SEO-Константа
Яндекс.Директ + оптимизация
Отчет об участии в дорожке поиска по коллекции конференции РОМИП-2009. Использование алгоритмов машинного обучения для оптимизации качества решения задачи ранжирования поисковыми машинами по базам BY.WEB ИKM.RU.
Ранжирование – это сортировка текстовых документов по степени их релевантности поисковому запросу. В этой сортировке документы упорядочиваются по убыванию, поэтому самые релевантные запросу документы должны выводиться в начале списка. Для решения этой задачи в современных поисковых машинах используются специальные ранжирующие функции, которые численно «оценивают» степень соответствия документа запросу. Основной задачей алгоритмов является непосредственно оценки степени релевантности и последующая сортировка документов в соответствии с задачей ранжирования.
Функция строится на так называемых признаках релевантности, имеющих численное выражение. Подобные признаки позволяют не только разделить документы на релевантные и нерелевантные поисковому запросу, но и объективно оценить степень их релевантности. В поисковых алгоритмах ранжирующие функции представляют собой комбинации множества факторов или признаков релевантности (сумма [1], взвешенная сумма [2] ), причем общее количество признаков редко превышает 15. Отдельные признаки релевантности в силу своей сложности могут использоваться как самостоятельные ранжирующие функции.
Новый подход к задачам ранжирования предполагает полноценное использование гораздо большего множества признаков релевантности – коллекция признаков BY.WEB включает в себя порядка 163 элементов. Основная их масса – это достаточно простые числовые характеристики, которые могут относиться как к самому документу, так и к поисковому запросу. Принципиальным отличием данного подхода является введение нового способа комбинации признаков релевантности, то есть, функции релевантности. Здесь ранжирующая функция вычисляется при помощи методов машинного обучения, что позволяет алгоритму поиска постоянно меняться и подстраиваться под новые признаки релевантности.
В данной работе рассматриваются две различные коллекции – BY.WEB и KM.RU, которые включают в себя различные наборы факторов. Первая коллекция – BY.WEB – использует 163 фактора, вторая – KM.RU – построена на 69 факторах.
Коллекция KM.RU взята из проиндексированной программой «Яндекс. Сервер» массы документов, где признаки релевантности и факторы, влияющие на ранжирование документов, представляют собой прямую функцию от тела документа и поискового запроса. В качестве примеров факторов ранжирования выступать могут:
Первая коллекция, коллекция BY.WEB – это выборка из белорусского сегмента интернет-пространства по состоянию на конец весны 2007 года. Именно поэтому коллекция включает в себя 163 фактора ранжирования, а также информация о ссылках. Примерами расширенной коллекции факторов ранжирования могут послужить:
В этом разделе будет рассмотрен процесс определения формулы релевантности для коллекции BY.WEB. Процесс и результат также применимы и к коллекции KM.RU.
Машинное обучение должно основываться на использовании баз знаний; здесь для коллекции BY.WEB была собрана специальная обучающая выборка. Выборка включала в себя порядка 45000 пар типа (запрос, документ), с уже определенной оценкой степени релевантности для каждого документа и соответствующего ему запроса. Оценки документам, соответствующим определенным запросам, включают в себя три типа оценок – «vital», «notrelevant» и «cantbejudged», где первый тип в численном выражении – это 0,4, а все остальные приравнивались к 0, при этом значения относятся к эвристикам [Эвристикой называется такой алгоритм решения какой-либо задачи, который не имеет под собою строгого математического обоснования, однако он позволяет находить правильное ее решение в подавляющем большинстве случаев. Например, продвижение сайтов учитывает алгоритм Google PageRank, который, в свою очередь, относится к эвристическим алгоритмам — прим. коллектива компании «SEO константа»]. Для каждой из пар были выявлены признаки релевантности и факторы ранжирования.
Основная задача машинного обучения – это приближение оценки релевантности на основе базы знаний, т.е., обучающей выборки. Немаловажной задачей является также и построение функции ранжирования документов, которая строится на минимизации функционала среднеквадратичного отклонения от значения оценок. Если поставленная задача будет решена верно, то результатом будет автоматическая правильная сортировка документов обучающей выборки, но при этом необходимость приближать оценку релевантности доминирует над требованием ранжирования документов, поэтому первый функционал в нашей задаче будет выражаться оптимизируемой задачей pfound.
Примем за истину, что задача ранжирования выполнена, и список из n документов отсортирован по определенному порядку в соответствии с оценкой их релевантности поисковому запросу. Далее будет описана модель, где пользователь, который ввел запрос, просматривает отсортированный список документов сверху вниз, т.е., в порядке убывания степени релевантности запросу. Тогда метрика pfound позволит оценить вероятности найти полностью релевантный документ в нашей модели. За формулу метрики pFound принята следующая формула:
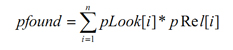
здесь за pLook[i] принимается вероятность просмотреть документ, стоящий на i месте из всего списка, а pRel[i] – это вероятность того, что этот документ будет полностью релевантен запросу.
Значение pRel[i] здесь является отображением автоматической оценки релевантности документа определенному запросу. В соответствии с ранее введенными числовыми выражениями оценки релевантности, документ с оценкой «vital» соответствует 0,4, то есть, вероятность его релевантности для пользователя приравнивается к сорока процентам. Остальные оценки, т.е., «notrelevant» и «cantbejudged» обладают нулевой вероятностью того, что документ будет релевантен запросу.
Оценка вероятности того, что пользователь просмотрит документ, находящийся на i месте в сортированном списке, основывается на двух базовых предположениях, используемых в данной модели. Первое предположение – это остановка поиска подходящего документа в случае его нахождения, а второе предположение – это беспричинная остановка поиска. В качестве формулы pLook[i] используется:
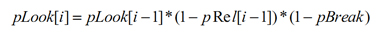
В формуле понятие pLook[i] обозначает вероятность того, что пользователь просмотрит i документ из списка, понятие l-pRel[i] – это вероятность того, что документ, находящийся на i месте не будет по мнению пользователя релевантен запросу, что вынудит его продолжать поиска, а l-pBreak – это вероятность остановки поиска без видимых причин. Значение pBreak в модели по умолчанию – 0,15.
Расчет значения pFound здесь описан только для одного запроса, в то время как переде машинным обучением ставится задача максимизировать усредненное значение метрики для всех 499 элементов типа «запрос» из обучающей базы.
В рамках обучения на базе коллекций BY.WEB И KM.RU использовались полиномы, которые выступали в роли функций релевантности ранжирования коллекций. Полиномы выбирались при помощи генетического алгоритма, а модификация стохастического алгоритма Differential Evolution [Дифференциальная эволюция представляет собою метод многомерной математической оптимизации, то есть задачи определения экстремума целевой функции в векторном пространстве, которая, в свою очередь относится к классу стохастических и генетических алгоритмов. Поисковая система Яндекс очень активно использует данный алгоритм в своей работе, так как он достаточно прост в своей реализации, может вычисляться параллельно, то есть одновременно — прим. коллектива компании «SEO константа»] использовалась для определения нужных коэффициентов при мономах.
После завершения тестирования различных формул релевантности были сформированы три группы результатов ранжирования, которые впоследствии и были отправлены на оценку. Первая группа результатов (CLEAR) была получена в ходе применения формулы машинного обучения из предыдущей секции на базе данных РОМИП’2008, вторая группа результатов (OLD) была получена путем применения формулы, использующей базу данных Яндекса, которые включали в себя до 20 000 тысяч запросов, третья, последняя группа результатов (MIX) – это результаты, полученные путем суммирования формул CLEAR И OLD. Из трех типов формул только формула CLEAR использовала сравнительно небольшие выборки, а вот формулы OLD и MIX работали с крупными базами данных, поэтому и результаты второй и третьей формулы были отправлены на анализ эффектов переобучения.
Ниже приведены наглядные графики оценки коллекции BY.WEB для всех трех групп результатов:
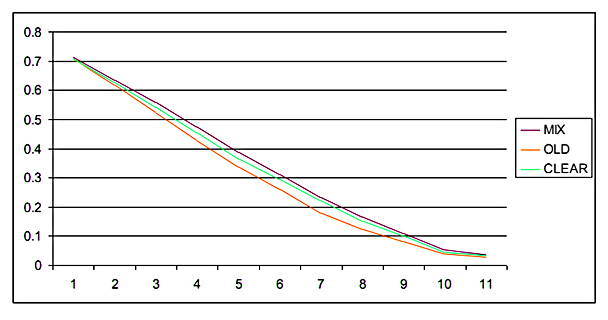
Худшие результаты были достигнуты путем использования формулы OLD, которая работает с данными, отличающимися от коллекции BY.WEB, однако при этом формула позволяет минимизировать эффект переобучения CLEAR, поэтому лучшей формулой признается формула MIX. Предложенные в данной работе алгоритмы ранжирования демонстрируют лучшие результаты, если сравнивать их эффективность с другими поисковыми системами. Ниже приведена таблица, отображающая топ систем по метрике Precision(10) для коллекции BY.WEB.
| MIX | CLEAR | xxx-4 | xxx-12 | OLD | xxx-11 | xxx-10 |
| 0.48849 | 0.4857 | 0.4816 | 0.4743 | 0.4681 | 0.4622 | 0.42363 |
Рерайт материала «Оптимизация Алгоритмов Ранжирования Методами Машинного Обучения» выполнила Инна Вдовицына
Полезная информация по продвижению сайтов:
Перейти ко всей информации