SEO-Константа
Яндекс.Директ + оптимизация
Накопление и сравнение моделей поведения в Сети предоставляет огромную возможность понимания прошлого поведения пользователей и предсказания будущего. В этой статье мы предпринимаем первый шаг к достижению этой цели. Нами представлено крупномасштабное изучение корреляции поведения пользователей Интернет в различных системах, габариты которых составляют от 27 млн. запросов до 14 млн. записей в блогах и 20,000 новостных статей. Мы ввели модель событий в этих варьирующихся во времени наборах данных и изучим их кросс-корреляцию. Мы также создали интерфейс для анализа наборов данных, включающий новую визуальную разработку DTWRadar, для обобщения различий между временными рядами. Используя этот инструмент мы получили характеристики поведения, которые обладают многообещающим потенциалом предсказания поведенческих моделей.
Несмотря на то, что существует огромное количество исследований поведения пользователей в различных веб-системах, работ по исследованию корреляции этих поведений практически нет. Будь то сёрфинг по Сети, размещение записей в блогах, использование поисковых систем или активность в секторе СМИ, пользователи оставляют признаки своих интересов по всей Сети. В обычное время у людей есть несколько регулярно проверяемых ресурсов, в которых они постоянно заинтересованы (к примеру, кто-то регулярно использует доступ к онлайн-банку), но иногда возникает повышенный интерес к другим сферам, как пиковая реакция на эксклюзивные события или новости, и пользователи уделяют больше внимания свежим и актуальным темам. Эффект этих событий отражается в изменении поведения пользователей, поскольку они массово стремятся найти дополнительную (при этом релевантную) информацию, начинают писать в блоги и коллективно участвовать в каких-либо социальных онлайн-проектах. При этом масштаб реакции и её скорость зависит и от количества пользователей и от их расположения. Реакция буквально может быть проявлена мгновенно в одной области (например, бурный всплеск поисковых запросов в системе), а может и растянуться по времени (например, подготовка и размещение детальной новостной статьи). Цель нашей работы состоит в предсказании и объяснении поведения через понимание того, как, когда и почему вступают различные варианты действий.
Возможность предсказывать и классифицировать поведенческие реакции смогла бы сильно повлиять на многие сферы, начиная с научного анализа социальных феноменов и заканчивая технической оптимизацией поисковых систем. Исследование, описанное в этой работе, отражает наш взгляд на будущее обширного автоматизированного прогнозирования поведения путём обеспечения инфраструктуры и инструментов, требуемых для изучения реакции различных интернет-систем относительно друг друга. И хотя мы пока и не разработали систему автоматизированного предсказания, наши инструменты уже могут отвечать на целенаправленные вопросы о пользователях, к примеру: в какое время посты в блогах изменяют поведение пользователей при поиске? Одинаково ли реагируют пользователи различных поисковых систем на одни и те же новости? Может ли телевизионная трансляция оказывать влияние на поиск?
В этой статье мы разрабатываем модель для оценки силы реакции в различных веб-системах, как структурированных, так и хаотичных, а также механизм сравнения этих реакций с использованием алгоритма Динамического Искажения Времени DTW (Dynamic Time Warping, создан для оценки сходства пары последовательностей, отличающихся по времени или скорости). В дополнение, мы создадим систему визуализации под названием DTWRadar, служащую для поиска и группирования отличий между разными временными рядами. Наши инструменты и алгоритмы создавались в целях количественной оценки и исследования пространства событий под управлением человека, а также для автоматизированного исследовательского анализа. Используя свои инструменты и уникальные наборы данных, мы совершили ряд открытий касательно взаимосвязи поискового поведения с другими поведениям в веб-системах.
Наша работа основана на использовании 6 наборов данных, размеры которых варьируются в пределах от 107 поисковых запросов до миллионов записей в блогах и тысяч голосов на специализированном веб-сайте. Насколько нам известно, это первое крупномасштабное изучение корреляции поведения веб-систем в одном временном интервале.
В разделе 2 мы начнём с обсуждения смежных исследований. Мы продолжим в разделе 3, представив нашу модель данных и затем опишем наборы данных в разделе 4. В разделе 5 мы построим простую модель тем, выходные данные которой используем для первоначального анализа корреляции в разделе 6. Мы покажем, что простая статистика корреляции не всегда является лучшим механизмом сравнения поведенческих наборов данных и введём алгоритм и DTWRadar, базовую визуализацию для более наглядного отображения в разделе 7. Использовав нашу разработку, в разделе 8 мы подведём итоги, рассмотрев обнаруженные открытия о свойствах поведения интернет-пользователей.
Важнейшей особенностью анализа временных рядов является способность к обнаружению трендов и адекватному прогнозированию. Нашему исследованию играет на руку непрерывный интерес сообществ, занимающихся сбором данных по трендам Веба (дата-майнинг) и текстовой информации (см. [5], [10], [24] и более подробно в [11]). Такие системы способны выявлять интересные события, которые могут быть проанализированы и сравнены в различных наборах данных с помощью нашей разработки.
Одним из требований к нашей системе является способность извлекать темы из логов запросов и коллекций текстов. Поскольку в нашей работе мы уделяем внимание, в основном, пользовательскому поведению при поисковых запросах, то мы использовали алгоритмы, схожие с [26]. Однако уже существует множество работ по извлечению тем из коллекций документов ([2],[12]). Они могут быть полезны в нашей дальнейшей работе, когда мы начнём использовать источник текстовой информации для автоматической генерации тем интереса и сравнивать их с помощью наших методов.
В плане предсказания влияния одного источника данных на другой существуют работы, нацеленные на узкоспециализированное применение, к примеру: предсказание поведения при покупке товаров [6], влияние опубликованного текста на цены акций [12], а также уровни интереса к веб-страницам, основывающиеся на появлении (и исчезновении) ссылок [1]. Эти системы довольно близки к нашему направлению исследований, поскольку часто используют автоматическую привязку документов к событиям.
Поскольку мы хотим поддерживать целевой анализ данных (а не просто автоматический дата-майнинг), то мы также заинтересованы в обеспечении пользователей визуальным представлением данных, которое может быть легко воспринято с первого взгляда. И хотя существует несколько систем визуализации временных рядов ([7], [13], [23],[25]), среди них гораздо меньше систем, поддерживающих визуальные сводки ([13], [23], [25]), и вообще нет таких, которые обеспечивали бы визуализацию различий наборов данных. По этой причине DTWRadar может быть актуален и в других работах, где требуется сравнение временных рядов.
Понятие запроса мы используем в общепринятом смысле, относящемся к набору слов, введённому в поисковую систему (например, «продвижение сайтов«). Под темой мы понимаем широкий набор связанных между собой запросов (например, {продвижение сайтов, продвижение сайтов в спб, сео раскрутка, и т.д.}). Для простоты мы будем называть каждую тему по её наиболее высокочастотному запросу.
Каждый набор данных составлен из событий, которые мы представляем как математический кортеж (упорядоченный конечный набор элементов с длиной n), имеющий вид <текст, вес, время, набор данных>. Для двух наборов данных логов запросов, текст – это обычная строка запроса. Для наборов данных BLOG, NEWS и TV текст – это содержимое блога, новостной статьи или веб-страницы, соответственно. В общем случае, первоначальное значение веса, присвоенное каждому кортежу, равняется 1. Но поскольку каждый набор данных содержит большое количество кортежей, мы разделяем множественные кортежи в определённом временном интервале (1 час является минимальным интервалом), которые имеют идентичные запросы и содержатся в одном наборе данных. Значение время в каждом кортеже является целочисленной переменной, изменяющейся от первого часа мая hour0 до последнего часа hour755. Например, мы представим 10 запросов «george bush», появляющиеся за первый час в наборе данных MSN в виде <”george bush”, 10, hour0, MSN>. Разделение уменьшит возможный интервал времени (например, разделение на периоды по 24 часа даст промежуток времени day0…day31). Заметим, что поскольку разные часы имеют характеризуются разной активностью, в общем случае мы нормализуем вес пропорционально активности. То есть, если за первый час было 1432 запроса, наш предыдущий кортеж принял бы вид <”george bush”, 10/1432≈ .007, hour0, MSN >. Наконец, для простоты мы сгенерируем нуль-кортежи (кортежи с нулевым весом) для периодов, в которых не наблюдалось данное событие/запрос. Это позволит нам легко преобразовать множество кортежей во временные ряды.
Отфильтровав набор данных по запросу и источнику, и упорядочив его по времени, мы получим базовую единицу анализа: временные ряды, которые мы назовём ряд запрос-событие (query-event-series, QESdataset-query). Например, QESMSN-american idol представляет все кортежи, для которых текст = ”american idol”, а набор данных = ”MSN”. Заметим, что для других наборов данных QESX-american idol представляет все записи блогов, новостные статьи и др., содержащие фразу ”americal idol”. Каждая QES является временным рядом с кривой характеристики, где ось абсцисс представляет время, а по ординате откладывается вес. Для простоты будем считать, что QESq,q(i) возвращает вес в момент времени i. Наконец, ряд тема-событие (topic-event-series, TESdataset-{queries}) – это комбинация всех случаев QES, представляющих запрос в {queries} (их генерация описана в разделе 5).
Для достижения цели исследования – понять как коррелируют различные варьирующиеся во времени поведения, мы воспользуемся 6-ю наборами данных. Каждый набор данных представляет собой лог интересов пользователей по разным темам в разных системах. Наши наборы данных составлены из логов запросов и кликов пользователей MSN и AOL, записей в блогах, новостных статей CNN и BBC, а также записей о телевизионных передачах на TV.com.
Основной набор данных, использованный в данном исследовании, является отрывком лога за 1-31 мая 2006 года из поисковой системы MSN [15]. Лог содержит 7,47 млн. сессий, содержащих 15 млн. запросов и кликов. Несмотря на то, что мы не обладаем полной информацией о способе сбора данных, считается, что логи являются случайным набором сессий (продолжительных браузерных сессий, отслеживаемых с помощью cookie). Для совместимости с набором данных AOL, описанным ниже, мы нормализуем следы путём «прерывания» сессии, когда пользователь не проявлял активность более часа. Результатом стало 7,51 млн. обработанных сессий за период. Вместо скрупулёзной установки реальных границ сессии нашей целью является устранение излишка пользователей, которые повторяют те же запросы за короткий период времени или бегло просматривают несколько страниц результатов (хотя очевидно, что могут быть применены иные границы сессий [16]). Для уменьшения требований к памяти, кортежи генерировались раздельно для каждого часа с весом, нормализованным по общему числу запросов, сделанных за этот период.
Второй набор данных был извлечён из логов запросов AOL [19]. Отрывок представляет собой поведение 484 тыс. пользователей, сгенерировавших 12,2 млн. запросов за рассматриваемый период (1-31 мая). Как и выше, набор данных AOL был нормализован «прерыванием» долгих сессий до чётких границ, заданных 1 часом неактивности (что дало 2,6 млн. сессий за период).
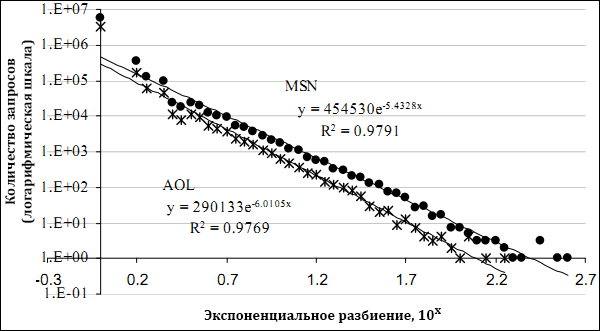
Рисунок 1. Распределение запросов логов MSN и AOL (лог-лог).
Хотя «прерывание» сессий данным образом является попыткой нормализовать два лога запросов, заметно, что этот способ фильтрации приводит к иному распределению популярности запросов. Поскольку пользователи имеют известную предрасположенность к повторному набору запросов, уже введённых ими ранее [21], существует вероятность искажения характеристики в наборе данных AOL по причине существенно меньшего числа уникальных запросов. Например, несмотря на то, что количество сессий в AOL втрое меньше, чем в MSN, он, тем не менее, генерирует приблизительно такое же число запросов. И хотя распределения рекуррентности запросов похожи (см. рис. 1), существует количественная разница (почти вдвое) уникальных пар сессия-запрос в наборе MSN (6,6 млн. и 3,7 млн.). И хотя это разница может быть вызвана некой отличительной чертой пользователей MSN и AOL, она так же может служить индикатором, что повторная выборка из того же набора пользователей не обеспечивает полный спектр вариантов запросов, обнаруженных случайной выборкой. Вследствие этого, темы, обнаруженные в выборке AOL потенциально могут не являться выборкой, отражающей основной интерес по данной теме.
Несмотря на это, мы видим, что наборы данных и AOL и MSN имеют общий запрос на 1-й позиции («google») и имеют 80%-ное совпадение первой десятки запросов. После 10-го запроса процент совпадений падает до ~66% и стабильно держится на этой отметке в течение первых 50 тыс. ранжированных запросов. Такое большая доля совпадений серьёзно помогает в сравнении двух наборов данных, по крайней мере, по некоторым запросам. Последствия этого совпадения рассматриваются ниже.
Выборке AOL сопутствовала ещё одна проблема: отсутствовали данные за небольшой временной промежуток (примерно 22 часа) 16 мая. Очевидно, что нельзя просто исключить из анализа данные за этот период, поскольку тогда будет наличествовать временной сдвиг, отсутствующий в других наборах данных. Мы рассматривали три варианта: присвоить данным в этом периоде нулевое значение, «пропатчить» данные, заменив этот период средними значениями между двумя конечными точками или же воспользоваться методом линейной экстраполяции. Мы обнаружили, что результаты всех трёх вариантов создают примерно одинаковые уровни корреляции. Мы считаем, что единственный случай, когда будет невозможно вычислить точную корреляцию, – это когда существует единичный пик (выделяющаяся «свечка» на графике) в поведении запросов, который значительно совпадает с отсутствующим периодом времени (считая, что такие пики с коротким сроком жизни распределяются равномерно, мы бы получили ошибочную корреляцию примерно 3% тем).
В дополнение к двух логам запросов, мы также использовали базу данных из 14 млн. записей в 3 млн. блогах за 1-24 мая 2006 года [18]. И хотя каждый пост имел таймштамп, не было указано какой-либо временной зоны. Вручную проверив ленты блогосервисов (таких как Blogspot, LiveJournal, Xanga и др.), нам удалось добавить корректные временные зоны к некоторым записям. Однако, поскольку многие из оставшихся постов размещались в популярных блогах, которые проверить не удалось, мы приняли решение распределить записи в блогах на суточные интервалы (24 часа).
Мы предположили, что на поведение блоггеров и пользователей поисковых систем зачастую оказывают влияние новости. Для проверки этой гипотезы мы сгенерировали набор данных новостей путём краулинга сайтов CNN.com и BBC.co.uk с целью поиска документов за период с 1 по 31 мая. Мы выбрали эти два источника, поскольку они позволяли нам получать новости автоматически, а статьи содержали нормализованные (по Гринвичу) временные метки. Нам удалось скачать более 12 тыс. статей с BBC за интересующий нас период, и примерно 950 статей с CNN (многие статьи CNN были получены от агентства Рейтер и более недоступны онлайн).
В идеале, мы хотели бы использовать максимальное число доступных новостных источников, чтобы определить популярность конкретных тем в разное время. Однако, поскольку многие источники закрывают доступ к своим базам данных по прошествии 7 дней, нам было сложно найти дополнительные статьи за выбранный период времени. Так как CNN и BBC чаще всего публикуют лишь одну статью по выбранной теме, большинство тем не обладает достаточным количеством признаков для адекватного анализа (например, каждый QES содержит только один кортеж, который имеет вес 1). С целью назначения более точных весов мы ввели модификацию, которая определяет уровень заинтересованности внешних источников в определённых статьях. К примеру, небинарной приблизительной характеристикой популярности можно считать число входящих ссылок на конкретную статью. Чтобы его узнать, мы воспользовались поиском MSN для обнаружения всех внешних (кроме CNN и BBC) ссылок на статьи. По утверждению в примере, мы присвоили каждому кортежу вес, равный количеству входящих ссылок. Этот поток событий мы назвали NEWS. Поскольку все статьи имеют временные штампы, набор данных новостей может быть сгруппирован почасово и нормализован по количеству входящих ссылок ко всем статьям за каждый час.
Хотя вышеописанный перерасчёт веса даёт нам некоторую информацию об интересе к событиям (полезную саму по себе), он, однако, не показывает изменений уровня интереса к теме. Путём добавления веса на основе интереса в момент публикации статьи, мы просто увеличиваем его на 1 пункт. Но в действительности интерес к теме, то есть и популярность статьи, изменяется со временем по мере добавления ссылок. Для имитации этого процесса мы опять используем набор данных BLOG и подсчитываем количество ежедневно появляющихся ссылок на данную статью в постах. Проще интерпретировать это как распределение общего числа входящих ссылок с блогов, т.е. кортеж ежедневно обновляет свой вес, приравнивая его к числу входящих ссылок. Назовём этот набор данных BLOG-NEWS, поскольку он даёт нам представление об интересе пользователей к теме, основываясь на уровнях интереса блоггеров. Из-за разбиения анализа (по 24 часа) и конечности анализируемой выборки BLOG (данные всего за 24 дня), разбиение BLOG-NEWS происходит на дневном уровне, с данными только до 24 мая.
Некоторые из самых популярных запросов в наборе данных MSN оказались нацеленными на поиск информации о ТВ шоу, актёрах и актрисах. Поэтому весьма вероятно, что трансляция определённого шоу может спровоцировать всплеск активности запросов, в зависимости от силы ожидания до нового выпуска передачи или реакции пользователей непосредственно после вещания. Подобным образом варьируется и интерес к актёрам и актрисам, в зависимости от популярности шоу. Чтобы проверить это, мы проиндексировали все эпизоды шоу, транслировавшихся в мае 2006 года на сайте TV.com. Данный сайт был выбран по причине того, что он является самым популярным ресурсом обсуждения ТВ-шоу и содержит подробную информацию об актёрском составе, описание всех эпизодов и пользовательские рейтинги. В процессе краулинга было найдено 2547 разных шоу за данный период, по 2 страницы о каждом (аннотация и расширенное описание). Поскольку мы хотели бы, чтобы «вес» события давал представление об аудитории, мы вычисляли это значение по числу голосов, полученных эпизодами на сайте (в целях нормализации каждому сайту был присвоен минимум силы в 1 голос). Поскольку определённое шоу может вещаться несколько раз, в разное время, страницы из данного набора данных были отмечены днём первой трансляции и разделены на интервалы по 24 часа.
Наборы данных BLOG, NEWS, и TV были проиндексированы в Lucene (lucene.apache.org) для простоты доступа к данным. Таблица 1 описывает полученные наборы данных.
| Имя набора данных | Временной интервал | Разбиение (в часах) | Данные источника | Весовая схема |
|---|---|---|---|---|
| MSN | Май 1-31 | 1 | 7.51 млн. поисковых сессий | Число сеансов поиска на единицу времени |
| AOL | Май 1-31 | 1 | 2.6 млн. поисковых сессий | Число сеансов поиска на единицу времени |
| BLOG | Май 1-24 | 24 | 14 млн. постов, 3 млн. блогов | Посты на единицу времени |
| NEWS | Май 1-31 | 1 | 13 тыс. новостных статей | Все входящие ссылки |
| BLOG-NEWS | Май 1-24 | 24 | 13 тыс. новостных статей | Входящие ссылки с блогов на единицу времени |
| TV | Май 1-31 | 24 | 2547 ТВ-шоу | Голоса |
Таблица 1. Использованные наборы данных.
Одним из ещё не рассмотренных вопросов является непосредственно принцип генерации тем. Поскольку наш основной интерес заключается в изучении взаимного влияния поведения при запросе с прочими поведениями, то мы хотели бы объединить наборы запросов в связанные группы. Существует множество работ по обнаружению темы и в потоках данных и в коллекциях неизменного текста [2]. Хотя все эти методы дают хорошие результаты, мы обнаружили одну простую, но полезную схему, связанную с [26], которая генерирует множества запросов, сгруппированных как «темы». Вкратце: алгоритм создаёт иерархическую систему кластеров из запросов, основываясь на пересекающихся кликах и коллекциях результатов поисковых систем.
Наш первоначальный набор данных включает в себя 963,320 уникальных запросов, появлявшихся два или более раз в логах MSN и AOL (нормализованных по нижнему регистру). Они представляют собой множество потенциальных запросов, которые мы можем объединить в темы. Каждый запрос был введён в MSN, после чего было возвращено до 50 результатов. По каждому запросу мы также приняли во внимание наиболее часто кликаемые результаты. В случае с логами AOL, где записывался только домен клика, мы нашли максимально полные URL, сравнив домены кликов с возвращёнными результатами MSN. Без особых трудностей мы определили полные ссылки для ~40% собранных «популярных» кликов. Каждый запрос затем связывался с выборкой URL, составленной из проходных ссылок и максимум с 10 самыми популярными кликами в поисковой системе. Эта выборка затем была преобразована во взвешенный вектор с помощью стандартной TF-IDF схемы [3], где каждая из 6,908,955 URL (являющаяся «словом», частота которого подсчитывается в «документе»), была взвешена по числу раз, когда она была возвращена в ответ на запрос (т.е. здесь запрос рассматривается как «документ» в схеме TF-IDF). Как побочный эффект учёта проходных кликов, стоит отметить, что на результаты оказывал влияние порядок «слов».
Попарное сравнение 963,320 запросов – при использовании стандартной косинусной метрики расстояний [3] – дало в результате 1,332,470 ненулевых рёбер. Ребро отражает сходство двух запросов и используется при создании кластеров наших запросов для последующего анализа.
Чтобы создать начальную коллекцию потенциальных тем для изучения, мы начали с поиска всех запросов, которые появляются 100 или более раз в логах MSN (мы считаем, что они немного лучше отражают поведение углублённого поиска, чем логи AOL из-за способа создания выборки, описанного в 4.2). Итоговые 5733 запроса были упорядочены по частотности. Начиная с самого популярного запроса, мы генерируем список всех релевантных ему запросов путём перехода по рёбрам, описанным выше (шаг 1). Эти запросы-соседи «назначаются» исходному запросу в качестве его альтернативных формулировок. По мере продвижения вглубь списка из 5733 запросов игнорируются низкочастотные экземпляры, которые уже были назначены какому-либо запросу ранее. В итоге был получен список в 3771 единиц главных запросов (то есть тем), имеющих в среднем 16,2 альтернативных формулировки. Заметим, что использованные запросы появляются в различных выборках в 96% случаев и никак не идентифицируют уникальных пользователей.
Анализируя набор данных, мы обнаружили, что многие альтернативные варианты имели опечатки, различия в порядке слов и лишние пробелы. И хотя мы ещё не наблюдали этого в эксперименте, наш подход склоняется к иному взвешиванию QES в случае с генерацией комбинированной TES для исходного запроса. Получается, что вес, присвоенный запросу QES, может быть получен пропорционально сходства данного запроса с исходным.
Что же до сгенерированных тем, то некоторые из них
оказались навигационными запросами корпоративных сайтов (например, для «amazon» , QESMSN/AOL =
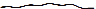 1,
а для «bank of america»
1,
а для «bank of america»
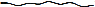 ), а другие запрашивали
поисковые системы и источники информации («white pages»
), а другие запрашивали
поисковые системы и источники информации («white pages»
 и «weather»
и «weather»
 ). Однако,
эта коллекция также содержит различные запросы, связанные с внешними событиями.
Среди них встречаются такие запросы как, например, всегда популярный «american idol»
). Однако,
эта коллекция также содержит различные запросы, связанные с внешними событиями.
Среди них встречаются такие запросы как, например, всегда популярный «american idol»
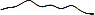 , запросы
по празднику «cinco de mayo»
, запросы
по празднику «cinco de mayo»
 (5 мая) и запросы, относящиеся к
людям и событиям из новостей, например, «uss oriskany»,
(5 мая) и запросы, относящиеся к
людям и событиям из новостей, например, «uss oriskany»,
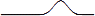 , военный корабль США, потонувший в конце мая.
, военный корабль США, потонувший в конце мая.
Высокая тематическая вариативность вдохновила нас тем, что в выборке были как запросы, от которых не ожидалось интересных корреляций, так и запросы с высокой корреляцией событий.
1 Мы используем искрографику (англ. sparklines, букв. черта искры) [22]
для иллюстрации поведения различных QES. Кривая является просто графическим отображением временных рядов,
где по оси абсцисс откладывается время кортежа, а по оси ординат – вес. Наглядный
пример для сравнения: обычный график выглядит как 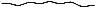 , а график, богатый
событиями, выглядит как
, а график, богатый
событиями, выглядит как  .
.
Существует несколько разных параметров, которые следует учитывать при сравнении наборов данных. Эти параметры влияют на эффективность корреляций и требуют настройки и тестирования в разных комбинациях. В наличии 756 одночасовых секторов из анализируемого интервала и необходимо продумать процесс сравнения в различных уровнях разбиения. Такую возможность обеспечивает разделяющий параметр b (напоминаем, что наборы данных разделены на отрезки длиной по 24 часа, и для них b должен быть ≥ 24). Как описывалось выше, разделение уменьшает количество событийных кортежей в каждом QES, создавая новый кортеж с комбинированным весом кортежей за данный период. Хотя разбиение несколько «смазывает» данные, всё равно наличествует некоторый шум в вариациях между отрезками. В целях уменьшения шума, мы применим Гауссово размытие, описываемое функцией:
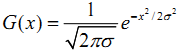
Определив кернфункцию Гаусса по каждому QES или TES, мы можем устранить большую часть шума. Наши эксперименты и инструменты поддерживают произвольные уровни σ. В будущих исследованиях стоит уделить внимание таким техникам сглаживания, которые более точно отображают визуальные характеристики оригинальной кривой [27].
Мы использовали экспериментальные темы, описанные в разделе 5, чтобы создать набор TES для различных пар тема/набор данных. Для коллекций логов требовалось просто нахождение всех запросов, которые совпадали с одним из запросов, определённых темой. Чтобы сгенерировать TES для остальных наборов данных, мы пропустили каждый запрос по библиотеке Lucene. И хотя первоначально мы разрешили булевы запросы (имитируя поведение большинства поисковых систем), некоторые запросы дали крайне низкую релевантность. Вместо использования произвольного эвристического порога для отсеивания результатов, мы попытались преобразовать булевы запросы во фразовые. Поэтому запрос «britney spears» подразумевал, что оба слова должны появляться вместе. Запросы, которые действовали в качестве стоп-слов («blog», «www») и совпадали с большим количеством документов, были отброшены (200 или более из наборов NEWS, BLOG-NEWS и TV, и 25000 из набора BLOG).
Поскольку не все темы существуют во всех базах данных исходных 3781 тем, нам удалось сгенерировать 3638 (96% пересечение), 3627 (96%), 1975 (52%), 1704 (45%) TES для наборов AOL, BLOG, NEWS, BLOG-NEWS и TV, соответственно.
Чтобы увидеть, сколько из TES отражали случайное внутреннее поведение, мы взяли все TES, сгенерированные выше, с общим весом более 10 (то есть более 10 поисковых запросов по теме, 10 записей в блогах и т. п.). Тест на частичную (круговую) автокорреляцию с уровнем точности .05 показал, что 983 (~8%) из всех 12324 были сочтены случайными (b = 24, σ = 0.5). Хотя мы не делали расширенный анализ содержимого случайных TES, общее сканирование тем показало, что они состоят из имён компаний, веб-сайтов и запросов взрослой тематики.
Чтобы найти корреляцию между двумя временными рядами (x и y), мы воспользуемся функцией поиска взаимной корреляции:
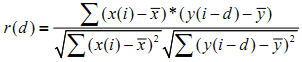
, где переменная d – это задержка, лежащая в пределах от -length(x) до +length(x). Она представляет возможный сдвиг одной кривой от другой к каждому экстремуму (до и после, без пересечения). Хотя мы не хотим устанавливать произвольные пороги совпадений, при использовании правильной модели такой порог может ограничить d до меньшего промежутка. Максимальное значение r – это «лучшая» корреляция двух функций, значение d в такой точке – «наилучшая» подходящая задержка между двумя функциями. Мы исключаем нуль не-корреляции, применяя симуляцию Monte Carlo, которая случайно меняет порядок одного из временных рядов и повторно находит взаимную корреляцию. Повторно генерируя максимальные значения взаимных корреляций, меньшие чем нерандомизированные временные ряды, мы можем исключить гипотезу о некорреляции.
Хотя в этой статье мы концентрируемся на корреляции между источниками, (то есть TESsource 1-topic 1 и TESsource 2-topic 1), нет причин считать, что такой анализ не может быть применён к разным темам в одном источнике. Например, сместив две TES (к примеру, относящиеся к датам выхода фильмов), мы можем сравнить реакцию на два разных фильма в одном источнике (то есть TESBLOG-x-men против TESBLOG-superman).
Наша рабочая гипотеза состоит в том, что если событие влияет на набор данных, то и все связанные темы получат положительные изменения в весе. Хотя реакции могут быть смещены, маловероятно, что новостное событие уменьшит поиск при увеличении блоггинга (или наоборот), поэтому мы не ожидаем случаев, когда негативно коррелирующие поведения могут соответствовать правильным отображениям. Фактически, при ручной оценке результатов и выборе положительных величин каждой корреляции мы обнаружили, что если максимум соответствует негативной корреляции, то тема не отвечает никакому из реальных событий. Темы такого типа являются обычными запросами по именам компаний («home depot» или «expedia») или сайтам («nick.com» или «myspace.com») и не являются реакциями на события. Из-за этого мы ограничились лишь максимальными положительными корреляциями.
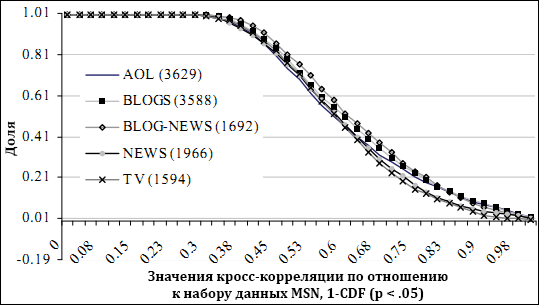
Рисунок 2. Значения взаимной корреляции всех TES в сравнении с эквивалентными им TES в MSN, значение y на соответствующем x являет собой тот процент TES, для которых корреляция ≥ x.
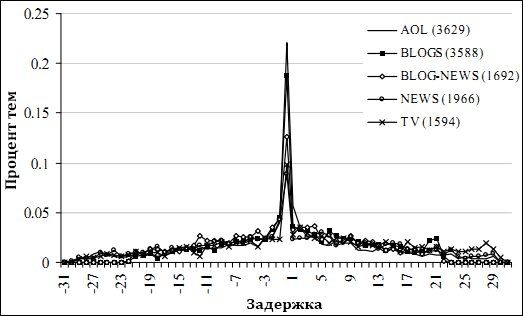
Рисунок 3. Распределение задержек (в днях) всех TES в сравнении с эквивалентными им в MSN, p < .05.
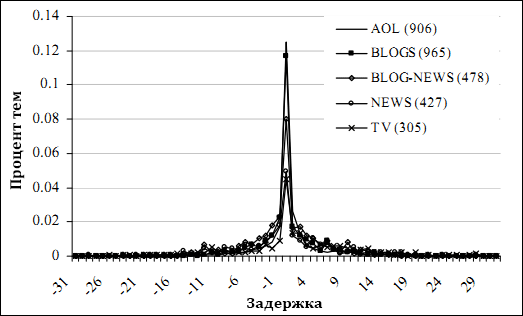
Рисунок 4. Распределение задержек (в днях) всех TES с корреляцией ≥ 0.7 в сравнении с эквивалентными им в MSN.
Рисунок 2 представляет распределение всех значимых корреляций, найденных при сравнении всех TES в наборе MSN с каждой из их противоположностей в других наборах данных (отрезки в 24 часа, σ = 2). Точка отсечения значимости была определена формулой ± z1-α/2 / N1/2, где z – процентная точечная функция стандартного нормального распределения, α – уровень важности, N – количество «экземпляров» (в большинстве случаев вдвое больше длины временных рядов). Промежуток, на котором найдены эти корреляции, показан на рисунке 3. Рисунок 4 показывает распределение только тех TES, для которых взаимная корреляция была ≥ 0.7 (превосходя уровни важности p <0.05). В среднем 38% задержек сконцентрированы на 0 дней. Что интересно, высококоррелирующие TES смещены от 0. Если эти смещения постоянны, темы в этом классе могут быть потенциально полезны для предсказаний. Однако, существует множество коррелирующих TES, которые являются не одиночными пиками, а систематически повторяющимися, потенциально демонстрирующими реакцию на какие-либо события (еженедельные TV шоу). Хотя может быть оптимальная задержка, что определено максимальной корреляцией для выравнивания двух TES, каждый пик в периодическом поведении может не всегда вести или отставать одинаковым образом.
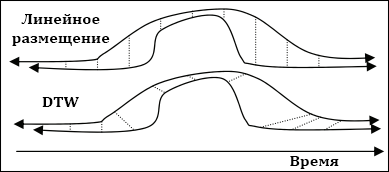
Одним из ограничений простого смещения двух коррелирующих QES является сложность в выяснении того, как один поток относится к другому в плане важности. Представим, к примеру, две коррелирующие кривые как на рисунке 5, где одна инкапсулирует другую. Разница в важности отображена количеством вертикальных линий в верхнем графике. И хотя она является правдоподобным размещением между двумя временными отрезками, она не демонстрирует разницу в интерпретации. Нижние отрезки являются просто меньшей версией верхнего, уплотнённой и по времени и по важности. Поэтому различное размещение – это то, которое охватывает эти свойства поведения, располагая изгиб точек и поведения соответственно друг другу, то есть повышение в первой кривой и повышение во второй, от вершины к вершине, от спуска к спуску и т. д., как изображено на рисунке 5.
Рисунок 5. Демонстрация DTW.
Достичь этого можно, использовав динамическое искажение времени (Dynamic Time Warping (DTW)) [16]. Существует несколько версий алгоритма, и вот одна из них, использующая подход с применением динамического программирования:
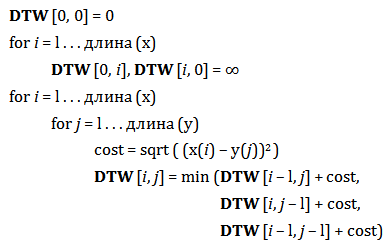
После исполнения алгоритма, двумерный массив DTW содержит размещение между двумя временными сериями. Начав с крайнего угла массива, и проходя обратно вдоль минимального градиента, мы находим наилучший путь искажения. Поэкспериментировав с алгоритмом, мы обнаружили, что альтернативные версии функции минимизации (cost function), включающие время и важность, работают не так надёжно из-за восприимчивости этой функции к масштабированию. Также мы обнаружили, что в общем случае результаты были более точными при использовании метода Sakoe-Chuba [20], который ограничивает путь искажения до фиксированного расстояния от диагонали массива DTW. Эта техника уменьшает нереалистичное искажение путей, которые отображают отдалённые события, с помощью ограничения максимальной задержки.
Ещё одним изменением, которое мы сочли полезным, оказалось использование задержки взаимной корреляции в качестве смещения перед вычислением DTW. То есть, если взаимная корреляция была максимальной на dmax, мы сдвигали одну кривую на это значение перед вычислением пути искажения, а затем сдвигали искажение обратно на ту же величину.
Наконец отметим, что алгоритм DTW, каким он представлен, генерирует «оптимальное» размещение от последовательности x до последовательности y из-за порядка, в котором он генерирует массив. Однако такое размещение может не быть оптимальным при работе от y к x. Чтобы исправить это, мы вычисляем DTW дважды, меняя порядок вводимых значений, и находим те размещения искажений, которые являются общими для обоих направлений.
Чтобы позволить пользователям наглядно увидеть отношение QES к TES из разных источников, мы создали приложение, называемое DTWExplorer. Его скриншот изображён на рисунке 6 с результатом работы по запросу «lost» (популярный телевизионный сериал с отрезками времени 24 часа и σ = 2). Отметим недельные колебания вокруг времени вещания шоу и большой подъём под конец сезона.
Рисунок 6. DTWExplorer (единица
масштабирования времени – день).
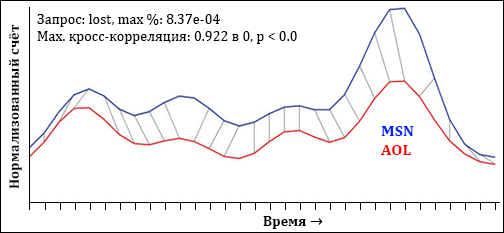
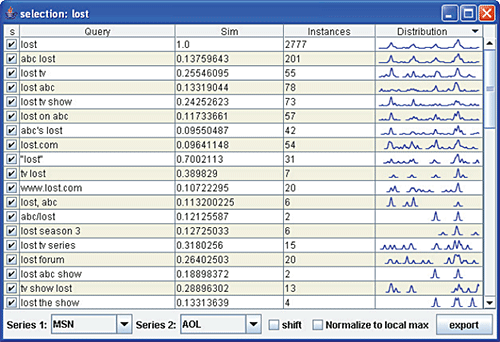
Рисунок 6. DTWExplorer (единица масштабирования времени – день).
При использовании DTWExplorer, пользователь вводит базовый запрос в систему, которая выводит список похожих запросов, из которых будет составлена тема. Они отображаются в таблице примерно так же, как на втором скриншоте рис. 6. Первый столбец показывает, будут ли события, подходящие под данный запрос, включены в анализ. Второй столбец показывает сами запросы, похожесть которых отображена в третьем столбце и основана на косинусоидой метрике, описанной ранее. Четвёртый столбец отображает количество событий определённого типа за интересующий нас период, и последний столбец содержит искрографики [22], показывающие совокупное поведение QES этого запроса в логах MSN и AOL. Сортировка возможна в любом столбце. В изображённом примере мы сделали сортировку по временному поведению (столбец «distribution»), которая проводится поиском взаимных корреляций каждого промежутка и базового запроса. При такой сортировке верхние запросы имеют очень похожее распределение во времени. Это было взято из работы [4], где семантическое сходство было определено корреляциями временных промежутков. Экран слева показывает выходные данные DTW по выбранным вариантам запросов. Тонкие линии, соединяющие две кривые, показывают наилучшее размещение (mapping) DTW. Заметим, что наше приложение поддерживает поиск по всем индексированным запросам, а не только по маленькому, с высокой частотой, примеру.
Приложение DTWExplorer поддерживает сравнение конкретных потоков сгенерированных временных промежутков с различной периодичностью (единичные, еженедельные, двухнедельные и т.п.).
В то время как пути искажения (warp paths), сгенерированные алгоритмом DTW, полезны для понимания изменяющегося поведения в течение времени, они не всегда дают представление о разнице между двумя промежутками. В идеале, нам нужна суммарная статистика или визуализация, которая описывает общее поведение двух промежутков относительно друг друга.
Чтобы достичь этого, мы ввели DTWRadar. DTWRadar – это визуальная конструкция, которая берёт каждый вектор искажения, созданный алгоритмом DTW, и помещает его в нормализованную систему координат (см. рис. 7). Возьмём временные промежутки T1 и T2, а также размещение искажений между ними (от точки a к 1, от точки b к 2 и т. д.). Мы создаём радарный вид, перемещая двухмерную систему координат вдоль одного из временных промежутков (к примеру, T1) слева направо. Когда серая ось попадает на размещённую точку на T1, мы отмечаем на радаре положение соответствующей ей точки на T2. Результат этого движения изображён на верху рисунка 7. Заметим 4 прозрачные точки на радаре и пятую, тёмную, точку, являющуюся их центроидом.
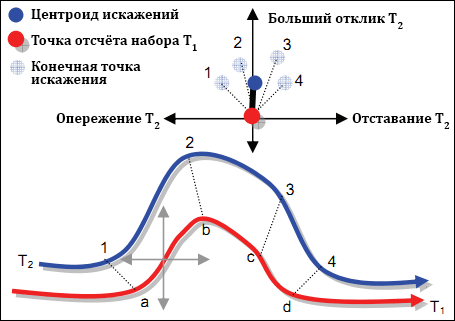
Рисунок 7. Графическое представление содержимого DTWRadar.
Чтобы понять радар, нужно просто посмотреть на расположение центроида относительно начала координат. В этом примере мы видим, что T2 имеет больший отклик (выше по оси y). Также мы видим маленькое отставание, т. к. центроид расположен немного правее по оси x. Если бы два временных промежутка представляли число запросов по какой-либо теме X в двух поисковых системах (QES1-X и QES2-X), то можно было бы сказать, что «поисковых запросов больше в поисковой системе T2, но они немного отстают». Заметим, что координатная система DTWRadar отображается прямо на один из временных промежутков. Поэтому этот вид позволяет нам узнать среднее опережение или отставание во времени по положению центроида относительно оси x и разницу важностей по положению относительно y. Оставив на радаре прозрачные точки, мы позволяем пользователю понять распределение искажения (то есть важность T2 постоянно выше, чем T1, но различается в плане опережения/отставания). Заметим также, что выходными данными алгоритма являются пары точек, каждая из которых представляет временные промежутки. Как мы покажем далее, эти точки полезны для кластеризации поведенчески связанных запросов и тем.
Мы обнаружили, что после объяснения этой интерпретации пользователям, они способны легко её понимать. Такая интерпретация комбинирует большое количество данных в компактном пространстве и генерирует много маленьких множеств и значительно упрощает сравнение взаимосвязей. Мы расширили DTWExplorer таким образом, чтоб он автоматически генерировал масштабированную версию DTWRadar для каждой пары вычисляемых промежутков. Рисунок 8 показывает этот процесс для QESBLOG-prison break и QESMSN-prison break (b = 24, σ = 2).
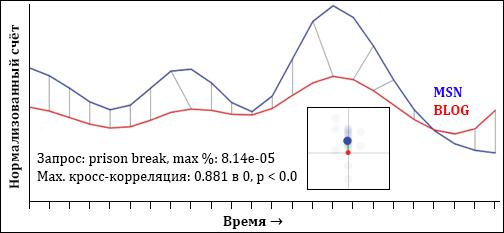
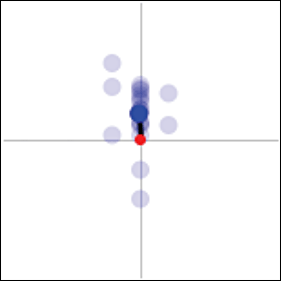
Рисунок 8. Выходные данные DTWExplorer и наложенный DTWRadar по запросу сериала «prison break» (масштабирование по дням, ниже – увеличенный вид радара).
Очевидно, есть большое количество возможных вариантов DTWRadar, которые могут улучшить понимание различных свойств. К примеру, хотя мы убрали тёмные отметки из обзора, поскольку обычно они дают много шума в масштабированных версиях, их можно добавить вновь.
Также мы поэкспериментировали с разными конфигурациями центроидов «средних» точек на радаре. Из наших опытов стало видно, что самый полезный выбор этой точки зависит от распределения индивидуальных точек искажения. Одна точка искажения, выбранная правильно или неправильно, может сильно повлиять на расположение центроида. На данный момент интерфейс обозревателя поддерживает оба типа. Ещё один возможный радарный вид – придающий больший вес поздним отображениям, а ранним – меньший. Графически это будет показано увеличением прозрачности отображённых точек и средним весом «центроида».
Мы считаем, что DTWRadar достаточно гибок для поддержки визуализации различных свойств, и при этом прост для быстрого понимания. Мы считаем, что даже если будут применяться иные техники выравнивания [8][9], то визуализация останется информативной.
Поскольку мы построили DTWRadar для каждой пары QES, то у нас пара точек, описывающая взаимосвязь между промежутками. Это значит, что можно сделать поддержку поиска этого пространства точек. Мы создали приложение, которое позволяет пользователю выбрать один источник в качестве начальной точки и масштабирует эти точки, показывая относительное положение в других QES или TES. Другими словами, мы наложили все DTWRadar с одним источником. Кликнув и перетягивая (click&drag) регион мета-радара, система находит все запросы по темам, которые отображают определённую взаимосвязь и возвращает их для дальнейшего анализа.
Будет логично спросить, насколько различны потоки данных во всех QES. Например, мы можем спросить: в среднем, ведёт ли QES из блогового источника (то есть посты, содержащие строку) QES из AOL? Рисунок 9 демонстрирует набор наложенных центроидов DTWRadar с MSN в качестве начальной точки. Мы выбрали этот набор, поскольку эти QES имеют высокую корреляцию из экспериментального списка, сгенерированного в анализе корреляции. MSN был выбран поскольку мы гарантированно имели данные для MSN на каждый данный запрос, хотя мы могли создать эти графики для любой связи. Центроид центроидов не отображён, поскольку он находится довольно близко к начальной точке во всех случаях. Изображение показывает распространение времени задержки и разницы важности.
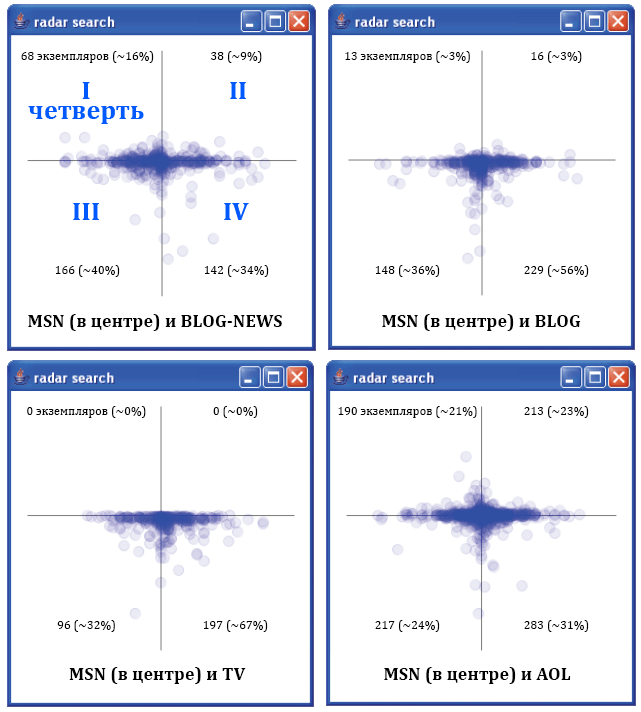
Рисунок 9. Кумулятивные позиции радаров по всем запросам при сравнении с набором данных MSN. Учтены только запросы со взаимной корреляцией ≥ 0.7. Точка в I четверти означает, что поведение имеет ведущие запросы по популярности и времени. Четверть II содержит отстающие события с высокой популярностью. Четверти III и IV представляют меньший общий интерес, чем поиски с ведущим и отстающим поведением соответственно.
Эффект нашей схемы распределения веса для набора данных TV заключается в том, что все центроиды появляются в четвертях III и IV (запросы с малой важностью). Несмотря на тот факт, что TV.com популярен, в действительности, ограниченное число голосов распределено по множеству шоу (несколько голосов на шоу). Так же в процессе анализа мы обнаружили, что из-за огромного количества ежедневных постов в блогах появилось сильное уменьшение важности QES каждого блога по отдельности. Многие посты в блогах написаны не на английском языке или не имеют ничего общего с внешними событиями (т.е. являются личными дневниками). В будущем такие дневники, не попадающие под какие-либо темы, стоит исключать из области исследования.
Мы сильно заинтересованы в возможности использовать события в одном информационном источнике для их предсказания в других. Вид радара даёт нам общее представление о взаимосвязях между ответами на события в потоках. Однако, как видно на рисунке 9, многие центроиды собраны в середине, а остальные могут помочь узнать, какие источники, темы и поведения предсказуемы. Например, в логах запросов скачок активности можно наблюдать ещё до ожидаемых событий, после чего идёт всплеск блоговой и новостной активности в наборах данных TV и BLOG близко ко времени самого события. Чтобы понять, какие поведенческие схемы являются общими, нам нужно классифицировать и охарактеризовать взаимосвязи между источниками и темами.
Мы случайным образом отобрали 244 запроса из набора сильно коррелирующих запросов. Затем вручную отнесли 216 из них в различные категории (корпоративные сайты, финансовые, ТВ шоу, новостные и т.д.). После мы исключили неоднозначные запросы, которые нельзя было отнести к той или иной категории. Например, «nicole kidman» отметили как celebrity и как in-the-news (её помолвка с Кейтом Урбаном была объявлена в середине мая). Аналогично, «world cup» отметили как sports и in-the-news в преддверии подготовки с событиям, связанным с новостями о происходящем.
Далее мы перечислим основные тенденции и проблемы, некоторые из которых пока что просто гипотетические, и обоснуем их характеризующими примерами.
Новости о странном – определённые события могут быть необычными и при этом иметь потенциал стать «вирусными» и захватить интерес множества людей. Такого рода тему мы назвали «новости о странном» (говоря прямо, не все необычные темы действительно странные, но они могут не быть на главной странице новостей). Мы обнаружили, что блоггеры лучше предсказывают будущую популярность таких событий. Например:
 ) о великане
ростом 2 метра 34,5 см, заказавшем индивидуальный набор обуви 58 размера,
статья о котором была размещена в Assosiated Press, опередили запросы по его имени (QESMSN =
) о великане
ростом 2 метра 34,5 см, заказавшем индивидуальный набор обуви 58 размера,
статья о котором была размещена в Assosiated Press, опередили запросы по его имени (QESMSN =  ).
). ), аэрокосмическом
инженере, критиковавшем решение NASA в начале мая, в блогах
прошёл раньше, чем начались запросы о нём (QESMSN =
), аэрокосмическом
инженере, критиковавшем решение NASA в начале мая, в блогах
прошёл раньше, чем начались запросы о нём (QESMSN =  ).
).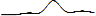 ) была примерно
идентичной по форме у MSN, но блоггеры прошли через цикл на 3 дня раньше.
) была примерно
идентичной по форме у MSN, но блоггеры прошли через цикл на 3 дня раньше.Ожидаемые события – записи в блогах оказались не настолько хороши в
предсказании ожидаемых событий. Например, по слову «preakness» о лошадиных
скачках (QESMSN = 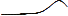 и QESBLOG =
и QESBLOG =  ),
множество пользователей генерировали запросы, но активность блоггеров была невелика. Мы
считаем, что реакция объясняется социальной сутью блогов и невысокой важностью
потенциально «новой» информации, поэтому блоггеры редко обсуждают широкоизвестные
факты. Но по мере приближения момента наступления события появляется новая
информация, на которую блоггеры и начинают реагировать.
),
множество пользователей генерировали запросы, но активность блоггеров была невелика. Мы
считаем, что реакция объясняется социальной сутью блогов и невысокой важностью
потенциально «новой» информации, поэтому блоггеры редко обсуждают широкоизвестные
факты. Но по мере приближения момента наступления события появляется новая
информация, на которую блоггеры и начинают реагировать.
Чем ближе знаешь, тем меньше почитаешь – мы заметили похожий эффект при сравнении новостей и
поискового поведения. Хотя тема может быть достойной внимания, она бывает
настолько знакомой среднему пользователю, что он не будет активно искать новую
информацию о ней. Одно из таких событий – «enron trial», судебном процессе
по делу компании Enron Corporation (QESNEWS = 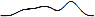 ).
Хотя темой новостей был суд, пользователи игнорировали его вплоть до вынесения приговора, послужившего
причиной резкого повышения внимания (QESMSN =
).
Хотя темой новостей был суд, пользователи игнорировали его вплоть до вынесения приговора, послужившего
причиной резкого повышения внимания (QESMSN = 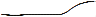 ). Такое
поведение может стать предметом для будущих исследований, поскольку мы
заинтересованы в том, чтобы отличать «важные» новости от «обычных».
Используя дополнительные источники, описывающие событие, можно по их количеству
определить порог важности. Это можно узнать даже при наличии всего нескольких
источников, записывая скорость публикации статей (т.е. чем важнее событие, тем
быстрее все хотят о нём рассказать), а также то, как источник описывает статью.
К примеру, маркировка «экстренное сообщение» может быть хорошим
идентификатором.
). Такое
поведение может стать предметом для будущих исследований, поскольку мы
заинтересованы в том, чтобы отличать «важные» новости от «обычных».
Используя дополнительные источники, описывающие событие, можно по их количеству
определить порог важности. Это можно узнать даже при наличии всего нескольких
источников, записывая скорость публикации статей (т.е. чем важнее событие, тем
быстрее все хотят о нём рассказать), а также то, как источник описывает статью.
К примеру, маркировка «экстренное сообщение» может быть хорошим
идентификатором.
Поведение фильтрации – одним неожиданным последствием выбора узкоспециализированного
источника, такого как TV.com, стала эффективная фильтрация новостей по определённым
темам. В данном случае актёры и актрисы упоминались в контексте шоу, в которых
они снимались. Например, запрос «mischa barton» (актриса в популярном ТВ-шоу, QESTV =
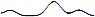 ) имел хорошую общую активность вследствие популярности шоу,
с неожиданным всплеском активности на MSN в конце месяца (QESMSN =
) имел хорошую общую активность вследствие популярности шоу,
с неожиданным всплеском активности на MSN в конце месяца (QESMSN = 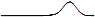 ) в преддверии
смерти её персонажа в конце сезона (изгиб ближе к концу кривой TV). Создав более точные
метки «источников» (к примеру, разделяя набор данных блогов на тематические
сообщества), можно отфильтровать и классифицировать определённые темы по
корреляции их поведения с поведение этих источников.
) в преддверии
смерти её персонажа в конце сезона (изгиб ближе к концу кривой TV). Создав более точные
метки «источников» (к примеру, разделяя набор данных блогов на тематические
сообщества), можно отфильтровать и классифицировать определённые темы по
корреляции их поведения с поведение этих источников.
Устранение шума – на фоне желания тематической секторизации источника, может быть полезно рассмотреть комбинацию источников для уменьшения шума. Поскольку новостные статьи в наборах данных BLOG-NEWS взвешиваются по поведению блогов, а блоггеры обычно ссылаются на статьи, которые они считают достойными, то события, которые можно предсказать в мерках времени и важности, примерно совпадают с поведением блоггинга. Например, поведение для запроса «uss oriskany» практически идентично в обоих наборах данных (взаимная корреляция 0.988 при задержке в 0 дней). Поскольку блоги сильно различаются по качеству и количеству информации, блоггер может просто сделать отсылку к статье не обсуждая её содержимое. Используя содержимое указателя мы сможем отличить тех блоггеров, которые наиболее точно описывают от тех, кто пишет посты «на автомате».
52 из 216 запросов были характеризованы как in-the-news. Поскольку каждый из 216 имеет высокий уровень корреляции с хотя бы одним из потоков данных, это может быть способом нахождения интересных событий. То есть если данная тема коррелирует с появлением в нескольких различных источниках, то она скорее всего является ответом на событие «news».
Корреляция и причинность – одной из основных проблем понимания причин и эффекта –
это различение корреляции и причинности. Два QES могут реагировать на событие в течение времени, но
причины их реакций могут быть разными. Например, некоторые ТВ-шоу показывали
участников съёмок и пародии на фильм «poseidon» (QESTV = 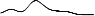 ) во время
премьеры фильмы. Однако, пользователи часто делали запросы о фильме до этого
события (QESMSN =
) во время
премьеры фильмы. Однако, пользователи часто делали запросы о фильме до этого
события (QESMSN = 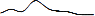 ). Хотя и
имеется очевидная корреляция двух потоков из-за грядущего выпуска,
пользователи, помимо самой премьеры, реагировали и на рекламу фильма. Поэтому
для «объяснения» поведения пользователей необходимо рассмотрение
комбинации событий (то есть источник рекламы/маркетинга и база данных премьеры
фильмов) и могут потребоваться более сложные модели.
). Хотя и
имеется очевидная корреляция двух потоков из-за грядущего выпуска,
пользователи, помимо самой премьеры, реагировали и на рекламу фильма. Поэтому
для «объяснения» поведения пользователей необходимо рассмотрение
комбинации событий (то есть источник рекламы/маркетинга и база данных премьеры
фильмов) и могут потребоваться более сложные модели.
Разница порталов – главные страницы современных поисковых движков не
просто содержат пустую строку ввода. Поисковые системы сам по себе являются
порталами новостей, развлечений и много другого. Информация, доступная на главной
странице, может привести к изменению поведения. И хотя невозможно различить эти
изменения как затронутые демографическими разновидностями, мы заметили
несколько таких, которые, по всей видимости, затронуты тем, какую информацию
портал показал своему пользователю. К примеру, пользователи AOL лидировали по важности и
времени в их реакции на «mothers day» (QESAOL = 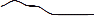 ) и «ashley flores»(жертва
похищения, QESAOL =
) и «ashley flores»(жертва
похищения, QESAOL =  ). С другой
стороны, пользователи MSN лидировали в запросах «flight 93 mborial»
(QESMSN =
). С другой
стороны, пользователи MSN лидировали в запросах «flight 93 mborial»
(QESMSN =  ) и реагировали
на новости немного раньше и с большим числом запросов (к примеру, для увольнения
«katie couric» из CBS в конце мая QESMSN =
) и реагировали
на новости немного раньше и с большим числом запросов (к примеру, для увольнения
«katie couric» из CBS в конце мая QESMSN =  , а для смерти
боксёра «floyd patterson» QESMSN =
, а для смерти
боксёра «floyd patterson» QESMSN =  ). В будущем мы
планируем использовать главные страницы различных порталов для более точной
идентификации этих различий.
). В будущем мы
планируем использовать главные страницы различных порталов для более точной
идентификации этих различий.
В этой статье мы описали первое крупномасштабное сравнение и изучение корреляции нескольких поведенческих наборов данных. Мы создали модель событий, позволяющую нам автоматически сравнивать реакцию пользователей относительно какого-либо источника – будь то поисковые сайты, блоги или сайты сообществ – с реакциями на другом. Мы разработали визуальный инструмент, DTWRadar, который позволяет пользователю просмотреть общую разницу между различными временными промежутками и найти определённые закономерности. Используя этот инструмент, мы обработали данные по взаимосвязям и описали некоторые ключевые свойства поведения различных интернет-систем и пользователей. Мы считаем, что DTWRadar носит независимый характер и может быть применён к любой базе данных, в которой возможно сравнение временных интервалов.
Сейчас мы изучаем сведения об общих паттернах поведения, полученные из этого исследования, и применяем их к определённым моделям, которые могут автоматизировать предсказание. И хотя ранние опыты дали некоторые результаты, ручное управление всё же было необходимо. Теперь мы концентрируемся на использовании описанных здесь техник и других способах вычисления поведения в сочетании с машинным обучением и алгоритмами анализа временных промежутков для выявления предсказуемых тем и поведения.
Мы считаем, что проведённое исследование имеет фундаментальное значение, так как понимание совокупного поведения масс так или иначе предоставляет массу возможностей в совершенно разных облсатях науки. Применение этих моделей возможно как в сферах психологии для глубокого понимания социологических феноменов, так и в быстрых и практичных системах ранжирования, от анализа средств маркетинга до поисковых систем, реагирующих на изменчивые нужды пользователей, желающих посмотреть последние новости об актуальных и интересующих их событиях.
Eytan Adar получил поддержку от объединений NSF Fellowship и ARCS Fellowship. Исследование щедро спонсировалось компанией Microsoft. Авторы хотели бы поблагодарить Nielsen/BuzzMetrics за выборку данных о блогах. Так же выражается благодарность Lada Adamic и Brian Davison за помощь в краулинге, Tanya Bragin и Ивану Бесчастных за их ценные комментарии.

Перевод материала «Why We Search: Visualizing and Predicting User Behavior» выполнил Максим Евмещенко
Полезная информация по продвижению сайтов:
Перейти ко всей информации