SEO-Константа
Яндекс.Директ + оптимизация
Наиболее известными алгоритмами ранжирования информации в системах информационного поиска, пожалуй, являются алгоритмы PageRank и HITS. В данной статье мы утверждаем, что эти алгоритмы не учитывают критически важную для современного поиска меру — временное измерение (temporal dimension). Качественные страницы в прошлом, не могут оставаться качественными в настоящем времени или в будущем. Указанные выше технологии отдают предпочтение старым страницам, поскольку последние имеют много входящих гиперссылок, которые накапливаются с течением времени. Новые страницы, которые могут быть высокого качества, не имеют или располагают несущественным числом входящих ссылок, а потому ранжируются хуже старых интернет-страниц. Поиск по научным публикациям сталкивается с аналогичной проблемой. Если мы используем алгоритмы PageRank или HITS, более старые или классические работы будут иметь высокий рейтинг из-за значительного объема цитирования, которое было осуществлено в прошлом. В данной работе исследуется временное измерение поиска в контексте научных публикаций. Ряд методов, которые предложены для решения озвученной проблемы, основаны на анализе истории поведения и источнике каждой публикации. Эти методы оцениваются эмпирически. Наши результаты показывают, что они являются крайне эффективными.
Мы не можем отрицать того факта, что интернет оказал глубокое влияние на наше общество, однако сама Глобальная паутина в
значительной мере обязана своей популярности широкому распространению систем информационного поиска. Цель поисковых систем
состоит в том, чтобы найти страницы, наиболее релевантные (соответствующие) пользовательскому запросу. Мотивация, положенная
в алгоритмы PageRank [6] и HITS [14] основана на том наблюдении, что гиперссылки, ведущие с одной веб-страницы на другую
выступают в качестве неявной передачей авторитетности целевому документу. Следовательно, для того, чтобы найти авторитетные
веб-документы мы можем использовать указанные алгоритмы ранжирования.
Тем не менее, важный фактор, который не учитывается в данных методах,- это своевременность результатов органического поиска.
Интернет представляет собой динамичную среду. Качественные страницы в прошлом, не могут оставаться качественными в настоящем
времени или в будущем. В данной работе мы изучаем поиск в зависимости от временного измерения, что очень важно в силу
следующих причин:
Мы считаем, что решение проблем, связанных с временным измерением поиска, имеет важное значение для будущего развития поисковых технологии.
В данной статье мы сделаем шаг в данном направлении.
Чтобы разобраться в вопросах более подробно, мы грубо классифицируем веб-документы на два типа: старые и новые страницы. Очевидно,
что существуют и такие интернет-страницы, которые занимают промежуточное положение. Мы не будем учитывать их для простоты нашего
последующего изложения.
Старые страницы (old pages) — это страницы, которые были созданы и находятся в интернете в течение длительного периода времени. Мы также можем классифицировать эти страницы на качественные и общие страницы. Качественные страницы (quality pages) обычно имеют большое количество входящих ссылок, в то время как ссылочная масса, приходящаяся на общие страницы (common pages), не столь велика. Старые качественные страницы могут быть разделены в зависимости от временного измерения:
Что касается старых общих страниц, мы также можем классифицировать их на два типа в зависимости от временного измерения:
Новые страницы (new pages) — это страницы, которые появились в интернете недавно. Новые страницы также можно сгруппировать по категориям:
В отличие от старых страниц, новые страницы имеют мало входящих ссылок или не цитируются вообще. Поэтому, объективное суждение об их качестве представляется крайне затруднительной задачей.
Таким образом, с учетом временного измерения и динамических процессов, протекающих в интернете, системы информационного поиска должны прийти к решению двух новых проблем, связанных с оценкой интернет-страниц:
Их решение представляются достаточно затруднительным для классических алгоритмов ранжирования Google PageRank или HITS. Сейчас мы попытаемся справиться с этими проблемами, принимая во внимание временную характеристику в задачах оценки качества интернет-страниц. В данной работе мы исследуем указанные вопросы в контексте поиска по научным публикациям по следующим трем причинам:
Конечно, между веб-страницами и научными публикациями существует ряд различий. Например, в интернете страницу могут удалить,
а вот опубликованную работу удалить невозможно. Гиперссылки, содержащиеся на веб-страницы также можно добавить или удалить,
тогда как для опубликованной исследовательской работы никакие референции или цитаты изменить нельзя. Тем не менее, по своей
сути, в обоих случаях основные задачи совпадают.
В данной работе мы изучаем оценку исследовательских работ, основанную на их цитировании, что соответствует оценке веб-страниц,
в основе которой положена гиперссылка. Мы представляем ряд методов для извлечения временного поведения (temporal behavior)
каждой публикации. Технологии оценивались экспериментально; результаты показали, что предложенные алгоритмы являются высоко
эффективными.
С момента опубликования работ, описывающих алгоритмы PageRank [6] и HITS [14], в литературе [1] [3] [4] [5] [6] [10] [11] [13]
[15] появилось большое количество исследований, связанных с их улучшением, вариациями, а также алгоритмическому ускорению. Также
много сообщалось о применении указанных алгоритмов как в информационном поиске, так и в поиске по научным публикациям, например,
при поиске ресурсов в Сети [6] [3]; поиск с учетом, как гиперссылок, так и содержания страниц [8]; при поиске по научным
публикациям [15]. Все эти работы рассматривали фреймворк оригинальных алгоритмов, и не учитывали временной аспект. Работы
[9] [16] посвящены эволюции веба и сталкиваются с той же проблемой, что мы обсуждали выше. В работе [2] также обнаруживают
указанную нами проблему и предпринимают ограниченную попытку ее разрешения, не содержащую момента оценивания.
В работе [15] описывается система CiteSeer, электронная библиотека научных публикаций. В ней также используются алгоритмы
PageRank и HITS для ранжирования статей либо по показателю «авторитетности» («authority» score), либо
по показателю «концентрации» («hub» score). В работе [15] отмечается, что в задачах поиска научных
публикаций следует рассматривать временной аспект. Тем не менее, в этой работе тема так и не получает дальнейшего развития.
Существует много факторов, которые влияют на ранжирование информации в результатах поиска. Вообще говоря, мы можем сгруппировать их по факторам содержимого и репутационным факторам.
Факторы содержимого: эти факторы, связанны с контентом документов. Они определяют степень релевантности документа пользовательскому запросу.
Репутационные факторы: репутация документов помогает определить рейтинг тех релевантных документов, которые возвращаются поисковой машиной. В контексте поиска по публикациям, репутационные факторы включают в себя количество цитат, приходящихся на заданную работу, репутацию его авторов и, соответственно, журналов.
Наша статья фокусируется на репутационных факторах и изучает то, как временное измерение может быть включено в оценку репутации исследовательских работ.
Существует два основных временных фактора, применимых к научной работе:
Основной алгоритм, который оценивает репутацию работы – это, безусловно, Google PageRank, который основан на цитировании (или на гиперссылках в контексте веб-поиска). Для того чтобы учесть время, наиболее очевидным подходом для нас представляется его включение в оригинальный алгоритм. Ниже, для решения нашей проблемы мы также описали метод, основанный на линейной регрессии.
Перед тем как описать технологию Временного PageRank, давайте сперва обратимся к оригинальной модели алгоритма Google PageRank [6]. Он также применим для поиска по научным публикациям. Значение PageRank (PR) страницы/публикации A определяется как:
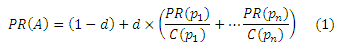
,где PR(A) – значение PageRank публикации A, PR(pi) – значение PageRank публикации pi, которая ссылается на публикацию A, C(pi) – количество исходящих ссылок с публикации pi, и d– коэффициент затухания, варьирующийся в диапазоне от 0 до 1. В данной работе, мы используем коэффициент затухания, который равен 0,85, что было использовано в оригинальной работе, посвященной PageRank [6]. Первоначально значение PageRank для каждой публикации равно 1. Подсчет производится в итеративном режиме до достижения точки конвергенции.
Сейчас мы опишем технологию Временного PageRank. Поскольку нас интересует авторитетность научной работы в настоящее время, то цитирование, которое было осуществлено несколько месяцев назад, очевидно, представляется для нас более важным, чем то, что произошло несколько лет назад. Мы модифицируем технологию классического PageRank посредством взвешивания каждой цитаты. Система рассчитывает взвешенное по времени значение PageRank (PRT) для каждой публикации следующим образом. Уравнение (2) – модифицированная версия уравнения (1):
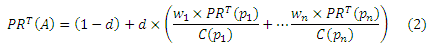
В этом уравнении, wi— это вес каждой цитаты, основанный на времени. Его значение зависит от даты цитирования публикации A публикацией pi, которое также является датой публикации pi. Чем ранее произошло цитирование, тем меньше вес оно имеет. Поскольку экспоненциальная средняя широко используется в предсказании временных рядов, мы выбираем экспоненциальное снижение весов в зависимости от времени,
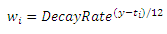
где y является текущим временем, ti — датой публикации pi, а (y-ti) — временным интервалом, выраженным в месяцах. Коэффициент затухания (DecayRate) является здесь специальным параметром. В то время как влияние параметра DecayRate на результаты прогнозирования будет описано более детально в подразделе 4.4, мы используем в следующем примере значение 0,5, чтобы проиллюстрировать данную концепцию. Например, в нашей обучающей выборке самые свежие работы опубликованы в декабре 1999 года. Цитирование, которое произошло в декабре 1999 года и декабре 1998 года, имеет вес 1 и 0,5 соответственно. Заметим, что если DecayRate равняется 1, взвешенный по времени алгоритм PageRank будет таким же, что и исходный алгоритм PageRank. Таким образом, параметр DecayRate может быть настроен в соответствии с природой набора данных/пользователя. Когда его значение близко к 1, то его вес со временем будет снижаться медленно. Это больше подходит для статических областей или пользователей, которые являются новыми для заданной области. Более поздние цитаты считаются более важными и имеют больший вес. Таким образом, с помощью этого подхода можно оценить важность работы, опубликованной ранее. Мы также заинтересованы в потенциальной авторитетности научной публикации в будущем. Для того чтобы оценить ее, давайте введем другой параметр, который назовем тренд-фактором (trend factor). Продолжая предыдущий пример для публикации A, PRT(A) уже фиксирует авторитетность с конца 1999 года. Как же изменяется авторитетность с годами? Она находит свое отражение в изменении цитирования с конца 1999 года. Таким образом, мы учитываем поведение публикации A в прошлом, чтобы вычислить ее тренд-фактор Trend (А):
После вычисления всех r(P) для всех научных публикаций мы нормализуем их таким образом, чтобы нормированные значения находились между минимальным тренд-фактором и 1. Минимальный тренд-фактор будет равен 0,5; причина в том, что для любой публикации вес каждой предыдущей цитаты будет сокращаться вдвое, спустя один год, как видно из уравнения (2). Нормированное значение r(P) является тренд-фактором публикации Р, Trend(P). Итоговый Временной PageRank (TPR) публикации А равен:
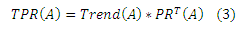
где PRT(A) было вычислено в уравнении (2).
Несмотря на то, что наш Временной PageRank учитывает время, данная технология еще не представляется полезной для новых публикаций, которые имеют несущественный объем цитирования или совсем не имеют его вообще со стороны других работ. Для оценки потенциальной авторитетности новой публикации ценными оказываются два вида источника информации: репутация авторов и издания. Для оценки их репутации мы можем использовать взвешенный по времени PageRank.
Оценка автора (author evaluation): репутация автора основана на научных статьях, которые он/она опубликовали в прошлом. Мы вычисляем оценку автора путем усреднения взвешенных по времени значений PageRank всех его/ее прошлых публикаций. Пусть работы, опубликованные автором aj в прошлом будут p1, p2, …, pm, тогда значение оценки автора Author(aj) рассчитывается как:
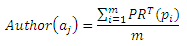
где PRT(pi) является взвешенным по времени значением PageRank публикации pi. Здесь PRT(pi) используется вместо PR(pi), так как мы считаем, что последние цитаты являются более значимыми для текущей репутации автора.
Оценка издания (journal evaluation): значение JournalEval(j) также назначается каждому изданию j с учетом статей, опубликованных в нем ранее. Используя оценку автора и издания, мы можем оценить авторитетность публикации различными способами.
Один из способов оценивания статьи основан на ее авторах. Обозначим авторов статьи р как a1, a2, …, ak. Значение оценки публикации можно рассчитать, основываясь на средневзвешенном значении оценки автора:
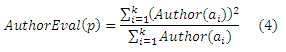
Другой способ заключается в объединении оценок автора и издания, чтобы получить общее значение каждой публикации. Предположим, что публикация p издана в журнале j. Мы вычисляем среднее арифметическое значений оценок автора и издания: AJEval(p) = (JournalEval(j) + AuthorEval(p))/2. Конечно, есть много других способов подсчитать это общее значение. Одна из альтернатив заключается в вычислении средневзвешенных значений JournalEval(j) и AuthorEval(p):
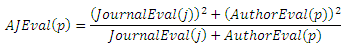
Мы сравним оба эти подхода несколько позже. Следует отметить, что спустя некоторое время, когда статья была опубликована, в задачах оценки публикации более эффективно использовать Временной PageRank, чем ее автора/издания. Причина этого заключается в том, что оценивание автора/издания является всего лишь усредненным значением всех публикаций, относящихся к авторам/изданиям.
Еще одной простой технологией, которую можно использовать в задачах оценки публикации, является линейная регрессия. В частности, можно использовать подсчет цитат, приходящихся на публикацию, которые были получены за последний период времени для выполнения линейной регрессии для прогнозирования количества цитат. Этот спрогнозированный подсчет цитирования можно использовать в качестве оценки заданной публикации. Если статья опубликована совсем недавно, то она может иметь несущественное количество цитат. В этом случае линейная регрессия не будет аккуратной. Тогда, для оценки свежей работы мы используем оценку авторитетности автора и издания. Оценивание автора и издания можно провести при помощи фактического подсчета цитирований всех публикаций автора или издания. Обозначим работы, опубликованные автором aj как p1, p2, …, pm. Оценка автора (author score) вычисляется следующим образом:
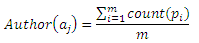
,где count(pi) – количество цитирований публикации pi. Рейтинг публикации, который основан на оценивании автора, дан в Уравнении (4). Оценивание издания можно провести аналогичным образом. После их расчета, мы можем использовать схожий с описанным в подразделе 3.2. метод, позволяющий скомбинировать значения оценок издания и автора.
В этом разделе мы оценим предложенные технологии, а также займемся их сравнением с классическим алгоритмом Google PageRank. Мы используем данные исследовательских публикаций KDDCUP 2003, представляющий собой каталогизированный архив публикаций по Физике Высоких Энергий Стэндфордского Центра Линейного Ускорителя.
В наших экспериментах мы используем стандартную парадигму поиска. То есть, для заданной коллекции научных работ и пользовательских запросов система осуществляла ранжирование работ по степени их убывающей релевантности, относительно вводимых запросов. Наши исследования направлены на изучение воздействия временного фактора на ранжирование, в основе которого положено цитирование, поэтому мы не заинтересованы в таких факторах содержимого, как местоположение ключевых слов, расстояние между ними в тексте документа и т.п. Мы просто полагаем, что публикация соответствует пользовательскому запросу в том случае, если она содержит все слова из поискового запроса.
Способ оценки (evaluation method): для того, чтобы оценить предложенные нами технологии, мы не сравниваем их рейтинги напрямую, поскольку в этом случае количественная оценка представляется затруднительной. Вместо этого, мы сравним количество цитат, которые будут иметь публикации с наивысшим рейтингом в следующем году. т. е. через год после того, как пользователь обратится к поиску. Это разумно постольку, поскольку количество цитат отражает авторитетность научной работы. В том случае, если эти активно цитируемые публикации в будущем будут иметь высокий рейтинг согласно нашему алгоритму, это будет означать, что алгоритм является эффективным при поиске высококачественной научной публикации.
В этой серии экспериментов мы использовали все документы 1992-1999 годов, чтобы сравнить различные оценки, присваиваемые предложенными нами технологиями. Мы обратились к поиску с 25 запросами, содержащих наиболее употребляемые физические термины и отранжировали научные публикации, по степени их релевантности каждому запросу. Данные за 2000 г. тестировались различными методами ранжирования. В Таблице 1 представлены результаты эксперимента. Отражены результаты только для 30 лучших работ. Причина использования только 30 лучших опубликованных работ заключается в том, что пользователю редко хватает терпения просмотреть более чем даже 20 статей.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| ТОП работ | Оригинальный PageRank | TPR | TPR (AJEval — среднее) | TPR (AJEval — среднее взвешенное) | LR | LR (AJEval) | Наибольшее количество цитат | ||||||
| 10 | 2516 | 44% | 4236 | 75% | 4312 | 76% | 4382 | 77% | 4219 | 75% | 4136 | 73% | 5661 |
| 20 | 3406 | 46% | 5702 | 78% | 5739 | 78% | 5756 | 78% | 5371 | 73% | 5447 | 74% | 7345 |
| 30 | 4024 | 48% | 6816 | 81% | 6845 | 81% | 6788 | 81% | 6385 | 76% | 6519 | 78% | 8406 |
Таблица 1. Сравнение результатов, полученных с использованием различных методологий по всем публикациям
Экспериментальные результаты представлены в три строки. Каждая строка показывает общее количество цитат с использованием различных методологий, примененных к группе публикаций. Первая строка отображает данные для 10 лучших публикаций (мы также называем их группой публикаций), где количество цитат получается путем суммирования цитат всех десяти публикаций по 25 запросам. Аналогично, вторая строка показывает данные для следующих десяти публикаций от 11-20, и так далее. Ниже приведем объяснение результатов по столбцам.
Столбец 1: здесь перечислена каждая группа публикаций согласно своему рейтингу.
Столбцы 2 и 3: столбец 2 приводит результат для каждой группы публикаций, которые ранжированы при помощи оригинального алгоритма PageRank. Каждый результат представляет собой общее количество цитат каждой группы публикации для 25 запросов. Каждое значение получено от цитат, которые публикация получила в 2000 году. Столбец 3 представляет собой отношение общего количества цитат с использованием этого метода и общего количества цитат в случае идеального рейтинга (так называемый оптимальный объем цитат, приведен в столбце 14), выраженное в процентах. Идеальным рейтингом является тот, при котором релевантные работы отранжированы по фактическому числу их цитирований, которые получит каждая из них в следующем году.
Столбцы 4 и 5: в столбце 4 приведены результаты (количество цитат) по алгоритму Временного PageRank (TPR). Столбец 5 представляет собой отношение общего количества цитат с использованием алгоритма Временного PageRank и общего количества цитат идеального рейтинга, выраженное в процентах. Согласно данным 4 и 5 столбцов, необходимо отметить, что результаты Временного PageRank оказываются значительно лучшими, чем у оригинального алгоритма Google PageRank.
Столбцы 6-7, 8-9: подобны предыдущим столбцам. В столбцах 6-7 и 8-9 приведены как соответствующие результаты TPR (AJEval – среднее значение), так и TPR (AJEval – среднее взвешенное значение). Эти два метода представляют собой комбинацию Временного PageRank (TPR) и оценивания автора и издания для новых статей, но скомбинированные различными способами. Публикации рассматриваются как новые в том случае, если они были опубликованы менее чем 3 месяца назад. Результаты обоих алгоритмов превосходят результаты, полученные с использованием только Временного PageRank. Причина этого заключается в том, что Временной PageRank не может обрабатывать новые работы достаточно эффективно. Заметим также, что подход с использованием средних взвешенных значений работает немного лучше, чем алгоритм со средним значением для 10 лучших публикаций, которые более значимы для нашего поиска. Более подробно причина этой разницы будет проанализирована в подразделе 4.3.
Столбцы 10-11 и 12-13: отображают соответствующие результаты линейной регрессии (обозначенные как LR) основных алгоритмов. Мы видим, что эти два метода работают также хорошо, но их результаты не так хороши, как у тех алгоритмов, которые основаны на Временном PageRank.
Столбец 14: показывает общее количество цитирований каждой группы публикаций при идеальном ранжировании, то есть, ранжированию релевантных публикаций согласно фактическому количеству цитат на 2000 год.
Подводя итог, следует отметить, что алгоритмы, основанные на Временном PageRank и линейной регрессии, дают лучшие результаты, чем оригинальный алгоритм Google PageRank. Кроме того, оценка автора и издания в большинстве случаев помогает лучше спрогнозировать результаты. Поскольку доля новых публикаций не велика (около 3%), эффект оценивания автора и издания ослабевает. Мы покажем результаты эксперимента с участием только новых публикаций в подразделе 4.3. Среди всех четырех алгоритмов, Временный PageRank с оценкой автора и издания дает наиболее качественные результаты.
Чтобы дать некоторое представление об эффективности предлагаемых методов ранжирования, укажем ТОП 10 наиболее цитируемых публикаций в 2000 году. Затем, с помощью предложенных методов, отранжируем все работы, появившиеся с 1992 по 1999 год. В Таблице 2 приведены результаты ранжирования.
| Ранг | ID публикации | Исходный PageRank | TPR (AJ Eval.) |
LR (AJ Eval.) |
| 1 | 9711200 | 19 | 1 | 1 |
| 2 | 9908142 | 742 | 8 | 5 |
| 3 | 9906064 | 613 | 6 | 10 |
| 4 | 9802150 | 39 | 2 | 2 |
| 5 | 9802109 | 46 | 4 | 3 |
| 6 | 9711162 | 323 | 11 | 7 |
| 7 | 9905111 | 576 | 9 | 4 |
| 8 | 9711165 | 620 | 20 | 14 |
| 9 | 9610043 | 17 | 12 | 19 |
| 10 | 9510017 | 7 | 13 | 8 |
Таблица 2. Ранжирование 10 наиболее цитируемых публикаций
Столбец 1: показывает ТОП 10 наиболее цитируемых публикаций в 2000 году.
Столбец 2: отображает ID публикаций.
Столбец 3: отражает ранг каждой публикации, присвоенный оригинальным алгоритмом Google PageRank.
Столбец 4: отражает ранг каждой публикации, присвоенный Временным PageRank. Новые публикации ранжировались с помощью комбинированной оценки автора и издания (подраздел 3.2).
Столбец 5: отражает ранг каждой публикации, присвоенный алгоритмом линейной регрессии. Новые публикации ранжировались с помощью комбинированной оценки автора и издания (подраздел 3.3).
Таблица 2 наглядно показывает, что результаты ранжирования, полученные с использованием оригинального алгоритма Google PageRank оказываются явно неудовлетворительными. В противоположность этому, предложенные нами алгоритмы имеют на удивление хорошую производительность. Все 10 наилучших публикаций получают очень высокий рейтинг (в пределах 20).
В этой серии экспериментов мы использовали только свежие работы. То есть, мы использовали только те научные публикации,
которые были опубликованы менее чем за три месяца до времени исполнения запроса. Нашей целью является измерение эффективности
оценивания автора и издания.
В этой серии экспериментов не используются алгоритмы Временного PageRank и линейной регрессии, потому что данные публикации
имеют несущественное количество цитат. Обратите внимание, что здесь мы не использовали пользовательские запросы, поскольку
возвращенные результаты будут отличаться дефицитом ответов системы по причине незначительного количества самих свежих работ.
Мы использовали алгоритмы ранжирования, предложенные для новых публикаций, по всем свежим работам. Результаты приведены в
Таблице 3.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| ТОП работ | Рандомное ранжирование | Оценка автора (PRT) | Оценка издания (PRT) | AJ Eval (PRT– среднее) | AJ Eval (PRT– среднее взвешенное) | Оценка автора (подсчет) | Оценика издания (подсчет) | AJ Eval (подсчет) | Наибольшее количество цитат | ||||||||
| 10 | 73 | 10% | 215 | 29% | 185 | 25% | 366 | 49% | 373 | 49% | 93 | 12% | 134 | 18% | 173 | 23% | 754 |
| 20 | 192 | 16% | 315 | 26% | 414 | 35% | 634 | 53% | 804 | 67% | 212 | 18% | 215 | 18% | 236 | 20% | 1194 |
| 30 | 219 | 15% | 543 | 37% | 692 | 46% | 861 | 58% | 1013 | 68% | 367 | 25% | 282 | 19% | 459 | 31% | 1481 |
Таблица 3. Сравнение результатов с использованием разных алгоритмов, применительно только к новым публикациям
Столбец 1: здесь перечислена каждая группа публикаций согласно своему рейтингу.
Столбцы 2 и 3: столбец 2 отражает подсчет общего количества цитат каждой группы публикаций согласно рандомному ранжированию. Рандомное ранжирование является достаточно разумным методом, потому что новые документы мало цитируются другими научными публикациями. Столбец 3 представляет собой отношение общего количества цитат этого метода и общего количества цитат идеального ранжирования (столбец 18), выраженное в процентах. Результаты рандомного ранжирования оказались крайне неудовлетворительными.
Столбцы 4-5, 6-7: отражают соответствующие результаты алгоритмов оценки автора (4-5) и оценки издания (6-7). В обоих случаях были использованы взвешенные по времени значения PageRank (PRT) всех публикаций авторов/изданий (см. подраздел 3.2). AuthorEval и JournalEval дают отличные результаты и превосходят алгоритм рандомного ранжирования.
Столбцы 8-9, 10-11: отражают соответствующие результаты алгоритмических комбинаций (AJEval–среднее значение) и (AJEval — среднее взвешенное значение). Данные технологии сочетают в себе различные комбинации оценок автора и издания. Среднее значение вычисляется из значений двух оценок стандартным способом, в то время как средний взвешенный результат более близок к той оценке, что имеет большее значение и соответственно больший вес. Мы видим, что алгоритмические комбинации дают лучшие результаты, чем методология, в основе которой положен единственный критерий. Обычно о качестве публикации судят по автору и изданию. Тем не менее, это не всегда так. Например, молодой исследователь, обладающий большим потенциалом, может иметь более низкую оценку как автор, однако он/она в состоянии опубликовать качественные статьи в ведущих научных изданиях. Аналогично, недооцененным может оказаться и новый журнал. Поэтому, когда есть большой разрыв между оценкой издания и автора, метод использующий средневзвешенное значение устраняет данную проблему, чем и превосходит алгоритм с использованием простого среднего значения.
Столбцы 12-13, 14-15 и 16-17: приводят результаты по трем алгоритмам, использующих подсчет цитат опубликованных работ для оценивания автора или издания. Они также достигают более лучших результатов, нежели чем в случае применения рандомного ранжирования, однако значительно уступают взвешенного по времени PageRank, базирующегося на оценке авторов и изданий.
Столбец 18: отражает общее количество цитирований каждой группы публикаций при идеальном ранжировании, то есть ранжированию научных работ согласно фактическому количеству цитат на 2000 год.
Подводя итог, стоит заметить, что PRT, использующий оценку авторов и изданий работает лучше, чем алгоритм, основанный на подсчете цитат, благодаря использованию взвешенных по времени значений. Наши результаты в столбцах 9 и 11 Таблицы 3 показывают, что предсказанное количество цитат, приходящихся на лучшие работы, составляет более половины от их числа в случае идеального ранжирования. Учитывая, что мы не располагаем информацией, касательно цитирования новых публикаций, подобные результаты являются весьма перспективными.
При внедрении концепции Временного PageRank мы заметили, что для достижения оптимального результата необходима настройка коэффициента затухания (DecayRate) для заданного набора данных. Наши эксперименты показали, что алгоритм TPR (AJEval) является эффективной оценочной технологией. Таким образом, мы применили ряд значений DecayRate в TPR (AJEval – среднее значение) и изучили взаимосвязь между эффективностью оценки и DecayRate. Различные значения параметра DecayRate {0.2, 0.3, 0.5, 0.7, 0.8, 1.0} подверглись экспериментальному изучению, результаты которого приведены в Таблице 4.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| ТОП работ | DecayRate = 0.2 | DecayRate = 0.3 | DecayRate = 0.5 | DecayRate = 0.7 | DecayRate = 0.8 | DecayRate = 1.0 | Наибольшее количество цитат | ||||||
| 10 | 4257 | 75% | 4287 | 76% | 4312 | 76% | 4243 | 75% | 4341 | 77% | 3308 | 58% | 5661 |
| 20 | 5698 | 78% | 5791 | 79% | 5739 | 78% | 5733 | 78% | 5645 | 77% | 4552 | 62% | 7345 |
| 30 | 6769 | 81% | 6868 | 82% | 6845 | 81% | 6881 | 82% | 6537 | 78% | 5511 | 66% | 8406 |
Таблица 4. Сравнение результатов алгоритма TPR (AJEval — среднее значение) с использованием различным значений коэффициента затухания (DecayRate)
Столбец 1: здесь перечислена каждая группа публикаций согласно своему рейтингу.
Столбцы 2 и 3: столбец 2 отражает результаты (количество цитат) метода прогнозирования TPR(AJEval) с DecayRate = 0.2. Столбец 3 приводит соотношение общего количества цитат алгоритма TPR(AJEval) (DecayRate = 0.2) и общего количества цитат при идеальном ранжировании (столбец 14).
Столбцы 4-5, 6-7, 8-9, 10-11, 12-13: близки по значению столбцам 2-3. Единственное отличие заключается в значении DecayRate, которое варьируется в данном случае от 0.3 до 1.0.
Столбец 14: отражает те же данные, что и столбец 14 Таблицы 1. Он показывает общее количество цитирований каждой группы публикаций при идеальном ранжировании, то есть, ранжированию релевантных публикаций согласно фактическому количеству цитат на 2000 год.
Результаты показывают, что диапазон значений DecayRate 0,3-0,7 является оптимальным для данной коллекции публикаций. Если значение параметра DecayRate оказывается ниже, чем 0.2, система плохо фокусируется на самых свежих цитатах; документы с меньшим количеством свежих цитат отсутствуют в спрогнозированном топе публикаций, вне зависимости от того, что могут оказаться авторитетными. Исключение этих работ из результатов снижает общее качество ранжирования. Напротив, когда параметр DecayRate близок к 1.0, то система вообще не различает временную разницу цитирования. Старые качественные работы, которые не обновляются в течение продолжительного периода времени, оказываются в более выигрышном положении за счет своей исторической давности. В результате этого, некоторые новые публикации уходят из верхних позиций получаемого рейтинга.
В текущей работе исследовался поиск, учитывающий временное измерение. До сих пор исследовательские работы ограничивались рассмотрением временного фактора как в контексте веб-поиска, так и поиска по научным публикациям. В данной работе мы попытались предложить ряд технологий, который позволили бы исправить ситуацию. Наши оценочные результаты показывают, что предлагаемые алгоритмы являются высоко эффективными. Хотя в этой работе мы использовали поиск по публикациям в качестве испытательной модели, предложенные методы могут быть адаптированы и к веб-поиску, поскольку понятия в этих двух сферах в значительной степени параллельны.
Ссылки:
[1] D. Achlioptas, A. Fiat, A. Karlin, and F. McSherry. “Web search via hub synthesis”, FOCS, Las Vegas, Nevada, 2001, pp. 500-509.
[2] R. Baeza-Yates, F. Saint-Jean, C. Castillo, “Web Structure, Dynamics and Page Quality”, SPIRE, Lisbon, Portugal, 2002, pp. 117-130.
[3] K. Bharat and M. Henzinger. “Improved algorithms for topic distillation in a hyperlinked environment”, SIGIR, Melbourne, Australia, 1998, pp. 104-111.
[4] A. Borodin, J. S. Rosenthal, G. O. Roberts, and P. Tsaparas, “Finding authorities and hubs from link structures on the World Wide Web”, WWW, Hong Kong, China, 2001, pp. 415- 429.
[5] A. Broder, R. Kumar, F. Maghoul, P. Raghavan, S. Rajagopalan, R. Stata, A. Tomkins, and J. Wiener, “Graph structure in the Web”, WWW, Amsterdam, The Netherlands, 2000, pp. 309-320.
[7] S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, P. Raghavan, and S. Rajagopalan, “Automatic resource compilation by analyzing hyperlink structure and associated text”, WWW, Brisbane, Australia, 1998, pp. 65 — 74.
[8] S. Chakrabarti, M. van den Berg, and B. Dom, ”Focused crawling: A new approach to topic-specific Web resource discovery”, WWW, Toronto, Canada, 1999, pp. 1623-1640.
[9] J. Cho and S. Roy, «Impact of Web Search Engines on Page Popularity”, WWW, New York, USA, 2004. pp. 20 – 29.
[10] M. Diligenti, M. Gori, and M. Maggini, “Web page scoring systems for horizontal and vertical search”, WWW, Honolulu, USA, 2002, pp. 508 – 516.
[11] S. Dill, R. Kumar, K. S. McCurley, S. Rajagopalan, D. Sivakumar, and A. Tomkins. “Self-similarity in the Web”, VLDB, Roma, Italy, 2001, pp. 69-78.
[12] R. Fagin, R. Kumar, K. S. McCurley, J. Novak, D. Sivakumar, J. Tomlin, and D. Williamson, “Searching the workplace Web”, WWW, Budapest, Hungary, 2003, pp. 366 – 375.
[13] S. D. Kamar, T. Haveliwala, C. D. Manning, and G. H. Golub, “Extrapolation methods for accelerating PageRank computations”, WWW, Budapest, Hungary, 2003, pp. 261 – 270.
[15] S. Lawrence, K. D. Bollacker, and C. L. Giles, “Indexing and retrieval of scientific literature”, CIKM, Kansas City, USA, 1999, pp. 139 – 146.
[16] A. Ntoulas, J. Cho, and C. Olston, “What’s New on the Web? The Evolution of the Web from a Search Engine Perspective”, WWW, New York, USA, 2004, pp. 1 – 12.
Перевод материала «Adding the Temporal Dimension to Search — A Case Study in Publication Search» выполнил Сергей Неиленко
Полезная информация по продвижению сайтов:
Перейти ко всей информации