SEO-Константа
Яндекс.Директ + оптимизация
Прежде мы исследовали альтернативные способы вычисления важности веб-страниц, отличающиеся от стандартных способов оценки при помощи ссылочного графа. В первом разделе настоящего материала, посвященного поведенческим факторам ранжирования, мы рассматриваем проведённые эксперименты, а также приводим статистику работы BrowseRank в практических условиях. Во втором разделе мы переходим к следующему поведенческому алгоритму, который называется ClickRank.
Мы провели ряд экспериментов для проверки эффективности предложенного алгоритма BrowseRank. Далее представлен итоговый отчёт и показаны выходные данные в виде таблиц. Первый эксперимент проводился на уровне веб-сайтов, чтобы узнать о производительности BrowseRank в рамках поиска важных и/или интересных сайтов и исключения спам-ресурсов. Второй эксперимент проводился на уровне веб-страниц для проверки эффективности BrowseRank в улучшении ранжирования релевантности документов.
В качестве исходных данных мы использовали информацию о поведении пользователей, собранную в Интернете коммерческой поисковой системой. Всевозможные персональные сведения строго отфильтровывались и полученные данные были специально обработаны для максимального исключения информации о личности пользователей. В сумме было получено более 3 млрд. записей и среди них было 950 млн. уникальных URL. На Рисунке 2 показана логарифмическая шкала распределения длительности посещения страницы, которая была случайным образом выбрана из части выборки. В этой части все страницы имели большое число посещений. Из графика видно, что зависимость не прямолинейна в начале. Это значит, что кривая не следует точной экспоненте распределения, что подтверждает наши доводы о зашумленности данных о длительности посещения.
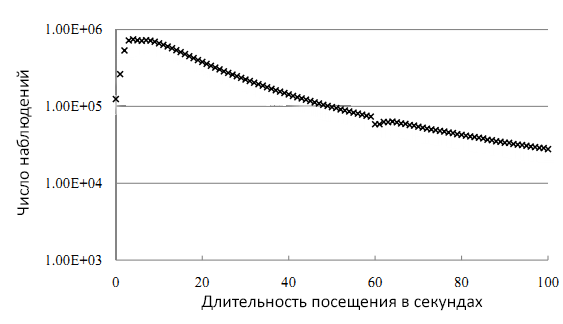
Рисунок 2. Распределение длительности визитов.
При проверке BrowseRank на уровне веб-сайтов мы не делали различия между страницами на одном и том же сайте. Переходы между страницами одного и того же сайта не принимались в расчёт и обобщались с переходами на (и с) страницы извне. В результате был получен граф сёрфинга пользователей на уровне сайтов, включающий в себя 5.6 млн. вершин и 53 млн. рёбер. Так же был создан ссылочный граф, содержащий 5.6 млн. сайтов из поисковой системы. В сумме у нас было 40 млн. веб-сайтов из поисковой системы. В качестве проверки работы нашего алгоритма, мы рассчитали для них PageRank и TrustRank.
В Таблице 3 показан топ из 20 сайтов, ранжированных разными алгоритмами. Из таблицы можно сделать следующие выводы:
Как итог, результаты ранжирования BrowseRank точнее отражают интересы пользователей, чем PageRank и TrustRank.
Таблица 3.Топ 20 веб-сайтов по версии разных алгоритмов.
| # | PageRank | TrustRank | BrowseRank |
| 1 | adobe.com | adobe.com | myspace.com |
| 2 | passport.com | yahoo.com | msn.com |
| 3 | msn.com | google.com | yahoo.com |
| 4 | microsoft.com | msn.com | youtube.com |
| 5 | yahoo.com | microsoft.com | live.com |
| 6 | google.com | passport.net | facebook.com |
| 7 | mapquest.com | ufindus.com | google.com |
| 8 | miibeian.gov.cn | sourceforge.net | ebay.com |
| 9 | w3.org | myspace.com | hi5.com |
| 10 | godaddy.com | wikipedia.org | bebo.com |
| 11 | statcounter.com | phpbb.com | orkut.com |
| 12 | apple.com | yahoo.co.jp | aol.com |
| 13 | live.com | ebay.com | friendster.com |
| 14 | xbox.com | nifty.com | craiglist.org |
| 15 | passport.com | mapquest.com | google.co.th |
| 16 | sourceforge.net | cafepress.com | microsoft.com |
| 17 | amazon.com | apple.com | comcast.net |
| 18 | paypal.com | infoseek.co.jp | wikipedia.org |
| 19 | aol.com | miibeian.gov.cn | pogo.com |
| 20 | blogger.com | youtube.com | photobucket.com |
Случайным образом были отобраны 10 000 сайтов из 5.6 млн. Эксперты провели оценку на наличие поискового спама и 2714 сайтов были помещены в спам-категорию. Остальные сайты в выборке были отмечены как нормальные ресурсы. Мы использовали распределение спама в выборке для оценки работы алгоритмов. 5.6 млн. сайтов были отсортированы в убывающем порядке по оценке алгоритма. Результаты сортировки были размещены в 15 выборках. Число сайтов в выборках, помеченных как спам разными алгоритмами, показано в Таблице 4.
Таблица 4. Число спам-сайтов в выборках.
| # выборки | Число сайтов | PageRank | TrustRank | BrowseRank |
| 1 | 15 | 0 | 0 | 0 |
| 2 | 148 | 2 | 1 | 1 |
| 3 | 720 | 9 | 11 | 4 |
| 4 | 2231 | 22 | 20 | 18 |
| 5 | 5610 | 30 | 34 | 39 |
| 6 | 12600 | 58 | 56 | 88 |
| 7 | 25620 | 90 | 112 | 87 |
| 8 | 48136 | 145 | 128 | 121 |
| 9 | 87086 | 172 | 177 | 156 |
| 10 | 154773 | 287 | 294 | 183 |
| 11 | 271340 | 369 | 320 | 198 |
| 12 | 471046 | 383 | 366 | 277 |
| 13 | 819449 | 434 | 443 | 323 |
| 14 | 1414172 | 407 | 424 | 463 |
| 15 | 2361420 | 306 | 328 | 756 |
Заметно, что BrowseRank успешно выделяет спам-сайты в выборках, а число спам-ресурсов в топовых выборках ниже, чем у PageRank и TrustRank. Это значит, что BrowseRank эффективнее борется со спамом, чем PR и TR. Причинами тому является:
Кроме того, производительность TrustRank выше, чем у PageRank, что следует из результата, полученного в [8].
В поисковых системах страницы часто ранжируются в выдаче по двум факторам: ранг релевантности и ранг важности (веса). Линейная комбинация двух списков ранжирования выглядит так:
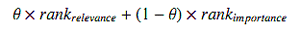
Здесь 0 ≤ θ ≤ 1 является параметром комбинации.
Опять использовались данные о поведении пользователей и ссылочный граф. В этот раз мы оценивали работу алгоритмов на уровне страниц. Из поисковой системы было выбрано 8000 запросов и связанные с ними страницы. Три независимых специалиста оценили релевантность страниц каждому запросу: 1 – релевантна, 0 – нерелевантна. Оценки были просуммированы и в случае, когда у страницы было два положительных отзыва, она относилась к категории «релевантна». В прочих случаях страницы были помечены как нерелевантные. Выборка была заранее обработана и очищена от спам-страниц. Как следствие, нам не требуется вычислять TrustRank, так что мы будем работать только с PR. Данные страницы рассматриваются в рамках данных о поведении пользователей.
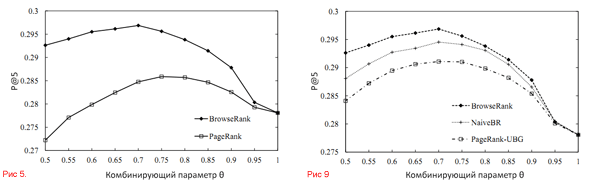
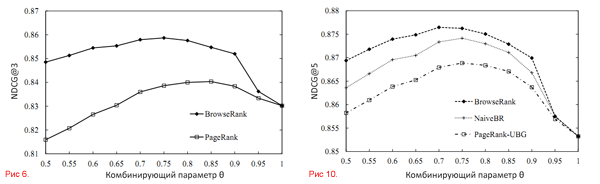
В этом эксперименте мы сравнивали работу PageRank и BrowseRank в качестве модели оценки важности. BM25 [40] использовался в качестве модели релевантности. Мы применили три метрики оценки эффективности ранжирования: MAP [41], точность (P@n) [41] и NDCG@n (Normalized Discount Cumulative Gain, сравнение нашего ранжирования с идеальным значением) [42, 43]. Результаты эксперимента показаны на графиках 3 – 9. Из графиков видно, что BrowseRank превосходит PageRank по всем параметрам в рамках нашей оценки. Например, на Рисунке 7 можно увидеть, что NDCG@5 у BM25 равен 0.853 (при θ = 1). BrowseRank достигает пикового значения NDCG@5 в 0.876 при тета = 0.70, а PageRank – 0.862 при θ = 0.8. Также были проведены t-тесты на уровне доверия 95%. В метрике MAP, превосходство BrowseRank над PR статистически отражено p-значением 0.0063. В метрике P@3, P@5, NDCG@3 и NDCG@5 качество так же выше со значениями 0.00026, 0.0074, 3.98X10-7 и 3.57X10-6 соответственно.
Для дальнейшего использования данных о поведении пользователей и оценки нашего алгоритма, мы приводим сравнение с двумя простыми алгоритмами, которые так же используют данные о поведении или графы сёрфинга пользователей: PageRank-UBG (взвешенный PR, рассчитанные по графу сёрфинга пользователей) и Naive BrowseRank (результат расчёта по числу кликов и средней продолжительности визита). Основываясь на результатах, отражённых на графиках 8, 9 и 10, можно сделать следующие выводы:
Графики 3–10. Измерение эффективности поиска разными метриками и сравнение BrowseRank с другими алгоритмами.
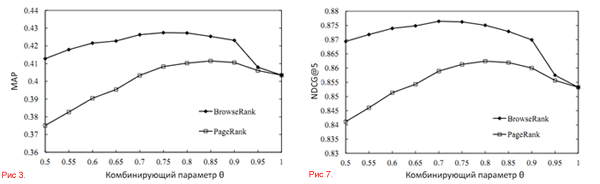
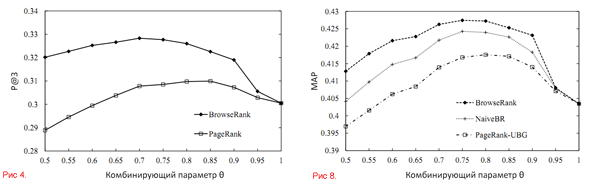
Итак, ранее мы выяснили, что ссылочный веб-граф не является надёжным источником информации для оценки важности веб-страниц. Более того, существующие алгоритмы ссылочного анализа типа PageRank слишком прямолинейны и просты для адекватной оценки важности страницы. Для решения этой проблемы мы предлагаем использование сведений о поведении пользователей для создания графа сёрфинга, построения модели непрерывно-временного процесса Маркова на графе и применение эффективного алгоритма для расчёта важности веб-страницы по созданной модели.
Данные из графа сёрфинга пользователей более надёжны и обширны, чем информация из классического ссылочного графа, а непрерывно-временная модель Маркова гораздо более производительна, чем все остальные существующие модели. Дальнейшее использование наших разработок приведёт к более точным результатам в оценке важности веб-страниц. Эксперименты подтвердили, что BrowseRank производительнее, чем PageRank и TrustRank в двух задачах веб-поиска, показывая, что современные методы оценки важности на самом деле не имеют серьёзных достоинств.
Однако по-прежнему существует ряд технических вопросов, которые необходимо исследовать в будущих исследованиях:
Сбор данных о поведении пользователей в Сети раскрывает новые возможности в сфере информационного поиска. Такие данные как активность пользователей на страницах выдачи поисковых систем являются ценным источником информации для понимания намерений пользователя и его запроса. Исследования логов поисковых систем [36, 35, 2, 37, 1, 25] и данных о кликабельности (click-through data) [9, 20, 21, 3, 33] показали серьёзные улучшения в качестве выдачи, хотя рассмататривались действия пользователей только на страницах с результатами поиска – совсем небольшой части пользовательской активности в Сети. Эффективная обработка всей пользовательской активности может дать поисковым системам понять предпочтения и намерения пользователей, а так же может как повысить производительность поиска, так и удовлетворить потребности пользователя, оставляя приятное впечатление от использования системы. Во-первых, анализ всех действий пользователя даёт наиболее близкую к пользовательской оценку важности сайтов и веб-страниц [26]. Во-вторых, поисковые системы сталкиваются с проблемой расстановки приоритетов по процессам индексирования, краулинга и обработки запросов [4]. В данных условиях внимание пользователей к определённой странице является основным критерием к оптимизации процессов обработки выдачи и так же отражает изменение поведения пользователей со временем. Так как содержание Сети обновляется и пополняется гораздо чаще, чем обрабатывается поисковиками [31], поиск популярного контента и адаптирование расписания краулинга под интересы пользователей явяется важным приоритетом в работе поисковых систем. Ещё одной интересной сферой исследования в работе поисковых машин является доступ к глубинному (невидимому) вебу (deep web) – части Сети, которая динамически генерируется и недоступна напрямую автоматическим краулерам [17]. Охват роботов может быть увеличен за счёт доступа к истории посещений пользователей, которая может указать путь на скрытые URL.
Здесь мы сконцентрируемся на большом объёме данных, полученных из компьютерного анализа поведения пользователей для: а) оценки всех действий пользователя в Сети и б) разработки моделей, обрабатывающих данные о сессиях пользователей. Нашим главным вкладом является инновационный алгоритм ClickRank, использующийся для оценки важности веб-страниц и сайтов. ClickRank первым делом обрабатывает локальное значение важности для каждой страницы на сайте за каждую сессию сёрфинга пользователя, основываясь на предпочтениях пользователя в контексте данной сессии сёрфинга. Далее ClickRank обобщает локальные значения всех сессий для создания глобальной таблицы ранжирования. Мы оцениваем этот метод в трёх глобальных сферах поиска. Первый эксперимент – это традиционная задача ранжирования веб-сайтов, в котором мы показываем, что эффективность ClickRank может поспорить с современными подходами, включая PageRank [32] и недавно предложенным BrowseRank [26], учитывая, что для ClickRank требуется значительно меньшая вычислительная мощность. Во втором эксперименте мы демонстрируем инновационность и эффективность ClickRank в ранжировании веб-страниц с несколькими сотнями современных характеристик, включая количество посещений страниц и ссылочный веб-граф. В данном крупномасштибном тестировании мы ставим задачу обучения оптимальной модели ранжирования в виде проблемы аддитивной (добавочной) регрессии, используя градиентные древа решений (gradient boosted decision trees) и сравниваем адекватность характеристик алгоритма ClickRank с прочими. Наконец, мы тестируем ClickRank в системе, которая собирает свежие и популярные страницы и показывает пользователям на странице выдачи в виде динамических быстрых ссылок.
Будем считать, что веб-сессия – это логическая единица пользовательской активности во времени, отражающая взаимодействие пользователя с браузером. Концепция веб-сессии в нашей работе применяется ко всем категориям веб-активности, в то время как прочие работы считают сессию простым набором поисковых запросов и не принимают во внимание её многие элементы.
Доступ к истории браузера можно получить из нескольких иточников (ISP, сетевые шлюзы, тулбары). В данной работы мы используем информацию, собранную тулбаром Yahoo! – специальным расширением для браузера, которое помогает пользователям в быстром поиске необходимой информации. Тулбар записывает активность пользователей, которым дали ему на это разрешение во время установки. Каждая запись в логе состоит из cookie, времени визита, URL, рефарального URL и списка атрибутов события. Cookie – это уникальный анонимный идентификатор клиента, который истекает и обновляется в определённое время. URL – идентификатор страницы, к которой запрошен доступ, а реферальный URL – предыдущий, с которого запрашивается доступ. Список атрибутов события состоит из различных метаданных, связанных с активностью пользователя. Для экспериментов в нашей работе были собраны анонимные данные о 30 млрд. событий за 6 месяцев в 2008-м году в системе Yahoo!
Для сегментации активности на сессии мы используем структуру пар реферального-нынешнего URL для воссоздания цепи активности пользователя. В нашей системе для мультиюзеров (с несколькими открытыми вкладками в браузере) мы группируем действия, связанные с разными задачами в разные сессии, а не обобщаем их в одну. Далее, мы задаём сортируем действия пользователя по времени и помещаем их в интервал с двумя границами. Мы считаем, что говая сессия начинается, когда зафиксирован промежуток неактивности в 30 минут (как и в BrowseRank). Так же новая сессия начинается, если в ней не присутствует реферальный URL (т.е. на страницу выполняется прямой заход).
Наш метод сегментации сессий требует только одной итерации сканирования всех данных и не требует сложных вычислений. Недавние исследования по разбиению логов запросов на логические сессии [6] показали, что в подавляющем большинстве (92%) случаев, сегментационный метод, основанный на установке тайм-аута (предела времени) даёт результат, идентичный результату сложных и вычислительно-затратных алгоритмов [6], если оба проверяются экспертами-людьми, используя объективный индекс Rand [34]. Для небольшой части оставшихся сессий, которые трудно сегментировать даже сложными алгоритмами, метод тайм-аута уступает по производительности всего на 1.4%.
| Среднее число событий за сессию | 9.1 |
| Стандартное отклонение числа событий | 24.5 |
| Средняя продолжительность сессии (с) | 420.3 |
| Стандартное отклонение продолжительности | 1068.0 |
| Сессий пользователя в день | 15.5 |
| Процент поисковых сессий | 4.85% |
Таблица 5. Суммируем ключевые характеристики стандартной веб-сессии.
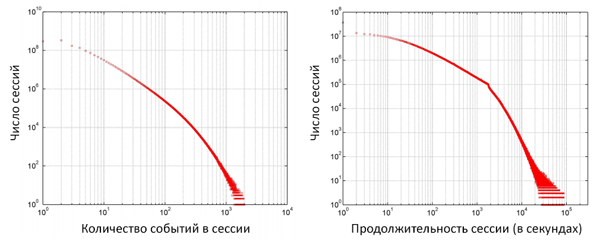
На Рисунке 11 показано вероятностное распределение числа событий в сессии и длительность сессии, соответственно. Число событий распределяется экспоненциально. Его математическое ожидание и производная 9.1 и 24.5, соответственно, что показвыает наличие у веб-сессии широкого набора действий, по сравнению с поисковой сессией, которая состоит из 5 событий в среднем. Кроме того, поисковые сессии (содержащие хотя бы один запрос, поданный в поисковую систему) составляют 4.85% от общего числа сессий. Это говорит о том, что концентрация внимания на них приведёт к исчезновению независимости в анализе.
Граф продолжительности сессии показывает два типа экспоненциального распределения тайм-аута в 1800 секунд (30 мин.). В среднем веб-сессия длится 420.3 секунды со стандартным отклонением в 1068 секунд.
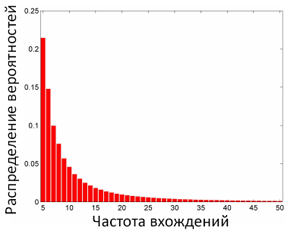
Важно учитывать разреженность контента среди 30 млрд. изучаемых событий. Нами был получено 3.1 млрд. уникальных URL. Для того, чтобы убрать индивидуальную зависимость, мы рассматривали страницы, на которые кликало более 5 пользователей. Число таких страниц составляет 48.5 млн. Рисунок 12 показывает распределение встречающихся веб-страниц в истории пользователей.
Майнинг сессий пользователей в масштабах веба особенно важен для понимания поведенческих факторов пользователей в соответствии с их потребностями. Нами предлагается несколько подходов к кластеризации, основанных на дифференцировании и статистической обработке сессий по тематике. В эксперименте мы привязали каждый URL к определённым категориям событий, разбитых по пяти высокоуровневым целям: поиск, работа с почтой, обучение, шоппинг и прочее (социальные сети и мультимедийное времяпрепровождение). Мы создали диаграмму, отражающую распределение событий в категоризированных сессиях. Чтобы максимально точно сопоставить посещение URL с категорией сессии, мы привлекли экспертов для категоризации топ 1200 популярных сайтов по вышеуказанным критериям.
В каждой сессии событие сёрфинга было отнесено либо к категории «неопределённое», либо к одной из пяти заданных. Все шесть типов событий (вместе с «неопределённым») были отсортированы для наглядного вида распределения с исключением сессий, содержащих более 80% неопределённых событий. Для дальнейшего анализа распределения в диаграмме сесий, мы использовали принципиальный анализ компонентов (PCA, principle component analysis) для уменьшения количества измерений в семимерном векторе характеристик. PCA спроецирован на маломерное линейное подпространство для более наглядного отображения разброса данных. 3D-вид диаграммы сессий на Рисунке 13 показывает неоднородность результатов, так как у нас есть широкий охват данных об активности. Среди первых шести собственных значений доминирует первое.
Полезная информация по продвижению сайтов:
Перейти ко всей информации