассмотрим полезность демографического контекста пользователя для улучшения ранжирования неоднозначных запросов. Контекстно-зависимая модель ранжирования обучается исходя из действий пользователя, используя простую но основательную модификацию современной модели кликов, способную извлекать зависимости из контекста поиска. После того как машина обучается новой модели кликов и используется на деле в оффлайновом опыте пересортировки, становится видно, что возможности использования демографического контекста при ранжировании даёт улучшения качества выдачи. Далее, мы изучим влияние различных демографических значений (пол, возраст и доход) на производительность поискового ранжирования и проанализируем запросы с сильной контекстной зависимостью, чтобы получить более полное понимание поведения модели.
В большинстве своём поисковые запросы коротки и недостаточно детальны для определения цели поиска пользователя. Несмотря на это, иногда поисковый движок может использовать дополнительную информацию, известную о пользователе, чтобы создать спектр возможных целей. Идея выйти за рамки самого запроса и дополнить поисковую сессию контекстной информацией получила широкий отклик в научном сообществе. Знание поискового контекста существенно и предоставляет различные его вариации, которые могут быть приняты во внимание при поисковом запросе. Можно использовать географические, социальные, демографические, временные зависимости, и даже поисковую историю пользователя. Например, географическое местонахождение пользователя может помочь определить набор результатов, релевантных к запросу (доставка пиццы), поскольку пользователю наверняка будут интересны только службы находящиеся поблизости. Прошлые работы (например, [7,8]) показали, что интересы пользователей в различных демографических группах могут различаться, и что обогащение поискового контекста такого рода информацией имеет потенциал к улучшению качества ранжирования сайтов. Однако, мало внимания было уделено оценке полезности демографического контекста для улучшения самого процесса ранжирования. Данная статья призвана исправить это недоразумение.
Польза демографического контекста была поверхностно обсуждена в статье Беннета [1]. Авторы показали как можно ввести модели, использующие местонахождение пользователя, и продемонстрировали существенный прирост производительности при сортировке. Коллинс-Томпсон [4] предлагал метод обеспечения пользователей результатами, персонализированными под их скорость чтения. Вебер [7] детально изучил демографию пользователей поисковых систем и отметил, что некоторые демографические различия между группами людей становятся причиной изменений в их поведении на поиске: например, для молодых людей при поиске «скрапбукинга» показатель энтропии был значительно выше, возможно, из-за более высокого интереса к данной теме. Плюс, авторы показали, что сортировка результатов поиска по CTR, вычисленному с учётом демографической группы, привела к улучшениям в точности первых результатов по сравнению с обычным CTR. Главные различия от нашей работы таковы: мы не ограничиваемся точностью первых результатов, а изучаем и сравниваем пользу различных демографических факторов для улучшения качества ранжирования; мы описываем общий метод, который может быть использован при взаимодействии контекстных значений разного происхождения для улучшения производительности сортировки. Тивэн [6] изучил несколько возможных способов разделить участников эксперимента по группам и задействовать их интересы в процессе ранжирования. Среди прочего, были использованы и группы с социально-демографическими особенностями (пол, возраст, род занятий).
Всё это даёт основания полагать, что обогатив поисковый контекст демографической информацией о пользователе можно улучшить работу поиска и обеспечить пользователя результатами наиболее подходящими для его демографической группы. Мы внедрим контекст поиска с помощью контекстно-зависимой модели кликов обучающего документа из лога кликов поискового движка. Задача вычисления релевантности документа по пользовательским логам широко обсуждалась в в других статьях. Наиболее подходящей к нашей является работа Ченга [3], в которой был представлен контекст, включающий демографические факторы, для решения задачи предсказания клика в спонсируемом поисковом домене. В отличие от нашей работы, та статья не сравнивала различные подмножества факторов в плане влияния на качество поиска. К тому же, она сфокусирована лишь на предсказании кликов, что ограничило её область применения на веб-поиске: у неподходящего документа может оказаться подходящий отрывок. Итак, наша статья расширяет прошлые работы в следующих направлениях:
Процесс контекстно-зависимой пересортировки состоит из двух главных шагов. Первый шаг оффлайновый: мы вычисляем параметры контекстно-зависимых моделей релевантности. Получившиеся модели и значения сохраняются и используются при следующем, онлайновом шаге. Далее мы опишем, как построена контекстно-зависимые модели кликов. В этой работе мы следуем методу, описанному в [1]: используя неявную ответную реакцию пользователя мы узнаём контекстный профиль документа. Чтобы внедрить эти профили мы делаем упрощённую версию современной модели кликов, названной Simplified DBN и описанной Хапеллем [2], и изменяем её для поддержки контекстных факторов. Для простоты предположим, что запрос зафиксирован и рассматриваются только первые 10 результатов. Модель Simplified DBN предполагает, что пользователь всегда рассматривает результаты на поисковой странице сверху донизу. Пользователь делает клик по документу только в том случае, если он или она, осмотрев его описание, находит его интересным. Если пользователя удовлетворяет посещённый документ, он или она прекращает поиск, и продолжает его в противном случае. Вероятности быть привлекательным (ad) и удовлетворительным (sd) зависят только от самого документа. Его релевантность определяется как вероятность того, что пользователь был удовлетворён с учётом того, видел(а) ли он(а) сам документ и вычисляется как rd=adsd. Документы с привлекательными отрывками, но нерелевантным содержимым содержат более низкое значение rd из-за малого sd. Чтобы сделать модель способной подхватывать контекстные зависимости, мы предполагаем, что вероятность привлечь пользователя ad и удовлетворить его sd зависит не только от документа, но и от вектора поисковых факторов u. Далее, мы предположим, что эти зависимости имеют определённую форму логистической функции:
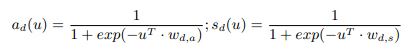
,где wd,a и wd,s означают контекстные зависимости документа d. Цель оффлайнового шага обучения состоит во внедрении модели параметров wd,a и wd,s для каждого документа. Эти параметры будут использованы в контексте пользователя при исполнении шага пересортировки. Можно показать, что модель параметров, которая максимизирует схожесть логов кликов может быть обучена с помощью регулярного логистического регрессионного шаблона с помощью алгоритма, представленного в Алгоритме 1. Мы налагем регуляризацию L1 на параметры модели, поскольку разреженность моделей уменьшает объём хранения данных. Нужно заметить, что контекстно-зависимая модель кликов может быть уменьшена до оригинальной, если установить регулирующие параметры со значением бесконечность. Наконец, модель легко можно распараллелить, поскольку параметры модели для каждой пары документов независимы друг от друга.

Алгоритм 1: обучение wd,a и wd,s по запросу q и документу d.
Пользовательский контекст, рассматриваемый в этой статье, содержит информацию о поле, возрасте и доходе пользователя. Эта информация представлена в виде вектора с неотрицательными элементами u ∈ R+11. Значение первого множества равняется 1, чтобы w0a,d и w0s,d соответствовали связанным условиям. Два множества представляют вероятности того, что пользователь является мужчиной или женщиной. Возраст пользователя представлен в виде распределения между следующими возрастными группами: меньше 18, от 18 до 24, от 25 до 34, от 35 до 45, и более 45. Доход представлен как вероятностное распределение между тремя группами доходности: группы имеющие наименьшую 20% (a), среднюю 60% (b) и наивысшую 20% доходность (c). Другими словами, с каждым пользователем мы ассоциируем контекстный вектор:
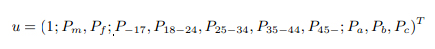
В каждом контекстном наборе вероятности нормализуются, чтобы в сумме получить 1 (Pa + Pb + Pc = 1). Это вероятности являются результатом проприетарного классификатора. Этот классификатор был обучен с помощью информации и полных имён (обычно указывающих на половую принадлежность), указанных в личных аккаунтах в поисковой системе или в аккаунтах популярных социальных сетей, привязанных к аккаунту в поисковой системе. Классификатор был настроен таким образом, что результаты его работы на определённом предельном уровне имеют максимальную точность, приближаясь к данному пределу.
Сценарий оффлайнового вычисления был взят из [1] и [4]. Поскольку маркировка суждений о контекстной релевантности непрактична, мы вместо неё используем поведение кликов пользователя. В каждой сессии мы берём только первые 10 результатов и присваиваем позитивное суждение о результате, если он соответствует последнему удовлетворённому клику в сессии. Все остальные документы из первых 10 результатов считаются нерелевантными, даже если они не были просмотрены. Считая непросмотренные документы нерелевантными мы облегчаем себе работу над производительностью пересортировки. Имея сессию с обеспеченными кликами метками релевантности, контекст сессии и параметры модели кликов для запрашиваемого документа, мы вычисляем контекстно-зависимую вероятность релевантности для каждого документа и упорядочиваем их согласно ей. После пересортировки документов мы измеряем качество ранжирования, инвертируя ранг релевантного документа (mean reciprocal rank, MRR). Обратные ранги релевантных документов за все сессии усредняются для представления общего качества построения выдачи. Параметры документных моделей обучались с помощью 31-дневных логов кликов. Данные о кликах за 4 дня подряд использовались при вычислениях предложенного алгоритма. Мы использовали liblinear в качество библиотеки логистической регрессии. Параметры регуляризации логистической регрессии были настроены на 20% подмножестве обучающих данных. Следуя [1] мы удалили все сессии, начинающиеся с одного из 15 наиболее частых запросов или не имеющие положительных суждений по кликам Также, мы удалили запросы, у которых модели релевантности не ассоциированы хотя бы с одним результатом. В итоге мы получили тестовый набор данных, содержащий 13,7 млн. сессий и 110 тыс. уникальных запросов, сделанных 9 млн. уникальных пользователей.
Мы не предоставим точных результатов измерения качества результатов из-за проприетарности такой информации, но вместо них сообщим улучшения относительно базовой (неконтекстной DBN) модели. Результаты можно найти в Таблице 1. Мы использовали энтропию кликов H (U|Q), чтобы отфильтровать подмножества запросов с разной степенью неоднозначности: считается, что высокие значения энтропии соответствуют наиболее неоднозначным запросам (например, в [1]). Мы демонстрируем производительность пересортировки для 4 моделей, обученных на разных подмножествах факторов: половая принадлежность, возрастные группы, доходность, а также модель, обученная на всех демографических факторах.
| Полная, % | Пол, % | Возраст, % | Доходность, % | Доля | |
| H ≥ 2 | +1.1 | +0.6 | +1.1 | +0.6 | 42% |
| H ≥ 1 | +1.0 | +0.4 | +0.6 | +0.7 | 68% |
| H ≥ 0 | +0.4 | +0.1 | +0.01 | +0.3 | 100% |
Таблица 1: Результаты пересортировки для подмножеств тестовых данных. Запросы с наивысшими значениями энтропии кликов H = H(U|Q) имеют наивысший уровень неоднозначности.
Последняя колонна представляет общее число сессий с определённым уровнем энтропии кликов среди всех сессий в тестовом наборе данных. Все улучшения являются статистически важными, при p<0.01, согласно критерию Вилкоксона. Следующее наблюдение состоит в том, что контекст, ассоциированный с возрастом пользователя является наиболее полезным для запросов с высокой энтропией. Мы обсудим это наблюдение в следующем разделе. Как видно, относительные улучшения для всех подмножеств факторов растут одновременно с порогом энтропии запросов. Это наблюдение поддерживает гипотезу о том, что контекст может быть полезным в случае неоднозначных запросов и в определённой степени способен понять неоднозначные запросы. Следующее наблюдение состоит в том, что может быть трудно назвать самый полезный контекстный набор: все наборы факторов по отдельности имеют схожую производительность.
Поскольку эксперименты демонстрируют способность поискового контекста в некоторой степени решить естественную неоднозначность запроса интересно будет поддержать это наблюдение с помощью самостоятельного анализа запросов с самыми контекстно-зависимыми документами. Для начала мы напомним, что есть два типа неоднозначности в запросах. Первый тип связан с концепцией объектной неоднозначности: запрос может быть интерпретирован по-разному, то есть может относиться к разным объектам. Второй тип предполагает, что даже если запрос имеет только одну интерпретацию, пользователь может быть заинтересован в различных её аспектах. Профессиональное продвижение сайтов должно учитывать данные выше типы неоднозначности при подборе ключевых фраз для продвижения интернет-сайтов. Зачастую пользователи, делая запрос, интересуются одной или несколькими основными интерпретациями, а также различными аспектами каждой их них. Оба типа неоднозначности представлены для этих запросов. Чтобы лучше взглянуть на результаты, мы взяли все троицы контекст-запрос-документ из тестового набора данных и вычислили дисперсию релевантности контекстно-зависимых документов, взятой из тестового набора. После этого мы выбрали 217 пар запрос-ссылка, которые из-за контекстной зависимости имели стандартное отклонение релевантности не менее 0,2 (релевантность вычислялась в интервале [0;1]). Средняя длина уникальных запросов равнялась 1.2 слова, энтропия — 1.84. Исходя из этого, можно сделать вывод, что эти запросы имеют потенциально высокую неоднозначность.
Далее, мы самостоятельно рассмотрели эти пары и обнаружили, что их можно разделить на два класса. Пара в первом классе обычно представляет неоднозначный запрос с разными интерпретациями, и документ имеет высокую релевантность к одной из них. Зачастую эти запросы имеют навигационные результаты для каждой возможной интерпретации. Наглядным примером такого класса может быть навигационный запрос [topshop]. Существует по крайней мере два документа с высокой релевантностью: d1, [topshop.com], и d2, [top-shop.ru]. Оба являются веб-сайтами разных магазинов. Первый является онлайн-магазином одежды и аксессуаров, направленный на молодую женскую аудиторию. Второй является универсальным онлайн-магазином, направленным на общую аудиторию, продающим набор товаров, включая широкий спектр потребительской электроники. Эти сайты имеют следующие профили привлекательности:
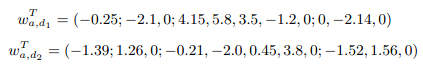
Это означает, что d1 наиболее привлекателен для молодой и женской части пользователей, но менее интересен для взрослых (поскольку в описании контекста есть излишек, мы приняли u2=u8=u11=0).
| Тип | # пары | # запросы | Длина запроса | Энтропия кликов |
| I | 157 | 144 | 1.18 | 1.77 |
| II | 60 | 56 | 1.33 | 2.01 |
Таблица 2: Анализ пар запрос-ссылка
Пары второго типа помогают решить неоднозначность первого. Цель пользователя состоит не в навигации, а в информации. Поэтому одна из возможных интерпретаций запроса является широким понятием, а пользователи из специфичной демографической группы заинтересованы в одном специфичном возможном аспекте запроса. К примеру, для запросов с техническими, относящимися к компьютерам, словами интерес и молодых и взрослых групп пользователей выражен в аспекте [что это такое] больше, чем для основной массы пользователей. Это выглядит вполне естественным, поскольку в среднем эти пользователи менее знакомы с технологией. Возьмём, к примеру, запрос такого типа [hosting]. На ум может прийти несколько интерпретаций: от желания узнать значение слова до прочтения мнений пользователей о различных провайдерах хостингов. Документ d3, представляющий собой страницу Википедии по данному слову, объясняет его значение. А, как видно из модели привлекательности документа, он наиболее интересен для пользователей из возрастной группы 45-54 лет по сравнению с пользователями, которые на 10 лет моложе.
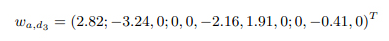
Мы предполагаем, что это наблюдение объясняет тот факт, что возрастные зависимости имеют наибольшее влияние на высокую энтропию запросов: пары второго типа имеют более высокую энтропию, и разрыв в цифровых технологиях является возможной причиной смещения предпочтений пользователей от одного аспекта к другому. Мы привели такую описательную статистику как количество пар запрос-ссылка, уникальная длина запроса и энтропия кликов обеих групп пар в Таблице 2.
Эксперименты с пересортировкой и самостоятельный анализ продемонстрировали, что поисковый контекст полезен для ранжирования очень коротких, неоднозначных и непредусмотренных запросов с высоким уровнем энтропии кликов. Детальное рассмотрение показало, что наибольшая часть больших контекстно-зависимых запросов является неоднозначными запросами с несколькими возможными целями навигации. Значительно меньшая часть контекстно-зависимых запросов попадают в категорию, которая может применять контекст для продвижения определённого аспекта для информационных целей. Все три описанные группы демографического контекста сделали значительный вклад в качество получаемой информации в серии оффлайновых опытов переранжировки, и можно назвать лишь одну самую полезную для контекстной ранжировки демографическую группу. Для запросов с высокой энтропией возрастные значения предоставляют достаточно информации для совершения контекстовой ранжировки, сравнимой с ранжировкой построенной при помощи всех названных групп.
Как видно из экспериментальной части, демографический контекст оказался полезен при ранжировании результатов поиска. Он продемонстрировал способность разрешать неоднозначность запроса в нескольких случаях. Самостоятельный анализ показал, что наибольшая часть запросов, имеющих сильную контекстную зависимость, являются неоднозначными запросами с несколькими различными интерпретациями и имеют раздельные навигационные результаты для каждой из них. Самый релевантный навигационный результат зависит от демографической группы, к которой принадлежит пользователь; зачастую эти группы определяются возрастом и полом. Предлагаемая модификация модели кликов, введённой Хапеллем [2] показала себя способной выделить контекстные зависимости исходя из данных о поведении пользователя. В качестве направления дальнейшей работы мы хотим расширить поисковый контекст для включения большего количества атрибутов пользователя (интересы, языковые предпочтения). Далее, интересно будет изучить скрытые атрибуты пользователя, исходя из его поведения на поиске. Поскольку мы показали, что демографический контекст иногда серьёзно влияет на определение цели пользователя при неопределённом или неоднозначном запросе, в качестве другой возможной цели будущей работы мы рассматриваем модели, которые точно изменяют вес всех целей запроса в зависимости от контекста. С другой стороны, разность в моделях поведения пользователей в разных условиях поиска может помочь извлекать интерпретации запросов. Мы считаем, что сложная машинная обучающаяся структура может использовать эти внутренние зависимости для улучшения качества ранжирвования неоднозначных запросов.
Перевод материала «Demographic Context in Web Search Re-ranking» выполнил Максим Евмещенко
Полезная информация по продвижению сайтов:
Перейти ко всей информации