SEO-Константа
Яндекс.Директ + оптимизация
В Сети содержится огромное количество информации и одним из актуальных вопросов в современном машинном обучении является правильный автоматический анализ и обработка данных из таблиц веб-сайтов. В нашей работе мы рассматриваем вопрос обучения робота «пониманию» HTML-таблиц в Сети. Из 0.3 млрд веб-документов мы собрали 1.95 млрд таблиц, из которых 0.5-1% содержали классифицированную по свойствам информацию (сущности с атрибутами). Во-первых, мы оспариваем утверждение, что для полноценного понимания таблиц необходим аналогичный человеческому «мозг». Во-вторых, мы доказываем, что процесс понимания таблицы не является простым определением положения строк и столбцов. Если табличные данные верно ассоциированы с системными знаниями, то все аналогичные таблицы будут распознаваться с такой же точностью понимания. Другими словами, «понимание» имеет место в том случае, когда компьютер верно анализирует семантику таблиц посредством сопоставления концепций в базе знаний.
Всемирная Паутина содержит невообразимый объём информации. К сожалению, большая часть этих данных предназначается исключительно человеку, а не машине. Одним из актуальных вопросов в развития Интернета является задача обучения машины понимать и обрабатывать сложные данные на веб-страницах.
В этой работе мы концентрируемся на таком аспекте, как понимание и верная интерпретация данных из HTML-таблиц. Этот вопрос актуален по двум причинам. Во-первых, в Сети уже присутствует несколько миллиардов веб-страниц с таблицами, во множестве которых содержится ценная информация. Во-вторых, таблицы хорошо структурированы и относительно просты для понимания, в то время как конвертирование обычного текста в структурированные данные с использованием техник обработки естественного языка весьма затратно и плохо применимо в масштабах корпуса Веба.
Фактически, мы приравниваем задачу понимания веб-таблицы к задаче корректной ассоциации данных с соответствующими семантическими концепциями в базе знаний. В частности, после создания ассоциативной связи каждая строка таблицы будет описывать атрибуты отдельной сущности (экземпляра) концепции – т.е. некоторые её параметры. В нашей работе предполагается, что таблицы горизонтальные, т.е. атрибуты сущности располагаются горизонтально, а в столбцах записываются их значения. Рассмотрим, к примеру, таблицы 1-а, 1-б и 1-в. Наша задача – сопоставить таблицу 1-а с концепцией президентов Российской Федерации в базе знаний. Это значит, что в нашей базе знаний содержится концепция президентов РФ и несколько экземпляров концепции (например, Владимир Путин) с характерными атрибутами (например, датами рождения). По аналогии необходимо сопоставить таблицу 1-б с концепцией отдельных субъектов Российской Федерации, свойствами которых являются административный центр и численность населения. Таблица 1-в сопоставляется с концепцией российских политиков, имеющих в качестве атрибутов политические партии. Стоит отметить, что в таблице может содержаться не вся информация об анализируемых сущностях, однако её должно быть достаточно в базе знаний для верного «угадывания» смысла таблицы. Так же необходимо знать, что процесс понимания таблицы по её данным отделён от понимания таблицы через распознавание структуры. Например, таблица 1-в имеет явно заданную структуру и понимание её смысла будет вестись первоначально через сопоставление структуры с определённой концепцией.
| Владимир Путин | 07.10.1952 | Ленинград |
| Дмитрий медведев | 14.09.1965 | Ленинград |
Таблица 1 (а).
| Ленинградская область | Санкт-Петербург | 5,028,313 |
| Московская область | Москва | 11,977,988 |
Таблица 1 (б).
| Имя | Политическая партия |
| Дмитрий Медведев | Единая Россия |
| Владимир Жириновский | ЛДПР |
Таблица 1 (в).
Как только решена задача понимания таблицы, хранящиеся в ней данные могут быть использованы, например, для улучшения семантического поиска. Следующие примеры демонстрируют некоторые «умные» ответы на семантические запросы. В качестве входных данных используются таблицы 1-а, 1-б и 1-в.
Если пользователь подаёт запрос «день рождения Путина», система покажет ему следующую таблицу:
| Президент | Дата рождения |
| Владимир Путин | 07.10.1952 |
Это показывает, что система корректно интерпретировала первый столбец таблицы 1-а, как относящийся к президентам, а второй – к их дням рождения.
По запросу «Ленинградская область» ответ системы будет таковым:
| Субъект Российской Федерации | Административный центр | Население |
| Ленинградская область | Санкт-Петербург | 5,028,313 |
Отметим, что 1) в результате показываются общие данные о субъекте (по заголовку) и 2) система отличает смысл запросов данных о предизенте и о субъекте.
По запросу «политики» ответом системы будет комбинация таблиц 1-а и 1-в с созданным заголовком:
| Политик | Дата рождения | Город | Политическая партия |
| Владимир Путин | 07.10.1952 | Ленинград | — |
| Дмитрий Медведев | 14.09.1965 | Ленинград | Единая Россия |
| Владимир Жириновский | — | — | ЛДПР |
Этот результат показывает нам интересное свойство системы: алгоритм знает, что президенты так же являются политиками и разные данные могут быть успешно совмещены в одном общем ответе. Подобная семантическая ассоциация таблиц друг с другом намного важнее, чем сухое сопоставление типов данных в каждом стоблце таблиц.
Однако понимание структуры данных и понимание семантики и контекста сильно различаются друг от друга. Например, изучая таблицу 1-а как понять, что Владимир Путин – президент, а 07.10.1952 – не просто дата, но так же и день его рождения? Более того, как понять, что первая строка описывает президента, а не город Санкт-Петербург? И, наконец, как нам совместить таблицу 1-а и 1-в?
Людям для правильного ответа на эти вопросы требуется определённый багаж знаний. Если известно, что Путин и Медведев являются президентами Российской Федерации, то, очевидно, можно добавить титул «президент» к первому столбцу таблицы 1-а. Далее, видно, что второй столбец – это даты. Так как президенты так же являются людьми, то очевидна возможность добавить заголовок «дата рождения» ко второму столбцу, так как подобный атрибут всегда сопутствует концепции «человек». Так как мы знаем, что Ленинградская и Московская области входят в состав России, можно добавить заголовок «субъект Российской Федерации». После этого, посмотрев на заголовки Президент, Дата рождения и Субъект Российской Федерации здравомыслящий человек поймёт, что свойства «дата рождения» и «город» являются атрибутами президентов, а не характеристиками субъектов РФ.
Таким образом полноценное понимание таблиц достигается после ответов на два вопроса:
1. Какая концепция (класс) вероятнее всего включает в себя ряд данных свойств?
2. Какая концепция (класс) вероятнее всего обладает рядом данных свойств?
Мы называем процесс получения ответов на эти вопросы концептуализацией. В нашей работе используется онтология Probase [1-4] в качестве багажа знаний для концептуализации информации в веб-таблицах.
[В информационных технологиях термином онтология обозначается крупный сектор формализованных и структурированных данных (т.е. база знаний), являющихся сущностями (объектами, экземлярами, индивидами), концепциями (понятиями, классами, группами), атрибутами (свойствами, характеристиками, параметрами) и отношениями (зависимостями объектов). Например, одним из объектов класса «информационный поиск» может являться сущность «продвижение сайтов« с атрибутами «срок» и «стоимость». Класс «информационный поиск» может включать в себя так же сущности «поисковый алгоритм», «ранжирование веб-документов» и т.д. Сущность «продвижение сайтов» так же может являться и классом, включающим в себя сущности «оптимизация страницы» (атрибуты «плотность ключевых фраз», «релевантность заголовка»), «создание контента» (атрибуты «число документов», «наличие изображений»). Создание онтологии направлено на предельно точную классификацию и детальное описание объектов в какой-либо области исследования.]
Probase – это огромная база знаний (данных), которая состоит из фактов, автоматически отобранных из 50 терабайт корпуса Веба и прочей дополнительной информации. Важным различием между Probase и прочими базами, создаваемыми вручную (например, Open Mind Common Sense [5], Freebase [6]) является её объём: Probase содержит более 2.7 миллионов концепций, которые охватывают большинство (если не все) представления о мировых фактах в человеческом сознании. Каждая концепция описывает ряд сущностей, ранжированных по популярности или иным метрикам, а так же ряд атрибутов, описывающих сами сущности в каждой отдельной концепции. Используя данные концепции и вероятностные оценки Probase, существенно улучшается процесс понимания веб-таблиц, так как они так же оперируют вероятностными данными, которые тяжело отслеживать вручную.
На рисунке 1 показан сниппет систематики Probase. Овалами обозначены концепции и их атрибуты, прямоугольники обозначают сущности, а стрелками показаны отношения.
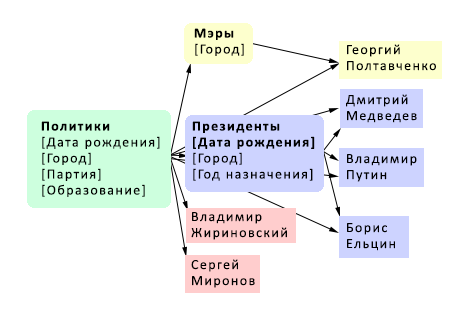
Рисунок 1. Сниппет систематики Probase.
На рисунке 2 целиком описан процесс понимания веб-таблицы. Прежде всего определяется заголовок таблицы. Если он отсутствует, то алгоритм пытается его сгенерировать на основе содержимого самой таблицы. Далее мы идентифицируем столбец, содержащий сущности (тогда остальные столбцы содержат атрибуты сущности). Если не удаётся определить заголовок или столбец сущностей (или же качество результата ниже требуемого), таблица исключается из анализа. Если анализ проведён верно, то распознанный контент присоединяется к концепции в Probase, которая лучше всего описывает столбец сущностей, таким образом расширяя базу Probase.
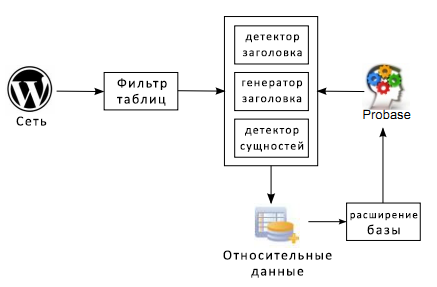
Рисунок 2. Принципиальная схема процесса понимания таблиц.
Для корректной концептуализации любой веб-таблицы необходимо располагать большим числом концепций, их атрибутов и однозначных примеров сущностей. В нашем исследовании по пониманию таблиц используется база данных Probase [1]. Probase – это исследовательский прототип, нацеленный на создание единой базы мировых общеизвестных фактов, собранных из информации в Сети и поисковых логов. Каркасом Probase является паттерн Hearst [7] – паттерн «такой как». Например, предложение, содержащее «…такие политики как Владимир Путин…» утверждает, что слово политик характеризует Владимира Путина, т.е. является атрибутом сущности «Владимир Путин».
Несмотря на свою популярность в извлечении концепций сущности, паттерны Hearst недостаточно эффективны для получения атрибутов и значений. Как итог, ядро системы Probase, к сожалению, не охватывает всё пространство атрибутов/значений и ему требуется расширение. Для дополнения Probase большим числом характеристик, мы используем следующий лингвистический паттерн для нахождения атрибутов концепции C:
Какой A у I?
В данном случае, А – главные атрибуты (зёрна или ядра), которые надо найти у сущности I в концепции C, полученной в Probase. к примеру, предположим, что необходимо найти главные атрибуты у концепции страны. Из Probase известно, что Россия является страной. Далее, используя паттерн «Какой * у России?» при информационном поиске, можно получить, например сопоставление «Какой (город) – столица России?». Таким образом, столица является кандидатом в атрибуты концепции страна. Полученные таким образом атрибуты достаточно хороши для определния множества структурных схем таблиц.
| C | Концепция |
| I | Экземпляр сущности |
| A | Атрибут |
| E(c) | Сущности концепции c |
| A(c) | Атрибуты концепции c |
| C(i) | Концепции, описывающие сущность i |
| pc(i) | Правдоподобность сущности i в классе c |
| ac(i) | Двусмысленность сущности i в классе c |
Таблица 2. Обозначения Probase
1. Почему мы используем жёсткую конструкцию «Какой A у I?»?
Мы намеренно применяем такой узконаправленный паттерн для увеличения точности результатов. Так как а) мы заинтересованы только в главных атрибутах, б) мы используем несколько разных сущностей для поиска атрибутов каждой концепции и в) мы сопоставляем паттерн с гигантским Веб корпусом (50 терабайт), мы всегда можем найти подходящих кандидатов в атрибуты. Отметим, что вышеуказанный паттерн является освновой для целого ряда паттернов. например, слово «какой» может быть заменено словами «где» или «кто».
2. Какие сущности следует использовать в качестве I в паттерне?
Для любой концепции Probase возвращает список сущностей, каждая из которых характеризуется определённой оценкой. Двумя важными параматрами сущности являются правдоподобность и двусмысленность. Значение правдоподобности показывает, насколько вероятен факт принадлежности рассматриваемой сущности данной концепции. Значение двусмысленности указывает на возможность принадлежности так же и другим концепциям.
К примеру, и Microsoft и Apple являются компаниями, однако Apple имеет более высокий показатель двусмысленности, т.к. apple (яблоко) – это ещё и фрукт. При использовании сущности Apple при обучении алгоритма, можно наблюдать ошибку, когда в атрибуты компании добавляется характеристика вкус. Таким образом, в машинном обучении отдаётся предпочтение наиболее однозначным сущностям с высокой степенью правдоподобности и низким показателем двусмысленности. Более подробно алгоритм назначения оценок описывается в работе [1].
Для нашего паттерна мы подбираем приемлимые сущности ES(c) класса c по формуле:
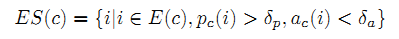
где δp и δa – предельные значения правдоподобности (англ. plausibility) и двусмысленности (англ. ambiguity), соответственно.
3. Как ранжировать кандидатов для получения главных атрибутов?
Для каждой концепции c мы выставляем оценки кандидатам в атрибуты из списка ES(c), а затем объединяем атрибуты, чтобы получить финальные варианты. Если атрибут a получен от сущности i, то мы добавляем веса к его значению правдоподобности pc(i). Далее мы сравниваем значения правдоподобности всех кандидатов и утверждаем самые высокоранжированные главными атрибутами концепции c. Пусть D(a) – несколько сущностей среди списка ES(c) с атрибутом a. Вес атрибута-кандидата a в соответствии с c определяется по формуле 1:
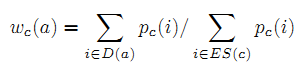
Отметим, что Формула (1) учитывает как правдоподобность, так и двусмысленность, потому что i ∈ ES(c).
При использовании лингвистических паттернов для поиска атрибутов в Сети встаёт проблема зашумленностишум данных, т.е. неизбежное наличие некорректных кандидатов атрибутов. Однако для разных сущностей I паттерны выдают различные типы шума, что позволяет эффективно отсекать шумовые данные на стадии ранжирования результатов.
Кроме применения вышеописанного паттерна, мы так же извлекаем атрибуты из базы DBPedia. Мы проводим строгую проверку соответствия при обнаружении в DBPedia сущностей из Probase.
В итоге мы извлекли 10.5 милионов точных главных атрибутов для 1 миллиона концепций. Этого достаточно для старта исследований по пониманию таблиц. После корректного определения структурной схемы, таблица может использоваться для расширения анализируемого набора атрибутов, таким образом существенно расширяя базу Probase. В процессе изучения 30 концепций с 20 главными атрибутами у каждой, выяснилось, что значение точности оценок нашего алгоритма достигает в среднем 0.96. Такой высокий показатель формирует прочный фундамент для будущих исследований процесса «понимания.»
Из 0.3 миллардов веб-документов было извлечено 1.95 миллиардов HTML-таблиц. Многие таблицы вообще не содержали ценной информации (некоторые таблицы, например, были использованы при т.н. «табличной вёрстке»), некоторые имели очень запутанную структуру, слишком сложную для понимания машиной. Мы отфильтровали таблицы по определённым правилам и получили 65.5 миллионов таблиц (3.4% от всей выборки), которые содержали потенциально полезную информацию.
В данном разделе мы математически описываем процесс понимания таблицы. При помощи расширенной базы Probase проводится идентификация сущностей (принадлежащих отдельным концепциям/классам), атрибутов и их значений в таблице. После верной идентификации распознанная информация подключается в Probase для дальнейшего расширения.
Прежде всего, необходимо подробно разобраться в работе функций kA(A) и kE(E), которые включены в API Probase (Application Programming Interface, комплекс внешних методов для работы со сложной системой). В Probase содержится огромное количество информации о концепциях, сущностях и их атрибутах. Для любой концепции можно провести поиск по Probase и получить соответствующий экземпляр сущности и его характеристики. Аналогично, для любого набора сущностей или атрибутов можно найти в Probase все соответствующие им концепции. Этим целям и служат функции kA(A) и kE(E). При данном наборе атрибутов A и наборе сущностей E, функции kA(A) и kE(E) применяются для поиска максимально релевантной концепции, которая включает в себя A или E.
– Функция kA(A): для набора атрибутов A возвращает список триад (ci, Ai, sai), упорядоченных по рангу sai, где ci – возможная концепция A, Ai ⊆ A – атрибуты концепции ci, а sai – оценка, отражающая точность принадлежности A к ci.
– kE(E): для набора сущностей E возвращает список триад (ci, Ei, sei), упорядоченных по рангу sei, где ci – возможная концепция E, Ei ⊆ E – сущности концепции ci, а sei – оценка, отражающая точность принадлежности E к ci.
| Имя | Дата рождения | Политическая партия | Начало политической деятельности | Рост |
| Владимир Жириновский | 25.04.1946 | ЛДПР | 1990 | 175 см |
| Николай Губенко | 17.08.1941 | КПРФ | 1989 | 175 см |
| Дмитрий Медведев | 14.09.1965 | Единая Россия | 1990 | 162 см |
Таблица 3. Пример таблицы для понимания алгоритмом.
Эта пара функций может помочь в определении структуры таблицы. Возьмём таблицу 3 в качестве примера. Предположим, что нам необходимо узнать, является ли первая строка заголовком таблицы. Как известно, в заголовке обычно содержится ряд атрибутов концепции. Применяя kA(A) на A = {Имя, Дата рождения, Политическая партия, Начало политической деятельности, Рост}, можно заренее ожидать выдачи определённых концепций с высокой точностью. Probase показывает следующие результаты для kA(A):
(Президенты РФ, {Дата рождения, Политическая партия, Начало политической деятельности}, 0.90)
(Политики, {Дата рождения, Политическая партия, Начало политической деятельности}, 0.88)
(Футболисты, {Дата рождения, Рост}, 0.65)
В выдаче президенты РФ ранжируется выше, чем политики. Это вполне допустимо, так как мы исследуем только заголовок и не изучили само содержание таблицы.
С другой стороны, если рассчитать kA(A) по третьей строке A = {Дмитрий Медведев, 14.09.1965, Единая Россия, 1990, 162 см}, можн получить нулевые результаты или результаты, имеющие низкую точность. Это показывает, что kA() полезна при работе именно с заголовками таблиц.
Однако у множества таблиц просто отсутствует заголовок. В таком случае в игру вступает функция kE(). Возьмём первый столбец E = {Имя, Владимир Жириновский, Николай Губенко, Дмитрий Медведев}. Применяя kE() на E, результаты будут следующими:
(Политики, {Владимир Жириновский, Николай Губенко, Дмитрий Медведев}, 0.95)
(Актёры, {Николай Губенко}, 0.5)
В данном случае, kE() считает наиболее релевантным результатом концепцию политиков. Применяя kE() на прочие столбцы, можно получить ещё несколько возможных атрибутов. Действую подобным образом, можно сгенерировать заголовок таблицы.
Подводя итог, можно скомбинировать результаты kA() и kE() и понять смысл самой таблицы. Оценки sai и sei, выданные kA() и kE() играют важную роль в формировании окончательного вывода. Важно знать, как именно рассчитываются sai и sei. Логично предположить, что чем больше подходящих атрибутов/сущностей мы найдём, тем выше должна быть конечная оценка. Предполагая, что (ci, Ei, sei) является результатом kE(E) и (ci, Ai, sai) – результат kA(A), самым простым и очевидным способом определения будет расчёт по формуле 2:
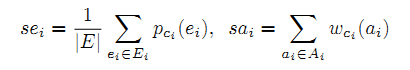
, где pci(ei) – значение правдоподобности ei данного ci и wci(ai) – оценка точности того, что ai является атрибутом ci в Probase.
Первым шагом к пониманию таблицы является локализация заголовка. В заголовке содержится ряд атрибутов, которые определяют структуру таблицы. Так же заголовок указывает на ориентацию таблицы своим расположением – либо он записан в столбце, либо в строке. В нашей работе предполагается, что все таблицы горизонтальные, к примеру, в таблице 3 заголовком является строка #1.
Пусть P – ряд возможных заголовоков таблицы T. В одном случае, можно рассматривать все строки таблицы T, т.е. предположить, что P одновременно включает все строки таблицы T. В другом случае анализировать только первую строку, которая в большинстве случаев является заголовком T. Нами применяется функция kA() для оценки всех вероятностей и генерируется несколько структурных схем-кандидатов. Формула 3:
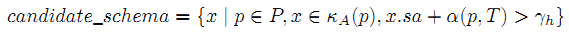
Формула 3 отфильтровывает кандидатов, оценка которых ниже установленного минимума γh. Итоговая оценка состоит из двух частей: начальная оценка sa, полученная из kA() и коэффициент поправки α(p, T), который оценивает вероятность того, что строка по своему синтаксису является заголовком. Использование коэффициента продиктовано опытом: заголовок таблицы обычно включает в себя определённые синтаксические особенности, которые позволяют выделить его среди прочих данных в таблице. Наример:
– в HTML используется тэг <th>
– характерные синтаксические признаки, например а) наличие двоеточий, б) специфическое форматирование (например, выделение слов жирным), отличающееся от прочих данных в таблице T
– различия типов данных: наличие в ячейке иного типа данных по сравнению с другими может являться индикатором заголовка. Например, одна из ячеек хранит в себе текстовые данные (англ. String, строковые данные) например, «Дата рождения» или «Возраст», а прочие ячейки в столбце – даты (04.08.1961) или числа (60)
Если формула 3 возвращает нулевой результат, то заголовок не определён. Такой результат вполне допустим, так как некоторые таблицы действительно не имеют заголовка.
На примере таблицы 3 правильно заданный минимум оценки позволит понять, является ли первая строка заголовком. Упрощая, предположим, что α(p, T) = 0, т.е. в таблице нет никаких синтаксических особенностей, облегчающих идентификацию заголовка.
(Президенты РФ, {Дата рождения, Политическая партия, Начало политической деятельности}, 0.90)
(Политики, {Дата рождения, Политическая партия, Начало политической деятельности}, 0.88)
В разделе «Детектор сущностей» мы подробно рассмотрим способ фильтрации таких результатов.
Если возможные заголовки не найдены в фазе детекции кандидатов, тогда алгоритм предполагает, что таблица не имеет заголовка. В таком случае алгоритм пытаемся сгенерировать заголовок самостоятельно на основе данных таблицы.
Для каждого столбца Li проводится поиск наиболее точно подходящей концепции. Например, из третьего столбца таблицы 3 можно выделить сущность «политические партии». Затем мы проверим, описывают ли концепции всех столбцов вместе какие-либо другие концепции. Чтобы это узнать, для каждого столбца Li проводится поиск наилучшего результата среди k топовых концепций, вызывая функцию kE(Li). Мы определяем k топовых концепций-комбинаций Li как c1(Li),…,ck(Li). Далее мы генерируем ряд возможных заголовков P путём отбора одной концепции по каждому кандидату в топе k вариантов:
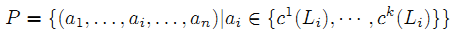
где n – число столбцов. Затем мы определяем candidate_schba, используя P и формулу 3. Напоминаем, что в данном случае α(p, T) равен нулю, как будто в таблице отсутствуют синтаксические особенности.
Если candidate_schba опять возвращает нулевой результат, т.е. отсутствие заголовка, и алгоритм не может его создать, то мы исключаем таблицу из анализа, оставляя её на будущее для дальнейшего изчения.
Перед детектором сущностей поставлено две задачи. Во-первых, он должен точно указать столбец сущностей в таблице. К примеру, в таблице 3 столбцом сущностей является первый, а не третий, так как таблица описывает политиков, а не политические партии (в данном случае, партия – атрибут политика). Во-вторых, если существует несколько схем-кандидатов, необходимо только отфильтровать неподходящие варианты для правильной интерпретации. Описанный ниже метод решает обе задачи одновременно.
Окончательное решение принимается по двум критериям. Критерий #1: столбец сущностей обязан включать сущности, принадлежащие одной и той же концепции, что позволит однозначно определить концепцию данного столбца. Критерий #2: в заголовке должны быть именно те атрибуты, которые сопутствуют сущностям в столбце сущностей, чтобы вариант структурной схемы совпал с полученной концепцией сущности.
В каждом варианте схемы s ∈ candidate_schba, полученного из формулы 3, мы нумеруем каждый столбец col и рассчитываем оценку уверенности (степени точности выбранной концепции). В каждом данном столбце col мы определяем:
– Ecol: все ячейки в col, кроме ячейки в заголовке, соответствующей s
– Acol: все атрибуты в s, кроме данного в этом столбце
Далее мы применяем функции kA() и kE() на Ecol и Acol для получения их возможной семантики. Пусть SCA – упорядоченный список (ci, Aicol, sai), созданный kA(Acol), а SCE – упорядоченный список (ci, Eicol, sei), выданный kA(Ecol).
Если col является стобцом сущностей, то мы сможем получить концепцию c из Ecol, при этом c должна твёрдо поддерживаться Acol. Таким образом, утверждение col в качестве столбца сущностей опирается на оценки точности нескольких концепций, полученных из самого столбца.
Мы комбинируем SCA и SCE для поиска общих концепций и рассчитываем произведение sai и sei для получения итоговой оценки точности.
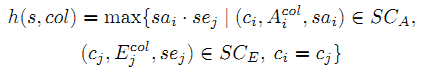
Максимальную оценку получают столбец сущностей и наиболее вероятная интерпретация.
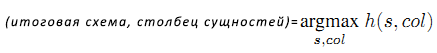
Используя этот подход для таблицы 3, алгоритм отклонит схему президентов РФ, так как несмотря на то, что такая концепция частично подтверждается атрибутами сущностей, столбец с актёром Николаем Губенко не поддерживает этот вариант. Таким образом, окончательная интерпретация схемы таблицы будет таковой:
(Политики, {Дата рождения, Политическая партия, Начало политической деятельности}, 0.88)
Так как мы занимаемся именно поиском концепций, было решено выбрать случайным образом 30 случайных распространённых концепций, различных по объёму и тематике. В экспериментах с участием проверяющих экспертов-людей, мы утвердили следующие правила оценки: 1 выставляется при полном совпадении, 0.5 – концепция лишь частично верна, 0 – полное несоответствие.
Нами использоваласть система-прототип с платформой распределённых вычислений Map-Reduce. Так как все нижеописанные этапы могут проводиться независимо друг от друга, параллельный расчёт каждого по отдельности в крупном кластере занимал всего несколько часов. После этого результаты были отправлены экспертам проверки точности.
1. Определение заголовка. Случайным образом были выбраны 200 таблиц, которые отправили на анализ алгоритму детекции заголовка. Результат был следующим:
| Нет заголовка: | 86.7% верно, 13.3% неверно |
| Есть заголовок: | 90.7% верно, 9.3% неверно (2.1% неправильное расположение, 7.1% определяется как обычная строка) |
Наш алгоритм верно определил заголовок (или его отсутствие) в 89.5% таблиц. Из 140 таблиц с заголовком, алгоритм верно определил его наличие в 127 (90.7%) таблицах.
2. Детекция столбца сущностей. Так как информация в веб-таблицах весьма разнообразна, случайный выбор таблиц для анализа из всей Сети не охватил бы все возможные структурные схемы и тематики. Поэтому мы создали тестовую выборку, используя таблицы с ресурса Википедии. Эти таблицы содержат структурированные данные совершенно разной тематики в силу природы самой Википадии. В этом эксперименте мы уделяем больше внимания точности, а не полноте оценок, так как работа с последней намного сложнее. Мы случайным образом выбрали 200 таблиц, которые содержали столбец сущностей по нашему мнению. При этом все таблицы брались с разных страниц. По окончании анализа эксперты выставили алгоритму оценку. Результаты показали, что 11 таблиц на самом деле не содержат столбец сущностей, и зачастую описывают две и более сущностей, что диссонирует с нашим предположением о наличии единственного столбца сущностей в таблице. Среди оставшихся 189 таблиц наш алгоритм корректно идентифицировал столбец сущностей в 165 случаях (87.3% от всех таблиц).
В рамках эксперимента мы разработали поисковую систему, которая работает с фразами таблицы, а не с самой таблицей. Под фразой (далее – фраза таблицы, табличная фраза) мы подразумеваем экземпляр сущности, его атрибуты и их значения. Обычно одна фраза соответствует одной строке в таблице. К примеру, таблица 3 имеет три фразы, каждая из которых описывает политика. В пределах сущности фраза является информационной единицей, которая отвечает на определённый вопрос. Разбивка таблиц на фразы является ключевым отличием от предыдущих работ [9], в которых минимальной информационной единицей считается таблица целиком, и поэтому выдаётся без изменений как ответ на поисковый запрос.
Более того, вместо грубого поиска совпадающих ключевых слов в таблице мы определяем семантику запроса и выдаём пользователю ряд табличных фраз по данной конкретной семантике. В поисковом запросе может наличествовать четыре семантических компонента: Концепция, Сущность, Атрибут и Ключевое Слово. Комбинации этих компонентов формируют различные типы поисковых запросов. В нашем эксперименте мы концентрируемся на распространённом паттерне Концепция + Атрибут, так как он включает себя два главных фактора: во-первых, связь между сущностью и концепцией, а во-вторых, связь между концепцией и атрибутом. Паттерн записывает в определённом виде, например «день рождения политика», «деятельность компании», «разработчик видеоигр». Если у нас есть несколько табличных фраз, отвечающих запросу, мы ранжируем их по двум факторам:
1) по совпадению ключевых слов и атрибутов запроса с фразой таблицы
2) по качеству табличной фразы
Чтобы не индексировать абсолютно все таблицы в Сети, встречаясь со сложными результатами работы по продвижению сайтов, наша поисковая система была разработана исключительно для краулинга по таблицам Википедии. Для каждой из 30 концепций мы выбрали 3 атрибута и сгенерировали соответственные запросы. Учитывая то, что нам было необходимо определённое число результатов по каждому запросу для адекватной оценки, мы попросили пользователей сперва подумать об атрибутах, которые они хотят найти, а потом выбрать максимум три характеристики с достаточным объёмом выдачи.
Для оценки точности и качества ранжирования, пользователи оценили каждый результат в первой десятке выдачи по каждому запросу. Пусть scorek обозначает оценку результата на позиции k среди n результатов. Тогда общее качество выдачи определяется как:
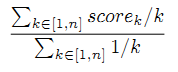
На 82 из 90 запросов было получено достаточно результатов. Среди них по 53 запросам все результаты в поисковой выдаче были верными, а 6 запросов имели оценку меньше 0.6. Средний балл по всем запросам составил 0.91. На рисунке 3 показаны средние оценки по запросам для каждой концепции. Из 29 концепций 25 получили оценку выше 0.8.
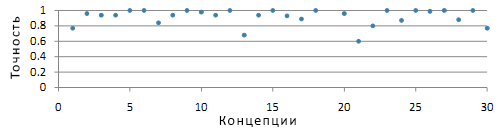
Рисунок 3. Средний балл запросов каждой концепции.
Для сравнения с реальными поисковыми системами мы направили все экспериментальные запросы в Google. По каждому запросу вручную оценивался топ-10 результатов и проводилась проверка, содержат ли результаты требуемую информацию о запрошенной паре Концепция + Атрибут в виде форм, списков или категорий. Из 820 результатов (10 по каждому запросу) 32 являлись ссылкой на Википедию, а 81 результат с не-вики сайтов был сочтён полезным. Однако полученные страниц имели весьма хаотичное форматирование, критически неприспособленное для выдачи нужной информации. Этот эксперимент показал, что использование классического поиска по ключевым словам не подходит в случаях с запросами подобной семантики.
Чтобы лучше оценить качество сущностей и значений их атрибутов мы сравнили наши результаты с технологией Google Squared, который ещё работал во время проведения эксперимента (Google Squared был закрыт 5 сентября 2011). Google Squared собирал информацию по введённому запросу и выдавал структурированные данные таблично виде. Разработанная нами поисковая система подбирает табличные фразы с одинаковой структурной схемой и выдаёт их в виде единой таблицы. Мы выбрали 10 наиболее высоко ранжированых схем по соответсвенным табличным фразам. По каждому запросу был подготовлен список сущностей и значений их атрибутов, и затем он сравнивался с результатами поисковой выдачи Google Squared. Мы вручную проверяли точность наших результатов и убедились в правильности полученных сущностей и значений их атрибутов. Рисунок 4 показывает процентное распределение наших результатов по всем 30 концепциям в сравнении с выдачей Google Squared. График наглядно иллюстрирует, какие части наших результатов были полностью включены в выдачу Google Squared, частично пересекались с ней или полностью расходились. При этом мы утверждаем, что наша система не только выдаёт верную информацию как Google Squared, но ещё и имеет более полную выдачу из-за отображения дополнительных характеристик и их значений, которых в Google Squared нет.
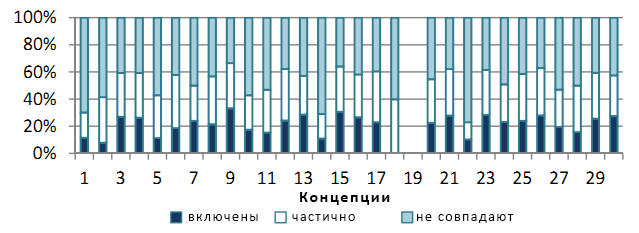
Рисунок 4. Сравнение с выдачей Google Squared.
В данном эксперименте мы оцениваем по числу сущностей и атрибутов потенциал нашего прототипа по расширению системы Probase.
1. Добавление сущностей. Расширение базы сущностей является самым простым процессом. Например, в соответствии с Probase, можно считать, что крайний левый столбец в таблице 3 содержит имена политиков, даже если не все имена были найдены в базе Probase. Крайний левый столбец аналогичен утверждению по паттерну Hearst: «…такие политики как Владимир Жириновский, Николай Губенко и Дмитрий Медведев…». Следовательно, можно дополнять Probase новыми данными по аналогии с обычной работой паттерна Hearst.
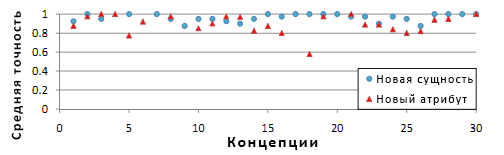
Чтобы убедиться в высоком качестве работы алгоритма, была выбрана 1000 топовых сущностей, считающихся главными в данной концепции c. Сущности каждой концепции c были ранжированы по значению двусмысленности ac(e), а затем окончательно переранжированы по значению правдоподобности pc(e). В данном случае δp имела значение 0.6. Алгоритм выполнил единственную итерацию и обнаружил 3.4 млн существующих сущностей в Probase. Намного важнее то, что при этом алгоритм обнаружил 4.6 млн новых сущностей для 20,000 концепций. Среди 30 концепций, для 28 было найдено 11,000 новых сущностей, 1,410 (12.8%) которых точни совпали с содержащимися в Freebase. Как и прежде, по каждой концепции мы вручную оценили топ-20 новых сущностей, которые были упорядочены по максимальному значению pc и затем рассчитали среднюю аримфметическую оценку для отображения качества концепции.
Результаты показаны кружками на рисунке 5. Среднее значение качества составило 0.96, все концепции имеют оценку, превышающую 0.875. В 12 концепциях абсолютно все сущности были определены верно. В целом, большинство новых сущностей было определно корректно.
2. Добавление атрибутов. После верной идентификации столбца сущностей можно расширить список атрибутов в базе Probase путём добавления неизвестных атрибутов в соответствующие концепции, описывающие столбец сущностей. Это поможет охватить большее число возможных атрибутов в таблицах, например, приравнивая атрибуты «тел-#» и «номер телефона». Кроме того, цикличное обогащая базу Probase путём добавления атрибутов не просто повышает качество понимания таблиц, ещё и рекурсивно развивает последующий анализ.
Мы запустили алгоритм ещё раз (как и в прошлый раз, на одну итерацию) и он обнаружил 0.15 млн новых атрибутов для 14,000 концепций. Около 2,700 новых атрибутов были обнаружены для всех 30 концепций. Как и прежде, мы были заинтересованы именно в качестве топовых атрибутов, а не в общем качестве выдачи. Для каждой концепции новые атрибуты были отфильтрованы по частотности и среднему wc(a), а затем упорядочены по максимальному значению wc(a). Мы снова вручную оценили топ-20 атрибутов и использовали среднее арифметическое для оценки концепции. В данном случае δa = 0.4
Результаты показаны треугольниками на рисунке 5. Нами были найдены новые атрибуты для 25 концепций и в среднем их качество составило 0.90. Единственной исключённой концепцией была «гитаристы» с оценкой качества 0.58. Это исключение имело место по причине того, что «гитаристы» очень часто связаны с «песнями» в таблицах. Однако так как охват песен в базе Probase невелик, вместо столбца сущностей песен выбирались гитаристы, что, очевидно, является не самым лучшим выбором.
Рисунок 5. Точность соответствия концепции обнаруженных новых сущностей и атрибутов.
До нашей работы по извлечению информации из таблиц в Сети проводилось ещё несколько исследований. Wang et al. [10] исследовал распознавание таблиц через методику машинного обучения, в которой учитываются особенности вёрстки, типы данных и использование слов. Эти характеристики использовались для обучения и тестирования различных классификаторов. Однако экспериментальный корпус включал в себя всего 10,000 таблиц с 200 сайтов. Yoshida et al. [11] изучал задачу интеграции таблиц с похожим контентом в одну большую сводную таблицу. Он использовал алгоритм EM (Expectation Maximization, [25]) для локализации атрибутов и значений в таблице путём распознавания её формата по предопределённой структуре, чтобы затем сгруппировать таблицы по атрибутам в несколько кластеров. Схожие атрибуты в одном кластере объединялись с целью создания одной большой таблицы. Другая ранняя работа [12] была направлена на дата-майнинг веб-таблиц исключительно по тематике «путешествия». Сначала распознавалось сходство ячеек, строк и столбцов, а затем идентификации структуры таблицы.
Cafarella et al. [13, 9] представили уникальную инновационную технологию по изучению таблиц в Сети. Их целью было определение типа данных в таблице: содержит ли она относительные другим данные. Алгоритм идентифицировал типизированные столбцы в таблице, создавая структуру для других таблиц, которые по его оценке содержали аналогичную информацию. Что интересно, Cafarella et al. нашли необычное применение анализатору таблиц – использовали его для поиска по корпусу таблиц. Совсем недавно появилась аналогичная система под названием Octopus [14], которая специализируется на поиске семантических совпадений в таблицах и при этом обладает высокой точностью и скоростью вычислений. Разработка в этой направлении опиралась на статистику корреляции данных между таблицами, а не использовала внешнюю базу, как мы работали с Probase. Кроме того, каждая таблица в их работе считалась отдельной сущностью (т.е., таблица являлась единицей информации в поисковой выдаче), в то время как мы считаем таблицу контейнером нескольких сущностей и значений их атрибутов. Syed et al [15] использовал Wikitology (гибридную базу как структурированных, так и неструктурированных данных из Википедии и других источников) – онтологию, объединяющую базы знаний DBPedia [16] и Freebase [6] для назначения ячеек таблицы релевантным информационным сущностям в Википедии. Для избежания двусмысленностей (ячейка может относиться к нескольким сущностям Википедии), концепция или тематика столбца (или строки) назначалась ячейке через «голосование большинством», таким образом обеспечивая максимальную точность совпадения. Прочие исследователи занимались маркировкой текста ячейки, типа стобца и отношениями столбцов (или строк) друг к другу [17, 18], работая с крупным корпусом данных (таким как YAGO). Однако, как мы упоминали в начале работы, человеку требуется не только определённый багаж знаний, но ещё и здравый смысл вкупе со знанием общеизвестных фактов для полноценного понимания таблицы, в особенности, если таблица изъята из контекста. Без этих ресурсов зачастую невозможно по-настоящему понять таблицу или провести семантический поиск, как описывается в нашей работе.
Представленное нами исследование сосредоточено на проблеме понимания таблиц в Интернете. Мы получаем необходимые алгоритму-анализатору ресурсы из расширенной базы данных Probase [1] – крупномаштабной онтологии, моделирующей концептуальную базу аналогичную человеческому сознанию. Расширенная Probase используется для поиска атрибутов каждой концепции, число которых в базе уже превышает 2 млн. Некоторые из работ так же концентрировались на поиске атрибутов: Pasca et al. [19] выбирал атрибуты класса начиная с нескольких пар зёрен (сущность + атрибут) для каждого класса. Кроме того, был разработан механизм ранжирования [20] для оценки атрибутов, полученных с помощью таких пар.
Кроме исследования таблиц, некоторые работы уделяют внимание иным источникам структурированных данных в Сети. Например, проводилось изучение эффективного использования информации, извлечённой из списков для создания относительных данных [21] или расширения набора сущностей [22]. Так же существует исследование по конвертированию текста в таблицы [23, 24]. Pyreddy et al. [23] использовал эвристические правила для разметки компонентов таблицы, а Pinto et al. [24] применял метод статистического моделирования CRF (Conditional Random Fields, используется для распознавания паттернов при машинном обучении) для обнаружения границ, заголовков и строк таблицы с текстом.
В работе наглядно показана работа мощного фреймворка по сбору ценных данных из крупномасштабного корпуса информации – HTML-таблиц в Интернете. Используя многоступенчатый алгоритм и универсальную вероятностную онтологию Probase наш фреймворк способен распознавать сущности, атрибуты и их значения во многих таблицах Всемирной Паутины. В ходе нашего исследования так же были разивались два интересных направления: во-первых, была разработана поисковая система по семантике таблиц, которая выдаёт релевантные таблицы по ключевым запросам, а во-вторых, был получен уникальный инструмент для дальнейшего расширения и развития онтологии Probase. Результаты экспериментов показали высокую скорость работы алгоритма по обоим направлениям, что доказывает практическую полезность нашего фреймворка в вопросах обнаружения данных и семантического поиска.
Материал «Understanding Tables on the Web» перевел и адаптировал Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации