SEO-Константа
Яндекс.Директ + оптимизация
Продолжим рассмотрение алгоритма недоверия Anti-Trust Rank, исследуя те результаты, которые были получены в ходе экспериментов на наборе данных WebGraph [3] за 2002 год. Эта коллекция включала в себя 300 млн. ссылок и 18.5 млн. узлов, относящихся к доменной зоне .UK. Во избежании мануальной оценки выборки на наличие/отсутствие спама, которая, как было отмечено в [1], представляется достаточно трудоемкой операцией, мы решили использовать эвристику. Для этого мы составили список подстрок (например, виагра, казино, взрослая тематика), присутствие которых в URL-адресе свидетельствовало о высокой вероятности того, что тот или иной цифровой документ из имеющегося набора данных будет являться спамом. Согласно эвристике, из 18,520,486 страниц нашей выборки, в спамденсинге было уличено 0.28%, то есть 52,285 документа. Для формирования Seed Set мы отобрали 40 страниц, отсортированных по их Google PageRank из числа тех URL-адресов, которые были отнесены нашей эвристикой к спаму. Для сравнения с алгоритмом доверия Google TrustRank мы выбрали еще 40 страниц, отсортированных по значению их обратного PageRank из числа тех URL-адресов, которые были отнесены нашей эвристикой к НЕ-спаму. Каждая страница как из первого, так и второго списка была проверена в ручную. Мы также выяснили то, что увеличение размера Seed Set скажется на работу алгоритм недоверия Anti-Trust Rank достаточно благотворно. Наконец, мы использовали α = 0.85, то есть вероятность телепортации в нашем случае составляла 0.15.
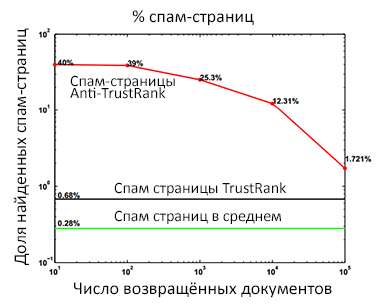
Рис. 51 Сравнение двух алгоритмов в обнаружении спам-документов
На рисунке 51 мы сравниваем точность работы Anti-TrustRank и Google TrustRank на разных уровнях полноты. Как вы можете видеть, несмотря на то, что оба алгоритма демонстрируют нам более высокий процент обнаруженных спам-страниц по сравнению с теми, которые нам удалось вычислить с помощью нашей эвристики (0.28%), Anti-TrustRank дает значительно лучшие результаты, чем TrustRank и это неудивительно, поскольку при распространении своего доверия к тем страницам, которые находятся в пределах его достижимости, Google TrustRank не располагает информацией о тех документах, которые находятся далеко от Seed Set. В принципе, схожая ситуация, но уже касающаяся ненадежности ресурсов, будет наблюдаться и по мере отдаления на более длинные дистанции недоверия Anti-TrustRank.
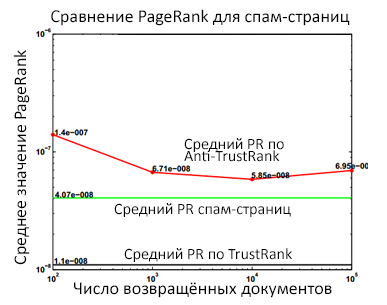
Рис. 52 Обнаруженные спам-документы с учетом их Google PR
Аналогично, глядя на рисунок 52, мы обнаруживаем, что в отличие от Anti-TrustRank, средний ранг спам документов, возвращенных TrustRank на разных уровнях полноты оказался меньшим, нежели чем усредненный ранг всех спам страниц. Далее, мы увеличиваем размер Seed Set с 40 страниц, до 80 и 120 соответственно (Рис. 53).
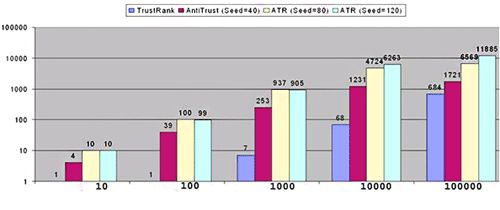
Рис. 53 Сравнение производительности алгоритмов для разного числа страниц в Seed Set
Ось X представляет собой количество документов, выбранных с учетом наибольшего значения недоверия и наименьшего показателя «траста». Ось Y показывает, сколько в действительности было обнаружено спама из числа предложенных нами страниц. С учетом присущей нашему алгоритму недоверия точности для разных уровней полноты, мы видим, что увеличение размера выборки приводит к большей производительности.
Прежде чем мы перейдем к рассмотрению следующих алгоритмов, давайте поговорим о возможностях машинного обучения в задачах выявления спама. Ранее мы уже имели удовольствие видеть результаты классификации страниц на предмет наличия непотистских (кумовских) ссылок, которая была выполнена с применением алгоритма построения дерева решений C 4.5. Схожую задачу классификации страниц можно решить с использованием машины опорных векторов (SVM, от англ. «Support Vector Machine»), и для наглядного доказательства высокой эффективности этой методологии мы решили привести вам в пример успешную попытку обнаружения поискового спама в блогах.
Поисковые системы относятся к сплогам (от англ. spamспам и blogблог) крайне негативно по той простой причине, что их применяют для сбора поискового трафика и продвижения аффилированных корпоративных веб-сайтов. В свою очередь, блоги являются богатым источником текстовой-, графической- и мультимедийной информации, а также представляют собой очень популярные средства массовой коммуникации. Наличие сплогов, не представляющих для пользователей поисковых машин какой-либо информационной ценности, ухудшает качество выдачи по блогосфере. Несмотря на то, что сплоги являются относительно новым явлением, их изучение идет достаточно активными темпами. Если возвращаться к разговору о методах обнаружения поискового спама, то они могут основываться либо на анализе ссылок, либо на исследовании содержимого цифровых документов. Общим примером контентного анализа может послужить работа [8], в которой авторы предлагают отличать поисковый спам от нормальных интернет-страниц посредством таких статистических особенностей содержимого, как количество слов, их средняя длина, частота терма в заголовках, анкоры ссылок, маркировка URL и пр. Конкретно противодействие спаму в блогах с использованием анализа содержимого было рассмотрено в [7], где страницы блогов рассматриваются по аналогии со стандартными HTML-документами. Как и в данном исследовании, в основе той работы лежит метод опорных векторов (SVM); авторы классифицируют наборы контентных и ссылочных особенностей страниц сплогов и сравнивают их классификацию для линейного ядра, радиальной базисной функции и сигмоида. В качестве классического примера ссылочного анализа можно привести работу [4], в которой для детекции поискового спама также используется пропагация доверия, то есть Google TrustRank. В [6] предложено вычислять поисковый спам посредством использования темпоральной (учитываем временные особенности) ссылочной информации, извлекаемой из двух статический срезов (снимков) состояния ссылочного веб-графа.
Вместе с тем блоги обладают рядом уникальных особенностей, являющихся следствием их коммуникативной природы, которую нам необходимо учитывать. Так, в отличие от более привычного нам поискового спама, где контент страниц является статичным, сплоги требуют постоянного обновления (блогинга) своего содержимого в целях сбора интернет-трафика, что зачастую решается посредством автоматической генерации контента (обычно он имеет коммерческую направленность) с применением соответствующего программного обеспечения. Вследствие этого, последовательность записей сплогов отличается такими поверяющимися паттернами, как идентичность периодов постинга и содержимого самих записей, цитирование аффилированных с ним веб-сайтов и т.д. Так как нормальные блоги, которые ведутся реальными людьми, не имеют вышеобозначенных паттернов, в дальнейшем мы будем использовать их в качестве индикаторов некачественных ресурсов. Понимая, что порочная практика генерации контента может повлечь за собою наложение штрафных санкций со стороны поисковых систем, сплоги также копируют информацию с нормальных блогов, в результате чего мы не можем строить свою работу только на исследовании их контентных особенностей. С позиции ссылочного анализа отметим, что пропагация доверия из [1,4] в нашем случае будет неэффективна в следствие того, что спамер имеет возможность создавать неограниченное количество ссылок, указывающих на его сплог. По причине темпоральной динамики блогов мы также не можем полагаться исключительно на срезы статичных состояний — механизмы создания контента и ссылок, которые используются в сплогах, существенно отличаются от классического поискового спама. Нам сложно анализировать изменения в поведении сплогов, которое в принципе не может быть описано некоторым набором снимков.
Однако ниже описывается инновационный подход к вычислению сплогов, который основан на том наблюдении, что блог является динамичной, всевозрастающей последовательностью записей (постов), а не просто набором отдельных HTML-страниц. В нашем подходе сплоги идентифицируются посредством их темпоральных и ссылочных характеристик, наблюдаемых в цепочке постов:
Предполагая, что сплоги могут быть вычислены за счет присущих им повторяющихся темпоральных и ссылочных паттернов, наблюдаемых в последовательности публикуемых записей (постов), мы разработали новые методы по их обнаружению, которые основываются на данных закономерностях. Также стоит сразу же заметить, что с учетом автоматической генерации не только содержимого (мы также не исключаем копирование информации с других блогов и/или сайтов), но и гиперссылок, вся ссылочная структура сплога нацелена на привлечение реального трафика на определенную группу аффилированных с ним веб-сайтов.
Особенности содержимого. Сейчас мы приступим к обсуждению особенностей содержимого, которые послужат нам в качестве базисного набора по причине своей широкой распространенности в задачах обнаружения спамденсинга. Для классификации блогов на нормальные, качественные ресурсы и, соответственно, сплоги, мы используем подмножество особенностей, приведенных в [8]. Для начала мы извлекаем характеристики из пяти отличных секций интернет-блога:
Теперь, для каждой категории мы извлекаем следующие признаки: количество слов (wc), среднюю длину слов (wl), а также вектор, описывающий взвешенное распределение частоты слов (wf). Для эффективности вычислений всякая категория содержимого анализируется нами по отдельности. Для того чтобы избежать чрезмерно близкой подгонки данных, нам необходимо уменьшить длину вектора wf, поскольку общее количество уникальных термов (включая слова, содержащие цифры) составляет более 100,000 (в том числе такие нетрадиционные обращения, как «Привеееед!»), что будет создавать для нас излишние помехи. Во-вторых, мы будем иметь распределение слов с длинным хвостом, то есть большинство из них используются крайне редко. В качестве метода обнаружения линейной комбинации признаков, наилучшим образом разделяющий классы, мы будем использовать линейный дискриминантный анализ Фишера (LDA). Здесь мы вычисляем оптимальное преобразование пространства признаков на основании критерия разделимости, минимизирующего внутриклассовое расстояние при одновременной максимизации межклассового. Мы будем использовать критерий разделимости J = tr(Sw-1Sb), где Sw обозначает матрицу рассеяния внутри классов, а Sb — матрица рассеяния между классами. Соответственно для него подбираются такие признаки, которые соответствуют максимальным собственным значениям матрицы (Sw-1Sb). Мы выбираем топ k собственных значений для определения ключевой величины вектора wf.
Особенности темпоральной регулярности. Темпоральная регулярность вмещает в себя подобие между контентом (регулярность содержимого) и временной последовательностью в публикации постов (структурная регулярность). Для оценки значения темпоральной регулярности содержимого (TRC) мы определяем обобщенную автокорреляцию по нечисловым данным (контенту записей в интернет-блоге). Здесь мы имеем временной ряд, то есть упорядоченную по времени последовательность значений множества случайных величин. В том случае, если существует зависимость последующих значений ряда от предыдущих, то для его прогнозирования мы используем автокорреляционную функцию (условно обозначим ее за R(k)). Интуитивно понятно, что данная функция представляет собой значения коэффициентов корреляции будущих значений временного ряда с его предыдущими значениями, и т.д. Поскольку основным мотивом для владельца сполга является продвижение сайтов и коммерция, мы предполагаем, что содержимое сплога с течением времени будет меняться несущественно. Те же блоги, которые ведутся реальными людьми, как правило, используют для постинга более разнообразный тематический набор, что даст нам низкий показатель автокорреляции (рис. 54).
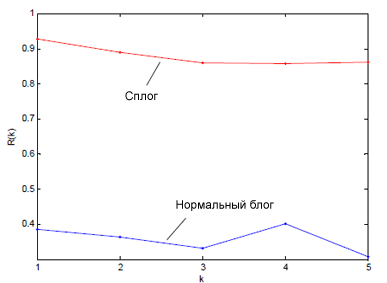
Рис. 54 Автокорреляционная функция сплога и нормального блога.
Сейчас мы приведем расчет обобщенной функции автокорреляции R(k) для дискретных данных с тем упрощением, что здесь мы не учитываем метаданные (если таковые имеются), указывающие на дату создания контента, всего лишь сравнивая сходство предыдущих записей с последующими. Определяем автокорреляционную функцию как:
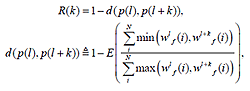
, где E — оператор математического ожидания, R(k) — ожидаемое значение автокорреляции между текущим I-ым и приращенным (I+k)-ым постом; d — мера различия в матрице расстояний, wlf(i) относится к I-ой размерности вектора wf I-го поста. Оценка темпоральной регулярности содержимого блога bi, обозначаемая как TCR(bi), получена через m-мерный вектор, то есть TCR(bi)=R(k) для k=1,2,…,m.
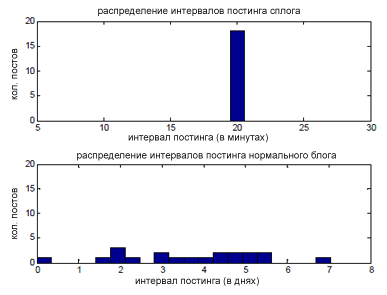
Рис. 55 Интервалы постинга сплога (каждые 20 минут) и нормального блога (от нескольких часов до недель)
Мы рассчитали темпоральную структурную регулярность (TSR) блога посредством вычисления энтропии распределения временной разницы (интервалов) постинга. Мы считаем, что сплог будет иметь низкую энтропию, являющейся следствием искусственно генерируемого контента (рис. 55). Для оценки распределения мы применили иерархическую кластеризацию, где в качестве алгоритма объединения различных значений интервалов постинга был выбран метод одиночной связи. Расстояние между двумя кластерами определяется посредством расстояния между двумя наиболее близкими соседями в каждом из них, а в качестве критерия остановки выступает минимальное изменение среднеквадратической ошибки. После того, как кластеры определены, мы подсчитываем энтропию кластеров, которая служит для нас оценкой темпоральной структурной регулярности всякого имеющегося блога bi:
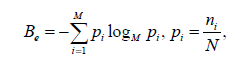
и TSR(bi)=1−Be/Bmax, где Be является энтропией блога bi, а Bmax — максимальная энтропия, наблюдаемая по всем блогам; N — общее количество записей (постов) в блоге; ni и pi— количество постов и вероятность i-ого кластера соответственно; M — количество кластеров. Важно отметить, что в случае отсутствия метаданных, указывающих на дату размещения постов, шаг по вычислению TSR пропускается.
Регулярность ссылочной структуры. Мы предполагаем, что ссылочная структура сплогов будет отличаться более последовательным поведением (все-таки их целью является привлечение трафика) и частой цитируемостью аффилированных с ними веб-сайтов, которые, заметим, не будут являться авторитетными ни с точки зрения поисковой системы, ни с позиции нормальных блоггеров. Анализ ссылочного поведения сплогов мы будем проводить с применением алгоритма HITS [5], а в качестве индикатора сплогов использовать нормализованный показатель концентрации (hub scores). Наш интуитивный подход основан здесь на том, что сплоги ссылаются на некоторый конкретный набор сайтов, в то время как целью нормального блога может служить более широкий спектр интернет-страниц (рис. 56).
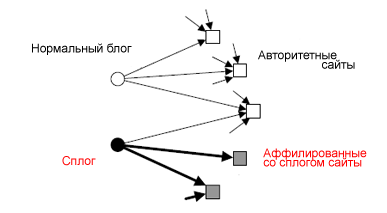
Рис. 56 Ссылочное окружение сплога (толщина стрелок указывает на частоту цитируемости неавторитетных сайтов) и нормального блога
В классическом алгоритме Джона Клейнберга (Jon Kleinberg) HITS всякий веб-сайт wi имеет как показатель концентрации hi, так и авторитетности ai. Дается веб-граф, состоящий из M интернет-сайтов, хорошие «хабы» и «авторити-ресрусы» отождествляются с графом блогов А, который, в свою очередь, является подграфом для веб-графа. Мы создаем матрицу смежности В ориентированного двудольного графа (то есть множество его вершин разбито на два непересекающихся подмножества, причем всякое ребро инцидентно вершине из обоих подмножеств), состоящего из N-блогов и M-сайтов, где Bij=1 говорит нам о наличие гиперссылки из блога bi на веб-сайт wj. Каждому блогу присваивается показатель концентрации, а каждому интернет-сайту значения авторитетности. Тогда, вектор h(b)=(h1,…,hN)T содержит значения концентрации блогов, а вектор a(w)=(a1,…,aM)T — значения авторитетности сайтов. Для оценки ссылочной регулярности (LR) мы вычисляем нормализованный показатель концентрации блогов: h(b) = B(out)a(w), a(w) = (B(out ))T h(b) и LR(bi)= hi(b), где B(out) является матрицей полустепеней исхода (мы их нормализуем), следующая из матрицы смежности как B(out)=D-1B, где D=diag((oi,…,oN)T), а oi=ΣjBij — полустепень исхода блога bi. Отметим, что нормализация полустепеней исхода вершин (то есть количество исходящих ребер) играет очень важную роль в оценке ссылочной регулярности, с помощью которой мы планируем отличать сплоги от нормальных блогов. Без нее, сплог, который имеет многочисленные гиперссылки, указывающие на аффилированные с ним веб-сайты, может легко повысить свой показатель концентрации за счет создания нескольких исходящих линков на авторитетные интернет-ресурсы. Для подавления данного эффекта мы нормализуем полустепень исхода таким образом, что с точки зрения вклада сторонних ресурсов в показатель концентрации блога, нам будут одинаково важна качественная составляющая каждого из них. Тогда, получение высокого показателя концентрации возможно лишь случае цитирования широкого спектра авторитетных веб-сайтов.
Для практических экспериментов использовались данные TREC (Text Retrieval Conference) за 2006 год, которые собирались в течение 77 дней и, после соответствующей обработки (удаление дубликатов и т.д.), содержали порядка 43.6 тыс различных блогов. Необходимым условием для включения исходного материала в нашу выборку было наличие у блога домашней страницы и минимум одной единственной записи (поста). На TREC мы вручную отметили 8 тыс. нормальных блогов и 800 сплогов. Для целей анализа было решено создать симметричный набор, состоящий из 800 сплогов и 800 блогов. Мы использовали классические методы машинного обучения (классификатор SVM с полиномиальным ядром, пакет LIBSVM [2]) для отнесения блогов к классу “сплог” или “нормальный блог”. Для оценки производительности нашего детектора, который сочетает в себе как TRC, TSR, LR, так и традиционные особенности содержимого, мы использовали 5-fold кросс-валидацию. Среди показателей качества нашей классификации были: площадь под кривой ошибок (AUC), аккуратность (accuracy), точность (precision) и полнота (recall). Результаты приведены в Табл. 18
| Особенности | AUC | Аккуратность | Точность | Полнота |
| база-256 | 0.951 | 0.873 | 0.861 | 0.889 |
| R+база-256 | 0.971 | 0.918 | 0.915 | 0.923 |
| база-128 | 0.924 | 0.859 | 0.864 | 0.853 |
| R+база-128 | 0.954 | 0.896 | 0.889 | 0.905 |
| база-64 | 0.896 | 0.820 | 0.817 | 0.825 |
| R+база-64 | 0.950 | 0.883 | 0.870 | 0.901 |
| база-32 | 0.863 | 0.795 | 0.810 | 0.771 |
| R+база-32 | 0.937 | 0.871 | 0.852 | 0.898 |
| база-16 | 0.837 | 0.711 | 0.662 | 0.861 |
| R+база-16 | 0.922 | 0.856 | 0.832 | 0.893 |
| R | 0.807 | 0.753 | 0.722 | 0.821 |
Как вы можете видеть, комбинирование характеристик, основанных на регулярности (обозначены за R) с базисными особенностями содержимого (обозначены за R+база-n) позволяет достичь значительно лучших результатов, нежели чем их одиночное применение.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации