SEO-Константа
Яндекс.Директ + оптимизация
Чтобы подтвердить эффективность предложенного общего фреймворка, мы провели несколько опытов для проверки производительности алгоритмов BrowseRank Plus и MobileRank по двум направлениям: поиск важных веб-сайтов и фильтрация спама/низкокачественного материала. В эксперименте использовались два набора данных: один описывал поведение пользователей, а второй являлся данными о мобильном вебе.
Мы использовали набор данных о поведении из коммерческой поисковой системы для наших экспериментов. Всевозможные личные данные были исключены из образцов. В целом было получено более 3 млрд записей и 950 млн уникальных URL.
Сперва мы создали граф сёрфинга пользователей на уровне веб-сайта, как описывается у [1] посредством объединения страниц одного и того же сайта и игнорирования переходов между страницами в пределах этого сайта, а так же собирая переходы со (или к) страниц в том же сайте. Данный граф сёрфинга пользователей состоял из 5.6 млн вершин и 53 млн рёбер. Затем на граф применялись BrowseRank Plus и BrowseRank. Так же мы создали ссылочный граф с 5.6 млн веб-сайтов, а затем рассчитали PageRank и TrustRank.
Для PageRank использовался uniform teleport vector. Для TrustRank сначала на ссылочный граф применялся инверсированный PageRank и полученный топ из 2000 вебсайтов затем рассматривался как исходная выборка. Затем мы вручную проверили эти 2000 сайтов, исключили спам, зеркала (дубликаты сайтов) и сайты со взрослой тематикой, что уменьшило исходную выборку до 1700 надёжных вебсайтов. TrustRank рассчитывался путём передачи оценки доверия с данной выборки. BrowseRank работал по тем же настройкам, как в [1].
Таблица 10 показывает топ-20 вебсайтов, ранжированных различными алгоритмами. Для краткости обозначим PageRank, TrustRank, BrowseRank и BrowseRank Plus как PR, TR, BR и BR+, соответственно. Из таблицы можно заключить следующее:
Таблица 10. Топ-20 сайтов по версии разных алгоритмов.
| # | PageRank | TrustRank | BrowseRank | BrowseRank+ |
| 1 | adobe.com | adobe.com | myspace.com | myspace.com |
| 2 | passport.com | yahoo.com | msn.com | msn.com |
| 3 | msn.com | google.com | yahoo.com | yahoo.com |
| 4 | miscrosoft.com | msn.com | youtube.com | youtube.com |
| 5 | yahoo.com | microsoft.com | live.com | facebook.com |
| 6 | google.com | passport.net | facebook.com | bebo.com |
| 7 | mapquest.com | ufindus.com | google.com | ebay.com |
| 8 | miibeian.gov.cn | sourceforge.net | ebay.com | hi4.com |
| 9 | w3.org | myspace.com | hi5.com | live.com |
| 10 | godaddy.com | wikipedia.org | bebo.com | orkut.com |
| 11 | statcounter.com | phpbb.com | orkut.com | google.com |
| 12 | apple.com | yahoo.co.jp | aol.com | go.com |
| 13 | live.com | ebay.com | friendster.com | friendster.com |
| 14 | xbox.com | nifty.com | craigslist.org | skyblueads.com |
| 15 | passport.com | mapquest.com | google.co.th | pogo.com |
| 16 | sourceforge.net | cafepress.com | microsoft.com | craigslist.org |
| 17 | amazon.com | apple.com | comcast.net | aol.com |
| 18 | paypal.com | infoseek.co.jp | wikipedia.org | cartoonnetwork.com |
| 19 | aol.com | miibeian.gov.cn | pogo.com | microsoft.com |
| 20 | blogger.com | youtube.com | photobucket.com | miniclip.com |
Из 5.6 млн вебсайтов, мы случайным образом отобрали 10000 экземпляров и попросили экспертов провести ручную разметку на вопрос спама. В процессе маркировки страницы, являющиеся целиком рекламными и не несущие никакой полезной информации, так же считались спамом. 2714 сайтов были помечены как спам, а оставшиеся 7286 оказались нормальными.
Для сравнения производительности алгоритмов, мы изобразили распределение блоков спама способом, похожим на [1] [17] [6]. Для каждого алгоритма 5.6 млн веб-сайтов были отсортированы в убывающем порядке в соответствии с оценками, выданными алгоритмом. Затем сайты были разбиты на 15 блоков. Статистика распределения спама приводится в Таблице 11.
Таблица 11. Количество спам-сайтов в блоках.
| # | # вебсайтов | PageRank | TrustRank | BrowseRank | BrowseRank+ |
| 1 | 15 | 0 | 0 | 0 | 0 |
| 2 | 148 | 2 | 1 | 1 | 1 |
| 3 | 720 | 9 | 11 | 4 | 6 |
| 4 | 2231 | 22 | 20 | 18 | 9 |
| 5 | 5610 | 30 | 34 | 39 | 27 |
| 6 | 12600 | 58 | 56 | 88 | 68 |
| 7 | 25620 | 90 | 112 | 87 | 95 |
| 8 | 48136 | 145 | 128 | 121 | 99 |
| 9 | 87086 | 172 | 177 | 156 | 155 |
| 10 | 154773 | 287 | 294 | 183 | 205 |
| 11 | 271340 | 369 | 320 | 198 | 196 |
| 12 | 471046 | 383 | 366 | 277 | 283 |
| 13 | 819449 | 434 | 443 | 323 | 335 |
| 14 | 1414172 | 407 | 424 | 463 | 482 |
| 15 | 2361420 | 306 | 328 | 756 | 753 |
Из эксперимента были получены следующие наблюдения: TR работает лучше, чем PR, так как рассчитывает оценку доверия на основе человеческой разметки и ссылочного графа. Среди всех алгоритмов BR+ пессимизирует наибольшее количество спам-сайтов. И хотя BR поместил немного больше спамовых вебсайтов в последний блок, чем BR+, BR+ превосходит его работу в целом по блокам 6, 5, 4, 3, 2. К примеру, lastlotteryresults.com ранжируется BR очень высоко, но BR+ ранжирует его очень низко. Анализ данных показал, что 26% переходов на этот вебсайт совершались с сайта, на котором расположено объявление latest-lotteryresults.com на главной странице. Судя по данным, вебмастер сайта намеренно кликал по объявлению. При помощи нормализации BR+ может эффективно пессимизировать подобное кликовое мошенничество.
Мобильный веб-граф, который мы использовали в экспериментах, был предоставлен китайской мобильной поисковой системой. Сканирование графа проводилось в октябре 2008. В графе около 80% китайских веб-страниц (816 млн) и 20% некитайских (158 млн). В нашем статистическом анализе основные свойства графа были схожи с (Jindal и др. [18]). Мы рассчитали PageRank и MobileRank по данному графу.
В таблице 12 приводится топ-10 веб-сайтов, отранжированных алгоритмами. Мы провели пользовательское исследование и обнаружили, что MobileRank работает лучше PageRank. Например, wap.cnscu.cn по PageRank ранжирован на втором месте, а MR не включил его даже в десятку. После анализа данных, мы обнаружили, что на главную страницу сайта есть 78331 ссылка с 829 других вебсайтов. Топ-5 веб-сайтов генерируют 8720, 5688, 3764 и 2920 входящих ссылок, соответственно. Таким образом, топ-5 вебсайтов создают 31,5% входящих ссылок. По MR эффект возможных бизнес-отношений между wap.cnsci.cn и топ-5 генераторов будет снижен. Другим примером является wap.motuu.com, который ранжируется на 11 место по PR и 474 по MR. На главную страницу сайта ведёт 12357 входящих ссылок с 79 вебсайтов. Топ-5 ссылающихся сайтов генерируют 3350, 2540, 1662, 1541 и 1144 ссылок, соответственно, занимая 82.3% от 12327 ссылок. MR успешно пессимизирует эффект такой ссылочной массы и понижает ранг.
Таблица 12. Топ-10 сайтов по различным алгоритмам.
| # | PageRank | MobileRank |
| 1 | wap.sohu.com | wap.sohu.com |
| 2 | wap.cnscu.cn | sq.bang.cn |
| 3 | m.ixenland.com | wap.joyes.com |
| 4 | i75.mobi | i75.mobi |
| 5 | planenews.com | wap.cetv.com |
| 6 | wap.joyes.com | waptx.cn |
| 7 | sq.bang.cn | zhwap.net |
| 8 | wap.ifeng.com | wapiti.sourceforge.net |
| 9 | u.yeahwap.com | download.com |
| 10 | wap.cetv.com | wap.kaixinwan.com |
Мы случайным образом выбрали 1500 страниц из мобильного веб-графа и вручную разметили их как «мусорные» или нормальные. 441 страница была расценена как бесполезная, какие зачастую создают недобросовестными оптимизаторами при продвижении сайтов.
Аналогично фильтрации спама в разделе «Фильтрация спама», мы используем распределение по блокам для сравнения производительности алгоритмов. Мы отсортировали 158 млн страниц в убывающем порядке соответственно их оценке и распределили на 10 блоков. В таблице 13 показана сводка по наличию бесполезных страниц в блоках.
Таблица 13. Мусорные страницы в блоках.
| # | # страниц | PR | MR |
| 1 | 23470 | 9 | 3 |
| 2 | 2751839 | 43 | 17 |
| 3 | 13285456 | 76 | 24 |
| 4 | 17766451 | 51 | 48 |
| 5 | 19411228 | 39 | 49 |
| 6 | 20299877 | 40 | 44 |
| 7 | 20916468 | 43 | 36 |
| 8 | 21278962 | 61 | 63 |
| 9 | 21278962 | 36 | 68 |
| 10 | 21278962 | 43 | 89 |
Видно, что MR работает лучше PR в пессимизации мусорных страниц в последние блоки. Например, в наших данных мусорная страница (рекламная страница) обладает большим числом входящих ссылок. Судя по всему, ссылки были добавлены роботом на несколько форумов. Это хорошо подпадает под типичный паттерн поведения спамеров. По MR (см. формулу 24) при фиксированном числе сайтов, чем больше входящих ссылок с сайта, тем больше штраф на среднюю продолжительность визита. Поэтому MR лучше пессимизирует мусорные страницы, чем PR.
Ранее было предложено несколько обобщённых фреймворков для ссылочного анализа. Ding и др. [19] скомбинировал принципы PageRank и HITS в единый фреймворк с точки зрения расчёта матриц. Chen и др. [21] расширили HITS для анализа и гиперссылок на странице и взаимодействия пользователей с веб-страницей. Они учитывали два фактора в общем фреймворке и провели ссылочный анализ данных графа. Poblete и др. [20] скомбинировали ссылочный граф и кликовый граф в гиперссылочно-кликовый граф, а затем провели на нём случайное блуждание. Для получение более надёжного случайного блуждания было проведено слияние нескольких типов данных. Работы, описанные выше очень отличаются от предложенного нами алгоритма. Некоторые из них (Ding и др. [19]) стремятся к расчёту матриц, другие ([19][20]) нацелены на слияние сигналов. Предложенный общий фреймворк Маркова основан на процессах Маркова и объясняет факторы расчёт авторитетности страницы. Так же он охватывает [20] в качестве своего частного случая.
В данной части работы мы подвели итог общему фреймворку Маркова, необходимого для расчёта авторитетности страницы. В данном фреймворке для моделирования случайного блуждания используется Сетевой Скелетный Процесс Маркова. Авторитетность страницs составляется из двух факторов: доступность страницы и полезность страницы. Эти два фактора могут рассчитываться как вероятности переходов между страницами и среднее время пребывания на странице в Сетевом Скелетном Процессе Маркова. Предложенный фреймворк охватывает многие существующие алгоритмы и помогает в разработке новых. Мы показываем его преимущество путём разработки Зеркального Полумарковского Процесса и применяя его в двух задачах: борьбе со спамом в обычном вебе и расчёте авторитетности страниц в мобильном. Наши эксперименты показали, что фреймворк позволяет мделировать авторитетность по различным определениям, на основе которых мы получаем различные списки ранжирования. Однако потребуется более сложный эксперимент для понимания практической пользы фреймворка в информационном поиске.
В дальнейших работах мы планируем обнаружить иной способ расчёта среднего времени пребывания на странице, разрабатывать новые процессы Маркова и алгоритмы в пределах фреймворка, а так же использовать фреймворк на случаях однородного веб-графа и последовательностей веб-графов.
В последние несколько лет много внимания уделялось вопросу оценки авторитетности веб-страницы на основе пользовательского поведения. Однако предложенные методы имели ряд недостатков. В частности, предложенные техники работали на единственном снимке графа сёрфинга, игнорируя его природную динамику с непрерывно изменяющейся пользовательской активностью, что приводит актуальность использования метода к нулю. В данной работе предлагается новый метод расчёта важности веб-страницы под названием Fresh BrowseRank. Оценка страницы нашим алгоритмом соответствует её весу в стационарном распределении гибкой модели случайного блуждания, которая управляется чувствительными к обновлениям весами вершин и рёбер. Наш метод обобщает некоторые ранние подходы, обладает расширенными возможностями для захвата динамики Веба и пользовательского поведения и преодолевает стандартные ограничения BrowseRank. Результаты эксперимента показывают, что наш подход способен генерировать более релевантные и более свежие результаты ранжирования по сравнению с классическим BrowseRank.
Оценка авторитетности веб-страницы является одной из самых важных характеристик, используемых алгоритмами ранжирования. Существует множество способов расчёт важности веб-страниц, среди которых есть такие алгоритмы, которые анализируют историю посещений пользователя. В частности, алгоритм BrowseRank [1] измеряет важность веб-страницы посредством расчёта её вероятности в стационарном распределении непрерывного процесса Маркова на графе сёрфинга пользователей. Несмотря на неоспоримые преимущества BrowseRank и его модификаций (см. раздел 2), эти алгоритмы не учитывают временные характеристики Сети. Более новые страницы, вероятно, более релевантны запросам, чувствительным к новизне, чем старые страницы и, как следствие, временная характеристика релевантности документа позволяет провести более чёткое разграничение между релевантными и нерелевантными документами. Учитывая существование регулярно обновляемых ресурсов, посвящённых новостям, политическим вопросам, спортивным обзорам или конференциям, пользователь, скорее всего, ищет информацию, относящуюся к самому последнему событию. По этой причине вопрос создания чувствительного к новизне (свежести, fresh) BrowseRank должен быть весьма актуален для поисковых систем.
Далее представлен алгоритм Fresh BrowseRank, который распределяет веса по страницам в зависимости от их новизны. Чтобы показать эффективность Fresh BrowseRank, мы сравниваем его с классическим BrowseRank на большой выборке в графе сёрфинга пользователей и демонстрируем, что наша методика имеет более высокую производительность по сравнению с оригиналом. Насколько нам известно, предложенный алгоритм является первым алгоритмом ранжирования, чувствительным к новизне и работающем на основе истории посещений пользователя.
Широко применяемым методом оценки важности веб-страниц является анализ Веба в виде графа веб-страниц, соединённого гиперссылками. Наиболее известным представителем алгоритмов ссылочного анализа является PageRank (Page и др. [2]). Согласно алгоритму оценка страницы p равна её весу в стационарном распределении дискретного процесса Маркова, который моделирует случайное блуждание пользователя по гиперссылочному графу. Однако подобный метод оценки обладает рядом уязвимостей. В частности, значительная доля страниц и ссылок является ненадёжной и не используется реальными людьми. Прочие варианты используют качественно иной вид данных. Как следствие, моделирование случайного блуждания на плоском гиперссылочном графе не реалистично. В 2008 Liu и др. [1] предложили алгоритм BrowseRank, который рассчитывает важность веб-страницы, используя данные о поведении пользователей. Граф сёрфинга содержит множество информации, такой как время пребывания пользователей на странице, число переходов между веб-страницами и т.д. В отличие от PageRank, основанного на дискретной случайной работе, BrowseRank использует непрерывный процесс Маркова на основе статистики сёрфинга пользователей. Такая модель является более реалистичным подходом к оценке важности веб-страниц. Однако подходящий алгоритм ранжирования должен обладать некоторыми свойствами, которых нет у BrowseRank. Liu и др. в [3], [4] предложили разнообразные модификации алгоритма, которые позволяют устранить некоторые недостатки. В [3] показаны новые способы оценки распределения времени пребывания. В [4] используется Скелетные Процессы Маркова для моделирования случайного блуждания веб-сёрфера. Они показывают, что этот фреймворк охватывает множество существующих алгоритмов (среди которых PageRank, Usage-based PageRank [5], TrustRank [6], BrowseRank Plus, MobileRank [7] и их модификации). Параметры этих алгоритмов могут выбираться таким образом, что они будут работать аналогично классическому BrowseRank. Существуют и другие подходы к вычислению важности веб-страницы с использованием данных о пользовательском поведении, которые не применяют модель случайного блуждания (например, [8]).
Важной проблемой, которая не решена ни одним из упомянутых алгоритмов, является проблема ранжирования новизны. Как показано в [9], граф сёрфинга существенно меняется каждый день. Поэтому страницы, имевшие высокий BrowseRank несколько дней назад, могут не быть авторитетными в настоящий момент.
Yu и др. [10] были первопроходцами в изучении алгоритмов ссылочного анализа, чувствительных к временным характеристикам Сети. Авторы модифицировали PageRank посредством взвешивания каждой гиперссылки в соответствии с её возрастом. Прочие алгоритмы ссылочного ранжирования, чувствительного к новизне, изучались Amitay и др. в [11], Berberich и др. в [12] и [13], Yang и др. в [14], Dai и Davison в [15]. Алгоритм T-Fresh из последней работы обобщает идеи из всех остальных вышеупомянутых публикаций. Однако T-Fresh обладает несколькими недостатками, которых нет в алгоритме APR за авторством Жуковского и др. в [16]. Оба метода основаны на взвешивании графа, которое собирает информацию о свежести страниц и гиперссылок. Dai и Davison вывели два новых фактора важности страницы, которые зависят от свежести самой станиц и свежести ссылок. В отличие от T-Fresh, оценка свежести APR зависит от скомбинированного поведения страниц и ссылок. Такой подход позволяет контролировать влияние обоих типов характеристик на назначаемую оценку. Следуя схожему принципу мы предлагаем методику решения проблемы нечувствительности BrowseRank к новизне.
Популярные поисковые системы постоянно предлагаю пользователям установить в их браузер свои тулбары, которые, помимо полезных возможностей отслеживают сессии пользователей, чтобы использовать собранную информацию для улучшения качества поиска. Анонимная информация, описывающая пользовательское поведение (посещённые страницы, количество посещений, поданные запросы и т.д.) сохраняется в логе браузера. Мы определяем сессии и граф сёрфинга пользователей аналогично Liu и др [1]. Пусть S — это сессия пользователя. Страницами сессии будут p1(S),p2(S),…,pk(s)(S). Для каждого i ∈ {1,2,…,k(S) — 1} тулбар делает запись pi(S) → pi+1(S). Мы называем страницы pi(S), pi+1(S) соседними элементами сессии S.
Для каждой страницы p из лога браузинга мы определяем число сессий, начатых с этой страницы как s(p). Для каждой пары соседних элементов {pi,pi+1} в сессии мы определяем число сессий, содержащих такую пару как I(pi,pi+1).
Мы определяем граф сёрфинга пользователя G = (V,E) таким образом: ряд вершин V состоит из всех веб-страниц, упомянутых в логе, а так же из дополнительной вершины x. Набор ориентированных рёбер E содержит все упорядоченные пары соседних элементов {p1,p2}. Так же он содержит дополнительные рёбра от последних страниц всех сессий к вершине x. Пусть σ(x) = 0. Для каждой страницы p при условии p → x ∈ E определим число сессий, завершившихся на p как I(p,x).
Освежим в памяти определение BrowseRank. Вероятность сброса σ(p) — это вероятность выбора страницы p при старте новой сессии. Она пропорциональна числу сессий s(p), начинающихся со страницы p. Поэтому σ(x) = 0. Вероятность перехода w(p1 → p2) — это вероятность клика гиперссылки p1→p2. Она равна I(p1,p2)/(∑pi → p ∈ E).
Оцениваемое время пребывания Q(p) страницы p определено в [1]. BrowseRank p равен Q(p)π(p), где
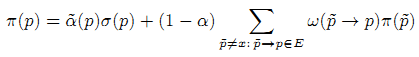
(последние уравнения работают и при p = x), α_(p) = α(1 — π(x)) + π(x).
Стоит отметить, что вероятности перехода не зависят от свежести ссылок и пользователь выбирает старые и новые ссылки с одинаковой вероятностью. По этой причине мы освежаем вероятности перехода путём взвешивания ссылок в соответствии с оценкой свежести страниц перехода.
Определим меру новизны страницы. Мы используем фреймворк из работы [16]. Рассмотрим два момента времени τ, Т, τ < Т. Мы разделяем интервал [τ,Т] на К частей: [ti-1,ti], i ∈ {1,2,…,K}, t0 = τ, ti-ti-1 = (T — τ)/k. Для каждой страницы p из V определим через t(p) дату создания. Мы считаем, что вершина x была создана в момент времени τ.
Пусть i ∈ {1,2,…,K}. Пусть p ∈ V — это вершина, созданная до ti. Мы определяем оценку новизны Fi(p) p в i-ом интервале времени следующим образом:
1) Мы определяем начальное значение Fi0(p) забирая новизну страницы p и её ссылок как (27):
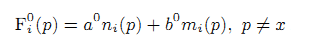
где a0, b0 — неотрицательные параметры; ni(p) = 1 если вершина p создана в i-ом периоде, иначе ni(p) = 0; mi(p) — это число посещений страницы в i-ом периоде. Устанавливаем Fi0(x) = 0.
2) Начальная оценка Fi0(o) распределяется по вершинам через исходящие рёбра (28):
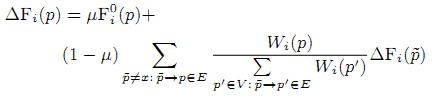
где μ ∈ [0,1], Wi(p) — это оценка, назначенная «локальной» мерой новизны вершине p в i-ом периоде времени. Эта мера определяется таким же образом, как начальная мера Fi0 (значения параметров могут отличаться от параметров в уравнении (27)) (29),
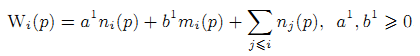
Мы хотим «распространить меру новизны» по исходящим со страницы ссылкам, даже если среди них нет свежих ссылок. Поэтому мы увеличиваем вес страницы на 1 (последнее слагаемое в формуле 29), если она была создана до времени ti. Система, описанная в уравнении 28 иллюстрирует влияние соседей на меру новизны страницы.
3) Наконец, мера новизны Fi определяется как Fi(p) = ΒFi-1(p) + ΔFi(p). Мера экспоненциально уменьшается со временем, если нет никакой активности у вершины p (параметр Β из (0, 1)). В действительности Fi(p) = ΒiΔF0(p) если не было активности за период [τ, ti].
В уравнении 28 все рассматриваемые вершины и рёбра созданы до момента времени ti.
Пусть мера новизны назначит странице p в графе G оценку Fk(p). Мы освежаем вероятность перехода путём замены I(p1,p2) на I(p1,p2)Fk(p2). Другими словами вероятность свежего перехода wf(p1→p2) ребра p1→p2 равно I(p1,p2)Fk(p2)/(∑p:p1→p∈EI(p1,p)FK(p)) и Fresh BrowseRank p равен Q(p)πF(p), где
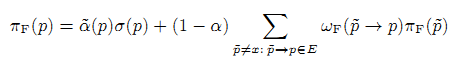
В таблице 14 представлено описание всех параметров алгоритма.
Таблица 14. Параметры Fresh BrowseRank.
| Параметр | Описание |
| τ, T | рассматриваемый период времени |
| K | количество интервалов |
| a0 | прирост Fi0(p) если t(p)=i |
| b0 | прирост Wi(p) если t(p) = i |
| a1 | прирост Fi0 если юзер кликает на p в периоде i |
| b1 | прирост Wi если юзер кликает на p в периоде i |
| mu | коэффициент затухания Fi(p) |
| α | коэффициент затухания оценки Fresh BrowseRank |
| β | скорость уменьшения Fi(p) |
Пусть fq(p) — значение нашей характеристики страницы p и запроса q. Сделаем её запросо-зависимой путём линейной комбинации Fresh BrowseRank с запросо-зависимой характеристикой.
Обучающая выборка содержит коллекцию запросов и наборы страниц Vq1, Vq2,…,Vqk для каждого запроса q, которые отсортированы от наиболее релевантных (свежих) к нерелевантным страницам. Другими словами Vq1 — это набор всех страниц с самой высокой оценкой. Для любых двух страниц p1 ∈ Vqi, p2 ∈ Vqj пусть h(i,j,fq(p2) — fq(p1)) будет значением пенальти, если позиция страницы p1 в соответствии с нашим алгоритмом ранжирования выше, чем позиция страницы p2 но i < j. Функция h — это функция потери (loss function). Мы рассматриваем потери с границами bij > 0, где 1 ≤ i < j ≤ k: h(i,j,x) = max {x + bij, 0}2. Пусть w — это вектор параметров Fresh BrowseRank.
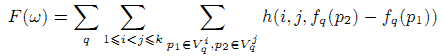
Минимизируем вектор методом градиентной оптимизации. Алгоритм ранжирования новизны требует частой настройки параметров. Простой выбор значений параметров из крупной выборки отнимает много времени. Поэтому применение простой оценки существенно снизит качество поисковой выдачи. Покажем, как мы нашли производную дπF/дwi. Насколько нам известно, мы первые получившие производные от стационарного распределения процесса Маркова когда его вероятности перехода — это функции стационарного распределения другого процесса Маркова (вложенные процессы Маркова широко применяются, см. [15], [16]). Легко найти производные дπFresh/дα через решение следующей системы линейных уравнений (30), (31).
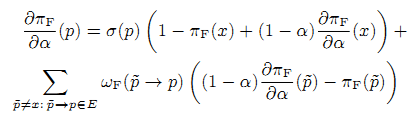
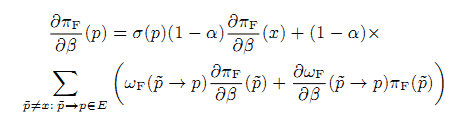
получаем производную дw/дΒ(q→p) через нахождение дFk/дΒ(p) из уравнения:
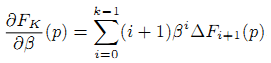
Представим системы линейных уравнений с решениями дπF/дμ, дπF/дα0, дπF/дα1 (производные дπF/дb0, дπF/дb0 — решения тех же уравнений). Первые уравнения системы аналогичны уравнениям из (5). Нам только требуется выбрать рассматриваемый параметр вместо Β. Остаётся найти дΔFi/дμ, дΔFi/дα0, дΔFi/дα1 (32), (33):
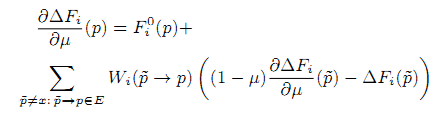
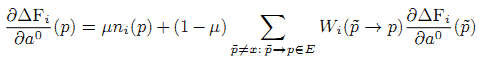
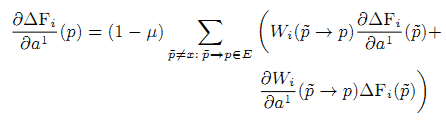
параметры τ, Т, К выбираются из небольшого числа вариантов. Мы рассматриваем интервал времени [τ,Т] длиной в 1 неделю. Параметр К выбирается таким образом, чтобы длина одного периода [ti-1,ti] были либо 1 день, либо 6 часов, 3 часа и 1 час.
Все эксперименты проводились на страницах и ссылках сканированных в декабре 2012 популярной коммерческой поисковой системой. Мы использовали все данные с тулбаров с 10 декабря по 16 декабря 2012. В выборке было 113 млн. страниц и 478 млн. переходов. Для оценки ранжирования мы выбрали ряд запросов, поданных реальными пользователями за период с 14 по 17 декабря. Запрос — это пара «текст запроса, время запроса». Каждый запрос был оценён экспертами, нанятыми поисковой системой. Когда ассессор оценивал пару «запрос, URL», он назначал оценку и новизне страницы в соответствии с временем запроса и оценивал тематическую релевантность страницы запросу. Из-за специфики задания мы рассматривали только чувствительные к новизне запросы, на которые и нацелен наш алгоритм. Чтобы иметь должную релевантность для таких запросов, документы должны были быть и новыми и отвечающими тематике одновременно. Ассессоры были проинструктированы оценивать документы как новые, если тулбар делал запись не раньше 3 дней до момента оценки. Наконец, вышеописанные процедуры вылились в 200 оцененных запросов по новизне и 3000 пар запрос-URL.
Оценка релевантности проводилась по пятибалльной шкале: Идеально, Отлично, Хорошо, Неплохо, Плохо. Мы разделили данные на две части. На первой части (75% данных) мы обучали параметры, а на второй тестировали работу алгоритма. Мы сравнили Fresh BrowseRank с классическим BrowseRank так же, как это делали Dai и Davison [15] и Жуковский [16]. Алгоритмы были линейно скомбинированы по рангам при помощи BM25. Затем параметры Fresh BrowseRank выбирались путём максимизации функции потери. Параметр линейной комбинации BM25 выбирался через максимизацию метрики NDCG. Мы получили следующие параметры:
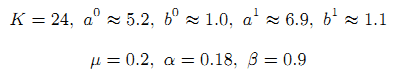
Параметр K выбирался из набора {7, 28, 56, 168}. В этих случаях длины интервалов [ti-1,ti] равнялись 1 дню, 6 часам, 3 часам и 1 часу, соответственно.
Таблица 15 демонстрирует производительность алгоритмов по метрикам NDCG@5 и NDCG@10.
Таблица 15. Производительность.
| Алгоритм | NDCG@5 | NDCG@10 |
| Fresh BrowseRank | 0.71256 | 0.784 |
| BrowseRank | 0.68312 | 0.75188 |
Мы представили Fresh BrowseRank, следующий алгоритм анализа пользовательского поведения, чувствительный к новизне. Мы сравнили его с классическим BrowseRank. Наш алгоритм был протестирован на крупном объёме данных и продемонстрировал превосходство над BrowseRank. Кроме непосредственного интереса наших результатов, они так же могут быть полезны коммерческим поисковым системам, желающим улучшить качество своей выдачи. Естественно, стоит предлагать и другие алгоритмы анализа пользовательского поведения, чувствительные к новизне, на основе нашего фреймворка. По этой причине мы считаем, что наш подход будет фундаментом исследований в данной области. Было бы интересно изучить прочие аспекты пользовательского поведения, однако нам не хватает алгоритмов. Например, стоит представить слой узлов запросов в виде графа. Так же мы представили методику обучения параметров вложенных процессов Маркова. Было бы интересно использовать эти алгоритмы для других алгоритмов, основанных на схожих процессах.
Материал «Поведенческие факторы» подготовил и перевел Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации