SEO-Константа
Яндекс.Директ + оптимизация
Современные поисковые системы выдают список документов фиксированной длины (обычно 10) в ответ на запрос пользователя. Следующие 10 результатов поиска находятся в пределах одного клика. Эта документы либо заменяют данную страницу результатов, либо добавляются в конец списка. Следовательно, чтобы изучить более 10 документов, показанных первыми, пользователь обязан явно выразить своё намерение. И хотя кликабельность документов ниже на второй странице (и после), тем не менее они представляют значительный объём трафика.
Мы предлагаем модификацию кликовой модели Динамической Сети Байеса (Dynamic Bayesian Network, DBN) явно включив в модель вероятность перехода между страницами поисковой выдачи. Мы покажем, что наша новая кликовая модель способна гораздо лучше отражать поведение пользователя на (и после) второй страницы результатов, при этом показывая производительность аналогичную первой странице результатов.
На странице результатов выдачи современной поисковой системы (коммерческой или любой другой) обычно расположены кнопки, ведущие к дальнейшим результатам поиска. на Рисунке 1 показан пример таких кнопок. Пользователь может перейти к следующей странице результатов либо используя номер страницы (например, «2»), либо нажав кнопку «Следующая страница». В нашем эксперименте используются похожие настройки.

Рисунок 1. Кнопки постраничной навигации поисковой системы
Анализируя лог кликов поисковой системы Yandex, мы выяснили, что 1/3 всех пользователей использует кнопки постраничной навигации как минимум раз в неделю. На уровне запроса, с вероятностью в 5-10%, пользователь перейдёт ко второй странице поисковой выдачи. Эта вероятность ещё выше для последующих страниц результатов — переключившись на вторую страницу выдачи, пользователь зачастую продолжает переходить к третьей и четвёртой страницам, и данная вероятность как минимум в 5 раз превышает вероятность перехода с первой страницы на вторую. В среднем, пользователи изучают 1.1 страниц. Эти факты говорят о том, что мы должны уделять больше внимания ранжированию документов за пределами первой страницы выдачи — подобные документы характеризуются необычным кликовым паттерном и интеренсны значительному количеству пользователей.
Главный исследовательский вопрос, освещённый в этой работе — моделирование поведения пользователя на страницах поисковой выдачи. Мы утверждаем, что существующие кликовые модели не в состоянии корректно отображать кликовое смещение (skewness — перекос, асимметрия), вызванное необходимостью переключать страницы и предлагаем модификацию кликовой модели Динамической Сети Байеса посредством явного включения в модель вероятности перехода между страницами поисковой выдачи.
Seo и др. [8] изучали задачу, схожую с проблемой смещения, которой мы занимаемся в контексте совокупности поисковых интерфейсов. В их работе поисковая система выдавала набор вертикальных блоков, каждый из которых обладал так называемым пределом ранга (rank cut) — показывались только первые 5 документов из всей вертикали. Было обнаружено, что пользователи редко продолжают перемещаться по вертикали, вместо этого предпочитая переключаться на следующую вертикаль. Следовательно, наблюдалось смещение в количестве кликов, полученном конкретной вертикалью. В целях борьбы со смещением, авторы предложили использовать нормализацию количества кликов.
Мы же предлагаем вместо нормализации использовать подход кликовой модели. Кликовая модель — это вероятностная модель кликов в поведении пользователя. Обычно такие модели включают в себя как наблюдаемые события кликов по документу (Ck), так и скрытые события, например «пользователь изучил сниппет k-того документа» (Ek). В данной работе мы предлагаем использование модели Динамической Сети Байеса (DBN), как у Chapelle и Zhang [1]. С момента её появления, DBN широко использовалась и расширялась для работы с различными задумками. К примеру, Hu и др. [6] использовали модель DBN, чтобы наглядно показать как меняется восприятие релевантности в сессиях поиска. Не так давно Huang и др. [7] так же создали модель на основе модели DBN, но с иной целью: они включили информацию о перемещении курсора мыши в кликовую модель и показали, что это помогает улучшить прогноз кликов.
Основа. Для каждого запроса q мы определяем сессию запроса как набор действий, выполненных пользователем, начиная со ввода запроса и продолжая до тех пор, пока пользователь не введёт новый запрос или полностью покинет поисковую систему (т.е. закроет окно браузера). Модель DBN [1] включает в себя следующие бинарные события для каждого результатаk:
Мы используем Упрощённую модель DBN — SDBN (Simplified DBN), описанную в [1, Раздел 5]. Эта модель допускает, что пользователь изучает Ek документов один за другим, начиная с первого документа (E1 = 1). Сперва он изучает сниппет документа и, если он привлечён данным документом) (Ak = 1), он совершает клик (Ck = 1). Если после клика результат удовлетворяет пользователя (Sk = 1), он прекращает изучение документов (Ej = 0 для j > k). Иначе пользователь переходит к следующему результату. Математически это записывается как:
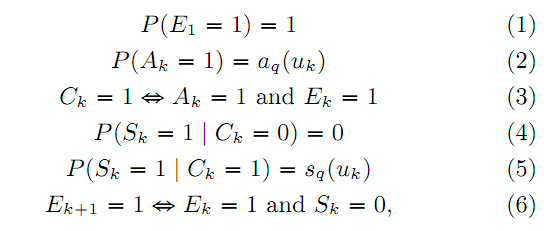
, где aq(uk) – привлекательность сниппета k-ого документа, а sq(uk) – вероятность удовлетворения пользователя k-ым документом. Параметры a и s получаются из кликов по Алгоритму 1 в [1]. Получив эти параметры, мы можем оценить релевантность документа по формуле:
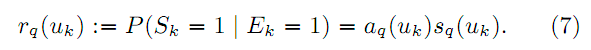
Как было показано в [1, Раздел 4.3] данная предсказанная релевантность может быть скомбинирована со стандартным подходом асессорского оффлайнового обучения ранжированию, чтобы достичь более высокой производительности поиска (сообщается о приросте оценки DCG в 2%). Данная комбинация с предсказанием на основе кликовой модели становится особенно актуальна для низких рангов, так как при использовании K-глубинного объединения [10], низкоранговые результаты могут никогда не показываться асессорам.
За пределами первой страницы выдачи. Наиболее прямолинейным способом расширения кликовой модели за границы первых 10 документов является простое применение модели ко всему списку документов, не только к первым 10. Такая модель косвенным образом допускает, что пользователь всегда кликает на кнопки постраничной навигации, если он не удовлетворён/привлечён хотя бы одним из 10 документов. Далее будем считать это утверждение нашим основным методом.
Первая предложенная нами модель является расширением модели SDBN. Мы вводим важный элемент — ложный «документ» p, соответствующий кнопке постраничной навигации. Ложный документ распространяется на все страницы результатов, а параметры модели для этого документа зависят только от запроса пользователя q. Так как это не настоящий документ, мы определяем иное значение параметров модели: привлекательностьaq(p) ложного документа p моделирует вероятность не-остановки после изучения 10 документов и перехода к следующей странице результатов посредством клика по кнопке постраничной навигации (вероятность продолжения); вероятность удовлетворения sq(p) играет роль «параметра нетерпеливости». Причина добавления «параметра нетерпеливости» такова, что первый документ на второй странице (u11 в нашем случае) будучи единожды показан, получает намного меньше кликов по сравнение с первым документом u1 на первой странице (как минимум в 3 раза меньше по нашим данным). Это может быть обусловлено не только пониженным качеством документа, но так же и понижением доверия результатам после необходимости клика по кнопке навигации: пользователь прекращает изучать поисковые результаты сразу же после перехода к следующей странице результатов. Данный факт так же предполагает, что мы не можем просто применять модель SDBN отдельно к каждой странице результатов. Итоговая модель, которую мы будем называть SDBN(P) отображена на Рисунке 2. Для упрощения, предположим, что на странице результатов показывается всего 3 документа, хотя по-настоящему их 10.
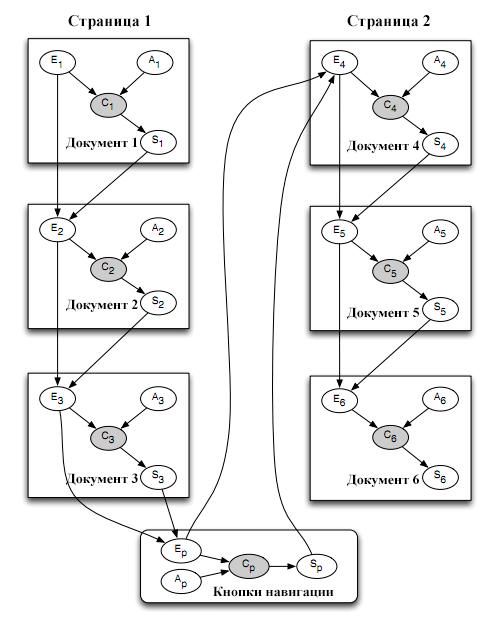
Рисунок 2. Графическое отображение SDBN(P) и SDBN(P-Q); стрелками показаны вероятностные реакции. Вероятности событий Ap и Sp зависят от запроса в SDBN(P) и не зависят от запроса в SDBN(P-Q).
В модели SDBN(P) используются те же уравнения 1-6 как и в SDBN. Вероятность клика по ложному «документу», соответствующему кнопке навигации так же рассмотрена: мы не только поменяли модель, но так же представили дополнительный источник информации. Как и в [7], где авторы использовали информацию о перемещении курсора, чтобы улучшить модель, мы не измеряем, насколько хорош наш прогноз данных дополнительных наблюдаемых событий (кликов по кнопке навигации) – мы только заинтересованы в предсказании кликов по документам и не включаем в расчёт сложности (perplexity) клики навигации (10).
Так же мы представляем вторую модель SDBN(P-Q), которая использует уравнения 1-6 для нормальных документов и 3, 4, 6, 8, 9 для ложного «документа» p, являющегося кнопкой навигации:
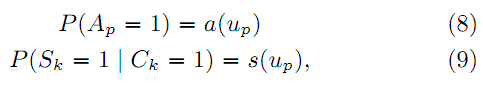
, т.е. мы допускаем, что параметры привлекательности и «удовлетворительности» не зависят от запроса (поэтому в определении SDBN(P-Q) и вписано «минус Q») и являются глобальными константами.
В данном разделе мы сравниваем наши модели SDBN(P) и SDBN(P-Q) с оригинальной моделью SDBN. Для обучения модели использовался Алгоритм 1 из [1]. Затем мы опробовали модели и увидели, как изменяется вероятность кликов по документам вне ТОП-10 в зависимости от настроек. Исходный код нашей реализации доступен по адресу github.com/varepsilon/clickmodels.
Для сравнения кликовых моделей мы используем распространённую меру сложности (perplexity). Доя каждой позиции k документа мы используем:
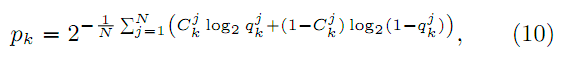
, где Ckj – бинарное значение, соответствующее наблюдаемому клику на k-ой позиции j-ой сессии запроса. qkj – предсказанная вероятность клика на k-ой позиции в j-ой сессии запроса при данных наблюдаемых предыдущих кликах (рассчитанных с использованием уравнений 1-6 для SDBN или соответственных уравнений для других моделей). Чем ниже сложность модели, тем лучше. Сложность идеального предсказания равна 1, а сложность модели случайного броска монеты равна 2.
Мы протестировали модели кликов, проанализировав их способность прогнозировать будущие события. Мы записали сессии запросов, выполненные небольшим числом пользователей поисковой системы Yandex за последние 11 дней в феврале 2013. Было получено 37,163,170 сессий запросов (в среднем 3,378,470 сессий в день). Мы обучили нашу модель используя день k и проверяли её на следующем дне k+1. Средние значения сложности по десяти парам обучения-проверки показаны на Рисунке 3. Вертикальные полоски соответствуют интервалам уверенности, рассчитанным с помощью метода bootstrap [5] с 1000 образцов и степенью уверенности в 95%. Видно, что значения сложности моделей не отличаются для позиций 1-10. Однако легко заметить, что сложность намного ниже у моделей SDBN(P) и SDBN(P-Q) для всех позиций ниже 10-й.
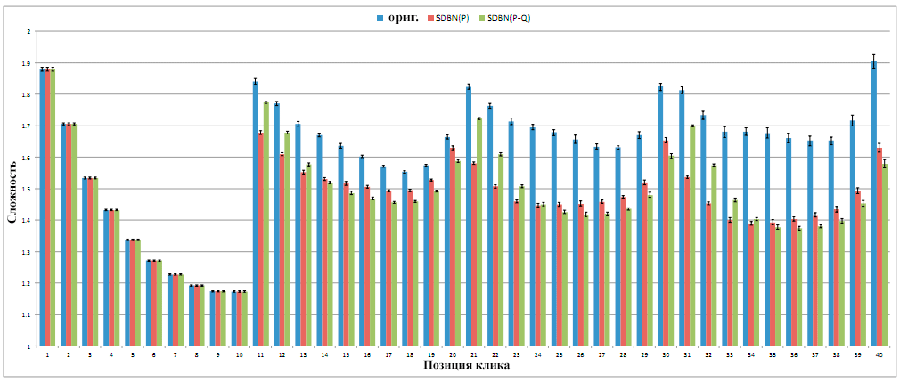
Рисунок 3. Сложность прогнозирования кликов у различных моделей для позиций с 1 по 40
Ещё одним интересным наблюдением является то, что мы больше не наблюдаем постоянно уменьшающуюся сложность для k > 10. Вполне вероятно, что гипотезу «пользователь изучает документы один за другим» стоит пересмотреть для второй и последующих страниц результатов. Мы оставим этот вопрос на рассмотрение в дальнейших исследованиях.
Далее мы выделяем прирост сложности двух новых моделей по сравнению с оригинальной. Если рассчитать среднее значение сложности для позиций 1-40, то модели SDBN(P-Q) и SDBN(P) характеризуются приростом в 20.5% и 20.2%, соответственно.
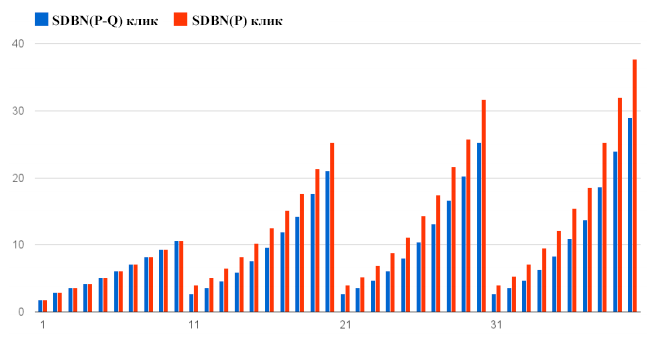
Рисунок 4. Сложность прогнозирования кликовых событий для SDBN(P) и SDBN(P-Q) (ось ординат); ранг документа (ось абсцисс).
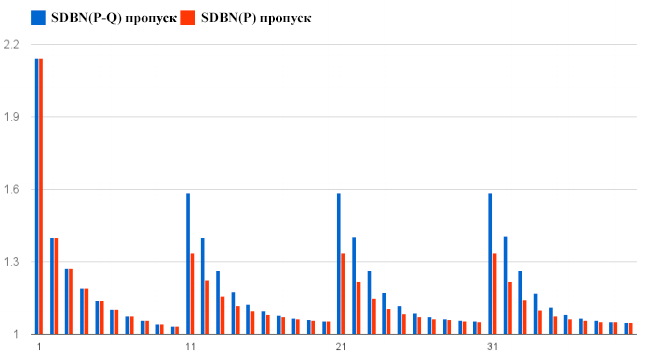
Рисунок 5. Сложность прогнозирования не-кликовых событий для SDBN(P) и SDBN(P-Q) (ось ординат); ранг документа (ось абсцисс).
Аналогично авторам [4] мы так же анализируем сложность прогноза кликов и пропусков (не-кликов) раздельно. Мы рассчитываем pkclick и pkskip с помощью уравнения 10, ограничиваясь равенством Ckj нулю или единице. Соответствующие результаты показаны на Рисунках 4 и 5. Обе модели имеют сложности с предсказанием кликов, но так как кликовые события происходят реже, чем пропуски, общая сложность не так высока. Из этих графиков видно, что SDBN(P) всегда лучше прогнозирует пропуски и хуже – клики.
Возвращаясь к Рисунку 3, можно видеть, что на каждой странице результатов для позиций 20-40 SDBN(P) превосходит SDBN(P-Q) в начале страницы результатов, а SDBN(P-Q) выигрывает у него ближе к концу страницы. Мы считаем, это происходит из-за того, что относительная важность прогноза клика/пропуска различается в разных частях страницы.
Мы изучили смещение кликов на страницах поисковой выдачи. Мы показали, что кликовый паттерн для документов за пределами ТОП-10 отличается от паттерна первых 10 результатов, возвращаемых поисковой системой. Мы представили новые кликовые модели на основе широко используемой модели DBN и показали, что при помощь явного включения кнопок постраничной навигации в модель можно достичь лучших результатов прогнозирования кликов вне первой страницы. Чтобы немедленно применить наши кликовые модели, можно последовать инструкции в [3] для построения более точной оценочной метрики.
Качество прогнозирования кликов по-прежнему невысоко, по сравнению с первой страницей. Можно провести границу между кнопкой «Следующая страница» и кнопками с номером страницы (см. Рис. 1). Наше внутренние изучение логов показало, что менее 10% пользователей используют обе кнопки (из лога, собранного за 1 неделю). Большинство (более 70%) используют номера страниц, меньше 1/3 пользуются кнопкой «Следующая страница». Можно смоделировать эти два события раздельно с целью улучшения производительности.
Наша работа ограничена тем, что мы используем каскадную модель DBN. Так как результаты кликов пользователя обычно показываются в возрастающем порядке [1], клики, нарушающие порядок, гораздо более заметны при анализе кнопок навигации – пользователи часто пропускают следующую страницу результатов или возвращаются к ранее посещённой странице (более 10% пользователей делают это как минимум раз в неделю, что побуждает нас игнорировать до 13% сессий запросов). Было бы интересно детально проанализировать подобные сессии.
Одним из направлений будущей работы является анализ мобильного/планшетного трафика при поиске. Версия страницы поисковых результатов на мобильных устройствах и планшетах отличается от «настольной» как дизайном, так и способом ввода информации. В частности, кнопки навигации могут выглядеть по-другому: иногда кнопки мобильной навигации добавляют новые результаты к концу той же самой страницы выдачи вместо перехода на новую страницу. Было бы интересно проверить работоспособность наших моделей для интерфейсов мобильных и планшетных устройств.
Ещё одним направлением исследований является анализ различных классов запросов и различных пользователей. Обладая какой-либо информацией о запросе и пользователе заранее, мы в дальнейшем можем усовершенствовать модель, корректируя вероятности, относящиеся к кнопкам навигации. Мы можем пойти ещё дальше и сделать все параметры модели зависимыми от пользователя.
Кроме того, стоит исследовать связь кнопок навигации со сменой поисковой системы [9]. Использование кнопок навигации может быть тесно связано с тем, что пользователи меняют свою поисковую систему на иную (возможно, по причине неудовлетворённости результатами, из-за требований к охвату информации и т.д.)
Ссылки:
[1] O. Chapelle and Y. Zhang. A dynamic bayesian network click model for web search ranking. In WWW. ACM, 2009.
[2] A. Chuklin, P. Serdyukov, and M. de Rijke. Using intent information to model user behavior in diversied search. In ECIR, 2013.
[4] G. Dupret and B. Piwowarski. A user browsing model to predict search engine click data from past observations. In SIGIR. ACM, 2008.
[5] B. Efron and R. J. Tibshirani. An Introduction to the Bootstrap. Chapman and Hall/CRC, 1 edition, 1994.
[6] B. Hu, Y. Zhang, W. Chen, G. Wang, and Q. Yang. Characterizing search intent diversity into click models. In WWW, page 17. ACM, 2011.
[7] J. Huang, R. W. White, G. Buscher, and K. Wang. Improving searcher models using mouse cursor activity. In SIGIR, page 195. ACM, 2012.
[8] J. Seo, W. B. Croft, K. H. Kim, and J. H. Lee. Smoothing click counts for aggregated vertical search. Advances in Information Retrieval, 2011.
[9] P. Serdyukov, G. Dupret, and N. Craswell. WSCD2013: workshop on web search click data 2013. In WSDM. ACM, 2013.
[10] K. Spark Jones and C. van Rijsbergen. Information retrieval test collection. J. documentation, 32(1):59-75, 1976.
Материал «Modeling Clicks Beyond the First Result Page» перевел Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации