SEO-Константа
Яндекс.Директ + оптимизация
Противодействие поисковому спаму является одной из первостепенных задач, которые должны решать системы информационного поиска. Внедряемые анти-манипулятивные технологии главным образом фокусируются на детекции всевозможных стратегий, вводящих алгоритмы ранжирования поисковых систем в заблуждение. Среди подобного рода стратегий можно привести работу над псевдо-улучшением релевантности содержимого страничек веб-сайта поисковым запросам, а также задействование в манипуляциях ссылочного окружения. Несмотря на то, что предложенные поисковыми машинами анти-спам технологии были достаточно успешны в деле противодействия запрещенным практикам, они столкнулись с большими трудностями при внезапном появлении новой волны спам-технологий и ее неослабевающем давлении на результаты органического поиска. Мы пытаемся взглянуть на решение данной проблемы немного с другой точки зрения, отмечая, что пользовательские вопросы, по которым пользователи систем информационного поиска попадают на спам-страницы / сайты, обладают следующими характеристиками: 1) они популярны или отражают потребности пользователей поисковых систем и 2) в качестве ответа по ним предлагается только несколько ключевых или авторитетных ресурсов. Исходя из данных наблюдений, мы предлагаем вам новый алгоритм анализа информации пользовательских кликов, итеративно распространяющего спам-оценки между пользовательскими запросами и URL-адресами, содержащихся в небольшой исходной выборке страниц/сайтов. После того, как будет получена исходная выборка, мы используем гиперссылочную структуру двудольного кликового графа для обнаружения других страниц/сайтов, которые, с определенной долей вероятности, могут также являться спамом. Эксперименты показывают, что наш алгоритм эффективен и результативен в идентификации поискового спама. Кроме того, комбинирование нашего метода с некоторыми популярными анти-спам технологиями, такими как алгоритмом доверия TrustRank, позволяет достичь куда большей производительности, по сравнению с каждой из них взятой по отдельности.
К поисковому спаму можно отнести все попытки манипулировать алгоритмами ранжирования систем информационного поиска, как правило, с целью получения незаслуженно высоких позициях в органической выдаче одной или нескольких интернет-страниц [9]. Castillo и Davison [3] дали следующее определение спам-документам: это страницы сайтов, которые оказываются в выигрышной позиции в том случае, если используют запрещенные практики. Прежде всего, к таким страницам следует отнести те веб-документы, которые содержат непристойные материалы, вредоносное программное обеспечение, а также стремящиеся получить незаслуженно высокий поисковый трафик. Существует большое количество причин, по которым те или иные веб-мастера прибегают к спам-технологиям. Однако наиболее важной из всего их числа является то, что некоторые веб-страницы пытаются получить большее количество пользовательских визитов без наличия в своем содержимом контента надлежащего качества или каких-либо вложений в легальные инструменты рекламы. Согласно предыдущим исследованиям [19], подавляющее большинство пользователей, приходящих на поиск, ограничиваются просмотром только тех результатов поисковых машин, которые они возвращают на первую страницу органической выдачи; следовательно, посещаемость данной страницы или всего сайта будет напрямую зависеть от его положения в результатах рейтинга. Причина, по которой мы сталкиваемся с постоянно-растущими объемами некачественных документов и манипуляций, связана с тем, что поисковые системы уже давно играют доминирующую роль в поиске какой-либо информации и именно они считаются основным источником трафика для интернет-ресурсов. Следовательно, большинство манипуляций реализуется с целью получения прибылей. В 2005 году Singhal [20] подсчитал, что ожидаемый доход спамеров составляет несколько долларов США за продажу партнерских программ на Amazon, приблизительно 6$ за продажу Виагры и порядка 20-40$ за привлечение нового участника порнографического сайта. Для борьбы с поисковым спамом разработаны различные технологии. Внедренные анти-спам технологии используют особенности веб-страницы [17], включая как особенности содержимого [11], так и гиперссылочной структуры [4]; создают классификаторы поискового спама. Прочие особенности, такие как те, что извлекаются из поисковых логов, а также логов просмотров [4] [5] [12] также помогают нам идентифицировать спам. В действительности, мы можем обнаруживать спам с большей аккуратностью в том случае, если объединим все сигналы, следующие от заданной интернет-страницы/сайта, включая содержимое, гиперссылочную структуру, особенности поисковых логов, а также особенностей просмотра страниц пользователем [12][17]. В таком фреймворке разработчикам анти-спам методологий необходимо проделывать дополнительную работу по разработке отличительных характеристик и стратегий, позволяющих идентифицировать новые типы манипуляций посредством тщательного анализа особенностей спам страниц/интернет-ресурсов. Действительно, самым большим ограничением для такого агрегирующего подхода является то, что, в том случае, если прежние спам-техники оказались идентифицированы алгоритмами поисковой машины и потеряли прежнюю эффективность, спамеры незамедлительно разрабатывают новые манипулятивные схемы. Сейчас поисковый спам эволюционировал от простейшего текстового и ссылочного спама до более софистических технологий, таких, например, как использование JavaScript в своих манипулятивных целях [6].
В своем большинстве существующие исследования фокусируются на идентификации различных манипулятивных схем. Однако (что часто упускается из виду) в задачах противодействия мошенничеству было бы крайне полезно взглянуть на то, коим же образом спам-документы получают трафик и, соответственно, свои прибыли. Необходимо отметить, что пользовательские заходы на некачественные страницы в основном приходятся на системы информационного поиска, а их основной целью является привлечение настолько высокого трафика, насколько это только возможно. Говоря другими словами, они применяют различные спам-технологии для того, чтобы введенные в заблуждение ранжирующие механизмы поисковых машин признали продвигаемые ими странички/сайты более «релевантными» определенным пользовательским запросам, а следовательно имели лучшую видимость в результатах органического поиска и, таким образом, получили необходимый трафик. Такие пользовательские запросы спамеры подбирают с особенной тщательностью. Обычно, эти запросы выбираются, исходя из следующих двух параметров. Во-первых, как правило, они могут выбираться на основании своей популярности или из-за отражения высокого спроса со стороны пользователей поиска; в том случае, если манипулятивная стратегия будет выбрана верно, то и по последним поисковым запросам спамеры могут получить большой приток посетителей. Популярными запросами считаются такие запросы, которые обладают высокой частой встречаемости в поисковых логах. Как уже упоминалось выше, иные пользовательские запросы могут быть не столь популярными, однако отражать общую потребность в получении информации по какой-либо теме и, следовательно, обладать всем необходимым потенциалом, чтобы рассматриваться спамером наряду с явно популярными, например: «Как похудеть?», «Эффективны ли таблетки для похудения?» и т.п. Несмотря на то, что могут использоваться поисковые запросы, отличные от приведенных выше, в рамках выбранной спамером стратегии, они также отразят всю ту же необходимость в снижении веса, которая интересна большому числу пользователей веб-поиска. Во-вторых, для подобного рода спам-ориентированных запросов в результатах органической выдачи обычно наличествует только несколько ключевых или авторитетных ресурсов. В противном случае, а именно в том варианте, если бы в поиске по заданному пользовательскому запросу откликалось множество релевантных ответов и ключевых веб-сайтов, ситуация при которой спам-страницы получили бы высокие позиции была бы крайне маловероятной. Например, вряд ли спамеры выберут, а также оптимизируют содержимое своих некачественных документов, под такие запросы как «yahoo» или «нокиа» по той простой причине, что в результатах органического поиска существует множество авторитетных страниц, наличие которых устремляет вероятность получения спам-страницей высоких позиций к нулю. Следовательно, некачественные документы могут ранжироваться в результатах поисковой выдачи высоко только с учетом второй особенности избираемых оптимизатором запросов, в то время как первая особенность гарантирует ему то, что выбранное ключевое слово интересно большому числу пользователей поиска. Наконец, учитывая описанные нами особенности пользовательских запросов, привлекать пользовательский трафик спам-страницам помогает соответствующая оптимизация их содержимого.
Таким образом, более вероятно, что спамеры выберут в качестве ключевых фраз, которые будут приводить пользователей поиска на их некачественные страницы, 1) высокочастотные запросы или те, что отражают большой спрос со стороны пользователей поиска, и 2) в ответ на которые машина не может предложить ключевые или авторитетные интернет-сайты (в настоящей работе мы называем подобного рода запросы спам-ориентированными). С определенной долей вероятности те веб-документы/сайты, на которые выходят пользователи по спам-ориентированным запросам, сами являются некачественными. Эти два наших наблюдения означают, что для обнаружения поискового спама мы бы могли использовать логи кликов. Мы создаем двудольный кликовый граф, содержащий узлы запросов и узлы URL, а также применяем итерационный метод для пропагации спам-оценок (spamicity score) на основании двух указанных характеристик вероятности обнаружения манипулятивного содержимого. Мы обнаружили, что значительное количество некачественных страниц может быть идентифицировано с помощью применения исключительно данных пользовательских кликов. Такой результат демонстрирует, что мы бы могли улучшить производительность анти-спам технологии посредством учета преимущественно поисковых логов. Вклад настоящей работы заключается в следующем:
Результаты показывают, что предложенный алгоритм пропагации может идентифицировать различные спам-документы не только эффективно, но и с высокой результативностью. Оставшаяся часть нашей работы организованна следующим образом: Раздел 2 содержит краткий обзор смежных работ. Раздел 3 описывает нашу мотивацию в детекции поискового спама и формулирует проблему пропагации меток. В Разделе 4 мы обсуждаем нашу проблему распространения меток более детально и доказываем сходимость предложенного нами алгоритма пропагации. В Разделе 5 мы проводим экспериментальную проверку наших технологий, а также демонстрируем не только эффективность, но и результативность обнаружения спам-страниц по данным пользовательских кликов. В Разделе 6 мы подводим некоторые итоги и намечаем направления для будущих исследований.
Возникновение различных манипулятивных практик идет параллельно развитию систем информационного поиска. Castillo и Davison [3] сгруппировали технологии поисковых манипуляций по двум категориям: спам, относящийся к содержимому, и гиперссылочный спам. Манипуляции с контентом страниц, включая текстовой спам и методологии сокрытия, относятся к тем запрещенным технологиям, с помощью которых вебмастер, желающий улучшить видимость своего ресурса в результатах органического поиска, сознательно манипулирует алгоритмами оценки содержимого страниц своего сайта, а также анализаторами URL-адресов, разбивающих единообразные локаторы ресурса по наборам составляющих их ключевых фраз. Gyongyi и др. [11] представили группировку технологий контентного спама по типу реализации ключевых фраз в текстовых полях интернет-страниц, включая повторение, выгрузку, вплетение и, наконец, сшивание фраз; кроме того, были описаны такие технологии сокрытия, как клоакинг [24], мошеннические перенаправления [6], а также сокрытие видимого содержимого [15]. Для построения спам-классификатора, Ntoulas и др. [17] представили несколько конентных особенностей, а сама их работа до сих пор считается одной из наиболее авторитетных в задачах исследования детекции спама, относящегося к содержимому. Они обнаружили, что в отличие от НЕ-спам документов, спам-страницы содержат более популярные слова. Прочие исследования учли дополнительные текстовые особенности, которые позволили обнаруживать некачественные страницы. Такие лингвистические особенности [18], как часторечные n-граммы, текстовые характеристики [2], особенности языковой модели [14], а также паттерны HTML-кода [22,23] были полностью изучены и доказательно признаны полезными инструментами в задачах вычисления веб-спама.
Ссылочные спамеры создают определенные гиперссылочные структуры, целью которых является увеличение оценок, назначаемых такими классическими алгоритмами ссылочного анализа, как Google PageRank и HITS. К гиперссылочному спаму относятся ссылочные фермы [25], страницы-приманки [11] а также манипулятивные схемы по обмену ссылками между веб-сайтами. Были использованы разнообразные алгоритмы распространения доверия и недоверия, как TrustRank [10] и BadRank [21], а также их модификации [16, 26], которые доказали свою эффективность по части пессимизации поискового спама из результатов органической выдачи. Также было обнаружено, что некачественные сайты часто образуют плотные подграфы, то есть подмножество вершин, соединенных большим числом ребер; для их вычисления многие работы [4, 25] использовали ссылочные особенности, включая степени вершин и спамоемкость гиперссылочного окружения. Относительно недавно, Cheng и др. [7] использовали информацию, полученную на форумах по поисковой оптимизации с целью нахождения сайтов-соискателей и, таким образом, выхода на ссылочные фермы.
Для более эффективного и результативного обнаружения некачественных документов, исследователи обычно комбинируют различные спам-сигналы, поступающие из различных данных пользования вебом, включающие логи просмотров, а также поисковые логи, для построения соответствующих классификаторов. Liu и др. [13] использовали логи просмотров в задачах оценки авторитетности интернет-страниц посредством определения Марковской цепи с непрерывным временем по графу пользовательских просмотров. Они продемонстрировали эффективность их алгоритма BrowseRank в деле пессимизации некачественных веб-сайтов. Liu и др. [12] предложили фреймворк детекции поискового спама, ориентированный на пользовательского поведение, который также основывался на логах пользовательских просмотров, собиравшихся тулбаром одной крупной поисковой системы. Они показали, что практически единственным источником пользовательских визитов на некачественные сайты являются системы информационного поиска. Прочие особенности включали в себя вероятность того, что заданная страница может выступать в качестве документа-источника (то есть, в случае с ординарным документом, люди следуют по исходящим с него гиперлинкам), а также непродолжительности периода навигации по всему веб-сайту (исходя из того предположения, что подавляющее большинство пользователей не станут просматривать на некачественном ресурсе достаточное количество страниц). Поисковые логи содержат в себе различную информацию, касающуюся пользовательских запросов и релевантных им URL-адресов. Однако, не существует какого-либо детализированного анализа о том, каким образом могут быть использованы эти данные. Предыдущие исследования всего лишь выводили из них дополнительные особенности [5,12,17] в стоящих перед ними задачах идентификации ссылочного или контентного спама.
Подводя итого вышесказанному, внедренные анти-спам технологии используют контентные и ссылочные характеристики, а также особенности пользовательского поведения для построения классификаторов поискового спама. Разработчикам анти-спам методов необходимо проделывать дополнительную работу по разработке таких отличительных особенностей и стратегий, которые позволили бы идентифицировать новые типы спама путем тщательного изучения манипулятивных техник. Самое большое ограничение указанных подходов заключается в том, что, в том случае, если прежние обманные трюки оказались идентифицированы алгоритмами поисковой машины, спамеры разрабатывают новые спам-практики. По причине того, что спамеры часто разрабатывают новые спам-технологии и делают это практически мгновенно, как только старые методы перестают приносить желаемый результат, идентификация спама и равнодействующая анти-спам технология оказываются замкнутыми в порочном кругу.
Традиционные анти-спам технологии сфокусированы на идентификации различных манипулятивных практик. Данные технологии не учитывают то, каким образом некачественным документам удается получать пользовательский трафик, иными словами, они не исследуют то, с какой тщательностью осуществляется подбор ключевых фраз и увеличение позиций некачественных страниц/сайтов в результатах органического поиска. Чем больше пользовательского трафика получают спам-сайты, тем больше прибыли приносит это владельцам указанных веб-ресурсов, хотя это будет сопряжено с тем возрастающим разочарованием, которое будут все в большей мере ощущать пользователи поиска, получая в качестве ответа на свой запрос спам-страницу. Несмотря на то, что спамеры стремятся получить настолько высокий поисковый трафик, насколько это только возможно, маловероятно, как было описано нами в Разделе 1, чтобы их некачественные документы/сайты получили высокие позиции в органической выдаче по всему перечню тех пользовательских запросов под которые они оптимизируют свои интернет-ресурсы. Опираясь на эти наблюдения мы разработали алгоритм пропагации меток, который основан на данных пользовательских кликов. Если говорить более детально, то, для начала, в качестве исходного набора нами выбирается небольшое число страниц, а сама разметка идет по принципу спам или НЕ-спам. Далее их метки распространяются по кликовому двудольному графу и идентифицируются остальные возможные спам/НЕ-спам документы. Входные данные включают в себя: а) выборку маркированных URL-адресов (спам или НЕ-спам); б) набор немаркированных URL-адресов; в) ряд ограничений между URL-адресами и пользовательскими запросами в логах. Основная цель заключается в обнаружении спам страниц/сайтов по неразмеченным данным. До того момента, как мы сформулируем нашу задачу, давайте для начала дадим несколько определений:
I. Данные поисковых кликов C и двудольный граф G. Логи кликов состоят из тройки <q,u,fqu>, где q является запросом, под u понимается URL-адрес, соответствующий веб-документу, а fqu — это то количество кликов, которое пришлось на выданному URL-адресу по заданному пользовательскому запросу q. Определим Q = {q | q появляется в C} и U = {u | u появляется в C}. Данные поисковых кликов C имеют эквивалентную форму — кликовый двудольный граф G = (Q, U, E). На этом графе G существуют два различных типа узлов, запросов и URL-адресов. Для каждой записи <q,u,fqu> в C, существует ребро (q,u) ∈ E с весовым значением fqu. Каждой q/u назначается вероятность pq/pu, которая оценивает то, с какой вероятностью данная пара q/u является спам запросом/страницей или, говоря другими словами, оценивает спамоемкость q/u. Важно отметить, что кликовый двудольный граф может быть сконструирован либо на уровне интернет-страниц, либо на уровне веб-сайтов. В последнем случае, u заменяется на ассоциированный с ним сайт, при условии сохранения своего URL. Например, <«продвижение сайтов», http://wseob.ru/seo/promotion, 100> заменяется на <«продвижение сайтов«, http://wseob.ru/, 100>.
II. Маркированный исходный набор единообразных локаторов ресурсов L. Множество L содержит в себе все страницы/сайты в C(G), которые были вручную маркированы нами как спам или НЕ-спам. Более формально, L = {u | u маркирован в качестве спам страницы/сайта или НЕ-спам страницы/сайта}. Конструктивные особенности набора L будут обсуждаться в Разделе 5.2.
III. Итоговый набор единообразных локаторов ресурсов RU и итоговый набор пользовательских запросов QU. Множества RU и QU содержат в себе все пары <u,pu> и <q,pq>, соответственно. После завершения исполнения нашего алгоритма, каждому URL u или запросу q в C (или G) будет назначена вероятность pu/pq, которая оценивает вероятность того, является ли данный URL или пользовательский запрос спам страницей/сайтом или спам-ориентированным запросом. Более формально,
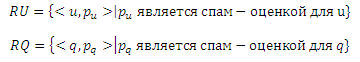
Для заданного G = (Q, U, E) и L⊂U, основная задача майнинга спам страниц/сайтов состоит в получении итогового набора RU и RQ, которые содержать все возможные спам страницы/сайты и запросы на графе G соответственно.
В настоящей работе мы предлагаем алгоритм пропагации меток (LP) для решения проблемы, определенной нами в предыдущем Разделе. Говоря более конкретно, для каждого пользовательского запроса q нам необходимо рассчитать вероятность pq того, что запрос q является спам-ориентированным посредством включения всех информационных меток от его окружения. Аналогично, мы рассчитываем вероятность pu для каждого URL u. Более формально описанную процедуру можно записать следующим образом. Для ∀q/u мы используем lq/lu для обозначения меток, которые в случае спама обозначаются за S, а в случае НЕ-спама за N. Важно отметить, что P(lu=N) = 1-P(lu=S). Следовательно, каждый URL u в маркированном наборе L должен изначально иметь P(lu=S)=1 или P(lu=S)=0, а каждый URL u в наборе U-L должен иметь P(lu=S)=0. Тогда, имеем:
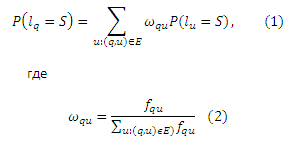
Параметр ωqu может быть интерпретирован как вероятность перехода от запроса q к URL-адресу u. Это может быть выведено из Уравнений (1) и (2) таким образом, что метка q определяется по всем окружающим ее меткам . Чем больше ωqu, тем большее влияние оказывает соответствующий узел на соответствующую метку q. Аналогично, для каждого URL u в U/L, вероятность P(lu=S) вычисляется следующим образом:
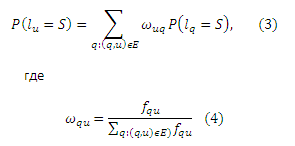
является вероятностью перехода от URL u к запросу q. Важно отметить, что как ωqu, так и ωuq не ограничиваются приведенной формой и могут быть заданы произвольным образом. Единственным требованием для них является то, что они должны иметь вероятностную интерпретацию, означая, что ∑q:(q,u)∈Eωuq = 1 и ∑q:(q,u)∈Eωqu = 1. Мы также можем интерпретировать ωqu и ωuq как функцию особенностей запросов и URL-адресов и, таким образом, включить данные особенности в расширенную версию нашего алгоритма. Мы оставим указанную процедуру для наших будущих работ. В соответствии с уравнениями (1) и (3) мы рекурсивно получаем P(lq=S) и P(lu=S) для всех запросов и URL-адресов на кликовым двудольном графе. Мы можем вкратце описать указанный итеративный процесс. Предположим, что существуют запросы |Q|: q1,q2…q|Q| и URL-адреса |U|: u1,u2…u|U|. Определим вектора:
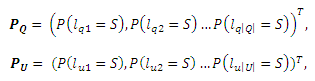
а также матрицы переходных вероятностей:
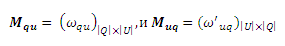
Тогда, в i-ой итерации, мы имеем:
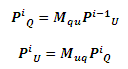
Необходимо отметить, что на каждом итерационном цикле всем URL-адресам в исходном наборе L переназначаются их изначальные метки. Таким образом, наш алгоритм сходится. В Разделе 4.4 мы докажем его сходимость.
Рассмотрим небольшой фрагмент двудольного графа, полученного по логам кликов, пришедшихся на результаты органического поиска, который приведен на Рисунке 1.
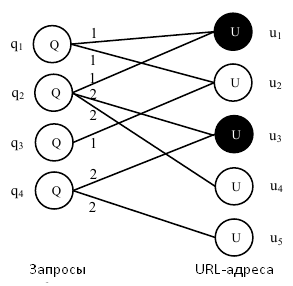
Рисунок 1. Пример, демонстрирующий работу алгоритма пропагации меток по кликовому двудольному графу.
Допустим, что L={u1, u3} и оба этих URL-адреса являются спам-страницами, которые на нашем Рисунке закрашены черным цветом. Прочие узлы, включая все узлы пользовательских запросов и оставшиеся узлы URL-адресов, изначально имеют нулевое значение P(l=S). Тогда, мы имеем:
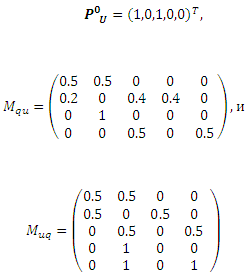
После первой итерации, получаем:
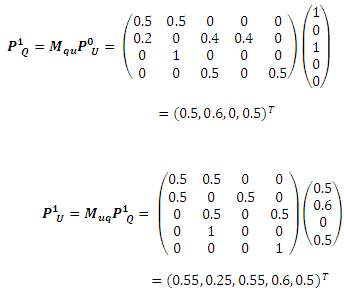
Отметим, что здесь как P(lu1=S), так и P(lu3=S) имеют значение 0.55, которое должно быть сброшено до 1 до начала следующей итерации.
Алгоритм пропагации меток или случайное блуждание по кликовым двудольным графам подразумевают проблему положительной обратной связи. Возьмем для следующего примера узел u5 из Рисунка 1. По истечению первой итерации P(lu5=S) составляет 0.5. Поскольку u3 является исходным URL, который имеет мануально нанесенную отметку «спам», мы устанавливаем P(lu3=S) в 1 до начала второй итерации. Следовательно, легко заметить, что после второй итерации P(lu5=S) составит 0.75 и сойдется к 1 в том случае, если наш алгоритм продолжит исполняться. Причина заключается в том, что ребро e=<q4,u5> неориентировано, а u5 является узлом, имеющим первую степень, что означает, что оценка u5 вернется q4; в ходе указанного процесса, u3 получит свою первоначальную спам-оценку. Мы называем такой эффект проблемой положительной обратной связи, которая может увеличить зашумленность кликового двудольного граф и, таким образом, исказить окончательные результаты. Рассмотрим экстремальный случай, представленный на Рисунке 2.
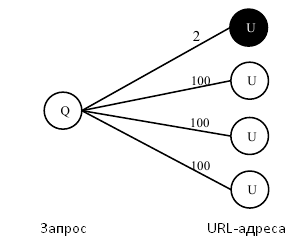
Рисунок 2. Экстремальный случай проблемы положительной обратной связи.
Предположим, что нетипичный пользователь обращается с запросом q к системе информационного поиска, а затем проходит по некачественному документу, в то время как большинство других пользователей, задавших данный запрос, следуют по предложенным ссылкам, ведущих на высококачественные веб-сайты. Все спам-оценки URL-адресов сходятся к 1 после исполнения нашего алгоритма на веб-графе, что противоречит действительному толкованию интернет-страниц и указанного запроса. Глядя на Рисунок 1, можно сделать вывод о том, что эта проблема в основном затрагивает узлы, имеющие первую степень, а именно u4, u5 и q3. Для того, чтобы решить эту проблему, мы вводим понятие доверия (confidence). Мы определяем степень доверия узла на двудольном графе как функцию его степени d. Говоря более формально, c(q)=f(dq), c(u)=f(du), где dq и du являются степенями узла q и u соответственно. Тогда Уравнения (1) и (3) можно переписать следующим образом:
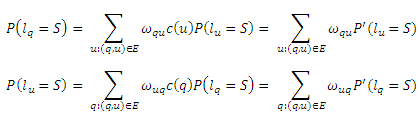
Необходимо отметить, что здесь функция f является произвольной со множеством вариантов. Для простоты, в текущей статье мы используем индикаторную функцию. Определяем
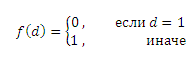
Интуитивной интерпретацией индикаторной функции является то, что до получения необходимого нам объема информации, касающейся оценки узла, имеющего первого степень, в том варианте, если он является спам-страницей, мы могли бы обойти его на двудольном графе как псевдо-нормальный документ, устанавливая его спам-оценку равной нулю. Важно отметить, что указанное ограничение затрагивает только немаркированные узлы, поскольку нам необходимо распространить значение спамоемкости из соответствующего исходного множества. Теперь, применяя модифицированный алгоритм к Рисунку 2, мы получаем P(lq3=S) = 2/302 и P(lu3=S) = P(lu4=S) = P(lu5=S) = 2/302, которые представляются более достоверными, нежели чем при исполнении оригинальной методологии. Схема алгоритма пропагации меток представлена на Рисунке 3.

Рисунок 3. Алгоритм пропагации меток (LP)
Очевидно, что Mqu и Muq являются стохастическими матрицами справа, строки которых состоят из неотрицательных действительных чисел, в сумме каждой из них дающих единицу. Далее рассмотрим Muu=MuqMqu. Для каждого элемента mij в Muu имеем
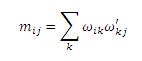
, где ωik и ω’ik являются элементами Muq и Mqu соответственно. Следовательно, мы имеем:
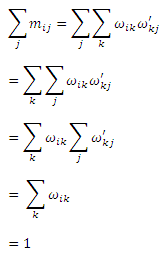
тем самым означая, что Muu также является стохастической матрицей справа. Теперь, если мы заинтересованы только в PU, итеративный процесс может быть переписан следующим образом:
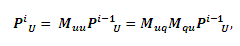
,где i обозначает итерации. Предположим, что существуют исходные URL-адреса |L| в L; узлы, имеющие первую степень, |C| и, таким образом, r = |U|-|L|-|C| оставшиеся URL-адреса в C. Говоря более конкретно, пускай вектор вероятности PU=(PT PL), где PT являются верхними строками |L|+|C| PU (маркированные и псевдо-маркированные данные), а PL оставшимися строками r PU (немаркированные данные). Мы разбиваем Muu после (|L|+|C|)-ой строки и (|L|+|C|)-го столбца на 4 подматрицы:
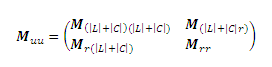
Отметим, что в действительности PT никогда не изменяется. Можно показать, что в нашем алгоритме PL=MrrPL+Mr(|L|+|C|)PT, что приводит нас к
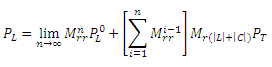
Zhu и Ghahramani [27] доказали, что PL сходится к (I-Mrr)-1Mr(|L|+|C|)PT в том случае, если матрица Muu является стохастической справа. Следовательно, начальное значение PL несущественно, то есть не представляет для нас особой важности. Применяя аналогичный подход, мы могли бы доказать, что PQ также сходится.
Основной целью настоящих экспериментов является оценка того, насколько эффективен наш алгоритм по части вычисления спам-сайтов. С учетом заданного исходного набора L, наш LP алгоритм возвращает перечень страниц/сайтов, отсортированных в порядке убывающей вероятности обнаружения в их содержимом поискового спама. Сами страницы/сайты, содержащиеся в исходной выборке, не включаются в данный перечень. Мы также получаем перечень поисковых запросов, отсортированных в порядке убывающей вероятности использования их на поиске в качестве спам-ориентированных запросов. Детальное обсуждение запросов и интернет-сайтов представлено в Разделе 5.6.
При содействии известной китайской коммерческой поисковой системы в период с 1 марта 2011 года по 5 марта 2011 года нам удалось собрать коллекцию логов пользовательских запросов. Отметим, что какая-либо приватная информация в них не содержалась. Мы сократили все пары «запрос-URL», имеющих всего лишь единственный клик за какой-либо день отчетного периода, поскольку они могут содержать шум и, возможно, приватную информацию. После выполнения процедуры по очистке данных, наша коллекция логов пользовательских кликов включала в себя 8443963 уникальных запросов и 12470865 уникальных URL-адресов, ассоциированных с 1055001 интернет-сайтом. В общей сложности было собрано 17660907 уникальных пар «запрос-URL», которые и были использованы для построения двудольного графа. Максимальная компонента связанности графа содержала в себе 211135 (25.0%) уникальных запросов, 3614514 (29.0%) URL-адресов и 7805300 (44.2%) пар «запрос-URL». Интересным наблюдением оказалось то, что вторая по величие компонента связанности содержала только 326 запроса, что намного меньше аналогичного значения, указанного для первой компоненты. Мы не видим какого-либо резона запускать процесс пропагации на столь слабо связанном графе. Следовательно, мы фокусируемся только на максимальной компонент связанности данного графа. Несмотря на то, что наш алгоритм может исполняться как на уровне кликов по сайтам, так и на уровне кликов веб-страницам, мы в основном использовали первый подход по причине разреженности данных. На единственную страницу обычно приходится несколько или даже один запрос, что добавляет нашим данным зашумленности.
5.2.1 Отбор исходного спам-набора
Исходное множество содержит маркированные для нашего LP алгоритма интернет-сайты. При содействии популярной китайской коммерческой поисковой системы мы получили перечень спам-сайтов. В наших данных пользовательских кликов в общей сложности появляется 2100 сайтов из числа этих некачественных интернет-ресурсов; мы возьмем их в качестве спам-секции нашей исходной выборки, которую будет использовать наш алгоритм.
5.2.2 Отбор исходного НЕ-спам множества
Для создания исходного НЕ-спам множества мы мануально выбрали несколько ординарных веб-сайтов, опираясь в своем решении, касательно включения того или иного ресурса в исходный набор, на два критерия. Во-первых, эти сайты должны быть популярными. Выбор подобного рода ресурсов обусловливается двумя причинами: а) чем популярней сайт, тем меньше вероятности того, что он будет содержать в себе поисковый спам и б) выбранные сайты содержат всевозможные ключевые ресурсы, и они нам необходимы для оценки спамоемкости пользовательских запросов. Во-вторых, мы удалям те сайты, контент которых генерируются самими пользователями по той простой причине, что мы не можем в этом случае гарантировать качество создаваемого содержимого. Например, news.sina.com не является спам-сайтом по той простой причине, что подавляющее большинство страниц представляют собой новостные статьи. Содержимое размещается только после предварительно проверки материала редактором. В отличие от него, сайт bbs.sina.com.cn было решено не включать в наш исходный набор постольку, поскольку принадлежащий ресурсу форум и его контент не обладает достаточно высокой степенью благонадежности. Для нашего исходного НЕ-спам множества мы вручную отобрали 1153 интернет-сайта. В завершении всего, мы создали исходную выборку для нашего алгоритма, которая включила в себя 2100 спам-сайта и 1153 НЕ-спам сайта. Оба указанных перечня ресурсов доступны по адресу thuir.cn/weichao/sigir2012/.
Мы запустили LP-алгоритм на двудольном кликовом графе, построенном по данным поисковых логов в соответствии с той методологией, что была подробно описана ранее, который мы назвали аналогично нашему алгоритму LP. Несмотря на то обстоятельство, что наш алгоритм сходится, куда более сложным вопросом является время его остановки. Мы обнаружили, что при 20 итерациях вероятность обнаружения некачественного сайта/документа изменяется не существенно. В частности, в нашем эксперименте мы не обнаружили значительной разницы между результатами, полученными после 20 и 40 итерациями. В нашем опыте мы использовали две методологии, выступивших в качестве сравнительной основы — алгоритм PageRank и TrustRank. Google PageRank является широко используемым методом ранжирования результатов органического поиска, а TrustRank демонстрирует свою эффективность в идентификации поискового спама. При содействии одной популярной коммерческой поисковой системы мы создали гиперссылочный граф, который содержал в себе 258326221 сайт. Для каждого исходящего со страницы A на документ B гиперлинка мы добавили ориентированное ребро, ведущее с веб-сайта A на сайт B. Таким образом, ссылочный граф содержал в себе 4883760072 ребер. Мы использовали указанную пару методологий, полностью основанных на данном ссылочном графе, которые можно рассматривать в качестве типичных представителей контенто-независимых алгоритмов противодействия некачественным ресурсам в реальных условиях Глобальной паутины. Кроме того, в реализации мы использовали стандартный параметр α=0.85. В дальнейшем, мы обозначаем эту пару алгоритмов нашего сравнительного анализа как PR и TRUST соответственно. Методологии, анализирующие содержимое документов/сайтов, в настоящей работе рассматриваться не будут по той простой причине, что большинство из них применимы только к определенным манипулятивным технологиям. Мы ожидаем, что они не смогут продемонстрировать достаточно хорошей производительности, так как в реальных условиях веба спам-сайты используют самые разнообразные обманные техники. Поскольку наш алгоритм пропагации меток использует различные типы информации, поступающей от реализованных анти-спам технологий, их алгоритмическая комбинация была бы, на наш взгляд, чрезвычайно интересной; мы ожидаем, что такого рода комбинация продемонстрировала бы куда большую производительность, нежели чем применение каждой методологии по отдельности. Для комбинирования результатов различных алгоритмов мы применяем методологию, которая была предложена в работе [1]. Предположим, что Lu является рангом сайта u в проверочном наборе, отсортированного по спам-оценке, присвоенной LP-алгоритмом, а Ou является рангом, присвоенным иным анти-спам алгоритмом. Оба списка сортируются в порядке убывающего значения вероятности принадлежности к спаму. Обратите внимание, что результаты, возвращенные PageRank/TrustRank сортируются в порядке возрастания присвоенных ими оценок, так как низкое значение PageRank/TrustRank свидетельствует о большей вероятности наличия некачественного сайта. Объединенная оценка S рассчитывается следующим образом:
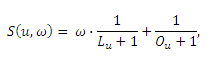
,где ω представляет собой значимость оценки, присвоенной LP-алгоритмом. Мы устанавливаем параметр ω=1, указывая на то, что оба алгоритма равнозначно важны в расчете итоговой оценки. Далее, список результатов, полученный с использованием LP, комбинируется с PR и TRUST; мы назовем их LP-PR и LP- TRUST соответственно. Мы запускаем 5 алгоритмов, а затем сравниваем их производительность на проверочном наборе по показателям точности, полноты и значения AUC, которые являются общепринятыми метриками, оценивающие идентификацию поискового спама, как , например, в предыдущих исследованиях [5][12].
Мы привлекли несколько экспертов для маркировки списка URL-адресов, который был возвращен алгоритмами. Тем не менее, такого рода маркировка представляется для нас нетривиальной задачей. Как обсуждалось в подразделе 5.1, наш двудольный граф построен по более чем 1 млн. веб-сайтов, а потому маркировка всего их числа не представляется возможной. Поскольку по большей части нас интересует производительность LP-алгоритма, мы равномерно избрали 3000 сайтов из первой половины результатного перечня, возвращенного LP, и использовали их в качестве проверочного набора. Причина, по которой мы решили сфокусироваться на топовой половине результатного перечня, возвращенного LP, заключается в том, что стоимость ошибочной маркировки авторитетного сайта (то есть отнесение его к категории спам-ресурса) значительно выше, нежели чем при обратной ситуации. Мы предложили двум опытным асессором оценить наличие на сайтах поискового спама в соответствии с критериями маркировки, использованных в Web Spam Challenge [28]. Следуя указанным инструкциям, наши асессоры помечают каждый интернет-сайт четырьмя вариантами меток:
Необходимо отметить, что мы очень строго относимся к оценкам некачественных сайтов, особенно в случае назначения отметки НЕ-спам «Пограничным объектам» и «Неклассифицируемым объектам». Причиной столь строго подхода, как уже упоминалось выше, является то, что стоимость ошибочной маркировки нормального сайта в качестве спам-ресурса значительно выше, нежели чем при обратной ситуации. Еще одна проблема заключается в том, что некоторые сайты могут исчезать из веба по ряду причини, долгое время оказываясь недоступными. Для анализа подобного рода ресурсов мы посылаем их URL-адреса коммерческой поисковой системе (sogou.com), взамен получая их снапшоты. После этого, на основании данных снапшотов им присваиваются соответствующие отметки: «Спам», «НЕ-спам» или «Недоступный объект». Те интернет-сайты, чьих снапшотов не существует, маркируются нами как «Недоступный объект». Каждому аннотатору было предложено промаркировать 1500 сайтов. Более того, им было предложено пометить еще 150 сайтов для того, чтобы оценить их согласованность. Значение Каппы Кохена, используемого нами в качестве критерия согласия, составило 0.856, что свидетельствует о превосходной согласованности между нашими аннотаторами. Из всех 3000 сайтов, отметку НЕ-спам получили 1490 интернет-ресурсов; отметку спам получили 870 сайтов; оставшиеся 640 сайтов оказались на момент нашего исследования недоступными. Мы удалили все недоступные сайты и использовали в качестве проверочного набора 2360 интернет-ресурсов, имеющих соответствующие отметки (более подробную информацию об этих сайтах, вы можете получить по адресу thuir.cn/weichao/sigir2012/).
Мы запустили пять алгоритмов и сравнили их производительность на проверочной выборке с использованием метрик точности, полноты и значения AUC. Результаты экспериментов продемонстрированы на Рисунках 4 и 5.
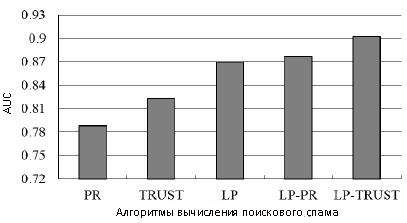
Рисунок 4. Значение AUC для различных стратегий идентификации веб-спама.
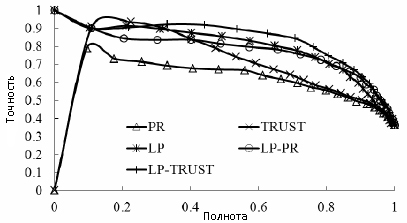
Рисунок 5. Кривая точности-полноты для различных алгоритмов детекции поискового спама.
Глядя на данные рисунки можно увидеть, что все значения AUC пяти алгоритмов оказываются большими, чем 0.78, что указывает на то, что все они отличаются эффективностью в деле определения некачественных ресурсов. По той простой причине, что спам-сайты пытаются увеличить свою голосующую способность, используя такие манипулятивные трюки, как создание ссылочных ферм, для нас не является неожиданностью то обстоятельство, что алгоритм Goolge PageRank показал здесь наихудший результат. TRUST показал результаты более лучшие, чем PR, что вполне согласуется с предыдущим исследованием [10]. Значение AUC нашего LP-алгоритма составило 0.870, что значительно превышает аналогичный показатель как у PR (0.788), так и у TRUST (0.823). Это является наглядной демонстраций того, что наш алгоритм эффективен в идентификации сайтов, использующих техники поискового спама. Обнадеживает то, что LP-алгоритм не только показывает лучшую по сравнению с TrustRank производительность, но и исполняется с меньшими временными затратами. В нашем эксперименте LP-алгоритм, использующий коллекцию пользовательских кликов, сошелся менее чем за 20 минут. В то же самое время, для сходимости алгоритмов TrustRank и PageRank потребовалось 10 часов, так как в отличие от нашего метода, эти алгоритмы исчисляются на всем веб-графе, который, как правило, содержит большее количество узлов, чем двудольный кликовый граф. В то время как комбинация LP-PR получает еще большее значение AUC (0.8771), алгоритм, комбинирующий LP-TURST, имеет впечатляющий показатель AUC (0.902), что существенно превышает результаты, полученные по всем прочим алгоритмам, и является наглядным свидетельством того, что именно такая комбинация позволяет достичь максимального увеличения производительности по части обнаружения поискового спама. Точность этого подхода может достигать как 90% при показателе полноты в 50%, так и 84.5% при показателе полноты в 70%.
Мы также решили провести еще один опыт с той целью, чтобы выяснить насколько наш алгоритм устойчив к спаму. Известно, что формирование исходного набора страниц в таких полу-обучаемых алгоритмах, как TrustRank, является одной из самых ответственных процедур. Мы рандомно разбили наши некачественные сайты на 21 подмножество (каждое из которых содержало 100 эталонных спам-сайтов), а затем постепенно добавляли их в исходный набор. Результаты этого опыта приведены на Рисунке 6.
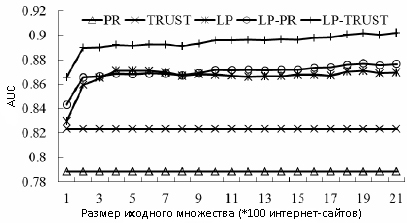
Рисунок 6. Производительность алгоритма с различным количеством спам-подмножеств, добавляемых в исходных набор.
Видно, что все наши алгоритмы устойчивы к поисковому спаму. Они могут достигать относительно высокого показателя AUC даже после добавления в исходный набор только 400 сайтов. Мы также обнаружили, что LP-алгоритм исполняется значительно лучше, нежели чем PR и TRUST. Показатель AUC комбинирующего алгоритма LP-PR оказывается несколько меньшим, чем у LP в том случае, когда размер эталонных спам-сайтов находится в интервале 400-700, однако в дальнейшем, при добавлении большего числа спам-подмножеств, он начинает превосходить LP. Алгоритм LP-TRUST в течение всего опыта показывал наилучшую устойчивость к спаму. Односторонний парный тест Уилкоксона продемонстрировал, что LP, LP-PR и LP-TRUST существенно лучше, нежели чем TRUST и PR, а LP- TRUST значительно лучше всех прочих методологий. Более подробные результаты тестирования представлены в Таблице 1.
| Тест Уилкоксона (p-оценка) |
PR | TRUST | LP | LP-PR |
| TRUST | 2.525e-06 | НД | НД | НД |
| LP | 3.206e-05 | 3.710e-05 | НД | НД |
| LP-PR | 3.206e-05 | 3.206e-05 | 0.000543 | НД |
| LP-TRUST | 3.206e-05 | 3.206e-05 | 3.206e-05 | 3.206e-05 |
Таблица 1. Результат одностороннего парного теста Уилкоксона (односторонняя p-оценка указывает нам на то, превосходит ли тот алгоритм, что указан в строке, тот метод, что указан в каждом столбце).
Эксперимент демонстрирует, что наш новый алгоритм достигает больших успехов в идентификации спам-сайтов. Более того, поскольку он исходит из абсолютно отличного взгляда на текущие анти-спам технологии, комбинирование данной модели с уже реализованными техниками приведет к более мощному подходу, который бы идентифицировал поисковый спам.
5.6.1 Анализ пользовательских запросов
Затем мы провели серию экспериментов для того, чтобы посмотреть как наш алгоритм обнаруживает спам-сайты, а также ответит на вопрос, почему комбинация LP и алгоритма TrustRank приводит к столь высокой производительности. Мы выбрали топ 1000 спам-ориентированных запросов и мануально классифицировали их на 7 категорий: порно, игры, здоровье, развлечения, программное обеспечение, лотереи и прочее. На Рисунке 7 представлен подробный композитный состав спам-ориентированных запросов.
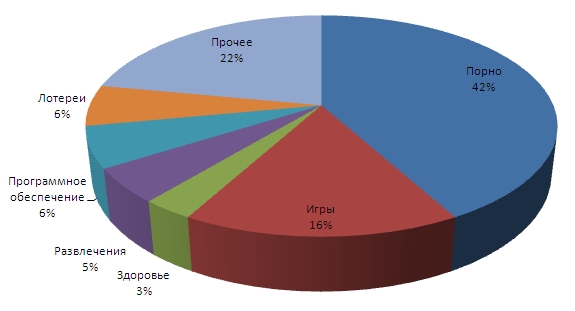
Рисунок 7. Композитный состав наиболее популярных спам-ориентированных запросов.
Как вы можете видеть, 42% данных запросов, так или иначе относятся к индустрии порно. Liu et al. [12] обнаружили, что многие спам-ориентированные запросы, приводящие на некачественные сайты, относятся именно к взрослой тематике. Как правило, спамеры используют их по той простой причине, что они никогда не теряют популярности в логах систем информационного поиска. Более того, по той простой причине, что во многих странах сайты с порно-контентом являются незаконными, очень часто по этим взрослым запросам не хватает ключевых ресурсов, которые, выступая в качестве ответов поисковой машины, являлись бы «авторитетными» в своей тематике. Подобного рода противоречие ставит данные запросы на первую строчку в рейтинге наиболее используемых в среде поискового спама.
Мы заметили, что запросы, относящиеся к играм стоят на втором месте (16% из 1000 запросов). Это объясняется тем фактом, что относительно много пользователей интернета являются молодыми людьми и играют в онлайн-игры. Неудивительно, что они используют поисковые системы для получения информации об играх. Однако помимо поиска нормальной информации, множество запросов могут подаваться с целью получения нечестной выгоды в играх или поиска нелегальных возможностей. Например, 64.2% игровых запросов касаются частных «пиратских серверов» для онлайн игр. Эти сервера являются нелегальными, так как они эмулируют работу официальных, но не предоставляют никаких гарантий. Зачастую сайты подобных серверов используют спам-техники для выведения своих позиций в на первую страницу органической выдачи. Обычные игровые сайты не рискуют применять спам-технологии, так как не в их интересах быть занесёнными в чёрные списки – так они потеряют весь трафик с поисковых систем. Обычно они применяют иные способы привлечения внимания, такие как спонсированный поиск. Но картина для нелегальных сайтов совершенно иная, так как поисковые системы сами предоставляют для них возможности использования спамерских технологий. Например, мы подали запрос «私服» (пиратский сервер) в Google 28 октября 2011 и обнаружили, что почти все сайты из топ-10 (кроме 5-го и 10-го) использовали спамерские техники для получения своих позиций. Фактически, 5-й результат был ссылкой на интернет-энциклопедию, похожей на wikipedia.com, а 10-й был новостной страницей известного веб-сайта. Данный пример показывает, что существует стойкая тенденция нелегальных сайтов использовать спамерские техники. Мы перечисляем их URL и способы в Таблице 2.
| Позиция | URL | Спам или НЕ-спам |
| 1 | 7774f.com | Спам (Выгрузка и Вплетение) |
| 2 | 52dayu.com | Спам (Выгрузка, Вплетение и Переадресация) |
| 3 | cnnds.com | Спам (Повторение и Сшивание фраз) |
| 4 | shiqi.cc | Спам (Ссылочный обмен) |
| 5 | baike.baidu.com/view/6975.htm | НЕ-спам (Сайт интернет-энциклопедии) |
| 6 | 20zf.com | Спам (Ссылочный обмен) |
| 7 | wnlzj.com | Спам (Вплетение и Сшивание фраз) |
| 8 | luosisa.com | Спам (Вплетение) |
| 9 | ipput.com | Спам (Вплетение и Сшивание фраз) |
| 10 | Вертикальный результат поиска (Новости) |
НЕ-Спам |
Таблица 2. Топ-10 результатов по запросу «私服».
Мы провели похожие исследования по запросам, относящихся к другим категориям и пришли к схожему выводу, что большинство запросов соответствуют двум критериям, озвученным в Разделе 1. Во-первых, они популярны или отражают высокий спрос пользователей поисковой системы, как, например, на онлайн-игры или фитнесс. Во-вторых, они не имеют ключевых ресурсов или авторитетных результатов. Несколько из этих запросов даже являются нелегальными. Предыдущее исследование [5] предполагает, что монетизируемые запросы с большей вероятностью являются спамовыми. Однако мы обнаружили, что популярные запросы (например, взрослой тематики), так же как и запросы с нелегальными намерениями тоже, вероятнее всего, являются спамовыми. На это есть две причины. Во-первых, спамеры стараются привлечь трафик на свои сайты, чтобы увеличить прибыль от рекламы вместо легальной продажи продуктов пользователям. Чем больше трафика или значения PageRank имеют их сайты, тем больше рекламодатель платит денег. Поэтому они стараются перетянуть трафик с популярных запросов и иногда преуспевают в этом по запросам с низким количеством авторитетных ресурсов. Во-вторых, аналогично нелегальным веб-сайтам, они не могут повысить свои позиции в выдаче поисковых систем нормальным способом, таким как спонсированный поиск, что приводит их напрямую к спамерским технологиям.
5.6.2 Анализ сайтов
Далее мы изучили характеристики спам-сайтов. При изучении топовых по спамерской оценке алгоритма LP сайтов, мы обнаружили, что большая часть сайтов содержала нелегальных контент, такой как порнография, ведение пиратских серверов и азартных онлайн-игр и при этом использовались спамерские техники для привлечения трафика. Наш алгоритм легко обнаруживал эти сайты, так как запросы, ведущие на них, были весьма специфичны и содержали либо слова взрослой тематики или ключевые фразы, включающие слова «пиратский сервер». В отличие от сайтов взрослой тематики, которые извлекают выгоду от повторения ключевых фраз, пиратские серверы или сайты онлайн азартных игр часто используют выгрузку, вплетение и сшивание ключевых фраз для перетягивания на себя поискового трафика. Более того, эти сайты зачастую ссылаются друг на друга и надеются получить бонус от обмена ссылками. К примеру, uiop8.com использует практически все спамерские техники, перечисленные ранее.
Другие спам-сайты, которые мы обнаружили, являются более «общими». Большая их часть выбирает тему, по которой проводится оптимизация и пытаются создать как можно больше спамерского контента, который кажется релевантным множеству запросов по конкретной тематике. Примером служит сайт hywww8.com. Также мы обнаружили, что спам-сайты с маленьким количеством запросов и кликов, скорее всего, являются спамерскими. Большая часть спам-сайтов в списке результатов имеют 1 запрос и 2 клика (2 – это минимальное число кликов в отфильтрованных логах кликов). Это соответствует интуитивному представлению. Авторитетные сайты чаще всего охватывают много тем или имеют много кликов. Как результат, когда пользователь кликает по сайту по спамовому запросу и его данные появляются в логах, где у него очень мало кликов по неспамовым запросам, у нас появляется больше уверенности, что сайт взаправду является спамерским.
5.6.3 Комбинирование пропагации меток с TrustRank
И хотя наш метод может обнаруживать разнообразные спам-сайты, у него есть свои ограничения. Тяжело маркировать нормальные сайты с небольшим числом запросов. Главной проблемой является то, что о таких сайтах наличествует очень мало информации в логах кликов. Однако прочие антиспамовые техники, такие как TrustRank, могли бы предоставить нам информацию об авторитетности сайта, а её можно было бы использовать для улучшения производительности наших алгоритмов. Но и у TrustRank есть свои ограничения. 17646.com, пиратский сервер онлайн-игр получил высокую оценку TrustRank, расположившись на 86000-м месте среди 258326221 сайта. В то время как TrustRank не смог определить его как спамовый сайт, наш алгоритм пропагации меток поставил его на 80-е место. Комбинируя спам-оценку и оценку доверия, мы поместили этот сайт на 176-е место в списке итоговых результатов, что означает, что он является спамовым. Так как мы используем принципиально иной подход для детекции поискового спама, мы ожидаем получения более высокой производительности посредством комбинирования нашего алгоритма с прочими современными достижениями. Это будет являться темой исследований наших последующих работ.
В данной работе мы предложили инновационный алгоритм пропагации отметок по двудольным кликовым графам для детекции поискового спама. В отличие от современных подходов, которые концентрируются на идентификации заранее определённых видов поискового спама на страницах или сайтах, наш алгоритм использует характеристики спамовых запросов. Оценка спамности передаётся между запросами и URL итеративно по двудольному кликовому графу из исходной выборки, которая содержит как спамовые, так и неспамовые страницы/сайты. Результаты экспериментов показывают, что наш алгоритм эффективен в обнаружении спамовых сайтов и отдельных страниц. Этот алгоритм открывает новые перспективы борьбы с поисковым спамом, а комбинирование с некоторыми современными антиспамовыми технологиями приводит к ещё более высокой производительности.
В дальнейшей работе мы планируем исследовать несколько нижеописанных аспектов. Во-первых, мы попытаемся разрешить проблему разреженности, описанную в Разделе 5 посредством сбора большего количества кликовых данных. Мы так же заметили, что существует несколько слабо связанных компонентов, помимо максимального в логе кликов. Являются ли они спам-сайтами? Как много спамовых сайтов содержится в данных компонентах? Мы попытаемся ответить на эти вопросы в дальнейших работах. Во-вторых, наш фреймворк будет расширен для включения характеристик контента, гиперссылочных характеристик и кликовых характеристик. Например, мы обнаружили, что даже для популярных неспамовых запросов сайты с низким числом кликов будут считаться подозрительными. Запрос «戴尔官方网站» («официальный сайт Dell») появлялся в логе 6159 раз, и по нему было кликнуто 39 различных сайтов. Среди этих сайтов спамовый сайт buydellonline.cn встречался дважды. Более того, он встречался всего 4 раза в логе кликов. И наоборот, dellenglish.com, который встречался всего три раза, но имел всего 38 кликов по запросу «изучение английского» оказался нормальным сайтом. Это показывает, что такие характеристики могут существенно повлиять на производительность алгоритма LP. Более того, мы заметили, что некоторые запросы имеют большую склонность быть спамовыми запросами, а другие наоборот, такие как названия небольших компаний. Таксономия запросов так же является полезной характеристикой. Мы будем использовать эту информацию в нашем процессе пропагации в дальнейшем.
Эта работа получила поддержку от Фонда Естественных Наук (60903107, 61073071), Национальной Программы Исследования и Развития (863) Высоких Технологий (2011AA01A205) и Исследовательского Фонда Докторской Программы Высшего Образования Китая (20090002120005).
Перевод материала «Fighting against Web Spam: A Novel Propagation Method based on Click-through Data» выполнили Константин Скоморохов и Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации