SEO-Константа
Яндекс.Директ + оптимизация
Прежде мы уже описывали вам методику автоматической идентификации географической принадлежности интернет-ресурсов [здесь]. Данная же статья, во-первых, более подробно раскрывает изложенную ранее схему объединения алгоритмов Яндекса, а во-вторых, описывает простой и быстрый, но, тем не менее, достаточно точный метод ассоциирования веб-ресурсов, находящихся в базе данных Яндекса, с их географическим положением. Этот алгоритм использует данные о положении по IP адресу, доменные имена и информацию из содержимого сайта: телефонные и почтовые коды. Новизна текущего подхода заключается в создании базы данных местонахождения по IP адресу используя метод непрерывных блоков IP-адресов. Кроме того, свой вклад вносит и анализ доменных имен. Способ использует инфраструктуру поисковой системы и даёт возможность эффективно и на постоянной основе ассоциировать большие объёмы данных поисковой системы с географическим положением. Опыты были проведены на индексе поисковой системы Яндекс; оценка показала высокую эффективность выбранного алгоритма.
С недавних пор учет географических факторов интернет-страниц в ранжировании сайтов становится всё более необходимым для большинства интернет-пользователей. Эта тенденция отмечена академическими исследованиями в данной области и появлением локальных служб онлайн-поиска.
Кроме российской доменной зоны, поисковая система Яндекс индексирует ресурсы, расположенные на доменах постсоветского пространства, а также любые другие русскоязычные документы вне зависимости от их размещения. На момент написания материала, в Яндексе проиндексировано около 600 миллионов страниц с более чем 2.5 миллионов веб-сайтов; из них около 95% относятся к Российской Федерации. Несмотря на то, что самая высокая интернет-активность наблюдается в крупных городах, таких как Москва и Санкт-Петербург, интернет в России и других постсоветских странах развивается главным образом в удалённых регионах. Этот факт говорит о крайней необходимости поисковой системы Яндекс получить максимально подробную и точную информацию о географической принадлежности проиндексированных html-страниц сайтов.
Данный вопрос частично решается в Яндекс.Каталоге посредством ручной модерации. В настоящее время, каталог содержит около 87,000 записей географическими метками, которые присваиваются редакторами вручную; из них около 48,000 отнесены к русским городам. Географический атрибут имеет разные семантические свойства: 1) расположение провайдера (физическое местонахождение владельца ресурса); 2) география контента (географическое положение, описанное в содержании веб-страницы); 3) зона обслуживания (область, на которую распространяется веб-ресурс) [2]. Присвоенные вручную значения могут быть унаследованы от поддоменов или отдельных страниц сайта. При этом, редакторы запрещают наследование значение для определённых доменов (например, от бесплатных хостингов или публичных доменов). Около 140,000 сайтов дополнительно получают атрибут российского города посредством наследования его из каталога (расширенная ручная классификация, РРЧ (extended manual classification, EMC)). Однако для текущего географического покрытия базы данных необходима разработка автоматизированных методов массовой географической ассоциации проиндексированных веб-ресурсов. Мы используем РРЧ в качестве проверки правильности алгоритмов, представленных ниже.
Современные тенденции вынуждают применять практический подход: методы обязаны быть эффективными, качественными и развивать обработку уже полученных данных. Эта статья описывает прогресс по автоматическому определению географических свойств русских сайтов на уровне города.
В литературе можно найти достаточное количество различных методов, которые используются для целей географической маркировки (смежные работы не представлены из-за ограничений по размеру статьи). В их число входят, как учет IP-адреса и доменного имени, так и содержимое сайта (например, названия городов, телефонные и почтовые коды). Главной идеей нашего подхода является эффективная комбинация нескольких источников географической информации.
Для определения города мы разработали два метода, работающих с 1) содержимым ресурса и 2) с данными на уровне веб-сайта (именем домена и IP-адресом). Эти способы были совмещены в последовательности, показанной на Рис. 1. Число классифицированных сайтов и значения точности (P) и полноты (R), вычисленные при помощи РРЧ даны для каждого шага нашей классификации. Более жирные стрелки показывают, что результаты классификации сопоставлены с входными данными для дальнейшней обработки. Таким образом, результаты классификации накапливаются в последовательности текущей обработки.
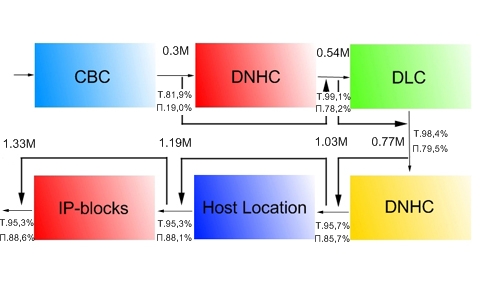
Рисунок 1. Последовательность работы классификатора.
Как показано на рис. 1, первый узел DNHC значительно увеличивает как полноту, так и точность, в соответствии с РРЧ (EMC).Последующие шаги не приводят к серьёзному повышению качества, определённому РРЧ (присутствует даже небольшое снижение точности), зато число классифицированных сайтов существенно возрастает (по причине того, что менее популярные не входят в РРЧ).
В итоге, используя диаграмму, мы могли бы распределить по соответсвующим городам ~1.3 миллиона русскоязычных сайтов из ~2 миллионов в базе данных Яндекса.
Эффективность алгоритма, работающего с трастовой базой высокоцитируемых веб-сайтов, может быть опредлена из сравнения с данными РРЧ. Для проверки общей производительности алгоритма в условиях сильной нагрузки, была сгенерирована тестовая выборка. Мы составили список из 1,200 веб-сайтов, выбранных случайным образом, не более одного на каждый домен второго уровня. Все сайты в списке были автоматически маркированы следующим образом: «город» и «без города» (т.е. алгоритм не может распознавать город). Список был отдан редакторам Яндекс.Каталога для ручного распределения в типичных условиях. Полученные после ручной обработки данные дали возможность разделить тестовую выборку на три категории: 1) географически определенные сайты, 2) трастовые, не спам-ресурсы (т.е. не сайты-дорвеи, не сайты в разработке, не устаревшие, не пустые или сайты-киберсквоттеры) и 3) полный набор сайтов.
Результаты оценки алгоритмом всех этих категорий собраны в Таблице 1. Первая колонка относится к подмножеству локальных сайтов (1). Метка «без региона» для этого подмножества была отброшена – произошла потеря в полноте алгоритма, но так же наблюдается и отсутствие потерь в точности. Во второй и третьей колонке автоматически назначенная метка «без региона» была интерпретирована как атрибут «без географии». Случай в определённой степени спорный, так как классификатор не разрабатывался для определения различий между локальными, глобальными и спам-сайтами; «без региона» чаще означает, что применённая техника распознавания города была провальна. Как результат, точность и полноста для этих случаев практически одинаковы.
| Локальные сайты | Локальные + нелокальные сайты | Вся выборка (+ «cпам») | |
| Количество сайтов | 723 | 1048 | 1200 |
| Точность | 0.917 | 0.722 | 0.688 |
| Полнота | 0.751 | 0.696 | 0.667 |
| F1 | 0.826 | 0.709 | 0.607 |
Таблица 1. Результаты оценки.
В данной статье описывается несколько методов, решающих задачу географического распределения сайтов, сумму которых должно учитывать региональное продвижение сайтов в поисковой машине Яндекса. Эти методы использует данные о положении по IP адресу, доменные имена и информацию из содержимого сайта: телефонные и почтовые коды. Методы используют инфраструктуру поисковой системы и делают возможной эффективную ассоциацию большого количества поисковых данных с географией на постояннной основе. Новаторский подход был разработан для ассоциации IP-адресов с регионами, основываясь на содержимом интернет-сайта. Данный способ имеет наибольшую степень точности для целей географического распределения, по сравнению с традиционными методами парсинга записей регистратора. Ещё одним вкладом является метод, основывающийся на исчёрпывающем анализе доменных имён.
Проведённая оценка доказала пригодность использования данного подхода в условиях реального веба. Несмотря на то, что при всем этом оценка продемонстрировала проблему в разделении сайтов на локальные, национальные и глобальные, мы также рассмотрим ее в скором времени и разработаем для этих целей классификатор по разделению сайтов вне зависимости от географического контекста.
Авторы хотели бы поблагодарить редакторов Яндекс.Каталога, которые взяли на себя мануальную обработку данных автоматической классификации.
Перевод материала «Automatic Geotagging of Russian Web Sites» выполнил Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации