SEO-Константа
Яндекс.Директ + оптимизация
Верное определение сессии является ключом к пониманию контекста естественного пользовательского поведения. В Таблице 6 показаны результаты кластеризации гистограммы независимой сессии, обработанной алгоритмом k-средних с k=10. Данные кластеры упорядочены по размеру. Важные характеристики кластеров выделены жирным шрифтом.
Таблица 6. Кластеризация сессий, отражающая паттерны поведения при сёрфинге.
| Кластеры: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Измерение характеристики | Среднее значение/Стандартное отклонение | 29.8% | 16.6% | 14.3% | 11.9% | 11.0% | 4.7% | 4.6% | 3.5% | 2.1% | 1.5% |
| Поиск | 23.63 / 37.71 | 0.35 | 98.43 | 1.19 | 2.35 | 2.33 | 56.18 | 41.52 | 52.23 | 6.46 | 0.09 |
| Почта | 16.81 / 34.98 | 0.07 | 0.66 | 97.25 | 0.39 | 0.42 | 1.29 | 51.79 | 0.70 | 9.79 | 0.07 |
| Информация | 12.26 / 30.85 | 0.04 | 0.27 | 0.39 | 1.03 | 96.50 | 24.58 | 2.65 | 0.50 | 5.97 | 0.02 |
| Контент | 34.31 / 45.69 | 99.42 | 0.37 | 0.64 | 0.45 | 0.36 | 0.64 | 0.95 | 45.25 | 60.51 | 99.54 |
| Шоппинг | 12.85 / 31.60 | 0.08 | 0.24 | 0.41 | 95.67 | 0.29 | 16.92 | 2.60 | 0.86 | 16.84 | 0.06 |
| События | 9.06 / 24.53 | 11.14 | 2.89 | 5.66 | 6.25 | 5.33 | 4.24 | 5.38 | 4.26 | 7.84 | 151.68 |
| Длительность | 420.30 / 1067.99 | 532.49 | 261.4 | 303.85 | 235.78 | 298.91 | 228.40 | 455.58 | 218.01 | 439.78 | 4237.65 |
Из статистических данных кластеров легко выделить разнообразные паттерны поведения пользователей. Пять главных кластеров соответствуют сессиям сёрфинга в Сети, информационному поиску, работе с почтой, онлайн-покупкам и обучению, соответственно. К примеру, центр первого кластера с 29.8% всех данных содержит 99.42% сёрфинга по крупным ресурсам сети. Обычно, в эту категорию входит взаимодействие с социальными сетями, такими как Facebook и MySpace. Стандартное кластерное отклонение в 2.82% в данном измерении характеристики является значительно меньшним по сравнению со стандартным отклонением в 45.69% от всех данных.
Кластеры, отражающие более сложное пользовательское поведение так же показаны в Таблице 6. Среди таких паттернов встречаются интересные случаи, например, сёрфинг по результатам поиска без кликов (кластер 2), сбор информации во время онлайн-шоппинга (кластер 6), посещения крупных сайтов по переходам с навигационных запросов (кластер 8), а так же долгое времяпрепровождение в социальных сетях (кластер 10, см. среднюю длительность сессии).
Такие наблюдения наглядно демонстрируют, что даже простой подход к отображению сессии может дать поисковой системе ценную информацию, например, распределение интереса пользователей к определённому контенту. Это может помочь как в задаче ранжирования результатов, так и в составлении расписания сеансов краулинга для поискового спайдера. Если применять фильтр ко всему набору сессий и выделять из них исключительно поисковые запросы, то в дальнейшем становится возможным определить закономерность связи запроса с типом сессии.
Далее нами предлагается инновационный подход к ранжированию результатов поиска, который назыавется ClickRank. ClickRank комбинирует различные пользовательские предпочтения, полученные из дата-майнинга веб-сессий. Алгоритм ClickRank адекватно отражает оценку важности веб-страниц и веб-сайтов без явного построения веб-графа. Таким образом достигается снижение требуемой вычислительной мощности, что особенно важно в задачах ранжирования результатов веб-поиска. Так же мы приводим описание возможностей ClickRank касательно его применения в обучении модели ранжирования.
Веб-сессия содержит несколько контекстных индикаторов пользовательских предпочтений относительно посещённых веб-страниц. Очевидно, что пользователи исследуют веб-контент, который они считают для себя важным в контексте поиска определённой информации. Это означает, что временной интервал посещения страницы становится важной характеристикой для оценки пользовательского интереса. Так же важна последовательность кликов, отражающая пользовательскую активность: доступ к одной определённой странице до другой явно показывает предпочтение пользователя. Целью ClickRank является правильная оценка таких сигналов в совокупности для определения локального значения важности для каждой страницы в сессии и дальнейшее сопоставление всей суммы данных по ряду сессий.
Первым шагом является вычисление локальных значений важности в каждой сессии. ClickRank веб-страницы pi в данной веб-сессии sj является функцией с несколькими индикаторами контекста сессии: интервал посещения, скорость загрузки страницы, ранг pi в упорядоченном наборе всех посещённых URL и частота появления в сессии.
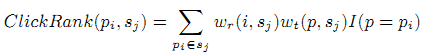
где wr(i,sj) – вес функции, вызванной в ранжировании события i в сессии sj, а wt(p,sj) – вес функции, рассчитанной из выборки временных характеристик, ассоциированных с сёрфингом по странице pi. I() является индикатором функции.
Мы определяем вес функции wr() для события i в ранге r(i) сессии sj с общим числом событий nj как
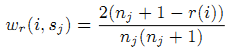
где r(i) ∈ {1,…,nj} и wr(i,sj) является монотонно убывающей функцией w.r.t. ранга события в сессии i. Функция выбора wr() определяется измерениями предпочтений пользователя через эксперимент отслеживания взгляда [1], который показывает понижение внимания к последовательным кликам в навигационных и информационных задачах. Стоит отметить, что сумма wr(i,sj) по данной сессии sj всегда равна единице
Для данного набора веб сессий S = (s1,…,sk) пользователей за определённое время мы считаем, что
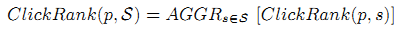
где ClickRank(p,s) является локальной функцией ClickRank определённой в (1) с экземпляром наблюдаемых сессий, а AGGR определяет функцию сбора как суммирование усреднённых величин во всех сессиях заинтересованных пользователей. В нижеследующих экспериментах мы используем суммирование как функцию сбора.
Наконец, ClickRank вебсайта w для данного набора сессий S является суммой значений ClickRank всех страниц в S, являющихся частью сайта. Отметим, что использование суммы по умолчанию определяет как важность, так и размер вебсайта, т.е. число страниц, из которых он состоит.
Наша формулировка ClickRank имеет теоретическую интерпретацию на основании модели намеренного сёрфинга. Веб-сессию можно рассматривать как логическую последовательность переходов по гиперссылочной структуре Сети. Перед каждым шагом пользователь выбирает цель перехода, которая, по его мнению, является наиболее релевантной, т.е. отвечающей его запросу. Далее пользователь подтверждает свою заинтересованность в странице через временные характеристики сессии, например, время, проведённое на странице или количество повторных заходов. Этот процесс продолжается на протяжении всей сессии, пока пользователь не начнёт новое «путешествие» по Сети.
Конкретизируя, локальная функция ClickRank определяет случайную переменную Xij:Ω→R+0, ассоциированную с веб-страницей pj в данной сессии si. Xij ограничивается в практических целях, поэтому E(Xij) < ∞ и var(Xij) < ∞. Определим ряд случайных переменных, связанных с веб-страницей pj во всей выборке наблюдаемых сессий S=(s1,…,sk) через {X1j, X2j,..,Xkj} и предположим, что они независимы друг от друга и имеют одинаковый закон распределения. Так как k → ∞, 1/k ∑ki=1 Xkj приближается к E(Xij) по закону больших чисел.
Мы можем задать границы функции ClickRank в вероятностном подходе при помощи следующих теорем.
Теорема 1. Пусть f:R→[0,+∞) является положительной функцией, тогда:
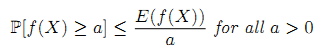
Теорема 2. Если f:R→[0,+∞) является положительной функцией, ограниченной числом M, то:
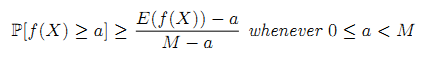
Проще говоря, с ростом объёма наблюдаемых сессий сёрфига, которые анализируются ClickRank, достигается определённый предел выборки, когда ранг, рассчитанный при помощи ClickRank для каждой страницы приближается к её действительному значению важности по критериям использования.
Так как ClickRank не зависит от типа запросов, можно использовать этот алгоритм в целях ранжирования документов несколькими путями [2]. В частности, за последнее время в информационном поиске приобрёл популярность подход к обучению ранжированию, целью которого является применение алгоритмов машинного обучения для составления функции ранжирования из всех полученных данных. Применяя фреймворк машинного ранжирования используется большое число характеристик для моделирования запросов и документов. Характеристиками запросов могут быть их символьная длина и частота в логе поиска, а характеристиками документа – статистические данные, например, число входящих ссылок. Машинное обучение предлагает удобный подход для численной оценки эффективности ClickRank как инновационного подхода на фоне множества существующих способов ранжирования.
Мы обучаем модель ранжирования с использованием фреймворка функциональной регрессии градиентного бустинга [3], что даёт решение функции ранжирования в виде аддитивного (дополнительного) расширения M параметрических функций
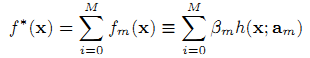
где f0(x) – эмпирическая функция, а [fm(x)]M1 – инкрементальные функции (бусты). В формуле 4 каждая инкрементальная функция fm(x) может быть в дальнейшем использована как результат обучающей базы h(x;am) и соответствовать коэффициенту Βm.
Идея градиентного бустинга заключается в последовательном использовании параметрической функции с данными условиями через метод наименьших квадратов при каждой итерации:
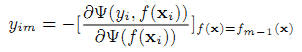
и
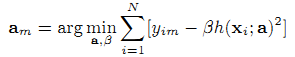
где N – число обучающих образцов. Необязательный коэффициент Βm рассчитывается линейным поиском:
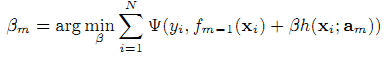
Мы используем дерево решений как обучающую базу h(x;am) в (4), где её параметрами являются разделённые переменные и соответствующие точки разделения. При каждой итерации m древо решений разделяет пространство характеристик на непересекающиеся зоны [Rlm]Ll=1 и делает предсказания на основе зоны, содержащей вектор наблюдаемой характеристики x как
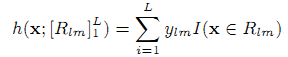
Градиентные древа решений (gradient boosted decision trees, GDBT) открывают широкие возможности по регрессии и классификации [3] и, в частности, полезны для обработки большого количества данных.
ClickRank имеет ряд преимуществ по сравнению с подходами PageRank и BrowseRank, оценивающими важность веб-страниц на основе веб-графа. Прежде всего, данные ClickRank не включают в себя схемы перемещения по всей Сети. Во-вторых, компьютерные вычисления проводятся намного быстрее: локальные значения ClickRank не требуют сложных вычислений и могут рассчитываться независимо для каждой сессии. Эти факторы позволяют использовать ClickRank наиболее эффективно в параллельных вычислениях без особой нагрузки на память компьютеров. Кроме того, появление дополнительных данных не требует полного перерасчёта всей модели, а только новых сессий. Это особенно важно для обработки крупных массивов данных в масштабах Сети, где информация о сёрфинге пользователей постоянно изменяется.
Мы демонстрируем эффективность алгоритма ClickRank в трёх ключевых аспектах информационного поиска: ранжировании сайтов, ранжировании веб-страниц и дата-майнинге новых популярных материалов. В наших экспериментах мы принимаем допущение, что длительность посещения и скорость загрузки страницы являются независимыми друг от друга характеристиками и определяем функцию временного веса в (1) как
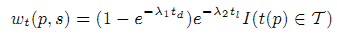
где td и tl – нормальная длительность посещения страницы и время загрузки страницы во всей сессии. t(p) – время начала события (timestamp), а T – временной промежуток.
В нижеописанных экспериментах мы использовали те же данные о сёрфинге за 6 месяцев, собранных инструментами Yahoo!. Все доступные данные содержат более 3.3 млрд веб-сессий. Среди этих сессий находятся 16.3 миллиона уникальных веб-сайтах и 3.1 млрд уникальных веб-страниц.
Мы рассчитали ClickRank для каждого веб-сайта и упорядочили данные по его значению. Топ-20 результатов ClickRank сравниваются с аналогичными расчётами PageRank и BrowseRank. Результаты сведены в Таблицу 7.
Таблица 7. Топ сайтов по мнению различных алгоритмов.
| Ранг | PageRank | BrowseRank | ClickRank |
| 1 | adobe.com | myspace.com | yahoo.com |
| 2 | wordpress.com | msn.com | google.com |
| 3 | w3.org | yahoo.com | myspace.com |
| 4 | miibeian.gov.cn | youtube.com | live.com |
| 5 | statcounter.com | live.com | youtube.com |
| 6 | phpbb.com | facebook.com | facebook.com |
| 7 | baidu.com | google.com | msn.com |
| 8 | php.net | ebay.com | friendster.com |
| 9 | microsoft.com | hi5.com | pogo.com |
| 10 | mysql.com | bebo.com | aol.com |
| 11 | mapquest.com | orkut.com | microsoft.com |
| 12 | cnn.com | aol.com | wikipedia.org |
| 13 | google.com | friendster.com | ebay.com |
| 14 | blogger.com | craigslist.org | craigslist.org |
| 15 | paypal.com | google.co.th | hi5.com |
| 16 | macromedia.com | microsoft.com | go.com |
| 17 | jalbum.net | comcast.net | ask.com |
| 18 | nytimes.com | wikipedia.org | google.co.th |
| 19 | simplemachines.org | pogo.com | comcast.net |
| 20 | yahoo.com | photobucket.com | orkut.com |
В задаче ранжирования веб-сайтов наши расчёты подтверждают предположение [4], что алгоритмы ссылочного анализа сильно зависят от числа входящих ссылок и не всегда отражают реальный интерес пользователей к веб-сайту. Это является фундаментальным ограничением ссылочного графа Сети, на основе которого ведутся расчёты PageRank и прочих схожих алгоритмов.
Ранжированные списки, расчитанные при помощи BrowseRank и ClickRank на удивление похожи (совпадает 18 сайтов из 20). Оба списка отражают интерес пользоватля гораздо точнее, чем это делает PageRank, так как они оба основываются на анализе пользовательского поведения. Различия между ClickRank и BrowseRank в данной таблице зависят от источника данных. BrowseRank рассчитывается на основе данных о пользователях, использовавших инструменты Live, которые являлись посетителями live.com и msn.com, а ClickRank обрабатывал данные о пользователях Yahoo!.
Ключевым отличием между результатами ClickRank и BrowseRank является то, что ClickRank считает точку старта сёрфинга пользователем более интересной. Один из крупнейших поисковиком ask.com даже не появляется в результатах топ-20, отобранных при помощи BrowseRank.
Для расчёта ClickRank требуется намного меньше вычислительных затрат по сравнению с PageRank и BrowseRank. ClickRank требует только единичного захода для обработки данных и ему не нужен строить непрерывный граф с распределением вероятностей. Это даёт ClickRank возможность очень быстро адаптироваться к новому контенту: как было сказано выше, информация о сёрфинге обрабатывается всего один раз и не требует перерасчёта всех данных. У ClickRank общее время обработки данных, содержащих 16.3 млн веб-сайтов и 3.1 млрд веб-страниц для теста ранжирования заняло 56 минут и 1 час 32 минуты соответственно. По нашим сведениям, такая скорость вычислений является самой высокой среди всех алгоритмов ранжирования на сегодняшний день.
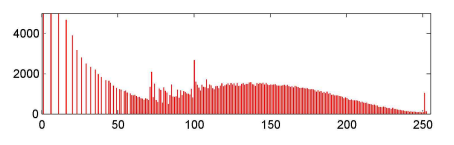
В реальных условиях важно свести к минимуму объём данных каждой оценочной характеристики, чтобы уложиться в приемлемый лимит памяти и задержки обработки данных. Зачастую числа с плавающей точкой сжимаются или округляются, чтобы занимать как можно меньше битов и таким образом повысить скорость вычислений. Нами используется шкала значения ClickRank виде целочисленных значения от 0 до 255. Распределение этих значений показаны на Рисунке 14.
Мы всесторонне оценили производительность ранжирования страниц при помощи ClickRank с несколькими сотнями дополнительными характеристиками оценки, используемыми в коммерческих поисковых системах, в том числе подверженных операциям по продвижению сайтов. Для дальнейшего изучения мы получили количественную оценку улучшения поиска при помощи ClickRank по современной системе и измерили относительную важность по сравнению с увеличенным объёмом факторов оценки ранжирования. Такая схема оценки работы алгоритма даёт более точные результаты в численных значениях на фоне обычных вычислений с ограниченным набором параметров. Например, в [4] используется единственная характеристика BM25 [5] для оценки релевантности.
Мы использовали метрики DCG (discounted cumulative gain) и NDCG (normalized discounted cumulative gain) широко используемыми в поисковых системах [6, 7] для численной оценки точности ранжирования. При данном запросе и ранжированном списке документов выдачи значние DCG(K) рассчитывается как
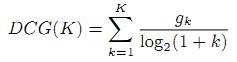
где gk – вес документа при ранге k. Оценка по пятибалльной шкале назначается каждому документу на основе его значения релевантности.
Мы обучили модель ранжирования используя градиентные древа решений со всеми существующими оценочными характеристиками, а так же создали систему, использующую в дополнение к ним характеристику ClickRank. Данные для обучения и проверки разделены через кросс-валидацию. Мы использовали одинаковые настройки параметров во всех экспериментах сравнения точности.
Для численной оценки относительной важности Si каждой индвидуальной входной характеристики ранжирования xi, мы использовали следующую формулу:
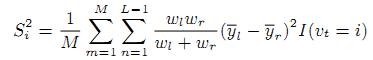
где vt–разделяющая переменная в нетерминальном узла n, а y—l, y—r–средние значение регрессии в левом и правом поддреве соответственно. wl и wr–соответственные суммы весов.
В данном эксперименте мы использовали ряд из 9041 случайно отобранных запросов в поисковом логе. Для каждого запроса 5-20 веб-страниц получили оценку от экспертов и определённые значения важности от 1 до 5 баллов.
Использование ClickRank в качестве дополнительной характеристики в оценке релевантности дало улучшение в 1.02%, 0.97%, 1.11% и 1.331% по метрикам DCG(1), DCG(5), DCG(10) и NDCG соответственно, при этом модель уже содержала сотни характеристик оценки контента (анкоры, титулы, контент в body и абзацы страницы) , ссылочной массы, поисковых запросов и прочих источников. Результаты имеют серьёзную статистическую важность с точки зрения информационного поиска и сведены в таблицу 8.
Таблица 8. Превосходство ClickRank по различным метрикам оценки.
| Длина запроса | Число запросов | Число эффективно обработанных запросов | DCG(1) | DCG(5) | DCG(10) | NDCG | p-значение |
| 1 | 1484 | 1232 | 0.448% | 0.713% | 1.002% | 0.378% | 5.33×10-2 |
| 2 | 2992 | 2450 | 0.560% | 0.993% | 1.121% | 1.071% | 4.65×10-4 |
| 3 | 2153 | 1722 | 1.618% | 1.076% | 1.406% | 2.177% | 1.10×10-4 |
| 4+ | 2412 | 1937 | 0.918% | 0.861% | 0.784% | 1.433% | 1.61×10-5 |
| все | 9041 | 7341 | 1.020% | 0.966% | 1.105% | 1.331% | 9.98×10-5 |
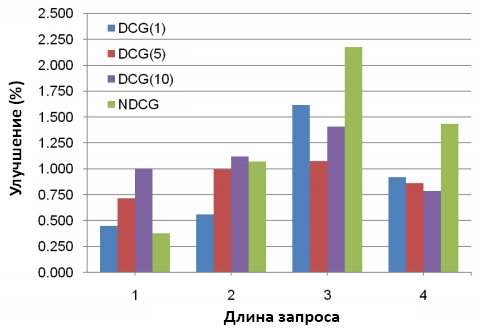
Улучшения весьма существенны в контексте коммерческого сетевого поиска. 81.2% от 9000 запросов демонстрируют пользу ClickRank. Кроме того, наблюдается серьёзное повышение точности ранжирования выдачи с длинными запросами, которые зачастую являются проблемным местом поисковых систем. На рисунке 15 наглядно показаны улучшения в зависимости от длины запроса.
Многие поисковики выдают набор «быстрых ссылок» – ссылки прямого доступа к страницам сайта, помимо поисковых результатов. Например, первая позиция в выдаче по навигационному запросу «ebay» – адрес www.ebay.com – так же содержит быстрые ссылки на популярные страницы сайта, например motors.ebay.com, half.ebay.com. Обычно, такие быстрые ссылки являются указателями на часто посещаемые разделы по данным лога кликов. Однако этот метод имеет два существенных ограничения. Во-первых, лог запросов не содержит пользовательскую активность вне работы с поисковиком, которая составляет 95% времени в интернете. Во-вторых, результаты, рассчитанные из логов запросов имеют сильную зависимость по отношению к старым навигационным ссылкам, которые получают больше кликов из-за своей видимости в поисковиках.
Мы демонстрируем новаторское применение ClickRank для обнаружения и отображения динамических быстрых ссылок в поисковых результатах. ClickRank адекватно обрабатывает быстрые ссылки за счёт ранжирования документов по свежести обновления. Главная идея заключается в применении временного интервала для функции отображения в уравнении (9) для определения скорости обновления контента, полученного краулером поисковой системы. Кроме того, в дополнение к обычным поисковых результатам система отображает высокоранжированные ClickRank страницы в виде быстрых ссылок.
На Рисунке 16 показаны результаты с обнаруженными системой быстрыми ссылками по запросу «beijing olympic 2008» за 2 полных суток во время летних Олимпийских Игр 2008. Быстрые ссылки, полученные ClickRank отображаются поочерёдно с самыми кликабельными навигационными ссылками. Быстрые ссылки хорошо освещают последние события, в то время как ссылки с наибольшим количеством переходов остаются без изменений. Результаты создания быстрых ссылок при помощи ClickRank имеют большое значение в контексте предлагаемого потенциально интересного контента пользователю по сравнению с ссылками, просто отображающими популярность структуры сайта.
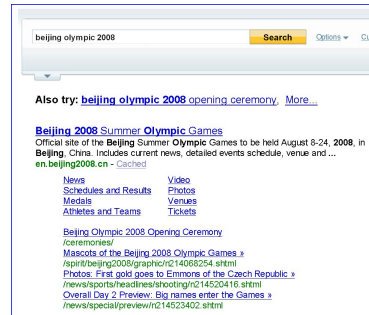
Рисунок 16 (а). 10 августа 2008.
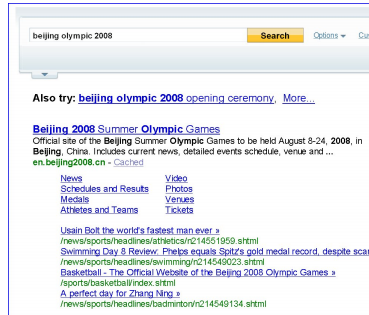
Рисунок 16 (б). 10 августа 2008.
Итак, мы изучили направление майнинга пользовательского поведения при сёрфинге для создания модели сессий в зависимости от интересов пользователей и предложили модель ранжирования по предпочтениям. Мы представили характеристики обычных веб-сессий и показали достойные внимания паттерны пользовательского поведения, полученные из данных сессий. Нами предлагается методология ClickRank, эффективный масштабируемый алгоритм для оценки важности как отдельных страниц, так и веб-сайтов целиком на основе предпочтений пользователей. ClickRank основвывается на модели заинтересованности пользователя Сети и в ходе экспериментов доказал адекватность своей оценки. Мы также рассмотрели преимущества ClickRank над существующими способами ранжирования. ClickRank выгодно отличается скоростью расчётов и точностью результатов, к тому же имея огромный потенциал по созданию динамических быстрых ссылок.
Посредством использования данных прошлых исследований, связанных с ранжированием информации, ClickRank открывает широкие возможности по потенциальному улучшению качества органического поиска. Так как количество сетевого трафика продолжает экспоненциально расти, можно ожидать повышенного внимания к поведенческим факторам в ближайшем будущем.
Полезная информация по продвижению сайтов:
Перейти ко всей информации