SEO-Константа
Яндекс.Директ + оптимизация
Максим Жуковский, Андрей Хропов, Глеб Гусев, Павел Сердюков (Яндекс)
Алгоритм BrowseRank и его модификации основаны на анализе сёрфинга пользователя. В данной работе предлагается новый метод для расчёта важности страницы с использованием более реалистичной и эффективной модели поведения пользователя при браузинге, чем в старом BrowseRank.
С целью улучшения качества информационного поиска, было разработано множество алгоритмов оценки важности веб-страниц: некоторые основывались на гиперссылочном анализе, другие — на пользовательском поведении, характеристиках ключевых фраз и т.д. BrowseRank [1] — это классический метод оценки авторитетности страницы, использующий данные о сёрфинге пользователя в расчёте. Согласно этому методу важность страницы соответствует её весу в стационарном распределении непрерывного процесса Маркова на графе сёрфинга пользователя. Несмотря на очевидные преимущества BrowseRank и его вариаций [2, 3], данные алгоритмы имеют ряд недостатков.
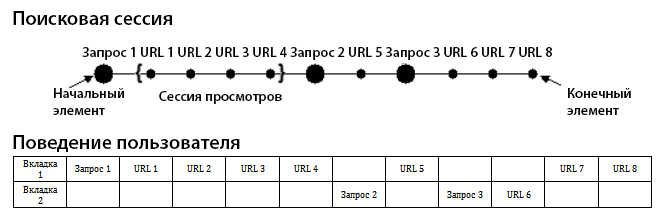
Рисунок 1. Типы сессий.
В данной работе мы предлагаем новый алгоритм под названием Search-aware BrowseRank (SBR). Наш алгоритм работает с модифицированным графом сёрфинга пользователя с дополнительными вершинами, которые соответствуют запросам и дополнительным рёбрам, соединяющих запросы и страницы. Данная модификация создана с целью решения первой из двух вышеупомянутых проблем путём учёта запросов в качестве части сессии браузинга и определения одинаковых запросов с разным порядковым номером в сессии, что случается практически в каждой сессии. Вторая проблема решается за счёт введения зависимости коэффициента пессимизации от средней позиции страницы в сессии. Чтобы продемонстрировать эффективность Search-aware BrowseRank мы сравнили его результаты с классическим BrowseRank на крупном графе сёрфинга пользователей. В итоге вклад нашей работы заключается в следующем:
Допустим, имеется пользователь и история его посещений. Мы добавляем запросы в сессии сёрфинга по определению Liu и др. [1] чтобы они были зависимы от пользовательского поведения. В отличие от Liu и др., согласно которому пользовательская сессия заканчивается со вводом нового запроса, мы рассматриваем эти сессии как наборы страниц и запросов с нижеописанными свойствами. Сессия начинается с веб-страницы или с запроса. Пусть p1,1…p1,j1,q1, p2,1…p2,j2,q2… будут первыми элементами сессии (в выборку добавлены и страницы и запросы). Пусть последняя запись в журнале пользователя была записана во время t (или же после посещения страницы pk,i или после подачи запроса qk), а следующая запись появится во время t~.
Пусть приращение t~ – t не превышает 30 минут. Если запись, сделанная в момент времени t~, описывает или переход со страницы p из выборки {p1,1,p1,2,…,pk,i} к странице pk,i+1 посредством клика по гиперссылке или описывает клик страницы pk,i+1 после подачи запроса q из выборки {q1,q2,…,qk}, тогда мы добавляем pk,i+1 в сессию и называем парой соседних элементов либо {p,pk,i+1}, либо {q,pk,i+1}. Если запись t~ описывает подачу запроса qk+1, то мы добавляем этот запрос в сессию и называем {pk,i,qk+1} парой соседних элементов (если запись, сделанная в момент времени t описывает подачу запроса qk, то пара соседних элементов это {qk,qk+1}).
Во всех остальных случаях страница pk,jk:=pk,i (или запрос qk) является страницей (или запросом) перехода данной сессии. Новая сессия браузинга начинается с первого элемента (запроса или страницы) в записи t~.
Для каждой страницы p (или запроса q) из логов пользователя мы определяем число сессий, которые начинались данной страницей или запросом как s(p) или s(q), соответственно. Для каждой пары соседних элементов {vi,vi+1} в сессии мы определяем число сессий, содержащих такую пару соседних элементов как I(vi,vi+1). Мы определяем элементы сессии браузинга S как v1(S),…,vk(s)(S). Соответствующие даты записей в истории определяются как t1(S),…,tk(s)(S), соответственно.
Мы даём следующее определение Search-aware графу сёрфинга G = (V,E): набор вершин V состоит из всех веб-страниц Vpage и всех запросов Vquery, упомянутых в логе и содержит одну дополнительную вершину x. Набор ориентированных рёбер vi → vi+1 в E является упорядоченным набором пар соседних элементов {vi,vi+1} в сессия браузинга. Набор E содержит дополнительные рёбра, идущие от последних страниц сессий к x. s(x) приравнивается к нулю. Пусть I(v,x) – число визитов v, если v → x принадлежит E. При моделировании пользовательского поведения на Search-aware графе браузинга мы рассчитываем вероятность сброса (т.е. вероятность начала новой сессии) и вероятность перехода (вероятность клика по гиперссылке или подачи запроса в пределах данной сессии). Вероятность сброса σ(v) для v ∈ V = s(v)/(∑v—∈VS(v~)). Пусть vi → vi+1 будет в E. Вероятность перехода описывается следующей формулой:
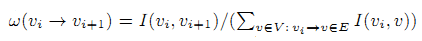
Чтобы определить предполагаемое время пребывания пользователя на странице p, мы считаем набор T(p) наблюдаемых интервалов пребывания tj+1(S) – tj(S), так чтобы pj(S) = p. Мы определяем оставшееся время пребывания Q(p) на странице p через T(p) аналогично работе [1]. Другими словами мы предлагаем рассматривать распределение интервалов пребывания как сумму распределения Чи-квадрат и экспоненциального распределения.
Алгоритм Search-aware BrowseRank определяется аналогично [1]. Его выходными данными является стационарное распределение непрерывного процесса Маркова на Search-aware графе сёрфинга. Пусть α(p) (α(q)) будет вероятность перехода по случайному ребру пользователем на странице p (или подающим запрос q). Пусть v ∈ V. Пусть s*(v) — это доля сессий, в которых p является последним элементом. Пусть a,b,c ∈ [0,1] являются изменяемыми коэффициентами. Определяем α(v) как линейную функцию:
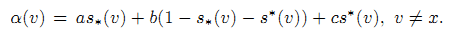
Search-aware BrowseRank для v ∈ V равен Q(v)π(v), где π(v) — это решение следующей системы линейных уравнений:
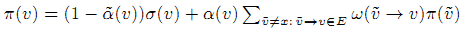
где α~(v) = α(v)(1 — π(x)) (эти уравнения работают и при v = x). Это определение отличается от определения BrowseRank только выбором графа и коэффициента пессимизации α(v). Системы линейных уравнений, определяющих π(v) для BrowseRank и Search-aware BrowseRank одинаковы.
Все эксперименты проводились на данных о пользовательском поведении, собранных в декабре 2012 года через Яндекс-бар. В выборке присутствует порядка 800 млн. страниц и около 4.41 млрд. переходов. Для оценки ранжирования мы выбрали 1000 запросов реальных пользователей. Для каждого запроса ряд URL оценивался экспертами, нанятыми поисковой системой. Оценка релевантности выбиралась по пятибалльной шкале: Идеально, Отлично, Хорошо, Неплохо, Плохо. Мы сравнили Search-aware BrowseRank (SBR) с классическим BrowseRank следующим образом. Алгоритмы линейно скомбинированы по рангам с BM25. Чтобы компенсировать разницу в масштабе BrowseRank и оценок BM25, параметр линейной комбинации выбирался таким образом, что средние значения характеристики и BM25, помноженных на коэффициент, равны. На рисунке 2 приводится производительность ранжирования по метрике NDCG@10 по обоим алгоритмам с разными параметрами.

Рисунок 2. Производительность SBR с параметрами (a,b,c).
Что касается BrowseRank, его NDCG@10 составляло около 0.7561. Результаты нашего эксперимента наглядно показывают, как влияет изменение коэффициента пессимизации страниц на производительность алгоритма ранжирования. Лучший результат был достигнут при условии a < b < c. Поэтому мы считаем, что настройка коэффициента пессимизации в виде функции расположения страницы в сессиях и увеличение веса страниц перехода в этой функции может повысить производительность алгоритма ранжирования.
Наши результаты могут быть использованы коммерческими поисковыми системами для улучшения качества поиска, в особенности на фоне высокой активности компаний по продвижению сайтов. Было бы интересно продолжить изучение коэффициента пессимизация при вышеупомянутых настройках.
Перевод материала «Introducing Search Behavior into Browsing Based Models of Page’s Importance» выполнил Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации