SEO-Константа
Яндекс.Директ + оптимизация
Аннотация
Причина возникновения такого явления как поисковый спам заключается в попытке некоторых оптимизаторов и владельцев сайтов обмануть ранжирующие алгоритмы систем информационного поиска и, тем самым, получить более высокие позиции в результатах их органического поиска, что незамедлительно отразиться на количестве посетителей и тех прибылей, которые они получают со своих веб-проектов. Одной из основных техник поискового спама являются ссылочные фермы, которые подразумевают создание большого множества плотно-связанных между собой некачественных страниц с единственной целью, заключающейся в манипуляции ссылочными алгоритмами ранжирования, рассматривающих входящие гиперссылки на цифровой документ как попытку голосования за него во Всемирной паутине. Безусловно, подобного рода ссылочные фермы должны быть исключены из результатов органического поиска, анализа и майнинга веба, однако они также представляют исследовательский интерес, относительно тех социальных процессов, что можно наблюдать в киберпространстве. Целью настоящей работы является понимание динамических процессов, происходящих в линкофармах. Например: до каких размеров они могут вырастать или сокращаться, как с течением времени меняется их принадлежность к той или иной тематики и т.п. Подобная информация может помочь нам в разработке новых технологий идентификации спама, а также в отслеживании тематик спам-сайтов. Главным образом, нас интересует обнаружение вновь появившихся спам-сайтов, что является чрезвычайно полезным в задачах обновления классификаторов спама. В текущей работе мы исследуем распределение размеров/тематик ссылочных ферм, а также их эволюцию на крупномасштабном интернет-архиве, описанном на японском языке, который был получен за три года и содержит 4 млн. хостов, а также 83 млн. гиперссылок. Насколько мы знаем, до сих пор научным сообществом не были получены исчерпывающие характеристики линкофармов с использованием временного ряда мгновенных снимков состояния ссылочного графа на столь масштабных данных. Мы предлагаем методологию извлечения ссылочных ферм, а также изучение их распределения по размеру и тематической принадлежности. Мы наблюдаем эволюцию линкофармов с точки зрения их роста и распределения изменений тематики. Мы рекурсивно разложили графы хостов по ссылочным фермам и обнаружили, что от 4% до 7% хостов являются участниками линкофармов. По сути это означает то, что мы можем удалить целый ряд спам-хостов, минуя анализ их содержимого как таковой. Мы также обнаружили две доминирующие в спам-сообществе темы: «взрослая тематика» и «путешествия», на которые пришлось более 60% спам-хостов в линкофармах. Эволюция размера ссылочных ферм продемонстрировала нам то, что множество манипулятивных схем поддерживаются в живом состоянии в течении многих лет, однако большая их часть не прирастает новыми участниками. Распределение ссылочных ферм по тематикам со временем существенно не изменяется, однако это не касается хостов и ключевых фраз, относящихся к каждой теме, которые динамически изменяются. Данные результаты указывают на то, что при наличии способности отслеживать тематические сдвиги в каждой ссылочной ферме, мы не имеем возможности эффективно обнаруживать новых участников линкофармов посредством их мониторинга. Это означает, что для обнаружения новых спам-сайтов текущего мониторинга ссылочных ферм недостаточно. Обнаружение сайтов, которые генерируют линки на спам-ресурсы мог бы стать эффективным подходом.
1. Введение
За два последних десятилетия интернет развился до основного источника информации и площадки для осуществления коммерческой деятельности. Ныне, получив доступ к Глобальной паутине через такие системы информационного поиска, как Google, Yahoo! и Bing, множество людей получают всевозможные знания, бронируют гостиницы, совершают ежедневные покупки в интернет-магазинах и т.д. Несмотря на то, что в интернете существует более 1 трлн. URL-адресов [1], половина пользователей ограничивают свой поиск первой пятеркой веб-сайтов, предложенных поисковыми системами в результатах органической выдачи [2]. В данной ситуации, владельцам веб-сайтов крайне важно получить как можно более высокие позиции в результатах поиска по пользовательским запросам, что увеличит приток посетителей на их сайты и, таким образом, принесет необходимые прибыли. В результате чего, некоторые люди начинают заниматься манипулированием как гиперссылочной структурой, так и содержимом интернет-страниц в целях введения в заблуждения ранжирующих механизмов и увеличения видимости своих веб-ресурсов. Данное поведение называется поисковым спамом, а псевдо-оптимизированные страницы — спам-документами. Спамеры используют различные техники для манипулирования текстовым содержимым и гиперссылочной структурой. Они вставляют в текстовое содержимое страницы своих сайтов популярные пользовательские запросы, а также копируют релятивные документы с прочих веб-ресурсов для того, чтобы их проект представлялся полезным для посетителей. Они также создают ссылочные фермы (link farms), представляющие собой плотосвязанные структуры, состоящие из множества перелинкованных спам-страниц, основная задача которых состоит в увеличении числа входящих ссылок на целевой документ и манипуляции такими алгоритмами ссылочного ранжирования, как Google PageRank [3], который рассматривает входящие гиперлинки в качестве «голоса», отдаваемого процитированному документу его соседями по Сети. Обнаружение и нейтрализации поискового спама является крайне важной задачей не только для поисковых машин, но и для приложений веб-анализа, основанных на веб-архивах постольку, поскольку манипулятивные практики вводят в заблуждение различные средства веб-анализа. Например, когда мы используем такие гиперссылочные методы извлечения веб-комьюнити, как алгоритм HITS [4] и травлинг [5] , полученные результаты могут содержать в себе множество линкофармов. Искусственное «нашпиговывание» контента популярными ключевыми фразами может контаминировать результаты частотно-временного анализа слов. Обнаружение и нейтрализация поискового спама также представляется серьезной проблемой по той простой причине, что для избежания новых анти-спам технологий, которые создаются разработчиками поисковых систем, и продвижения сайтов спамеры постоянно создают новые спам-страницы/модифицируют уже существующие. Например, для того, чтобы не попасть под фильтры, вычисляющие скопированный контент, спамеры сперва создают мозайчатое содержимое, скопированное из различных источников и представляющее собой небольшие текстовые фрагменты. Продолжая начатое дело, они создают новые страницы, которые еще неизвестны спам-фильтрам и единственная цель которых заключается в агрессивной демонстрации рекламы новых медицинских препаратов и прочих продуктов. Спам-страницы должны быть исключены из результатов органического поиска, анализа и майнинга веба, однако они также представляют для нас исследовательский интерес, относительно тех социальных процессов, которые можно наблюдать в киберпространстве. В текущей работе мы фокусируемся на линкофармах, а также изучаем протекающие в них такие динамические процессы, как, например, до каких размеров они могут вырастать или сокращаться, как с течением времени меняется их тематическая принадлежность и т.п. Подобная информация может помочь нам в разработке новых технологий идентификации спама, а также в отслеживании его тематических смещений. Главным образом, нас интересует обнаружение вновь появившихся спам-сайтов, что представляется крайне полезным в задачах обновления спам-классификаторов. Свои эксперименты мы проводим по крупномасштабному интернет-архиву, описанного на японском языке, за последние три года, который включает в себя 4 млн. хостов и 83 млн. ссылок. Насколько мы знаем, до сих пор не существовало исследования ссылочных ферм с использованием временного ряда мгновенных снимков состояния ссылочного графа на столь масштабных данных. В своей предыдущей работе [6] мы извлекли линкофармы из одного единственного мгновенного снимка состояния веб-графа, посредством применения на веб-графе алгоритма разложения компонентов сильной связанности (SCC — сокращение от англ. Strongly Connected Components). Мы продемонстрировали, что за исключением крупнейшей компоненты (то есть ядра) практически все оставшиеся крупные SCC оказались ссылочными фермами. Тем не менее, в прошлый раз нам не удалось эффективно извлечь линкофармы из самого ядра. Поэтому, в настоящей работе мы улучшили алгоритм разложения компонентов сильной связанности в целях извлечения более плотно связанных в ядре ссылочных ферм. Иными словами, мы отсекаем от ядра узлы с малой степенью, а затем рекурсивно применяем алгоритм разложения SCC к усеченному ядру со увеличением предельно-допустимого порога степени. Здесь нам удалось извлечь крупные компоненты сильной связанности по истечению по меньшей мере 10 итераций и продемонстрировать, что содержащиеся в указанном ядре данные SCC также, по всей вероятности, являются ссылочными фермами. Мы обнаружили, что от 4% до 7% всех хостов являются участниками линкофармов. Это означает, что мы можем удалить целый ряд спам-хостов из нашего интернет-архива только на основании полученной гиперссылочной структуры. После извлечения ссылочных ферм, в мы классифицировали тематическую принадлежность спам-хостов на основании их URL-адресов. Обнаружив, что спамеры формируют ссылочные фермы, используя такие спам-хосты, которые имеют URL-адрес и содержимое, аналогичные заявленной тематике.
Рисунок 1. Два спам-хоста, которые являются участниками единой ссылочной фермы, имеют общую для них тематику.

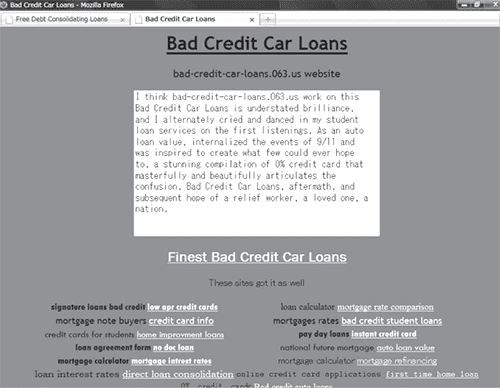
Например, Рисунок 1 демонстрирует нам две спам-страниц, относящиеся к одной ссылочной ферме. URL-адреса данных хостов free-debt-consolidating-loans.063.us и bad-credit-car-loans.063.us соответственно. Оба хоста содержат много общих для них ключевых фраз, такие как «заем», «кредит» и «долг», что указывает на их принадлежность к тематике «Финансы». Исходя из этих наблюдений, мы можем предположить, что относительно малые линкофармы состоят из интернет-документов, относящиеся к единой тематики. Мы выбрали 7 тематик, в которых чаще всего задействуются подобные манипулятивные практики (на основании ручного исследования малых линкофармов)и категоризировали содержащиеся в них спам-хостов по семи тематикам с использованием уникальных локаторов ресурсов. Мы показали, что добавление URL-адресов из линкофармов может улучшить результаты классификации. Были обнаружены две доминирующие в спам-сообществе темы: «взрослая тематика» и «путешествия», на которые пришлось более 60% спам-хостов. Мы исследовали увеличение размера и изменения в распределении ссылочных ферм по тематикам за последние три года. Мы обнаружили, что практически все крупные линкофармы не имели выраженной тенденции к дальнейшему росту; в целом их распределение по тематикам практически не изменяется, несмотря на то, что их спам-хосты и ключевые фразы подвержены динамическим сдвигам. Подобные результаты позволяют выдвинуть предположение о том, что мониторинг существующих ссылочных ферм смог бы оказаться полезным в задачах вычисления новых ключевых фраз, которые используют спамеры, однако он практически бесполезен в плане вычисления вновь созданных спам-страниц. Идентификация сайтов, генерирующих линки на спам-ресурсы может быть лучшим подходом к обнаружению новоявленных спам-документов.
Остальная часть данной работы организованна следующим образом. В Разделе 2 мы даем краткий обзор предшествующих исследований, связанных с вычислением поискового спама, классификацией страниц на основании уникальных локаторов ресурсов и тематической классификации спама. В Разделе 3 мы описываем наш набор данных. В Разделе 4 мы предлагаем рекурсивный алгоритм разложения компонентов сильной связанности (SCC) с узловой фильтрацией, а также демонстрируем различные характеристики компонент сильной связанности. В Разделе 5 мы демонстрируем результаты тематической классификации спам-хостов, принадлежащих ссылочным фермам. В Разделе 6 мы наблюдаем эволюцию линкофармов с позиции их размера и тематики. Наконец, в Разделе 7 мы подводим итоги проведенной нами работы, а также выносим благодарности тем людям, которые помогали нам при ее проведении.
2. Предыдущие работы
Для понимания самой проблематики спама, а также его обнаружения существует ряд исследований. Gyongyi и др. в своей работе [7] представили и классифицировали различные технологии поискового спама. Они также изучили оптимальную гиперссылочную структуру, позволяющую увеличивать значения Google PageRank [8]. Fetterly и др., посредством анализа статистических особенностей ссылок, URL-адресов, резолюций по хостам и содержимому интернет-страниц, продемонстрировали, что выбросы в статистических распределениях с большой долей вероятности указывают на спам-документы [9]. В задачах вычисления гиперссылочного спама, Gyongyi и др. предложили алгоритм доверия TrustRank [10], специально-настроенный (смещенный) PageRank, при котором ранговые оценки распространялись из исходного набора хороших страниц через исходящие с них гиперссылки. В результате чего, спам-документы получали низкую оценку TrustRank, в то время как легитимным страницам присваивалась высокая доверительная оценка. Benczur и др. представили алгоритм SpamRank [11], которой проверял распределение оценок PageRank по всему ссылочному окружению, цитирующего целевой документ. В том случае, если данное распределение оказывалось ненормальным, SpamRank рассматривал целевой документ как спам и пессемизировал его. Saito и др. использовали для вычисления ссылочного спама графовый алгоритм [6]. Они разложили веб по компонентам сильной связанности и обнаружили, что крупные компоненты содержат спам с высокой долей вероятности. Они извлекли ссылочные фермы из ядра посредством изучения максимальной клики (maximal clique). Данная работа схожа с текущей в том смысле, что здесь мы также запускаем алгоритм разложения SCC по веб-графу, однако для извлечения ссылочных ферм из ядра вместо изучения клики максимального размера мы используем рекурсивный алгоритм разложения компоненты сильной связанности. Существует ряд научных работ, связанных с классификацией интернет-страниц посредством использования уникальных локаторов ресурсов. Kan and Thi предложили методологию классификации документов с помощью URL-адресов и контролируемой модели максимальной энтропии [12]. Указанная ими техника классификации страниц посредством уникальных локаторов ресурсов полезна в том случае, если нам не доступно содержимое исследуемых страниц, документ содержит незначительное количество текстовой информации или в том случае, когда важна скорость обработки данных. Baykan и др. категоризировали легитимные страницы из каталога DMOZ Open Directory Project по 15 тематикам, посредством использования их URL-адресов [13] с высокой степенью аккуратности. Эта работа отличается от нашей в той части, что мы фокусируемся на спам-хостах, а также исследуем их тематику в мануальном режиме. Ma и др. идентифицировали уникальные локаторы ресурсов некачественных сайтов посредством их лексических и хостовых особенностей [14] с высокой степенью аккуратности. Эта работа отличается от нашей в том, что они использовали подозрительные URL-адреса в области почтового спама который был маркирован пользователями и был по умолчанию включён в список. С другой стороны, некоторые исследования классифицировали спам по тематикам. Hulten и др. классифицировали спам в сообщениях электронной почты по типу тех продуктов, которые спамеры пытаются рекламировать [15]. Они мануально проинспектировали 1200 спам-сообщений за период с 2003 по 2004 год, разделив их на 10 категорий. Wang и др. классифицировали ключевые фразы, на которые в значительной степени ориентируются те спамеры, которые используют технологию переадресации для понимания характеристик спама, применяющего автоматические редиректы [16]. Они собрали различные ключевые спам-фразы, которые извлекались из текста ссылочных анкоров на публичных форумах и, на их основании, мануально классифицировали спам по основным 10 тематикам.
3. Набор данных
Для своих экспериментов мы использовали три ежегодных мгновенных снимка ссылочного состояния интернет-архива, описанного на японском языке. Данные мгновенные снимки ссылочного состояния были получены в ходе массивного обхода графа в период с 2004 по 2006 год. Наш краулер использует стратегию обхода веб-графа, основанную на поиске в ширину за тем исключением, что он фокусируется на страницах, описанных на японском языке. Веб-документы, не относящиеся к доменной зоне .JP, собирались только в том случае, если были написаны на японском языке. Процесс сканирования прекращался в том случае, если в ходе индексации первых нескольких страниц, относящегося к какому-либо сайту, не было обнаружено ни одного документа, описанного на японском языке. Следовательно, наши мгновенные снимки содержали страницы, описанные на различных языках, таких как английский, французский, китайский и т.п. По нашей оценке, основанной на коде символа, общее число интернет-документов, описанных на японском языке, составляло порядка 60%. Наш агент накопления данных не включает в себя явных спам-фильтров, однако он определяет серверы-зеркала и старается индексировать только основные хосты. Таким образом, наш архив включает неотзеркаленные спам-хосты. Мы используем граф хостов, в котором каждый узел представляет собой хост, а каждое ребро между узлами — гиперссылку между страницами, ассоциированными с разными хостами. Мы использовали граф хостов, полученный за 2004, 2005 и 2006 год. В каждый граф мы включали только те хосты, которые присутствовали в нашем архиве за 2006 год, исключая тех, что исчезли в период с 2004 по 2005 год постольку, поскольку определение того, действительно ли они исчезли из веба или не были отсканированы нашим краулером в ходе обхода, представляется достаточно затруднительной задачей. Свойства полученных графов хостов перечислены в Таблице 1.
Таблица 1. Свойства графа хостов, относящегося к японскому вебу
| Год | 2004 | 2005 | 2006 |
| Количество узлов(хостов) | 2.98 млн | 3.70 млн | 4.02 млн |
| Количество рёбер | 67.96 млн | 83.07 млн | 82.08 мн |
4. Распределение ссылочных ферм по размеру
В этом Разделе мы рассмотрим рекурсивный алгоритм разложения компоненты сильной связанности (SCC) с узловой фильтрацией, предназначенного для извлечения ссылочных ферм. Затем мы опишем детали полученных компонентов и оценим их спамоемкость с тем, чтобы подтвердить их причастность к линкофармам.
4.1. Рекурсивное разложение компоненты сильной связанности с узловой фильтрацией.
Для извлечения ссылочных ферм мы разлагаем граф хостов по компонентам сильной связанности. Компонента сильной связанности графа представляет собой подграф, в котором все пары узлов имеют между собой ориентированный путь. Поскольку спам хосты имеют тенденцию к построению плотно-связанных ссылочных структур, можно допустить, что они могли бы формировать SCC. Общеизвестно, что в случае разложения веб-графа мы получаем ядро, наиболее крупную компоненту сильной связанности, которая содержит порядка 30% всех узлов, а также компоненты несколько меньших размеров [17]. Поскольку линкофармы образуют плотно-связанную ссылочную структуру [8], в которой гиперссылки между качественными и некачественными хостами встречаются крайне редко, можно ожидать, что спам-хосты сформируют SCC. В нашей предыдущей работе [6] было доказано, что 95% компонентов сильной связанности, образующихся вокруг ядра, содержащего более 100 сайтов, оказались ссылочными фермами. Однако мы не смогли провести эффективный анализ по обнаружению тех ссылочных ферм, которые были ещё более плотно связаны в ядре. Мы взялись расширить предшествующую работу посредством введения в наше исследование рекурсивного алгоритма разложения компоненты сильной связанности с узловой фильтрацией. Для начала мы отсекаем узлы, имеющие малую степень, непосредственно от ядра, а затем рекурсивно применяем алгоритм разложения SCC к усеченному ядру со степенью, возросшей до предельно-допустимого порогового значения. Иными словами, после того, как мы разложили граф хостов по SCC, мы удаляем из ядра те хосты, которые имеют полустепень исхода и захода меньшую чем 2, а затем снова разлагаем оставшиеся в нем хосты. В результате чего мы можем извлечь более плотные SCC из самого ядра. Далее, мы исследуем крупнейшую компоненту сильной связанности на предмет новых SCC, удаляя уже те хосты, которые имеют полустепень исхода и захода меньшую чем 3, и снова применяем алгоритм разложения к оставшимся хостам. Данный процесс выполняется рекурсивно с увеличением предельно допустимого порогового значения узловой степени и продолжается до тех пор, пока мы не получим крупные компоненты сильной связанности. В настоящей работе мы используем следующую терминологию:
4.2 Распределение компонент сильной связанности по размеру
Результаты разложения графовых уровней 1, 2, 5 и 10 за 2004, 2005 и 2006 года представлены в Таблице 2, 3 и 4 соответственно.
Таблица 2.Количество хостов и различных уровней компонент сильной связанности за 2004 год.
| Уровень | 1 | 2 | 5 | 10 |
| # хостов | 2.978.223 | 556.190 | 302.613 | 196.218 |
| # SCC | 1.888.550 | 9.055 | 612 | 127 |
| Размер ядра | 749.166 | 520.554 | 301.120 | 195.926 |
| (%) | 25.15 | 93.6 | 99.51 | 99.85 |
Таблица 3. Количество хостов и различных уровней компонент сильной связанности за 2005 год.
| Уровень | 1 | 2 | 5 | 10 |
| # хостов | 3.702.029 | 949.742 | 517.057 | 329.990 |
| # SCC | 2.188.035 | 12.633 | 830 | 135 |
| Размер ядра | 1.271.253 | 890.703 | 512.370 | 329.290 |
| (%) | 34.34 | 93.78 | 99.1 | 99.79 |
Таблица 4. Количество хостов и различных уровней компонент сильной связанности за 2006 год.
| Уровень | 1 | 2 | 5 | 10 |
| # хостов | 4.017.250 | 918.826 | 499.031 | 315.644 |
| # SCC | 2.483.446 | 12.182 | 899 | 215 |
| Размер ядра | 1.245.152 | 872.269 | 495.451 | 314.950 |
| (%) | 31.00 | 95.00 | 99.28 | 99.78 |
Удельный вес ядра увеличивается в размерах между первым и вторым уровнем, и остается стабильным после второго уровня на протяжении всех лет. Это означает, что хосты в ядре веба плотно связанны. Рисунок 2 демонстрирует распределение размеров компонент сильной связанности различных уровней за каждый год.
Рисунок 2. Распределение компонент сильной связанности по размеру за 2004 год (верхнее изображение), 2005 год (серединное изображение) и 2006 год (нижнее изображение). Каждый график демонстрирует распределение компонент сильной связанности по размеру для различных уровней.
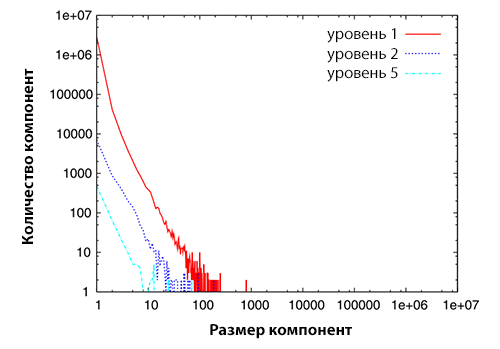
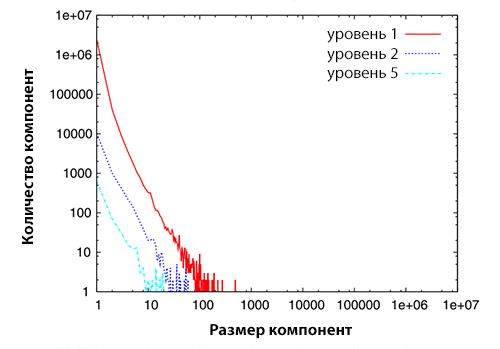
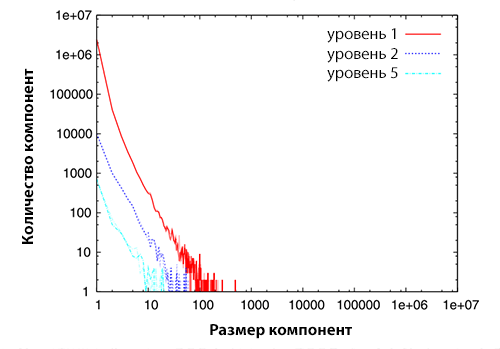
По оси абсцисс отложен размер компонент сильной связанности, а по оси ординат — количество самих компонент. Глядя на Рисунок 2, можно видеть, что распределение компонент сильной связанности следует степенному закону распределения, что согласуется с исследованием, проведенным Broder и др. [17]. Кроме того, мы обнаруживаем, что распределение компонент сильной связанности по размеру для различных уровней отражает аналогичные показатели степенного распределения, что отражено в Таблице 5.
Таблица 5. Показатель распределения компонент сильной связанности по размеру.
| Уровень/Год | 1 | 2 | 3 |
| 2004 | -2.50 | -2.50 | -2.67 |
| 2005 | -2.44 | -2.60 | -2.52 |
| 2006 | -2.45 | -2.54 | -2.29 |
Обратите внимание на то, что аномальное распределение обнаруживается на хвосте всякого графика, представленного на Рисунке 2. Данный феномен особенно четко выражен в тех компонентах сильной связанности, чей размер превышает 100. Мы оценили спамоемкость подобных SCC и обнаружили, что крупные компоненты сильной связанности содержат более 100 хостов, которые по все вероятности, являются спамом. Подробное описание указанного исследования приводится в подразделе 4.3.
Рисунок 3. Структура первого и второго уровня компонент сильной связанности за 2004 год (верхнее изображение), за 2005 год (серединное изображение) и 2006 год (нижнее изображение). Первый и второй уровень SCC демонстрируют схожую структуру за все три года.

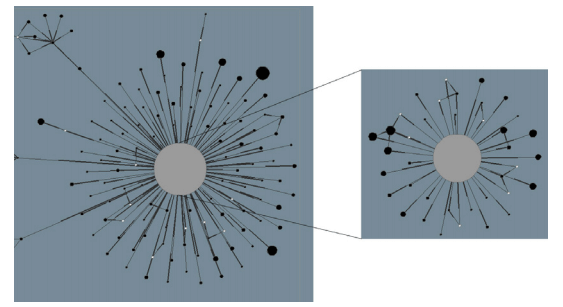
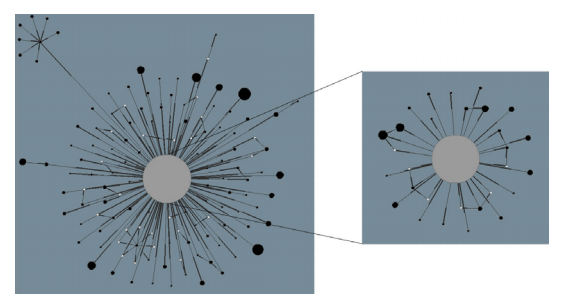
Рисунок 3 иллюстрирует общую структуру первого и второго уровня компонент сильной связанности за тройку лет. В левой части изображения вы можете видеть структуру первого уровня компонент сильной связанности, в то время как в правой его части отражен второй уровень. Большой серый узел олицетворяет собой ядро, черные узлы представляют собой те SCC, которые имеют более 100 узлов; белые узлы — это малые компоненты сильной связанности, которые соединены с большими SCC. Размер узлов отражает количество хостов, содержащихся в некоторой SCC. Две компоненты сильной связанности соединяются ориентированным ребром в том случае, если между содержащимися в них хостами существует гиперссылка, ведущая от одной компоненты к другой. Каждое ребро начинается у толстого конца и заканчивается тонким. Сравнивая левую и правую стороны Рисунка 3, можно увидеть, что как первый, так и второй уровни компонент сильной связанности демонстрирую схожую структуру. Кроме того, наиболее крупные SCC напрямую связаны с ядром. Некоторые крупные компоненты формируют масштабную гиперссылочную структуру, посредством их подключения к прочим крупным компонентам. Мы также исследовали то, каким образом первый уровень SCC связывался со вторым их уровнем. К нашем всеобщему удивлению мы обнаружили, что большинство компонент сильной связанности первого уровня были напрямую подключены к ядру второго уровня. Иными словами, даже на различных уровнях веб-графа ссылочные фермы были изолированы друг от друга. Это означает, что большинство линкофармов изолированы друг от друга.
4.3 Спамоемкость компонент сильной связанности
После извлечения компонент сильной связанности, мы оценили их спамоемкость для того, чтобы проверить их принадлежность к ссылочным фермам. Для оценки спамоемкости мы использовали особенности имен хостов, опираясь на исследование, которое было проведено Fetterly и др. [9] и Becchetti и др. [18]. Мы использовали две метрики: длина имени хоста (hostname) и наличие в нем спам-ориентированных ключевых фраз, то есть таких фраз которые часто употребляются спамерами. Оценка длины хостнеймов заключается в прямом подсчете символов в каждом из них. В спамерских кругах всегда существовала тенденция генерировать длинные URL-адреса (например, «sample-job-reference-letters.974.us»), которые включали бы в себя такие ключевые слова, как «porn», «casino», «cheap», «download» и т.п. (Для всех хостов, наличествующих в нашем наборе данных, средняя длина хостнеймов составляла 24.25 символа; процент хостнеймов, которые содержали в себе спам-ориентированные ключевые слова составлял 8.97%).
Спам-ориентированные ключевые слова были получены нами следующим образом. Сначала мы извлекли из нашего интернет-архива за 2004 год компоненты сильной связанности, которые содержали в себе более 1000 хостов. В данным SCC мы разбили хостнеймы данных хостов на токены по небуквеннеым символам (точкам, тире и цифрам). Затем, мы сформировали из них перечень наиболее часто встречающихся токенов и мануально выбрали из 1000 лексем, имеющих наибольшую частоту встречаемости, 114 токенов в качестве спам-ориентированных ключевых слов. Эти спам-ориентированные слова содержали термины, относящиеся к различным языкам, в том числе английскому, испанскому, итальянскому, французскому и японскому; это позволяло обнаруживать спам в именах хостов, составленных на различных национальных языках. В дополнение к указанным спам-ориентированным словам мы рассматривали первое поле имени хоста в качестве спам-слова в том случае, если оно содержало в себе исключительно те символы, которые не относились к алфавиту, а именно тире или цифры (например, «123-vakantiehuis.nl»). Мы провели исследование на предмет того, может ли длина имени хоста и наличие в нем спам-ориентированных слов послужить корректной оценкой спамоемкости SCC. Мы рандомно выбрали 100 хостов из всего их множества и проанализировали зависимость между спамоемкостью и длиной хостнеймов. Таблица 6 демонстрирует нам, что процент спам-хостов возрастает параллельно увеличению длины хостнеймов.
Таблица 6. Процент спам-хостов для хостнеймов различной длины.
| Длина хостнейма | Всего хостов | Спам-хостов | Спам-хостов (%) |
| 1-19 | 33 | 6 | 18.2% |
| 20-29 | 35 | 13 | 37.1% |
| 30-39 | 15 | 7 | 46.7% |
| 40-49 | 5 | 5 | 100.0% |
| 50-59 | 6 | 6 | 100.0% |
| 60-69 | 3 | 3 | 100.0% |
| 70-79 | 1 | 1 | 100.0% |
| 80-89 | 0 | 0 | 0.0% |
| 90-99 | 2 | 2 | 100.0% |
| Всего | 100 | 43 | 43% |
Следует особо подчеркнуть, что все хосты, которые имели длину хостнейма превышающую 40 символов, оказались спамом. С другой стороны, мы выбрали случайным образом 100 хостов хостнеймы которых содержали более чем одно спам-ориентированное слово. Мануальная оценка показала, что 98% данных хостов оказались спамом. Мы проанализировали среднюю дину хостнейма хостов в компонентах сильной связанности, а также процент хостов, которые содержали в хостнейме спам-ориентированные ключевые слова. В том случае, если SCC демонстрировала усредненное значение с большой длиной хостнейма или высокий процент имен хостов, содержащих спам-ориентированные ключевые слова, то такая компонента сильной связанности рассматривалась нами как имеющая высокую спамоемкость. Рисунок 4, 5 и 6 демонстрируют результаты нашего эксперимента по оценке спамоемкости SCC.
Рисунок 4. Спамоемкость компонент сильной связанности первого уровня: Усредненная длина хостнейма (слева) и процент хостнеймов, содержащих спам-ориентированные ключевые слова (справа)
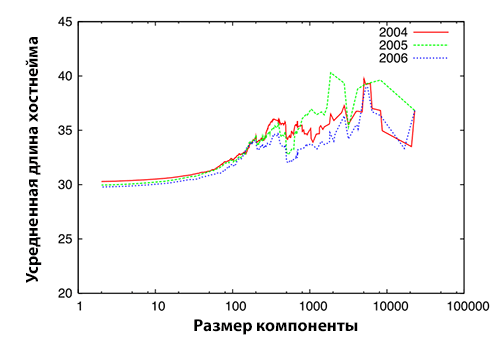
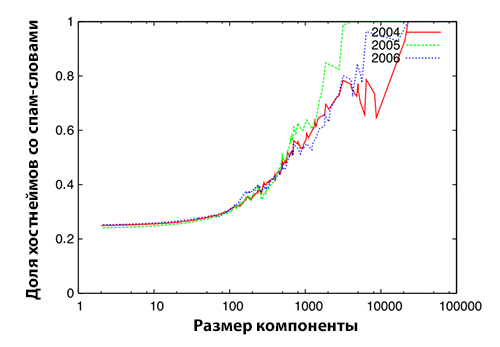
Рисунок 5. Спамоемкость компонент сильной связанности второго уровня: Усредненная длина хостнейма (слева) и процент хостнеймов, содержащих спам-ориентированные ключевые слова (справа)
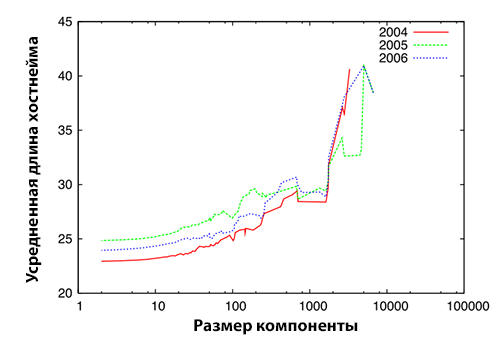
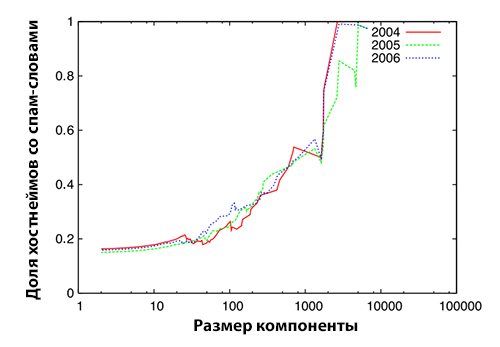
Рисунок 6. Спамоемкость компонент сильной связанности четвертого уровня: Усредненная длина хостнейма (слева) и процент хостнеймов, содержащих спам-ориентированные ключевые слова (справа)
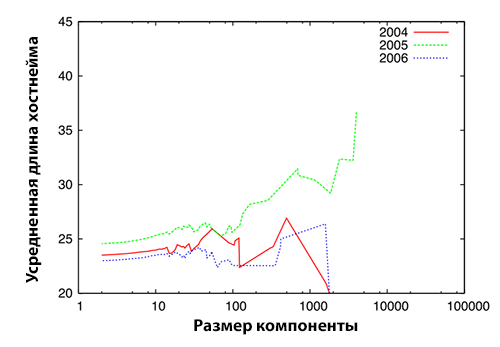

Ось абсцисс, которая отражает размер SCC, всех трех рисунков выражена в логарифмической шкале. Мы проанализировали спамоемкость компонент сильной связанности различных уровней за исключением ядра. Можно увидеть, что по мере увеличения размера SCC усредненная длина хостнейма, а также процент хостнеймов, содержащих по крайней мере одно спам-ориентированное ключевое слово, также возрастают. Это указывает на то, что компоненты сильной связанности с относительно большим числом хостов (особенно, более 100) отличаются высокой спамоемкостью, что согласуется с результатами исследования, проведенного в [6]. Поскольку ряд больших SCC на более глубоких уровнях демонстрируют меньшую спамоемкость, как это можно увидеть из Рисунка 6, мы решили мануально проинспектировать их хосты на предмет возможного отнесения последних к спаму. Их хостнеймы оказались короткими и состояли из ряда спам-ориентированных ключевых слов без небуквенных символов (например, «dvdporno.net») или содержали в себе только цифры и отдельные символы (например, «ib5.x1024.com»). Таким образом, мы доказали, что те большие компоненты сильной связанности, чей размер превышает 100 хостов, обладают высокой спамоемкостью, а, следовательно, в них более вероятно существование ссылочных ферм. Таблица 7 перечисляет количество компонент сильной связанности, чей размер превышает 100 хостов с указанием их количества в каждой из этих SCC.
Таблица 7. Количество компонент сильной связанности (размер превышает 100 хостов) и число хостов в каждой из них.
| Год | Уровень | 1 | 2 | 3 | 4 | 5 | Всего |
| 2004 | #SCC | 228 | 24 | 7 | 9 | 2 | 270 |
| #хостов | 182.285 | 18.650 | 9.306 | 5.032 | 242 | 215.515(7.2%) | |
| 2005 | #SCC | 167 | 32 | 18 | 13 | 7 | 237 |
| #хостов | 95.347 | 38.111 | 8.236 | 15.566 | 2.789 | 160.049(4.3%) | |
| 2006 | # SCC | 180 | 26 | 21 | 6 | 8 | 241 |
| #хостов | 146.015 | 26.127 | 11.092/td> | 9.084 | 1.499 | 193.817(4.8%) |
Учитывая, что крупные SCC имеют большую вероятность оказаться спам-фермами, по истечению пяти итераций нашего алгоритма с показателем точности равным 95% мы обнаружили порядка 4.3%-7.2% хостов, которые являлись спамом. Из этого следует, что мы можем удалить целый ряд спам-хостов без какого-либо анализа их содержимого. Для того, чтобы удостовериться в том, сохраниться ли имеющая место быть тенденция, связанная с принадлежностью крупных компонент сильной связанности к линкофармам, по мере углубления к ядру, мы мануально проанализировали имена хостов в крупных SCC с 5-го по 10-ый уровень. Как вы можете обнаружить по данным Таблицы 8, указанная нами тенденция продолжается на более глубоких графовых уровнях.
Таблица 8. Количество ссылочных ферм среди компонент сильной связанности (с размером превышающим 100 хостов) на графах глубокого уровня.
| Год/Уровень | 5 | 6 | 7 | 8 | 9 | 10 |
| 2004 Спам/Всего | 2/2 | 1/2 | 1/2 | 1/1 | 2/2 | 0/0 |
| 2005 Спам/Всего | 6/7 | 3/3 | 3/3 | 1/1 | 1/1 | 1/1 |
| 2006 Спам/Всего | 8/8 | 2/2 | 3/3 | 1/1 | 1/1 | 0/0 |
5. Распределение ссылочных ферм по тематике
В этом разделе мы изучаем тематическую принадлежность спам-хостов в крупных компонентах сильной связанности, которые были получены нами в предыдущем разделе. Мы анализируем тематическую принадлежность спам-хостов и выделяем 7 тем, наиболее подверженных спаму. Для того чтобы проанализировать распределение линкофармов по темам, мы классифицируем хосты в компонентах сильной связанности с первого по пятый уровень, на основании их хостнеймов. Подробный анализ SCC дан в Таблице 9. Из первоначальных 569318 хостов мы удалили дубликаты хостнеймов, получив в итоге 245822 хостов.
Таблица 9. Количество компонент сильной связанности с размером, превышающим 100 хостов, а также число последних в каждой SCC. Мы анализируем компоненты сильной связанности с 1-ый по 5-ый уровень
| # SCC | # хостов в SCC | |
| 2004 | 270 | 215.515 |
| 2005 | 237 | 160.049 |
| 2006 | 241 | 193.817 |
| Всего | 748 | 569.381 |
5.1 Тематика ссылочных ферм
Для того чтобы определить тематику спам-хостов, мы обратились к работе [15], в которой проводилась тематическая классификация почтового спама, и работе [16], где исследовался вопрос, с тематической принадлежностью спама, использующего автоматическую переадресацию. Поскольку особенности гиперссылочного спама отличаются как от спама, использующего редиректы, так и почтового спама, мы удалили и добавили некоторые категории после ручного анализа спам-хостов из нашего набора данных. В итоге, мы имели:
5.2 Тематическая классификация
В этом подразделе мы занимаемся тематической классификацией спам-хостов на основании их хостнеймов и подхода, использующего машинное обучение. В этом подразделе мы вводим технологию для получения достаточного количества помеченных образцов для реализации наших классификационных задач. Для каждой темы мы создаем бинарный классификатор, используя два различных набора данных и два различных обучающих алгоритма. Мы оцениваем производительность классификации, использую метрики точности, полноты и F-меры.
5.2.1 Обучающий и проверочный набор
Для получения достаточного количества помеченных образцов для нашей обучающей выборки мы использовали идентифицированные характеристики ссылочных ферм, по которым малые линкофармы состояли из хостов, имеющих содержимое/хостнеймы относящиеся к одной тематике. Исходя из этого, мы, прежде всего, мануально определили тематику небольшого числа хостнеймов в малой линкоферме; в том случае, если они оказывались идентичными теме t, мы помечали оставшиеся хостнеймы в этой ферме как относящиеся к тематике t. Мы отобрали компоненты сильной связанности, имеющих размер от 100 до 180 хостов в качестве малых ссылочных ферм. Среди подобного рода 229 компонентов сильной связанности, мы исключили 23 SCC по причине наличия в них бессмысленных хостнеймов (например, thjy.cq.focus.cn, quicklink38.netfirms.com). Мы также исключили 80 SCC постольку, поскольку они содержали имена хостов, которые не попадали ни под одну из семи тематик, описанных нами в подразделе 5.1. Эти компоненты сильной связанности содержали хосты с локальной информацией или были посвящены реализации специфичной продукции (например, philadelphia.pa.local-weather.ws, york-florists.co.uk). В 31 SCC среди оставшихся 196 компонент мы обнаружили хосты, которые не имели определенной тематической принадлежности, то есть попадали под категорию универсальных: сайты-виртуальные торговые ряды, включающие хосты, рекламирующие всевозможную продукцию; сайтов, торгующие доменными именами, которые содержали в себе хосты, рекламирующие доменные имена различных тематик. Таблица 10 демонстрирует число компонент сильной связанности, имеющих ярко выраженную единственную тематическую принадлежность и количество хостов в каждой теме.
Таблица 10. Число компонент сильной связанности (с размером от 101 до 180 хостов) и количество хостов, связанных с каждой темой.
| Категория | # SCC | # хостов |
| Взрослая тематика | 78 | 6.082 |
| Сомнительно | 3 | 330 |
| Финансы | 10 | 658 |
| Азартные игры | 14 | 938 |
| Работа | 18 | 1.048 |
| Мобильный телефоны | 11 | 642 |
| Путешествия | 31 | 2.250 |
| Всего | 165 | 11.948 |
По истечению анализа 165 SCC в нашем распоряжении оказалось 11948 обучающих образцов. Мы построили семь бинарных классификаторов. Каждый из них проверял заданное имя хоста на предмет его связи с той или иной темой, например, «Взрослая тематика» или «НЕ-взрослая тематика». Мы создали семь различных обучающих и проверочных наборов, изменяя положительные и негативные метки зафиксированных хостнеймов. Например, имя хоста «sample-job-reference-letters. 974.us» является положительным образцом для классификатора «Работа», в то время как для остальных классификаторов оно является негативным образцом. Таким образом, соотношение положительных и негативных образцов становится 1 к 6 по всем обучающим и проверочным наборам.
Для того чтобы удостовериться в том, что помеченные в качестве ссылочных ферм хостнеймы смогут улучшить производительность нашей классификации, мы обучили классификаторы с использованием двух наборов данных: набор H, состоящий только из мануально маркированных хостнеймов, и набор HS, состоящий как из мануально маркированных хостнеймов, так и из хостнеймов, извлеченных из помеченных компонент сильной связанности. Для набора данных H мы подготовили 150 мануально маркированных хостнеймов для каждой темы. Для набора данных HS мы подготовили 75 мануально маркированных хостнеймов и 75 хостнеймов, извлеченных из помеченных компонент сильной связанности для каждой темы. Таким образом, каждый набор имел 1050 хостнеймов (150 имен хостов x 7 тематик). Для оценки производительности тематических классификаторов мы провели 30 испытаний; в каждом испытании наборы данных H и HS разбивались случайным образом на обучающие множества SH и SHS, содержащих 100 положительных и 600 негативных образцов. SH включал в себя 100 положительных образцов, помеченных нами в ручную. SHS включал в себя 50 положительных образцов, также помеченных нами в ручную, и 50 положительных образов, извлеченных из компонент сильной связанности. SH и SHS использовались для обучения классификаторов, а его результаты были проверены на фиксированных обучающих наборах. После проведения всех испытаний, только для одной тематики нами было получено 30 результатов классификации по каждому набору данных, а также выведено среднее значение в качестве итоговой оценки. Для проверочных наборов мы выбрали 700 хостнеймов (100 имен хостов x 7 тематик) содержимое которых было проанализировано нами вручную. Мы изменили положительные и отрицательные метки данных хостнеймов для создания семи различных проверочных наборов. По каждой тематике мы не извлекали обучающие образцы из компонент сильной связанности, из которых извлекалась обучающая выборка.
5.2.2 Особенности и алгоритмы
В качестве особенностей мы использовали n-граммы, которые широко распространены в задачах текстовой классификации веб-страниц [19], [20]. N-грамм представляет собой последовательность n-символов. Например, мы можем разделить хостнейм «мотельдешево» на семь 5-грамм, включая мотель, отельд, тельде, ельдеш, льдеше, ьдешев и дешево. Для создания n-граммов из хостнеймов, каждое имя хоста прописывается в нижнем регистре и разбивается на лексемы с помощью знаков препинания, цифр или других символов, не относящихся к алфавиту, которые могут использоваться в качестве разделителей токенов. Для получения лексем мы удалили токены, длина которых была меньше чем два символа, а также те из них, что начинались двумя одинаковыми символами. Мы также удалили такие токены, как wwww, com по той простой причине, что они имеют высокую частоту обнаружения в уникальных локаторах ресурсов. таким образом, URL-адрес free-download-ringtones.com токенизировался как free, download и ringtones. В общей сложности, мы получили 61221 лексему. Мы экстрагировали 3, 4, 5, 6, 7 и 8 грамм из данных токенов. Итоговое количество n-граммных особенностей составляло 530224. В задачах обучения мы использовали как пакетный, так и онлайновый алгоритм обучения для проверки того, сможем ли мы выполнить тематическую классификацию вне зависимости от использования алгоритмов обучения. Для пакетного обучения мы использовали машину опорных векторов (SVM) с линейным ядром, а именно ее популярную реализацию SVMLight [24]. Для онлайнового обучения мы использовали алгоритм обучения взвешенный по доверию (CW) [21], [22], а именно его реализацию oll [23]. В процессе онлайнового обучения, мы перемешиваем эталонные данные и проводим обучение классификаторов в ходе 20 итераций.
5.2.3 Результаты классификации
Мы построили классификатор с использованием различных подходов к маркировке и алгоритмов машинного обучения. Результаты классификации представлены в Таблице 11 и Таблице 12. В качестве оценки производительности классификации мы использовали метрики точности (P), полноты (R) и F-меру (F).
Таблица 11. Результаты классификации с использованием различных наборов данных и SVM.
| H | HS | HSALL | |||||||
| Точность | Полнота | F-мера | Точность | Полнота | F | Точность | Полнота | F-мера | |
| Взрослая тематика | 0.956 | 0.811 | 0.877 | 0.943 | 0.821 | 0.876 | 0.866 | 0.900 | 0.882 |
| Сомнительные продукты | 1.000 | 0.992 | 0.996* | 1.000 | 0.985 | 0.992 | 1.000 | 0.990 | 0.995 |
| Финансы | 0.937 | 0.796 | 0.859 | 0.975 | 0.783 | 0.868 | 0.988 | 0.815 | 0.893 |
| Азартные игры | 0.947 | 1.000 | 0.973 | 0.980 | 0.995 | 0.987* | 0.985 | 0.985 | 0.985 |
| Работа | 0.994 | 0.799 | 0.884 | 0.990 | 0.949 | 0.969* | 1.000 | 0.950 | 0.974 |
| Мобильные телефоны | 0.996 | 0.911 | 0.951 | 0.990 | 0.947 | 0.968* | 0.975 | 0.930 | 0.952 |
| Путешествия | 0.973 | 0.900 | 0.935 | 0.975 | 0.900 | 0.936 | 0.968 | 0.905 | 0.935 |
| В среднем | 0.972 | 0.887 | 0.925 | 0.979 | 0.911 | 0.942 | 0.969 | 0.925 | 0.945 |
Таблица 12. Результаты классификации с использованием различных наборов данных и CW.
| H | HS | HSALL | |||||||
| Точность | Полнота | F-мера | Точность | Полнота | F | Точность | Полнота | F-мера | |
| Взрослая тематика | 0.970 | 0.791 | 0.871 | 0.977 | 0.801 | 0.880 | 0.919 | 0.890 | 0.904 |
| Сомнительные продукты | 1.000 | 0.988 | 0.994 | 1.000 | 0.988 | 0.994 | 1.000 | 0.990 | 0.995 |
| Финансы | 0.912 | 0.949 | 0.929 | 0.989 | 0.868 | 0.922 | 0.994 | 0.890 | 0.937 |
| Азартные игры | 0.977 | 1.000 | 0.989 | 0.974 | 0.998 | 0.986 | 0.990 | 0.995 | 0.993 |
| Работа | 1.000 | 0.756 | 0.859 | 1.000 | 0.903 | 0.949* | 1.000 | 0.965 | 0.983 |
| Мобильные телефоны | 0.989 | 0.928 | 0.957 | 0.990 | 0.953 | 0.971* | 0.995 | 0.960 | 0.977 |
| Путешествия | 0.963 | 0.900 | 0.931 | 0.962 | 0.900 | 0.930 | 0.973 | 0.900 | 0.936 |
| В среднем | 0.973 | 0.902 | 0.933 | 0.985 | 0.916 | 0.947 | 0.982 | 0.941 | 0.961 |
В случае использования для обучения набора HS общая производительность классификации улучшается. Среднее улучшение F-меры составляет 1.7% в случае обучения классификаторов с использованием SVM и 1.3% в случае использовании CW. Показатели F-меры отмечаются звездочкой в Таблице 11 и Таблице 12 в том случае, если они были лучше с 95% уверенности по t-проверке. Видно, что используя SVM, обучение классификаторов по набору HS существенно превосходит данную доверительную отметку по трем тематикам, в то время как классификаторы, обученные по набору H, превосходят доверительную отметку только по одной тематике. Используя CW, обучение классификаторов по набору HS существенно превосходят доверительную отметку по двум темам, в то время как классификаторы, обученные по набору H, не смогли преодолеть доверительную отметку ни по одной тематике. Улучшение, продемонстрированное по набору HS во многом обусловлено увеличением показателя полноты, который означает, что используя хостнеймы, извлеченные из маркированных компонент сильной связанности, идентифицирует спам-хосты, которые было бы невозможно вычислить в случае применения исключительно мануально помеченных хостнеймов. С другой стороны, высокое значение F-меры достигалось на обучающем наборе HS вне зависимости от использования алгоритмов обучения. Обратите внимание, что мы использовали схожие обучающие/проверочные наборы для двух алгоритмов. Мы построили классификатор, используя все доступные обучающие образцы для получения наилучшего результата классификации. Мы также подготовили набор данных HSall, который содержал в себе 150 хостнеймов отмаркированных вручную, а также 200 хостнеймов, извлеченных из маркированных SCC для каждой темы. В общей сложности, HSall содержал 2450 образцов (350 x 7 тематик). Усредненная F-мера составляла 0.945 в случае использования SVM и 0.961 в случае использования CW.
6. Эволюция ссылочных ферм
В Разделе 4 и 5 мы доказали, что крупные компоненты сильной связанности с размером более 100 хостов имеют большую вероятность оказаться ссылочной фермой; после чего мы классифицировали тематическую принадлежность хостов в линкофармах с высокой степенью аккуратности. В текущем Разделе мы изучаем темпоральные изменения, затрагивающие распределение ссылочных ферм по размеру и тематике, посредством использования графов хостов, полученных за три года.
6.1 Рост ссылочных ферм
Мы исследовали изменения в увеличении размеров и темпах роста компонент сильной связанности используя метрики эволюции, использованные в [25]. В текущей работе мы фокусируемся на увеличении и сокращении размеров SCC, применяя следующие обозначения:
Для понимания того, как какие эволюционные изменения претерпела какая-либо единственная компонента сильной связанности C(tk), мы находим SCC, которая соответствует C(tk) по времени tk−1. Данная SCC C(tk−1) представляет собой SCC, которая имеет больше всего общих хостов с C(tk). Когда во времени tk−1 существует несколько компонент сильной связанности, имеющих одинаковое число общих хостов с C(tk), мы выбираем наиболее крупную SCC как соответствующую заданной SCC. Пара (C(tk),C(tk−1)) называется стволом, основной ветвью (mainline). Мы наблюдали изменения в увеличении размеров и темпах роста основных ветвей с 2004 по 2005, а также с 2005 по 2006 гг. Темп роста C(tk) определяется как N(C(tk))/N(C(tk−1)). Рисунок 7 демонстрирует годовое изменение в размерах SCC , а Рисунок 8 — темпы роста ее размера.
Рисунок 7. Эволюционные изменения в размерах компоненты сильной связанности с 2004 по 2005 год (слева) и с 2005 по 2006 год (справа).

Рисунок 8. Темпы роста размера компоненты сильной связанности с 2004 по 2005 год (слева) и с 2005 по 2006 год (справа).
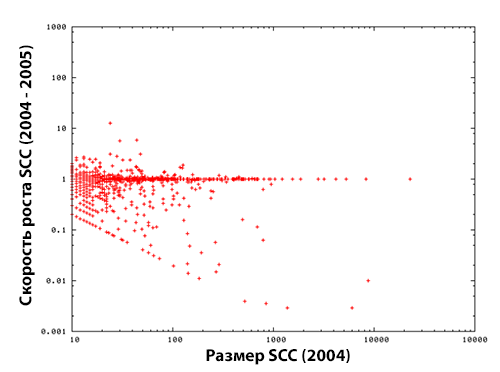
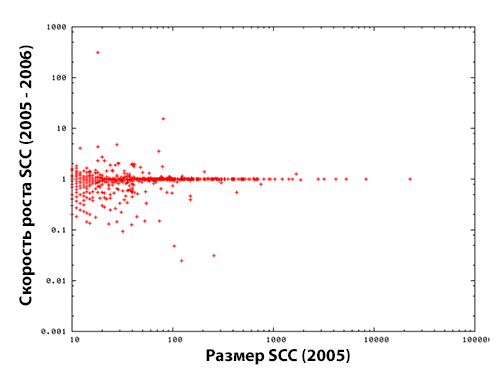
Глядя на все изображенные выше графики, можно заметить, что размер большинства компонент сильной связанности остается с течением времени стабильным. Стабильность проявляется тем больше, чем больше увеличивается размер самой SCC. Учитывая, что подавляющее число крупных компонент являются ссылочными фермами, можно ожидать, что расширение линкофармов оказывается практически несущественным. Следует также учесть, что ряд крупных SCC, содержащих более 1000 хостов, существенно сократились по своему размеру в период с 2004 по 2005 год, что можно наблюдать на правой нижней части левых графиков Рисунков 7 и 8. А если учесть тот факт, что крупные компоненты сильной связанности имеют наибольшую вероятность оказаться ссылочными фермами, подобное снижение может указывать на отказ спамеров от крупных линкофармов и, таким образом, их раздроблению на более малые ссылочные фермы. В нашей предыдущей работе мы использовали граф за 2004 год, который содержал хосты, исчезнувшие в 2005 году; тогда мы обнаружили, что большинство SCC с размером превышающим 100 хостов были линкофармами [6]. Поскольку в текущем исследовании мы использовали граф, который не включал исчезнувшие хосты, здесь более корректным является утверждение о сокращении ссылочных ферм. Если мы учтем исчезнувшие хосты, тогда тенденция сокращения ссылочных ферм станет более понятной. Интересным является то, что мы подтвердили, что темпы роста относительно малых компонент сильной связанности (с размером от 10 до 100 хостов) следуют Закону Жибра. А именно, темпы роста SCC не зависят от ее предыдущего размера (Согласно закону Жибра темпы роста фирмы не зависят от ее размера, а определяются случайным образом; в работе [26] подтверждаются некоторые взаимозависимости между степенным законом распределения компаний по размеру и законом Жибара).
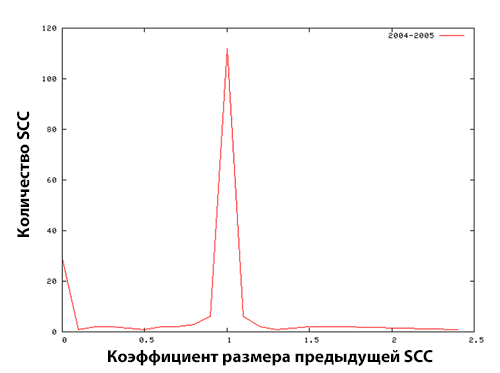
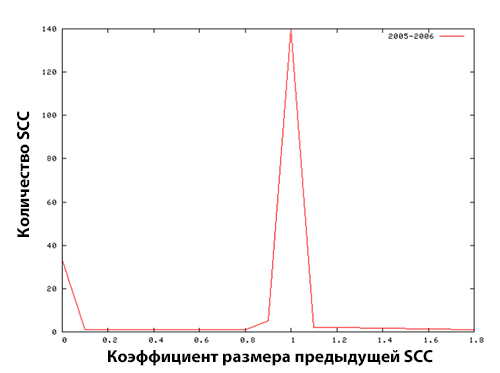
Для дальнейшего понимания эволюции ссылочных ферм, мы исследовали предыдущий размеры крупных компонентов сильной связанности. Мы рассчитали N(C(tk−1))/N(C(tk)) для C(tk), чей показатель N(C(tk)) превышал 100 хостов. Результаты нашего исследования продемонстрированы на Рисунке 9, где ось абсцисс представляет собой отношение предыдущего размера к текущему, а ось ординат — количество SCC. Коэффициент 0 означает, что все хосты только что включены в ссылочные фермы на временном этапе tk или то, что ссылочные фермы сформировались из ряда очень малых SCC; коэффициент 1 означает, что размер линкофармов не изменился со временем; Всплески наблюдаются при значениях коэффициента размера равного 0 и 1. Это означает, что большинство крупных ссылочных ферм появляются в первый год или то, что они хорошо поддерживаются на протяжении всего первого года.
Рисунок 9. Распределение предыдущего размера крупных компонент сильной связанности в 2005 (слева) году и 2006 (справа) году.
6.2 Тенденции, наблюдаемые в ссылочных фермах
В этом разделе мы исследуем темпоральные изменения в тематическом распределении спам-хостов, используя наши классификаторы, которые в Разделе 5 идентифицировали с высокой степенью аккуратности тематическую принадлежность спам-хостов. Мы классифицировали тематическую принадлежность всех спам-хостов в крупных SCC с первый по пятый уровень (См. Таблицу 7) из нашего интернет-архива, полученного за три года. Результаты представлены в Таблице 13.
Таблица 13. Тематическое распределение за три года.
| Взрослая тематика | Путешествия | Мобильный телефоны | Работа | Сомнительная продукция | Финансы | Азартные игры | Прочее | |
| 2004 | 50.7 | 11.9 | 4.8 | 2.2 | 2.9 | 0.8 | 0.6 | 26.2 |
| 2005 | 49.6 | 15.5 | 4.4 | 1.1 | 1.7 | 0.8 | 0.7 | 26.1 |
| 2006 | 51.4 | 13.0 | 3.7 | 2.2 | 0.9 | 0.8 | 0.6 | 27.4 |
Напомним, что наш классификатор не классифицировал те хостнеймы, которые не попадали ни под одну из 7 тематик, описанных подразделе 5.1. Они просто помещались в категорию «Прочее». Кроме того, порядка 3% хостнеймов каждый год попадали в более чем одну категорию. Мы также включили данные имена хостов в категорию «Прочее». Как Вы можете видеть по данным Таблицы 13, распределение ссылочных ферм по тематикам на протяжение трех лет практически не изменяется. Все это время наиболее доминирующей категорией является тема «Для взрослых», что согласуется с исследованием почтового спама, проведенного в работе [15]. Ежегодно она формирует более 60% всех спам-хостов. Второй по популярности категорией в среде спамеров является тематика «Путешествия». Количество спам-хостов, относящихся к теме путешествий в десять раз превышает объем спам-хостов, попадающих под категорию «Финансы». Процент хостов, которые были отнесены в категорию «Прочее» также практически не меняется. Мы проанализировали частоту и отранжировали спам-ориентированные ключевые слова за каждый год, и обнаружили, что за каждый год они отличаются. На Таблице 14 и 15 представлен перечень из 10 ключевых слов, имеющих наибольшую частоту употребления в хостнеймах, относящихся к теме «Финансы» и «Мобильные телефоны».
Таблица 14. Спам-ориентированные ключевые слова, имеющие наибольшую частоту употребления в хостнеймах, относящихся к тематике «Финансы» за 2004, 2005 и 2006 год. Слово «kredite» означает кредит на немецком языке. Термины «отчет» и «проверка» относятся к справкам (отчетам) о кредитоспособности потенциального заемщика.
| 2004 | 2005 | 2006 | |||
| Запрос | Частота | Запрос | Частота | Запрос | Частота |
| card | 207 | credit | 202 | loan | 169 |
| loan | 206 | loan | 143 | card | 162 |
| credit | 202 | card | 136 | credit | 133 |
| insurance | 126 | cards | 88 | cards | 106 |
| cards | 117 | mortgage | 77 | insurance | 103 |
| mortgage | 102 | insurane | 76 | mortgage | 86 |
| home | 58 | kredite | 70 | kredite | 70 |
| loans | 58 | report | 54 | car | 50 |
| car | 55 | finder | 49 | home | 49 |
| personal | 52 | reports | 45 | loans | 49 |
Таблица 15. Спам-ориентированные ключевые слова, имеющие наибольшую частоту употребления в хостнеймах, относящихся к тематике «Мобильные телефоны» за 2004, 2005 и 2006 год. Слова «sonneries», «toques», «polyphonic» и «klingeltoene» обозначают «рингтоны» на различных языках. Термин «loghi» значит «логотип», а «ecran» происходит от «fond d’ecran», что по-французски означает «тема» (для мобильных телефонов).
| 2004 | 2005 | 2006 | |||
| Запрос | Частота | Запрос | Частота | Запрос | Частота |
| sonneries | 2969 | ringtones | 1202 | ringtones | 1203 |
| ringtones | 1933 | nokia | 1133 | nokia | 1132 |
| nokia | 1645 | logos | 1064 | logos | 1072 |
| portable | 1485 | xsonnerie | 929 | xsonnerie | 929 |
| sonnerie | 1291 | suonerie | 844 | suonerie | 843 |
| portables | 1240 | loghi | 813 | loghi | 812 |
| polyphoniques | 1200 | polyphonic | 721 | klingeltoene | 725 |
| logos | 1189 | klingeltoene | 715 | polyphonic | 721 |
| ecran | 1177 | toques | 712 | toques | 712 |
| klingeltoene | 1105 | ringetoner | 561 | ringetoner | 561 |
Вопреки тому, что по данным Таблицы 13 на протяжении всех трех лет процент спам-хостов, попадающих под категорию «Финансы», практически не изменился, по данным Таблицы 14, позиции и частота встречаемости спам-ориентированных слов оказались подвержены динамическим изменениям. Например, в 2005 году среди наиболее часто встречаемых слов появляются такие слова, как «отчет», «проверка» и «отчеты», а присутствовавшие ранее «машина» и «дом», наоборот, исчезают. С другой стороны, по мере снижения удельного веса «Мобильных телефонов» по данным Таблицы 13 на протяжении всех трех лет, и в этой категории в 2005 году появляются такие новые слова как «xsonnerie» и «toques», а частота обнаружения некоторых из них в 2006 году только возрастает; Таблица 15 демонстрирует, что после 2005 года, доминирующее ранее ключевое слово «sonneries» исчезает из списка.
7. Заключение
В текущей работе мы изучили эволюцию, а также общее распределение ссылочных ферм по размеру и тематической принадлежности на крупномасштабном интернет-архиве, описанным на японском языке, который был получен за три года. Мы предложили рекурсивный алгоритм разложения компонент сильной связанности с узловой фильтрацией для извлечения линкофармов более плотно связанных в ядре. Мы продемонстрировали, что практически все крупные SCC, содержащие более 100 хостов являлись ссылочными фермами и мы могли бы извлечь их даже после удаления ряда хостов, имеющих малую степень. используя данный метод, мы обнаружили, что от 4.3% до 7.2% всех хостов являлись линкофармами с точностью более 95%. Это значит, что наша методология могла бы извлекать достаточно большое количество спам-хостов из интернет-архивов без соответствующего контентного анализа. Мы исследовали тематическую принадлежность хостов в ссылочных фермах. Мы выбрали семь тем и классифицировали спам-хосты в каждую из них с показателем F-меры равной 0.96. Мы изучили тематическое распределение в линкофармах и обнаружили, что тема «Для взрослых» и «Путешествия» являются наиболее доминирующими из всех семи тематик. Далее мы рассмотрели изменение в размере и тематике ссылочных ферм за три года для понимания их эволюции. Мы обнаружили, что многие линкофермы поддерживаются спамерами в течение многих лет, однако большинство из них не увеличивается в размерах. С другой стороны, мы обнаружили, что распределение ссылочных ферм по тематике остается стабильным, в то время как динамические процессы активно протекают в самих хостах. Подобного рода результаты показывают, что, посредством мониторинга за линкофармами, мы можем наблюдать тематические сдвиги в каждой из них, однако без эффективного обнаружения вновь созданных спам-сайтов. Обнаружение сайтов, которые генерируют гиперссылки, ведущие на ссылочные фермы, могло бы быть более полезной альтернативой в задачах обнаружения новых спам-сайтов.
Ссылки:
[1] The Official Google Blog, googleblog.blogspot.com/2008/07/we-knew-web-was-big.html
[2] Nakamura, S., Konishi, S., Jatowt, A., Ohshima, H., Kondo, H., Tezuka, T., Oyama, S. and Tanaka, K.: Trustworthiness Analysis of Web Search Results, ECDL, pp.38–49 (2007).
[5] Kumar, R., Raghavan, P., Rajagopalan, S. and Tomkins, A.: Trawling the Web for emerging cyber-communities, Proc. 8th International Conference on World Wide Web, WWW ’99, pp.1481–1493, New York, NY, USA, Elsevier North-Holland, Inc. (1999).
[11] Benczur, A.A., Csalogґany, K., Sarlos, T. and Uher, M.: SpamRank – Fully Automatic Link Spam Detection, Proc. 1st International Workshop on Adversarial Information Retrieval on the Web, AIRWeb ’05 (2005).
[12] Kan, M.-Y. and Thi, H.O.N.: Fast webpage classification using URL features, Proc. 14th ACM International Conference on Information and Knowledge Management, CIKM ’05, pp.325–326, New York, NY, USA, ACM (2005).
[13] Baykan, E., Henzinger, M., Marian, L. and Weber, I.: Purely URL-based topic classification, Proc. 18th International Conference on World Wide Web, WWW ’09, pp.1109–1110, New York, NY, USA, ACM (2009).
[14] Ma, J., Saul, L.K., Savage, S. and Voelker, G.M.: Identifying suspicious URLs: An application of large-scale online learning, Proc. 26th Annual International Conference on Machine Learning, ICML ’09, pp.681–688, New York, NY, USA, ACM (2009).
[15] Anthony, G.H., Penta, A., Seshadrinathan, G. and Mishra, M.: Trends in Spam Products and Methods, Proc. 1st Conference on Email and Anti-Spam, CEAS ’2004 (2004).
[17] Broder, A., Kumar, R., Maghoul, F., Raghavan, P., Rajagopalan, S., Stata, R., Tomkins, A. and Wiener, J.: Graph structure in the Web, Comput. Netw., Vol.33, pp.309–320 (2000).
[18] Becchetti, L., Castillo, C., Donato, D., Leonardi, S. and Baeza-Yates, R.: Link-Based Characterization and Detection of Web Spam, Proc. 2nd International Workshop on Adversarial Information Retrieval on the Web, AIRWeb ’06 (2006).
[20] Sculley, D. and Wachman, G.M.: Relaxed online SVMs for spam filtering, Proc. 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’07, pp.415–422, New York, NY, USA, ACM (2007).
[21] Dredze, M., Crammer, K. and Pereira, F.: Confidence-weighted linear classification, Proc. 25th International Conference on Machine Learning, ICML ’08, pp.264-271, New York, NY, USA, ACM (2008).
[22] Crammer, K., Fern, M.D. and Pereira, O.: Exact convexconfidence-weighted learning, Advances in Neural Information Processing Systems 22 (2008).
[23] Okanohara, D. and Ohta, K.: Online Learning Library, code.google.com/p/oll/
[24] Joachims, T.: Making large-scale support vector machine learning practical, pp.169–184, MIT Press (1999).
[25] Toyoda, M. and Kitsuregawa, M.: Extracting evolution of web communities from a series of web archives, Proc. 14th ACM Conference on Hypertext and Hypermedia, HYPERTEXT ’03, pp.28–37, New York, NY, USA, ACM (2003).
[26] Fujiwara, Y., Guilmi, C. Di., Aoyama, H., Gallegati, M. and Souma, W.: Do Pareto-Zipf and Gibrat laws hold true? An analysis with European firms. Physica A, Vol.335, pp.197–216 (2004).
[27] Georgiou, E., Dikaiakos, M.D. and Stassopoulou, A.: On the properties of spam-advertised URL addresses, J. Netw. Comput. Appl., Vol.31, pp.966–985 (2008).
 |
Ян-чу Чeн получила степень бакалавра в области Компьютерных Наук и Инженерного дела Сеульского Национального Университета (Южная Корея) в 2005 году. В 2008 году она получила степень магистра в области Информационной Инженерии Факультета Информатики и Коммуникаций Токийского Университета, в котором она по настоящее время является кандидатом в доктора философских наук. Ее интересы включают веб-майнинг и интернет-анализ. |
 |
Масаши Тоёда является доцентом Института Промышленных Наук Токийского Университета, Япония. Он получил степень бакалавра, степень магистра и Доктора Философии в области Компьютерных Наук Токийского Технологического Института (Япония) в 1994, 1996 и 1999 гг. соответственно. Он работал в Институте Промышленных Наук Токийского Университета в качестве специально назначенного доцента с 2004 по 2006 год. Его исследовательские интересы включают веб майнинг, пользовательские интерфейсы, визуализация информации и визуальное программирование. Он является членом ACM, IEEE CS, IPSJ и JSSST. |
 |
Масару Кицурэгава на данный момент является Профессором и Директором Центра Слияния Информации в Институте Промышленных Наук Токийского Университета. Он получил степени бакалавра и магистра по специальности Инженерной Электроники в Токийском Университете в Японии в 1978 и 1980 году, соответственно. В том же университете он получил степень Доктора Наук по Информационной Инженерии в 1983. На данный момент его исследовательские интересы охватывают разработку баз данных, веб-майнинг, архитектуру систем хранения данных, параллельный дата-майнинг/обработка баз данных, концепцию Цифровой Земли и обработку транзакций. Он занимал должность сопредседателя IEEE ICDE (Международная Конференция по Разработке Данных) в 2005 году; выступал в качестве члена правления VLDB и председателя ACM SIGMOD (Япония). Профессор Кицурэгава является членом IPSJ и IEICE (Япония) и директором DBSJ. Он член IEEE CS. |
Полезная информация по продвижению сайтов:
Перейти ко всей информации