SEO-Константа
Яндекс.Директ + оптимизация
К ссылочному спаму относятся любые попытки спамеров улучшить видимость своих интернет-сайтов в результатах органической выдачи посредством введения в заблуждение алгоритмов ссылочного ранжирования поисковых машин. Спамеры часто формируют плотно-связанные гиперссылочные структуры веб-сайтов, так называемые «ссылочные фермы». В текущем исследовании мы изучаем общую структуру и распределение ссылочных ферм по крупномасштабному графу, относящегося к японскому вебу, который содержит 5.8 млн. сайтов и 283 млн. гиперссылок. Для того чтобы изучить манипулятивную структуру мы используем на наших данных три графовых алгоритма. Сперва веб-граф разлагается по компонентам сильной связанности (SCC). Помимо крупнейшей компоненты (ядра), которая располагается в центре веба, мы обнаружили, что наиболее крупные SCC содержат в себе ссылочные фермы. Затем, для извлечения спам-сайтов, расположенных в ядре, мы перебираем максимальные клики в качестве исходных образцов ссылочных ферм. Наконец, мы расширяем данные линкофармы как достоверный исходный спам-набор посредством использования техники минимального разреза, которая сепарирует гиперссылки между спам и НЕ-спам сайтами. Мы обнаружили порядка 0.6 млн. некачественных сайтов в компонентах сильной связанности, сформировавшихся вокруг ядра, а также извлекли дополнительные 8 тысяч и 49 тысяч спам-сайтов из самого ядра с высокой степенью точности, посредством использования алгоритма перебора максимальной клики и техники минимального разреза соответственно.
К ссылочному спаму относятся любые попытки спамеров улучшить видимость своих веб-сайтов в результатах органической выдачи посредством введения в заблуждение алгоритмов ссылочного ранжирования поисковых машин. Спамеры часто формируют плотно-связанные гиперссылочные структуры веб-сайтов, так называемые «ссылочные фермы», посредством применения различных технологий, которые приведены в работе [8]. Поскольку данные мошеннические схемы могут ухудшить качество органического поиска, задача идентификации подобного рода спам-сайтов в киберпространстве представляется крайне важной. Существует не так уж много научных исследований посвященных проблеме ссылочных ферм. В текущей работе мы изучаем общую структуру и распределение ссылочных ферм по крупномасштабному графу, относящегося к японскому вебу, который содержит 5.8 млн. сайтов и 283 млн. гиперссылок. Для того чтобы изучить манипулятивную структуру мы используем на наших данных три графовых алгоритма. Сперва, веб-граф разлагается по компонентам сильной связанности (SCC). Мы обнаружили крупнейшую SCC, которую назвали ядром и которая содержала порядка 30% всех сайтов, обнаруженных в работе [5]. К своему удивлению мы обнаружили, что наиболее крупные компоненты сильной связанности, сформировавшиеся вокруг ядра, состоят из линкофармов. В указанных SCC мы обнаружили порядка 0.6 млн. спам-сайтов. Поскольку ядро до сих пор содержит множество некачественных ресурсов, нам необходим более строгий критерий, который позволил бы извлекать из нее ссылочные фермы с высокой степенью эффективности. Говоря более конкретно, мы перебираем максимальные клики, содержащиеся в ядре в качестве исходных образцов линкофармов. В процессе перебора кликов было обнаружено порядка 8 тыс. спам-сайтов, формирующих плотно-связанные ссылочные фермы. Затем, мы расширяем данные линкофармы посредством применения техники минимального разреза, который сепарирует ссылки между спам и НЕ-спам ресурсами. Эта техника позволила дополнительно извлечь 49 тыс. спам-сайтов с высоким показателем точности. Однако мы обнаружили, что в самом ядре содержится порядка 57 тыс. спам-ресурсов.
Оставшаяся часть нашего исследования организованная следующим образом. В Разделе 2 мы делаем краткий обзор предыдущих исследований, так или иначе связанных с нашими результатами. В Разделе 3 мы описываем наш набор данных. В Разделе 4 демонстрируются результаты разложения SCC нашего набора данных. В Разделе 5 мы применяем алгоритм перебора максимальной клики в целях разложения компонент. Кроме того, в Разделе 6 мы предлагаем вычисление спама с использованием техники минимального разреза . Заключительные слова авторов настоящей работы, а также их благодарности приведены в Разделе 7.
Основной целью гиперссылочного спама являются такие алгоритмы ссылочного ранжирования, как Google PageRank [16] и HITS [10], которые рассматривают гиперссылку, ведущую на какую-либо интернет-страницу в качестве ее неявного одобрения прочими документами в Сети. Для увеличения показателей ранжирования, спамеры часто добавляют исходящие ссылки с популярных веб-сайтов, а также различными способами накапливают большую гиперссылочную массу, ведущую на их целевой интернет-ресурс, например посредством связывания принадлежащих им веб-сайтов друг с другом [8]. Воздействия практики ссылочного спама на алгоритм PageRank исследовалось в работе [4, 7]. Для противодействия ссылочным манипуляциям и были предложены всевозможные технологии. Некоторые из них используют машинное обучения для классификации спам и НЕ-спам страниц, на основании тех особенностей, которые относятся к гиперссылочной структуре (например, полустепень исхода/захода вершины) и показателям ссылочного ранжирования страницы [1, 2, 3]. Другое направление работ пытается улучшить существующие модели алгоритмов ссылочного ранжирования, сделав их более устойчивыми к различного рода манипуляциям и ссылочному продвижению сайтов. В работах [4, 9, 11] предлагались и тестировались на реальных веб-данных различные ссылочные алгоритмы. Среди них были ряд гиперссылочных подходов [15, 17, 13], которые извлекали ссылочным спам, используя такие понятия из теории графов, как компоненты бисвязанности и общность гиперссылочного окружения. Насколько нам известно, ни одна предыдущая работа не занималась изучением распределения ссылок спам-сайтов, а также их связей в глобальной структуре веб-графа, что представляется крайне важным для определения большого числа некачественных ресурсов. Broder и др. [5] также использовали в своей работе разложение компонент сильной связанности веб-графа и исследовали глобальные свойства графа. В качестве дополнения к их исследованиям, мы обнаружили, что практически все сайты, включенные в крупные компоненты сильной связанности, которые сформировались вокруг ядра, являются спамом и они связаны с самим ядром. Flake и др. [6] предложили эффективную идентификацию веб-сообществ, которые представляют собой наборы сайтов, связанных тематически, посредством использования фреймворка максимального потока / минимального разреза. Данные подходы игнорируют направление ссылок между исследуемым веб-сайтами. Однако в задачах детекции ссылочного спама направление ссылок является крайне важным аспектом, поскольку некачественные интернет-ресурсы часто ссылаются на хорошие веб-сайты, а хорошие ресурсы, в свою очередь, цитируют своих неблагонадежных соседей по Сети крайне редко, что было изучено в работе [9]. Следовательно, мы предлагаем фреймворк максимального потока, учитывающего направления ссылок, и применяем его к ядру.
Для проведения экспериментов мы использовали крупномасштабный снимок мгновенного состояния (snapshot) нашего веб-архива, описанного на японском языке, который был создан посредством сканирования, проведенного в мае 2004 года. В принципе, наш агент накопления данных основан на поиске в ширину [14]; за тем исключением, что он фокусируется на страницах, описанных на японском языке. Мы собирали документы не принадлежащие доменной зоне .JP только в том случае, если они были написаны на японском. В случае фильтрации НЕ-японоязычных документов, мы рассматривали сайт как единый элемент. Процесс сканирования страниц интернет-ресурса прекращается в том случае, если при обходе первых нескольких страниц, относящегося к какому-либо веб-сайту, не было обнаружено ни одного документа, описанного на японском языке. Таким образом, этот набор данных содержит в себе довольно приличное количество страниц, описанных на английском или других языках. Процент документов, описанных на японском языке, оценивается в 60%. Этот мгновенный снимок гиперссылочного состояния включает в себя 96 млн. интернет-страниц и 4.5 млрд. ссылок. Мы используем веб-граф на уровне сайтов, в котором узлы представляют собой интернет-сайты, а ребра — существующие гиперссылки между страницами на различных сайтах. Обнаружение плотной связанности между некачественными спам-ресурсами на графе сайтов представляется куда более простой задачей, нежели чем на графе страниц, где подобная идентификация в принципе невозможна. Для конструирования графа сайтов, мы для начала взяли с каждого интернет-сайта репрезентативную страницу, которая имела 3 или более входящих гиперссылок с других сайтов и чей URL-адрес имел трехуровневую вложенность (например, http: //A/B/C/). Затем, те веб-страницы, которые имели вложенность меньшую от репрезентативного документа сокращались до одного сайта. Наконец, ребра между двумя веб-сайтами создавались в том случае, если между их страницами существовали гиперссылки, которые связывали данные ресурсы. Граф сайтов был сконструирован по данным нашего мгновенного снимка ссылочного состояния, включившего в себя 5.8 млн. веб-сайтов и 283 млн. ссылок. В своей работе мы называем этот набором данных веб-графом. Основные свойства и статистика доменов нашего веб-графа представлена на Таблице 1 и 2 соответственно. Наши вычисления были выполнены на рабочей станции, которая имела 4-ядерный процессор AMD Opteron 2.8 ГГц и 16 Гб оперативной памяти.
| Количество узлов | 5,869,430 |
| Количество дуг | 283,599,786 |
| Максимум полустепеней захода (исхода) | 61,006 (70,294) |
| Среднее значение полустепеней захода (исхода) | 48 (48) |
Таблица 1. Свойства веб-графа
| Доменная зона | Количество | Доля (%) |
| .COM | 2,711,588 | 46.2 |
| .JP | 1,353,842 | 23.1 |
| .NET | 436,645 | 7.4 |
| .ORG | 211,983 | 3.6 |
| .DE | 169,279 | 2.9 |
| .INFO | 144,483 | 2.5 |
| .NL, .KR, .US и пр. | 841,61 | 4.3 |
Таблица 2. Общие и национальные домены верхнего уровня, содержащиеся в нашем наборе данных
Ориентированный граф называется сильно связанным в том случае, если для каждой пары узлов существует ориентированный путь, соединяющий их друг с другом. Компонентами сильной связанности (SCC) ориентированного графа являются его максимальные сильно связанные подграфы. Обратите внимание на то, что компоненты сильной связанности однозначно разлагается на непересекающихся подмножества узлов и задача подобного разложения может быть выполнена за линейное время. Поскольку спам-сайты плотно связаны между собой, посредством ссылочной структуры, а хорошие сайты редко цитируют некачественные интернет-ресурсы, мы можем ожидать, что спамеры формируют компоненты сильной связанности без качественных веб-сайтов. В дальнейшем, мы приведем ряд наблюдений, которые нам удалось получить по данным нашего бенчмарка. Наш веб-граф разлагается на отдельные 3,424,385 компоненты. Распределение компонент по размеру, как было обнаружено в работе [5], следует степенному закону с экспонентой в 2.32. Здесь обнаруживается наиболее крупная компонента (ядро), кардинальность которой составляет 1,784,322. Указанное ядро содержит множество авторитетных сайтов и может быть рассмотрено в качестве центра наших данных. Количество компонент с единственной страницей составляет 3,398,316. Следуя работе [5], мы предлагаем вашему вниманию структуру « галстук-бабочка», которая отражена на Рисунке 1, и описывает взаимосвязь между ядром и прочими частями с указанием процента содержащихся в каждом ее элементе веб-сайтов.
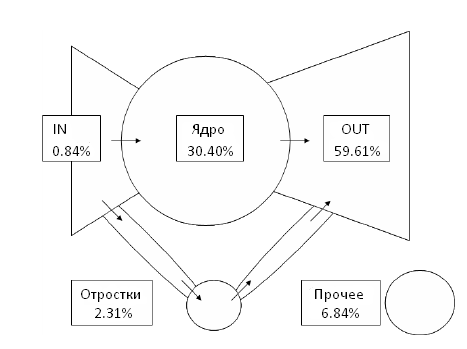
Рисунок 1. Структура «галстук-бабочка» в нашем наборе данных.
Далее по разделу мы увидим то, каким образом по этой структуре распределяются ссылочные фермы. Затем, мы рассмотрим относительно крупные компоненты с более чем 100 узлами за исключением самого ядра. Количество подобных компонентов составляет 551, притом, что в них содержится около 571 тыс. веб-сайтов. Наиболее часто встречающимися доменными зонами являются .COM (70.2%), .INFO (16.4%) и .NET (8.5%). Отметим, что сайтов, расположенных в доменной зоне .JP среди них нет. Рисунок 2 демонстрирует нам плотность каждой компоненты.
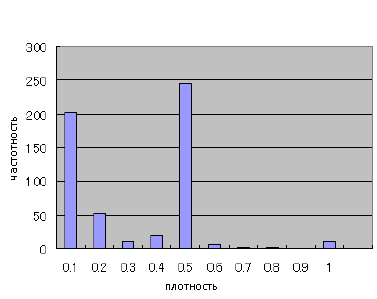
Рисунок 2. Плотность компонентов
Плотность индуцированного S ⊆ V подграфа определяется отношением числа его дуг к потенциально возможному их количеству, то есть A(S)/(|S|(|S| − 1)). Можно увидеть, что более чем половина из них формируют плотные гиперссылочные структуры с плотностью превышающей 0.5. Мы также проанализировали содержимое рандомно выбранных 550 веб-сайтов посредством отбора 110 компонент с последующим извлечением из каждой компоненты 5 интернет-сайтов (110 х 5 сайтов = 550), а также классифицировали их по трем категориям, то есть спам, подозрительные и НЕ-спам. Таблица 3 демонстрирует нам, что наибольшее число образцов является спамом.
| Спам | Подозрительные | НЕ-спам | |
| Число | 527 | 23 | 0 |
| Доля (%) | 95.8 | 4.2 | 0 |
Таблица 3. Образцы веб-сайтов, извлеченные из крупных компонентов(за исключением ядра)
Наконец, давайте рассмотрим распределение полученных компонентов в структуре «галстук-бабочка». Таблица 4 демонстрирует их распределение, которое указывает на то, что большинство ссылочных ферм сосредоточено в части OUT.
| OUT | IN | Отростки | Прочее | |
| Сайты | 448,688 | 4,919 | 40,425 | 77,626 |
| Компоненты | 450 | 10 | 32 | 59 |
Таблица 4. Распределение компонентов с более чем 100 узлами (за исключением ядра) в структуре «галстук-бабочка»
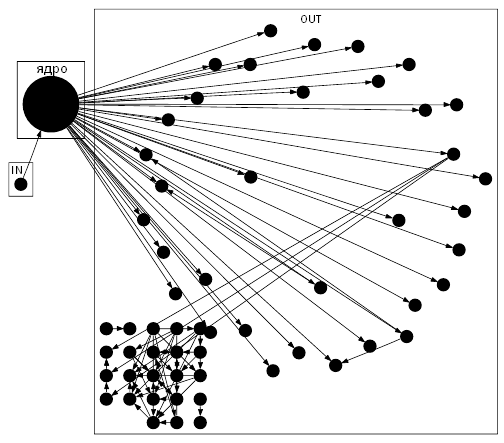
Рисунок 3. Связь компонентов
Ориентированный граф, представленный на Рисунке 3, демонстрирует связь между ядром и ссылочными фермами. Данный граф получен посредством сужения каждой компоненты сильной связанности в ядре, IN и OUT до узла, и удаления тех SCC, чей размер оказывается меньшим, чем 1000. Самая крупная компонента (ядро) обозначена на Рисунке 3 большой черной точкой. Вокруг ядра формируется множество крупных компонентов сильной связанности и, что является удивительным, все они оказываются ссылочным фермами. Между ядром и крупными компонентами в OUT существует множество дуг. Это означает, что эти SCC формируют оптимальные ссылочные фермы [7], которые накапливают входящие гиперссылки и не цитируют какие либо внешние веб-сайты. Необходимо отметить, что представленные на Рисунке 3 компоненты, связанные с ядром через более мелкие компоненты, опущены из рассмотрения. Поскольку данные SCC содержат спам-сайты с высокой степенью точности, мы можем использовать их в качестве исходного множества для дальнейшего вычисления ссылочных ферм, которое будет описано в Разделе 6. Обратите внимание на то, что сильная связанность является крайне слабым критерием для разложения. Например, для того, чтобы спамерам обойти подобную технологию идентификации им вполне достаточно начать цитировать качественные интернет-ресурсы. Действительно, ядро по-прежнему содержит большое количество спам-сайтов. Следовательно, в следующем разделе мы рассмотрим более сильный критерий плотности подграфа.
В этом разделе мы займемся перебором максимальных клик на веб-графе в соответствии с нашими задачами по обнаружению спам-сайтов в ядре. Мы полагаем, что большие клики вероятней всего сформированы спамерами. Для ориентированного графа G=(V,A), мы называем подмножество узлов K ⊆ V кликой в том случае, если существуют дуги (u, v), (v, u) ∈ A для любой пары узлов u,v ∈ K. Пусть GC = (C,A(C)) будет узлом, индуцированным подграфом G для компоненты сильной связанности C ⊆ V. Мы определяем неориентированный граф G’C = (VC,EC) из GC через EC = {{u,v} | (u, v), (v, u) ∈ A(C)}, а VC ⊆ C является множеством конечных точек каждого ребра в EC. Обращаем ваше внимание на то, что K является кликой на ориентированном графе GC в том и только в случае, если K является кликой (в привычном смысле) на неориентированном графе G’C. Далее мы продемонстрируем результаты наших расчетов. В оставшейся части настоящего исследования мы сосредотачиваемся на ядре C, которое является самой крупной компонентой, обнаруженной в Разделе 4. Рассматривая наш граф как неориентированный, мы получаем 1.09 млн. узлов и 6.59 млн. ребер. Максимальная степень неориентированного графа G’C составляет 3094. Поскольку алгоритм перебора максимальных клик, использованный в работе [12] использует O(∆4) для обнаружения максимальной клики, где ∆ обозначает максимальную степень графа, это отнимает слишком много времени для G’C постольку, поскольку максимальной степенью является 3000. Следовательно, мы отсекаем узлы, которые имеют степень большую, чем 80. Данная специальная процедура уменьшает количество узлов и ребер до 1,064,922 и 3,222,189 соответственно, а среднюю степень до 6.5. Кроме того, мы игнорируем те максимальные клики, чей размер оказывается меньшим 40 постольку, поскольку количество клик подобного размера огромно, а более крупные все-таки имеют большую тенденцию оказаться ссылочной фермой. Количество полученных нами клик составляет 26,931, притом, что они содержат 8346 различных веб-сайтов. Отметим, что большинство данных клик перекрывают друг друга. Указанные 8346 сайта, относятся к доменным зонам .COM (62.8%), .NET (11.2) и прочим, которые имеют несущественный процент. Мы выбрали в качестве образцов 165 сайтов из данных 8346 интернет-ресурсов и мануально классифицировали их, получив результаты, которые представлены в Таблице 5. Необходимо отметить, что большинство данных клик состояло из спам-ресурсов. Поскольку эти клики также содержат спам-сайты с высокой степенью точности, мы можем использовать их в качестве исходного набора для последующего вычисления ссылочных ферм в следующем разделе.
| Спам | Подозрительные | НЕ-спам | |
| Число | 157 | 8 | 0 |
| Доля (%) | 95.2 | 4.8 | 0 |
Таблица 5. Выборка сайтов, извлеченных из клик
В этом разделе мы предлагаем методологию вычисления спама, основанную на задаче минимального разреза s-t и двойственной ей задачи максимального потока s-t. Мы используем компоненты сильной связанности и клик, полученные в предыдущих разделах нашего исследования в качестве исходных наборов для последующего расширения и нахождения большего числа спам-сайтов. Здесь мы снова обращаемся к интуиции, которая говорит нам о том, что вопреки цитированию некачественными ресурсами хороших веб-сайтов, последние ссылаются на них крайне редко. Это предполагает, что «локальная реберная связанность», следующая от хороших сайтов к некачественным ресурсам в ядре крайне мала. Следовательно, можно ожидать, что при рассмотрении потока, исходящего от качественных интернет-ресурсов по направлению к спам-сайтам, минимальный разрез сепарирует ссылки между хорошими и некачественными узлами. Пусть W ⊆ V и B ⊆ V обозначают исходные наборы хороших и спам-сайтов соответственно. Положим сеть NW,B =((V ∪ {s, t}, A ∪ As ∪ At), c, s, t) с виртуальным истоком s, виртуальным стоком t, As = {(s, v) | v ∈ W}, At = {(u, t) | u ∈ B}, и пропускной способностью дуги c(a) = ∞ для a ∈ As ∪ At и c(a) = 1 в противном случае. В данной сети мы решаем задачу минимального разреза s-t
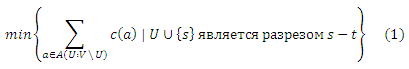
, где A(U : V U) является разрезом U. Мы рассматриваем V U* в качестве ссылочной фермы, где U* является таким узлом подмножества, что U* ∪ {s} является минимальным разрезом s-t. В реальных вычислениях мы решили задачу максимального потока s-t, которая двойственна (1), с использованием алгоритма проталкивания предпотока, который был предложен Гольдбергом и Тарьяном; время его исполнения составило 30 минут. Поскольку минимальный разрез s-t не является единственным, мы взяли минимальный разрез s-t поиском в глубину из t в остаточном графе полученного максимального потока. Далее вам предлагаются результаты наших вычислений. Сеть построена с учетом ядра. Мы мануально выбрали исходный набор, состоящий из 210 хороших сайтов. Исходный набор спам-сайтов изначально содержал в себе 8346 интернет-ресурса, содержащихся в кликах из Раздела 5, а также 448688 сайта, извлеченных из крупных SCC (расположенных в OUT), которые были связаны с ядром, что было описано в Разделе 4. Наша техника минимального разреза расширила исходный набор с 8346 до 57350 сайтов, содержащихся в самом ядре. Следовательно, мы получили дополнительно 49004 сайта. Наиболее доминирующей доменной зоной оказалась .COM (62.9%); за ней следовала .NET (19.8%). Наши результаты включали в себя только 62 страницы, относящиеся к доменной зоне .JP. Таблица 6 демонстрирует результаты по выборке, состоящей из 487 сайтов-участников ссылочных ферм. Данные свидетельствуют о том, что наш метод оказался вполне приемлемым в задачах идентификации некачественных ресурсов.
| Спам | Подозрительные | НЕ-спам | |
| Число | 459 | 27 | 1 |
| Доля (%) | 94.25 | 5.54 | 0.21 |
Таблица 6. Выборка сайтов, полученных техникой минимального разреза
Мы провели исследование общей структуры и распределения ссылочных ферм на крупномасштабном веб-графе с использованием графовых алгоритмов. Для начала мы использовали разложение компонент сильной связанности на веб-графе и обнаружили, что большинство крупных компонентов, формирующихся вокруг ядра, состоят из ссылочных ферм. Затем, мы перебрали максимальные клики в ядре в качестве образцов ссылочных ферм, а также показали, что перебор крупных максимальных клик был эффективен в задаче детекции образцов ссылочных ферм. Наконец, мы расширили данный исходный набор с помощью техники минимального разреза. Мы обнаружили порядка 0.6 млн. спам-сайтов в SCC, сформировавшихся вокруг ядра. Кроме того, мы извлекли 8 тыс. спам-ресурсов посредством применения алгоритма перебора максимальной клики и получили более 49 тыс. сайтов, содержащихся в ядре. Следовательно, мы обнаружили в самом ядре порядка 57 тыс. спам-сайтов с высокой степенью точности. Мы отметили, что практически все полученные ссылочные фермы состоят из веб-сайтов, описанных на английском языке. Однако посредством простой выборки мы все еще наблюдаем большое скопление ссылочных ферм в ядре. Следовательно, крайне важным является вопрос о том, чтобы в перспективе предложить такие методы, которые улучшили бы наш ссылочный подход. Посредством перебора максимальных клик мы можем обнаружить только малую долю скрытых в ядре линкофармов, поскольку мы игнорируем узлы с более высокой степенью по причине временных затрат, требующихся для вычисления. Еще одна причина заключается в том, что клики являются достаточно строгим критерием плотности. Следовательно, крайне важным является вопрос о том, чтобы внедрить более гибкие определения плотности подграфа. Существует много возможностей для улучшения нашего наивного подхода, заключающегося в использовании техники минимального разреза, поскольку имеется ряд альтернатив, касательно выбора пропускной способности дуги и исходных множеств. Это также является важным вопросом при использовании нашего метода на других бенчмарках.
Мы благодарим Такэаки Уно за предоставленную нам реализацию алгоритма перебора максимальной клики.
Перевод материала «A Large-scale Study of Link Spam Detection by Graph Algorithms» выполнил Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации