SEO-Константа
Яндекс.Директ + оптимизация
Эффективная защита поисковой выдачи от спама является основной проблемой современных поисковых систем. В данной статье рассматриваются способы борьбы со спамом ссылочного типа, который занимает главенствующее положение в Сети. Большинство ранних исследований по противодействию ссылочному спаму концентрировались на использовании данных Сети для вычисления спама и не принимали во внимание то, что спамовые ссылки могут быть определены посредством мгновенных снимков (SnapShot) состояния ссылочного веб-графа. Для того, чтобы отследить подобные кардинальные изменения ссылок, в статье предлагается использование помимо обычных данных ещё и временную информацию о ссылках для определения ссылочного спама. Определятся такие временные свойства как Скорость Накопления Входящих Ссылок (In-link Growth Rate, IGR) и Скорость Отмирания Входящих Ссылок (In-link Death Rate, IDR) в модели классификации спама (IVM). Результаты экспериментов с данными графа Сетевых доменов показывают, что изложенный метод может успешно применяться для детекции спама.
Использование людьми поисковых систем для нахождения нужной информации приобрело значительную важность за последнее время. В процессе поиска пользователи обычно открывают только высокоранжированные ссылки в поисковой выдаче. То есть, у страницы намного больше шансов получить посетителя из поисковой системы, если она высоко оценена поисковиком. По этой причине многие владельцы веб-сайтов стараются манипулировать информацией в Сети с целью повышения посещаемости своих страниц в коммерческих или личных целях. Манипулирование поисковой выдачей в общем случае называется Сетевым спамом.
Для поисковой системы эффективное определение и исключение поискового спама из выдачи становится критически важным аспектом работы. В сообществе учёных вопрос детекции спама официально классифицирован как научная тема для исследований и разработано несколько методов борьбы со спамом [1], [2], [3], [4], [5], [7], [8], [9], [12], [13].
Борьба со спамом является сложной задачей, так как развитие анти-спамовых технологий ведётся только на основе известных методов спама, а методики спама развиваются непрерывно и независимо. Несмотря на определённый прогресс в прошлых анти-спамовых исследованиях, остаются неразрешёнными ещё много вопросов. В частности, крайне необходим анти-спамовый алгоритм, который мог бы реагировать на различные методики спама и определять неизвестные или потенциальные алгоритмы спамминга.
В этой статье мы фокусируемся на противодействии ссылочному спаму. Современные поисковые системы ранжируют веб-страницы с учётом числа ссылок, связанных с этими страницами. Обычно, веб-страница, на которую ведёт много ссылок (называемых входящими ссылками), ранжируется выше в поисковой выдаче. Как следствие, продвижение сайтов пытается манипулировать ссылочной массой в сети, стараясь увеличить число входящих ссылок на нужную им страницу до тысяч и даже миллионов – такая методика поддержки страницы и является ссылочным спамом. В прошлых работах по борьбе со ссылочным спамом использовался один снимок состояния веб-графа, из данных которого извлекались свойства и определялись спамовые сайты.
Нами предлагается использование временной информации для детекции ссылочного спама. В частности, мы используем несколько снимков состояния веб-графа за определённый промежуток времени, извлекая временные свойства наряду с обычной информацией о ссылках, после чего конструируем для задачи классификатор SVM (Support Vector Machines, Машина Опорных Векторов). Среди извлечённых свойств фигурируют Скорость Накопления Входящих Ссылок (IGR) и Скорость Отмирания Входящих Ссылок (IDR).
Смысл нашего подхода заключается в том, что обычные страницы и спамовые страницы по-разному развиваются с течением времени, т.е. характеризуются различными паттернами эволюции веб-страниц. К примеру, ссылочный спам зачастую кардинально меняет свою направленность на спамовые сайты за короткое время. Вне зависимости от используемой спамерской технологии, этот паттерн получает отражение в ходе изменения веб-графа. Таким образом, наш метод детекции получает преимущество по выявлению спамовой массы. Как будет показано ниже, эксперименты на реальном веб-графе доказали эффективность нашего подхода.
Мы выбрали два снимка графа веб-сайтов, датированных февралём 2006 и мартом 2006. Граф веб-сайтов – это граф, в котором сам сайт является узлом графа, а гиперссылки между двумя веб-сайтами формируют рёбра. Мы использовали два выбранных графа на протяжении всей работы.
Статистические данные о графах показаны в Таблице 1.
| 2006-02 | 2006-03 | Изменения | |
| Среднее вхождение | 17.2865 | 17.2456 | 0.0409 |
| # вебсайтов | 41,464,052 | 41,062,569 | 401,483 |
Таблица 1. Статистика двух графов веб-сайтов.
| # исчезнувших сайтов | 4,753,588 |
| # созданных сайтов | 4,352,150 |
Таблица 2. Различия между двумя графами веб-сайтов.
Из Таблицы 1 видно, что общее число узлов обоих графов отличается незначительно. Однако из Таблицы 2 видно, что различия в содержании графа весьма масштабны. Частично причиной этой разности является наша стратегия краулинга, но частично причиной служит и тот факт, что множество веб-сайтов постоянно обновляются. Это означает, что временная информация, содержащаяся в графах вебсайтов довольно обширна и может быть использована для детекции поискового спама.
Для проведения эксперимента, мы попросили нескольких добровольцев обработать ряд случайным образом выбранных сайтов и классифицировать их как спамовые сайты или нормальные. Результаты показаны в Таблице 3.
| Число | Доля | |
| Всего | 113,756 | 100% |
| Спам | 12,020 | 10,57% |
| Не спам | 101,736 | 89,43% |
Таблица 3. Статистика маркировки отобранных сайтов.
В нашей работе мы преобразуем проблему детекции ссылочного спама в проблему классификации. Каждый узел (вебсайт) графа берётся как экземпляр для обучения классификатора SVM, который, в свою очередь, внедряется в детектор спама (т.е. он определяет, является ли новый экземпляр сайта спамовым или нет). Классификатор SVM, в основном, пользуется временными свойствами.
Здесь возникает вопрос в определении, собственно, временных свойств. Нами предлагается три типа характеристик. Во-первых, для каждого узла мы определяем характеристики на основе временной статистики по узлу. Затем мы получаем характеристики для каждого узла на основании временной статистики его соседей. И, наконец, мы определяем свойства для каждого узла на основании корреляции среди его соседей.
Sin(a,t) – набор входящих ссылок на вебсайт a в момент времени t.
Sout(a,t) – набор исходящих ссылок с вебсайта a в момент времени t.
|Sin(a,t)| – число вебсайтов в Sin(a,t).
G(t) – веб-граф в момент времени t.
t0 – момент времени, когда краулер заканчивает анализ февральского графа.
t1 – момент времени, когда краулер заканчивает анализ мартовского графа.
Скорость Накопления Входящих Ссылок (IGR)
IGR сайта определяется как отношения увеличившегося числа входящих ссылок к первоначальному числу входящих ссылок (т.е. к числу входящих ссылок на вебсайт в февральском графе).
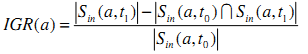
Главным трюком спамеров является получение входящих ссылок на определённые страницы. Таким образом, IGR является хорошим индикатором ссылочного спама. Для точного определения спама мы рассматриваем распределение IGR для всех веб-сайтов на рисунке 1.
Гистограмма на рисунке показывает распределение IGR для всех веб-сайтов в обоих графах. Кривая на рисунке отражает вероятность наличия спама, когда IGR находится в пределах от 0 до 5 (ось абсцисс). Левая вертикальная ордината соответствует гистограмме, а правая – кривой.
Из рисунка 1 видно, что значения IGR для большинства веб-сайтов находятся в пределе от 0 до 1, в котором вероятность спама крайне мала. Лишь небольшое число веб-сайтов имеют значение IGR в пределе от 1 до 5, в котором вероятность спама крайне высока. Из этого наблюдения очевидна корреляция между значением IGR и вероятностью наличия спама. Учитывая тот факт, что средняя вероятность спама в маркированных данных колеблется в пределах 10% (нижняя граница для детекции спама), можно считать, что IGR является адекватной характеристикой для детекции спама. С другой стороны, использование только этой величины недостаточно, так как будет иметь место высокий процент ложных срабатываний.
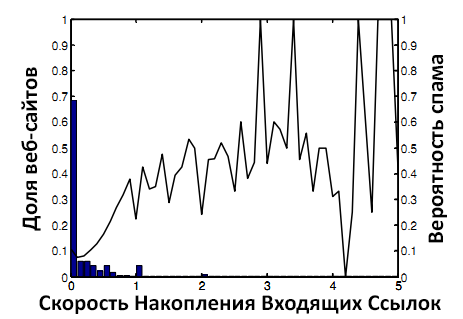
Рисунок 1. Вероятность спама и IGR.
Скорость Отмирания Входящих Ссылок (IDR)
IDR сайта определяется как отношение числа битых входящих ссылок к первоначальному числу входящих ссылок.
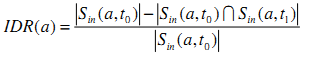
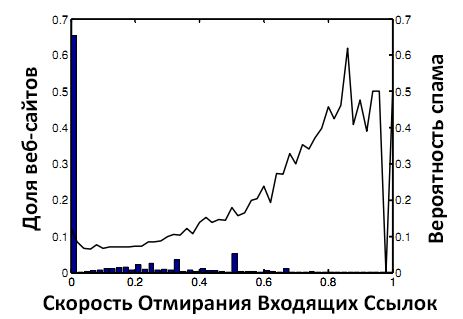
Рисунок 2. Вероятность спама и IDR.
Чтобы избежать детекции поисковой системой, спамеры могут часто изменять свои методики. Это повысит значение IDR конкретного веб-сайта по сравнению со значением IDR нормального сайта. На Рисунке 2 видно, что веб-сайты со значением IDR выше 0.4 с высокой вероятностью являются спамовыми.
Среднее IGR (IGRMean)
IGRMean веб-сайта определяется как среднее значение IGR веб-сайтов, которые на него ссылаются.
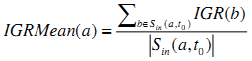
Одним из допущений алгоритма BadRank [4] является то, что плохие страницы имеют тенденцию ссылаться на такие же плохие страницы. Следуя этому допущению и считая, что IGR является адекватным индикатором спама, нами предлагается использование этой временной характеристики в детекции спама. Мы считаем, что веб-сайт скорее всего окажется спамовым, если сайты, которые на него ссылаются, имеют высокое значение IGR.
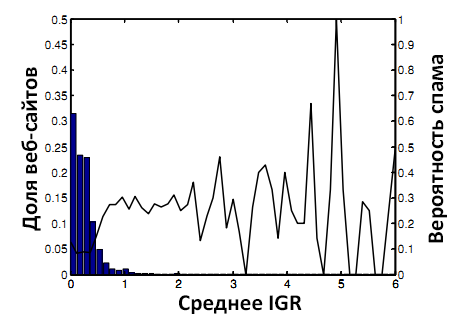
Рисунок 3. Вероятность спама и IGRMean.
Среднее IDR (IDRMean)
Схожим образом с IGRMean, IDRMean веб-сайта определяется как среднее значение IDR веб-сайтов, ссылающихся на данный веб-сайт.
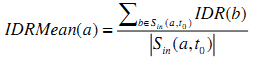
Цель использования данного свойства схожа с целью использования IGRMean. Мы построили распределение IDRMean на Рисунке 4. Сравнивая Рисунки 3 и 4, можно отметить, что IDRMean является ещё более точным индикатором спама, чем IGRMean.
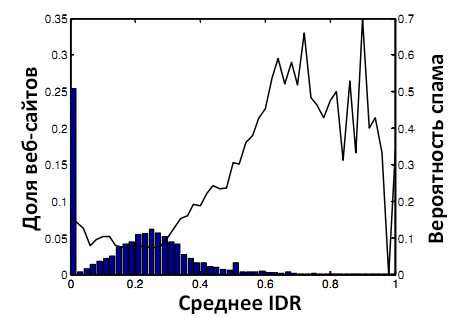
Рисунок 4. Вероятность спама и IDRMean.
Дисперсия IGR Входящих Ссылок (IGRVar)
Автономные спамовые сайты могут иметь соседей с похожими статистическими паттернами, которых нет у нормальных сайтов. С учётом этого факта, мы рассчитываем дисперсию значений IGR ссылающихся на узел сайтов с целью детекции спама.
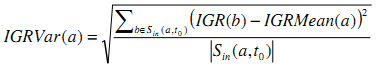
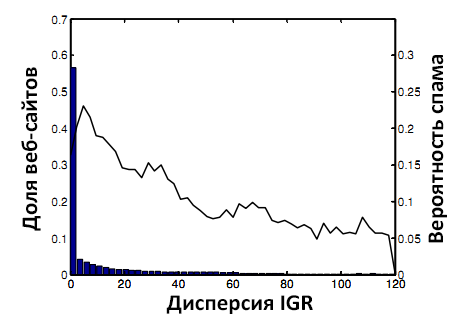
Рисунок 5. Вероятность спама и IGRVar.
Из кривой на Рисунке 5 видно, что большинство сайтов с высоким значением IGRVar являются нормальными сайтами и, как следствие, эта характеристика может быть использована для детекции спама.
Дисперсия IDR Входящих Ссылок (IDRVar)
IDRVar вебсайта – это дисперсия значений IDR веб-сайтов, ссылающихся на данный узел.
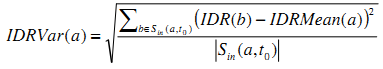
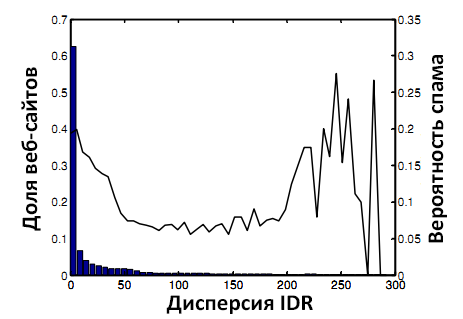
Рисунок 6. Вероятность спама и IDRVar.
Скорость Изменения Коэффициента Кластеризации (CRCC)
Watts и Strogatz [6] предложили использовать коэффициент кластеризации в качестве меры степени соединения соседей между собой в веб-графе. Мы немного изменили их определение для использования в рамках нашей задачи. Нам необходимо определить, насколько тесно связаны между собой входящие ссылки узла. Коэффициент кластеризации и скорость его изменения определяются следующим образом:
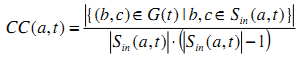
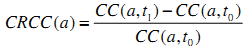
Рисунок 7. Вероятность спама и CRCC.
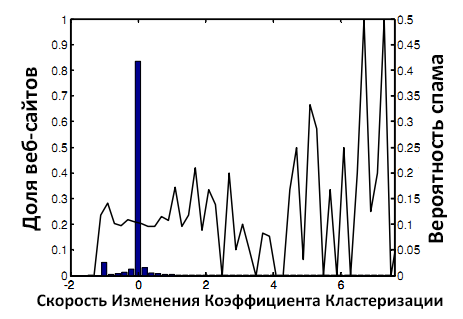
На Рисунке 7 видно, что CRCC является индикатором спамовых вебсайтов – более высокая скорость изменения коэффициента обычно соответствует более высокой вероятности наличия спама.
Все вышеописанные свойства относятся ко входящим ссылкам, но так же мы определяем и характеристики по отношению к исходящим ссылкам. В целом, у нас имеется 13 определённых временных характеристик.
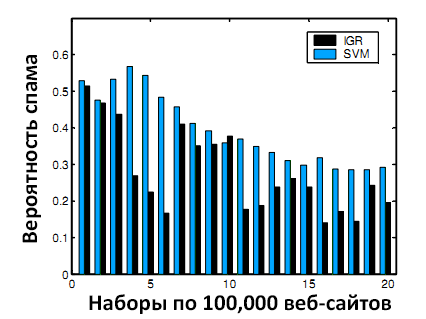
Мы разделили все вебсайты на выборку для обучения и тестовую выборку. Затем мы обучили модель SVM, используя инструментарий SVMlight [11] по маркированным данным в обучающей выборке и отправили её оценивать тестовую выборку. Далее мы разбили ранжированные моделью вебсайты в тестовой выборке на наборы, в каждом из которых содержалось 100,000 веб-сайтов. Каждый набор имел определённое количество маркированных данных и мы оценили точность детекции в этих наборах. Для сравнения мы так же классифицировали веб-сайты, используя только одну временную характеристику – IGR. На рисунке 8 показаны результаты для первых 20 наборов по 100,000 сайтов.
Из Рисунка 8 видно, что точность детекции спама при помощи SVM выше, чем при использовании IGR отдельно. Допуская, что нижней границей точности при детекции спама является 10% (т.е. 1 из 10 сайтов – спамовый), можно заключить, что производительность SVM весьма хороша – для большинства наборов точность оценки выше 40%, а в некоторых она доходит до 60%. Результаты доказывают, что использование временных характеристик в детекции поискового спама является допустимым.
Рисунок 8. Вероятность спама в первых 20 наборах.
Далее мы провели качественную оценку результатов. Мы проверили первые 10 сайтов, определённых SVM как спам и выяснили, что 8 из 10 действительно являлись спамовыми, включая 5 сайтов ссылочного спама, 2 сайта спамового комментирования и 1 сайта с двумя техниками сразу. Оставшиеся два сайта были из разряда подозрительных.
Так же мы проверили последние 10 спамовых сайтов, которые SVM не в состоянии определить. Мы обнаружили, что 4 сайта уже умерли, а на остальных не было обновлений в течение долгого времени. Это означает, что наш метод работает лучше для определения живых спамовых сайтов и хуже для сайтов без временных изменений. Для решения этой проблемы потребуются дополнительные методики выявления спама.
В данной статье мы предложили использование временных характеристик для детекции ссылочного спама. Мы дали определения этим характеристикам и использовали их в обучении SVM. Основной принцип нашей работы заключается в отслеживании кардинальных изменений в этих характеристиках. Результаты эксперимента показывают, что наше допущение корректно и предложенные свойства являются эффективными индикаторами спама.
В будущих исследованиях мы планируем интегрировать наш метод детекции спама в другие анти-спамовые техники для создания более мощного инструмента по борьбе со спамом. Мы так же планируем применить наш подход к графу веб-страниц, который намного более обширен по сравнению с графом веб-сайтов.
Перевод материала «Detecting Link Spam using Temporal Information» выполнил Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации