SEO-Константа
Яндекс.Директ + оптимизация
В данной работе мы анализируем крупную выборку «быстро» обновляющихся веб-страниц, предполагая, что контент обновляется по закону распределения Пуассона в микромасштабе. Мы доказываем, что существуют явные признаки веб-страниц, которые могут быть использованы для поддержания актуальности веб-корпуса.
Агенты накопления данных поисковых систем по мере обхода веба скачивают корпус веб-страниц в свой индекс для последующей работы с запросами пользователей. Одним из самых эффективных способов поддерживать актуальность корпуса веб-страниц является повторный краулинг обновляющихся интернет-документов [3]. Большая часть существующих работ исходит из предположения, что частота обновлений подчиняется закону распределения Пуассона и следуя ему возможно рассчитать среднюю скорость изменения веб-страницы. При высокой частоте обновления содержимого (некоторые вебмастера при продвижении сайтов следуют гипотезе, согласно которой такая стратегия увеличивает вероятность попадания ресурсов в ТОП 10, а потому стремятся к большей частоте обновления их контента) увеличиваются затраты поисковой машины на обработку новых данных. В нашей работе рассматривается вопрос, действительно ли распределение Пуассона точнее всего описывает характер часто обновляемых страниц и если нет, то какую пользу можно извлечь из анализа реальной картины изменений в рамках поиска актуального контента?
Определения: для каждой страницы число обновлений в час обозначается как X и подчиняется закону распределения Пуассона с параметром λ = 1/Δ. Δ – среднее время между изменениями страницы, при этом время между обновлениями распределяется экспоненциально с параметром 1/Δ.
Понятие «изменения»: Charikar [1] описал технологию работы simhash (similarity hash, хэш сходства), которая создаёт уникальный «отпечаток» веб-страницы и при этом хэш-суммы страниц с похожим контентом имеют сходные значения. Разницу в значениях simhash можно определить числом битов, по которым они различаются. В нашей работе обновлёнными считаются те версии страниц, хэш-суммы которых отличаются на 6 и более бит.
Расчёт скорости изменения: располагая историей изменений, собранной за временной интервал C проще всего разделить общее число изменений в этом интервале на его время. Здесь X = общее число изменений, T = время, Δ = скорость. Однако в случае, когда интервал повторного сканирования относительно совпадает с частотой обновления страницы, оценка приобретает стойкую асимптотическую зависимость. Если происходит более одного обновления за C, краулер распознает только одно. В результате, если C слишком велико по сравнению с Δ, вне зависимости от количества проведённых наблюдений, метрика будет считать интервал между изменениями выше реального.
Cho и Garcia-Molina [2] уменьшили асимптотическое отклонение путём вычитания предполагаемого коэффициента зависимости и добавив небольшую модификацию в формулу, чтобы исключить все точки сингулярности:
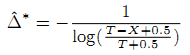
Данная формула продемонстрировала намного более точные результаты даже с небольшим ( < 50) числом наблюдений, в особенности когда C/Δ находился в пределах критической близости 0.5–2.0. Несмотря на то, что используемый нами интервал краулинга несопоставим со всем пространством возможных скоростей обновления, формула Cho и Garcia-Molina значительно лучше подходит для эксперимента, так как исследуемые страницы обновляются каждые 1-2 дня. Однако, если образцы стойко выбиваются из распределения Пуассона, асимптотическая независимость не отражается данной формулой. Поэтому будет проводиться как расчёт Δ^ = T/X, так и Δ^*.
Коллекция веб-страниц: создание тестовой выборки происходит в несколько этапов. Сперва мы выбираем хосты в соответствии с числом URL в ленте из краулинга Google по более, чем 1 млрд документов. От каждого хоста было выбрано несколько URL, каждая из которых проверялась дважды в день, а затем из них были выбраны URL со средней частотой обновления не превышающей 48 часов. 29,000 таких URL затем проверялись ежечасно. 80% из них успешно отвечали на запросы не менее 500 раз подряд и именно эти URL являются исследуемой выборкой. Каждый раз при обращении к странице создавался simhash контента по технике Charikar [1] и если новое значение отличалось более чем на 6 битов, регистрировалось событие обновления страницы.
Профили скорости апдейта: сначала мы изучили общее распределение скоростей обновления в данной коллекции. В экспериментальной выборке менее 5% веб-страниц имели 6 новых битов в сумме simhash при каждом пересчёте страницы. Используя формулу Cho и Garcia-Molina мы обнаружили, что у 25% часто обновляющихся образцов обновления происходят в пределах 1 часа. Более 50% страниц в выборке обновляются в течение 4 часов.
Страницы с регулярными обновлениями: логично предположить, что множество страниц должны обладать намного более регулярным характером изменений, нежели это диктуется распределением Пуассона, так как обновление зачастую проводится автоматически каждый день или каждый час. На рисунке 1 показана теплокарта (двумерное графическое отображение значений) всех наблюдаемых в действительности интервалов между обновлениями и средних значений апдейта каждой страницы. Высокочастотные блоки сконцентрированы в левом нижнем углу и соответствуют наиболее часто обновляющимся страницам. Однако хорошо заметен дополнительный блок в 24-часовых интервалах – он соответствует значительному числу страниц со средней частотой обновления около раза в сутки и большому числу изменений именно раз в 24 часа. На рисунке 2 это явление хорошо иллюстрируется для страниц с Δ^ = 24. Точка на рисунке 2 показывает наблюдаемое количество интервалов изменения и красная линия показывает предполагаемое число интервалов изменений в соответствии с экспоненциальной моделью Exp(1/24).
Рисунок 1. Теплокарта реальных и средних значений интервалов обновлений. Красный цвет соответствует низкой интенсивности, жёлтый – высокой.
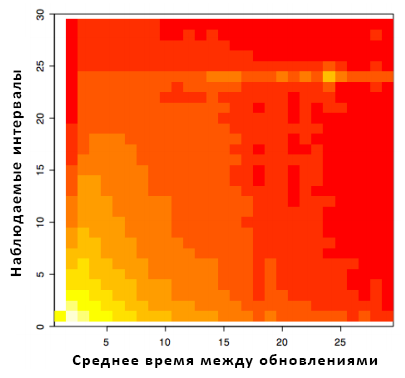
Рисунок 2. Сравнение реальных интервалов обновлений страниц с Δ^ = 24 и предполагаемого экспоненциальным распределением значения.
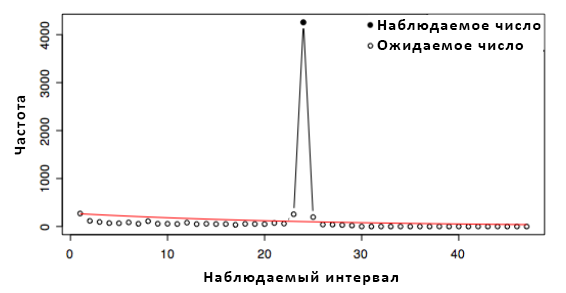
Зависимость обновлений от времени: если обновлением занимается человек или программа, настроенная человеком, то в обновлениях должна прослеживаться чёткая связь со временем. В нашей тестовой выборке мы разделили страницы на категории по региональному признаку, исходя из доменной зоны. Было создано две крупных категории: CJK = {.cn, .jk, .ko} и FIGS = {.fr, .it, .de, .es}. Откладывая точное время зарегистрированных обновлений в соответствии с дневным тихоокеанским временем на рисунке 3, можно наблюдать значительное снижение числа обновлений ближе к ночи и ещё большее – к выходным. Кривая сглажена 5-часовым окном для ровного отображения. График наглядно иллюстрирует рекомендацию для поисковых систем по распределению своих ресурсов для краулинга веб-страниц в определённое время.
Рисунок 3. Частотность обновлений на протяжении недели в соответствии с тихоокеанским часовым поясом.
Исследование оставляет открытым вопрос о целесообразности использования распределения Пуассона: весьма небольшое число страниц в выборке строго соответствовали подобному характеру распределения, ещё меньшее – не соответствовали вовсе. Однако мы выявили точную зависимость обновлений от времени суток, что может повысить эффективность краулинга: объём изменений увеличивается в зависимости от местного времени и дня недели, а часто обновляемые страницы обладают ежечасным и ежедневным характером обновления. Важный вопрос заключается в следующем: насколько полезен обновлённый контент для пользователя у 20% страниц, обновляемых ежечасно, а не по закону распределения Пуассона?
Материал «Microscale Evolution of Web Pages» перевел Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации