SEO-Константа
Яндекс.Директ + оптимизация
В настоящее время системы информационного поиска сталкиваются с проблемой веб-сайтов, занимающихся распространением вредоносного программного обеспечения. В текущей работе мы предлагаем новый эффективный алгоритм, который обучается вычислять подобного рода спам. Мы использовали двудольный граф с двумя типами узлов, каждый из которых представляет собой слой на веб-графе: сайты и файловые хостинги (файлообменники, файлхостинги), связанные между собой ребрами, олицетворяющих тот факт, что файл может быть скачен с хостинга через ссылку, размещенную на интернет-сайте. Производительность данной методологии по вычислению спама верифицируются с использованием двух наборов меток «ground truth»: мануальная проверка специалистов по антивирусному ПО и автоматически сгенерированные оценки, полученные от компаний производителей-антивирусов. Мы демонстрируем, что предложенная методология способна обнаруживать новые типы вредоносного программного обеспечения еще до того, как популярные антивирусные решения смогут их идентифицировать.
По причине того, что вредоносные программы передаются по Интернету, их распространение шло очень быстро, заражая компьютеры по всему миру беспрецедентными темпами [1], а его обнаружение стало одной из основных тем по интернет-безопасности [2, 11, 3]. Разработчики программного обеспечения систем безопасности сообщали, что темпы выпуска вредоносного программного кода и прочих нежелательных программ может превышать оные легитимных программных приложений [11]. Поисковые системы стали одним из главных помощников в распространении вредоносного программного обеспечения. Пользователи обращаются на поиск с целью найти программное обеспечение, однако иногда вместо интернет-ресурсов разработчиков программного обеспечения или легальных дистрибьюторов, они выходят на фейковые веб-сайты или дистрибьюторов вредоносного программного обеспечения. Относительно недавно, системы информационного поиска начали осознавать свой непреднамеренный вклад в дистрибуцию вредоносного ПО. С целью защиты пользователей от возвращаемых результатов поиска, которые могут содержать в себе вредоносное программное обеспечение, поисковые машины заключили соглашение о сотрудничестве между компаниями-разработчиками антивирусов. Веб-сервисы проверяют безопасность программ используя информацию партнёров о распознанных вирусах, например virustotal.com. Но даже огромная база вредоносного ПО не гарантирует детекцию новых вредоносных программ. Большинство антивирусных программных продуктов, выпускаемых такими компаниями, как Kaspersky, Symantec, MacAfee для распознания программных угроз, как правило, используют сигнатурный метод. Тем не менее, авторы вредоносного программного обеспечения успешно разрабатывают контрмеры, направленные против предложенных технологий анализа вредоносного ПО. Ежедневно создаются тысячи вариантов вредоносных программ. В соответствии с годовым отчетом компании Symantec [11]: в 2011 году было предотвращено 5.5 млрд. вирусных атак, что на 81% больше, нежели чем в 2010 году. В 2011 году было обнаружено более чем 403 млн. новых типов вредоносно программного обеспечения, что на 41% больше, нежели чем в 2010 году. Компания Symantec сообщает об огромном количестве заблокированного вредоносного ПО, однако они оценивают, что новые вредоносные технологии способны генерировать практически уникальные версии вредоносного кода для каждой потенциальной жертвы. Это указывает на то, что традиционные решения по обнаружению вредоносного ПО, основанные на сигнатурах, вероятней всего, будут опережаться рядом инновационных программных угроз, создаваемых авторами вредоносного программного обеспечения. В настоящее время требуется новый, радикально-отличный подход к решению указанной проблемы. Системы информационного поиска первыми столкнулись с угрозой, исходящей со стороны нового вредоносного ПО. Именно по этой причине его обнаружение на ранних этапах и, в частности, их дистрибьюторов, является принципиальной целью безопасного и высококачественного поиска. Некоторые интернет-сайты, даже в том случае, если они и не являются дистрибьюторами вредоносного ПО, тем не менее тесно связаны с последними, например, посредством гиперссылок, что также может представлять опасность для пользователей поиска. Мы даже можем не подозревать их в умышленном сотрудничестве с дистрибьюторами вирусного программного обеспечения. Следовательно, для обнаружения подозрительных интернет-сайтов, мы предлагаем подход, предполагающий распространение информации о дистрибьюторах вредоносного программного обеспечения посредством связей между соседями по Сети, который аналогичен концепции гемофильности (homophily). Мы использовали двудольный граф с двумя типами узлов: интернет-сайты и файлхостинги. Ребра, связывающие вершины нашего графа, олицетворяет тот факт, что файл размещен на файлообменнике и может быть скачен с интернет-сайта.
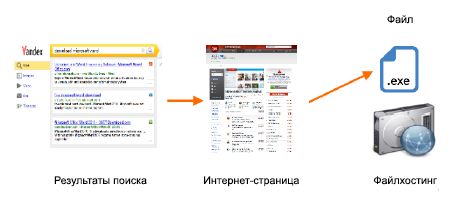
Рисунок 1. Распространение вредоносного программного обеспечения через системы информационного поиска
Компании-производители антивирусов предлагают ряд комбинированных методов по вычислению вредоносных файлов. Они базируются на файловых базах данных и дополнительной информации, касающейся взаимосвязей между файлами (например, использование схожих библиотек, схожее поведение на зараженных компьютерах и т. п.). Технология Polonium от компании Symantec [2] базируется на кастомизированном алгоритме распространения доверия на огромном двудольном графе с двумя типам узлов: пользовательские машины и файлы. Ребра обозначают файл, появляющейся на машине пользователя. Задача идентификации вредоносных программ приравнялась к задаче поиска файлов с ненадёжной репутацией. Технология Valkyrie от компании Comodo [1] базируется на семипараметрической модели классификатора, комбинирующего содержимое файла, а также его взаимосвязи, в задачах детекции вредоносного программного обеспечения. Мы рассмотрели ряд технологий майнинга графов, применяющихся для обнаружения поискового спама, которые могли бы оказаться полезными для борьбы с дистрибьюторами вредоносного программного обеспечения. Большинство из них базируются на хорошо известных нам алгоритмах PageRank [4] и HITS [5]. Одной из модификаций HITS является алгоритм LiftHITS [6] со специальными реберными атрибутами. Другая технология пропагации доверия, TrustRank [7], базирующаяся на PageRank, была разработана с целью противодействия поисковому спаму и требует мануально сформированной исходной выборки авторитетных страниц. Существует и другой подход по обнаружению спама — WITCH [8], алгоритм, который комбинирует две технологии: графовый и традиционный анализ страниц. Полуконтролируемый PageRank [9] является более общим подходом, нежели чем WITCH со схожей идеей использования как особенностей содержимого, так и преимуществ методологии PageRank. Для вычислений на огромном графе была использована логика MapReduce. Указанные графоориентированные подходы пригодны для обнаружения традиционных типов поискового спама, однако данных интернет-страницы (собранных из HTML и ссылок) явно недостаточно для детекции дистрибьюторов вредоносного программного обеспечения. Технология Polonium представляется хорошим подходом для решения проблемы распознания вредоносных файлов, однако это не является нашей основной целью. Главная задача, которая стоит перед поисковой системой, заключается в идентификации не файлов, а именно дистрибьюторов вредоносного ПО — интернет-страниц или целых сайтов, посредством использования всех доступных данных о загрузках файлов со страниц веб-сайтов. В конечном счете мы предлагаем новый комбинированный подход по обнаружению дистрибьюторов вредоносного программного обеспечения, основывающегося на идеях как антивирусной методологии из работы [2], так и на графовых антиспам алгоритмах [6, 7, 8].
Для детекции дистрибьюторов вредоносного программного обеспечения мы использовали анонимизированные пользовательские данные о скаченных файлах посредством их прохождения по гиперссылкам, расположенных на страницах веб-сайтов. Пользовательские данные были собраны в период с 1 по 7 августа 2012 года через специальные тулбары интернет-обозревателей. Мы получили 26,517,355 записей о загрузках со следующей информацией: страница, с которой была начата загрузка файла; тип файла (тип MIME); файлхостинг, на котором был размещен файл; дата загрузки файла. Мы отфильтровали некоторые типы скаченных файлов: изображения, аудио- и видео — файлы, торренты. В текущей работе мы предполагаем, что указанные выше типы файлов не могут быть вредоносными. Исследуя образцы дистрибьюторов вредоносного программного обеспечения, мы обнаружили, что в том случае, если заметное подмножество всех страниц сайта распространяет вредоносное ПО, тогда мы можем подозревать прочие файлы обозначенного сайта как вредоносные. Мы также обнаружили, что группы подозрительные интернет-ресурсов часто используют общий набор файловых хостингов для хранения файлов, отсюда мы выдвинули предположение о наличии взаимосвязей между некоторыми дистрибьюторами вредоносного программного обеспечения. Мы также отметили, что дистрибьюторы часто используют файловые хостинги с названиями, созвучными с известными файловыми хостингам или брендами программного обеспечения, например: media.fi1es.net, depostfiiles.com, fastfiledown10ader.com, msoffice.dld12.net и т. д. Следовательно, мы приняли решение трансформировать структуру «сайт — страница — файл — файловый хостинг» в структуру «сайт — файловый хостинг». Пара «сайт — файловый хостинг» формируется тогда, когда по крайней мере один документ сайта ссылается на файл, который размещен на файлхостинге. Каждая пара взвешена по количеству закачек файла с файлового хостинга посредством прохождения пользователя по гиперссылке, размещенной на сайте. В том случае, если файл размещен на самом сайте, такой интернет-ресурс можно представить двумя соединенными узлами на графе: «сайт» как сайт и «файловый хостинг» как файловый хостинг.
G = (V, E,W)
V — вершина двух типов: сайт S ⊂ V и файловый хостинг F ⊂ V;
S ∩ F = 0; S ∪ F = V;
E — ребро графа: E = {(s, f) : s ∈ S, f ∈ F};
W = {(ws(s, f), wf(s, f)) : s ∈ S; f ∈ F} ∈ [0, 1];
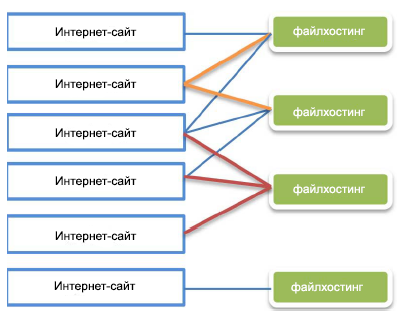
Рисунок 2. Двудольный граф сайтов и файловых хостингов с указанием связей между ними
Реберный набор весов представлен двумя типами:
ws(s,f) – доля файлов, которые были скачены посредством прохождения по гиперссылке с сайта s и размещались на f для всех загрузок с s.
wf(s,f) — доля файлов, которые были скачены посредством прохождения по гиперссылке с сайта s и размещались на f для всех загрузок с f.
m(v) – ранг вредоносности (malwareness rank) вершины v ∈ V , m ∈ [0, 1]. Мы воспользовались алгоритмом распространения доверия [10] чтобы провести оценку вероятностей максимального сходства состояний подозрительных узлов. Другими словами, m(s) является оценкой вероятности того, что s окажется дистрибьютором вредоносного программного обеспечения, а m(f) = 1 означает файловый хостинг f, размещающий только вредоносные файлы. Для инициализации методологии мы использовали исходную выборку трастовых и вредоносных файлхостингов. Пусть F0bad и F0good будут начальными выборками вредоносных и трастовых файловых хостингов соответственно, тогда m(fi) = 1, ∀i ∈ F0bad и F0good : m(fj) = 0, ∀j ∈ F0good. В конечном счете, мы построили граф, включающий 293.557 сайтов, 305.677 файловых хостингов и 622.137 ребер. Каждый файлхостинг в среднем хранит 48 файлов, порядка 50 файлов могут быть скачены посредством прохождения по ссылкам с одного веб-сайта. 82,9% сайтов размещают по крайней мере 1 файл, используя свой собственный хостинг. Но существуют веб-сайты, хранящие файлы на отдельном файловом хостинге, используемым исключительно данными сайтами, поэтому они не связанны с другими компонентами графа. Мы называем их автономными сайтами, доля которых составляет 55,2% интернет-ресурсов нашего набора данных.
В ходе подготовительных экспериментов с графом мы узнали, что нам необходимо использовать сигма-функцию, которая позволяет предотвратить распределение незначительных рангов или «шума» на графе, что препятствует сходимости алгоритма.
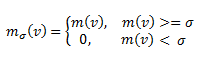
На первом шаге мы инициализировали граф G = (V, E, W); с предварительным набором F0bad плохих вершин файловых хостингов и предварительным набором F0good хороших вершин файловых хостингов. Мы устанавливаем m(v) = 0 для всех прочих вершин, исходя из предположения о том, что априори они не являются плохими. Идея заключается в обнаружении прочих подозрительных вершин с использованием концепции гемофильности — распространения информации о плохих соседях по Сети через вершины нашего графа. Мы предлагаем итерационный алгоритм, базирующийся на технологии HITS. На каждой итерации t ранг m последовательно вычисляется для всех сайтов и всех файлхостингов с использованием следующих шагов:
С помощью соседних значений рангов файловых хостингов (mt-1(f)), вычисленных на предыдущей итерации, рассчитывается вредоносность сайта.
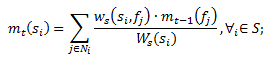
,где Ni является набором всех соседей вершины si;
С помощью соседних значений рангов сайтов (mt-1(s)), вычисленных на предыдущей итерации, рассчитывается вредоносность файлового хостинга.
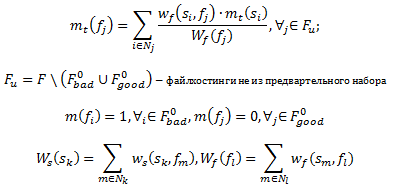
— коэффициент нормализации равен сумме реберных весов всего сетевого окружения. Отсюда, мы можем выполнить условие: m(v) ∈ [0, 1].
Условием прерывания итерационного алгоритма на итерации t является:
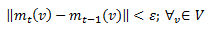
В том случае, если в результате некоторая вершина (сайт или файловый хостинг) имеет m(v) > θ, тогда мы рассматриваем ее в качестве плохой или дистрибьютора вредоносного программного обеспечения. Основной недостаток обозначенного метода: элементы графа, которые недосягаемы из начального набора не могут быть проанализированы или распознаны. Автономные интернет-сайты входят в их число, поэтому они могут быть проанализированы только с применением антивирусной информации. Данное выше выражение может быть записано в матричной форме. Однако матричные операции на крупных графах крайне ресурсоемкие. Разреженность матрицы отношений следует из топологии графа, следовательно мы решили отказаться от матричных расчетов. Операции, выполняемые на итерации нашего алгоритма, поддаются распараллеливанию, поэтому мы решили использовать подход MapReduce [12] для расчета ранга вредоносности. Схожая технология вычислений на большом графе описана в работе [9].
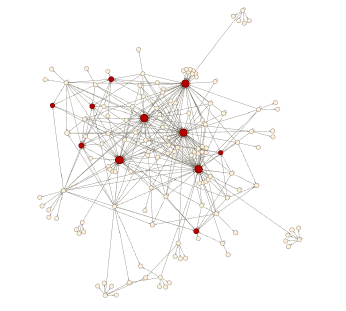
Рисунок 3. Инициализация двудольного графа (t = 0). Вершины, окрашенные в красный цвет, составляют предварительный набор F0bad.
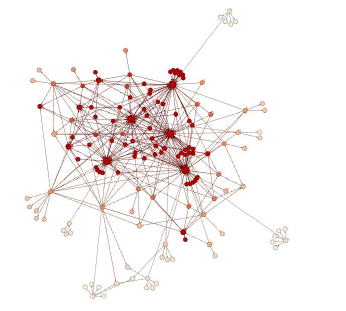
Рисунок 4. Двудольный граф после t=2. Интенсивность красного цвета вершин представляет собой значение ранга ее некачественности. Вершины, окрашенные в самый насыщенный красный цвет, имеют m2(v) = 1.
Мы использовали специальную систему распределенных вычислений, разработанную для эффективных расчетов на больших наборах данных. В процессе расчета, граф был разделен на части, каждая часть обрабатывалась отдельным компьютерным узлом. Процесс вычисления состоит из последовательных итераций. В начале каждой итерации для каждой вершины имеется набор входящих сообщений. Затем, для каждой вершины вызывается определенная функция. Функция использует текущее значение вершины и набор входящих сообщений. После чего, данная функция может изменять значение вершины и отправлять сообщения другим вершинам. На следующей итерации указанные сообщения доступны для целевых вершин. Вычислительный процесс выполняется в два шага:
MAP: отправка сообщений вершинам. В нашем случае — отправка набору соседних рангов из предыдущей итерации mt-1(vj), j ∈ Ni каждой вершине vi.
REDUCE: получение сообщений на вершине и расчет нового агрегированного показателя. В нашем случае — расчет ранга вредоносности mt(vi) вершины vi с использованием информации, полученной на шаге MAP.
Наши эксперименты начались с инициализации графа, описанной выше. Мы получили 52 файлхостинга, распространяющих вредоносные файлы, которые были взяты из мануальной проверки специалистов по вредоносному ПО и автоматически сгенерированных оценок, полученных от компаний-производителей антивирусов. Указанные файлхостинги были помечены как «вредоносные». Значение m(f) для этих вершин было установлено на 1. Набор, состоящий из 140 наиболее популярных файловых хостингов и официальных дистрибьюторов программного обеспечения, получил отметку как «трастовый». Вот некоторые интернет-сайты, которые вошли в наш доверительный набор: apple.com, microsoft.com, avira.com, firefox.com, kaspersky.com и т.д. Значение m(f) для этих трастовых файлхостингов было установлено на 0. Показатель σ = 0.05 из mσ(v) был установлен эмпирически, используя отложенные тестовые данные для сопоставления с условием остановки алгоритма. В результате мы устанавливаем предельно-допустимое пороговое значение вредоносности сайта и файлообменника на θ = 0.5. Мы подсчитали, что значения параметров: σ = 0.05, θ = 0.5, ε = 0.05 позволяют нашему алгоритму достигать точки конвергенции после двух итераций. Когда мы собрали данные за последующие периоды времени, оказалось, что за это время граф претерпел существенные изменения. Следовательно, с течением времени оценка становится иррелевантной. Мы полагаем, что, вероятней всего, вебмастерам-дистрибьюторам вредоносного программного обеспечения, которые занимаются продвижением своих сайтов, известны существующие методологии их идентификации, и они предусмотрительно часто меняют файловые хостинги, отказываясь от старых файлообменников. По нашей оценке, минимальный жизненный цикл такого файлхостинга составляет 1 неделю, однако средний срок жизни сайтов-дистрибьюторов вредоносного ПО более продолжителен. Поэтому мы приняли решение исполнять наш алгоритм каждый раз, когда мы получаем обновленные данные и использовать на этапе инициализации алгоритма предыдущие, а также новые результаты, поступающие от специалистов по антивирусному программному обеспечению и разработчиков антивирусного ПО. Для минимизации ложных положительных ошибок, случайные наборы дистрибьюторов вредоносного программного обеспечения, обнаруженные нашей методологией, проходят периодическую двойную проверку, осуществляемую группой специалистов по антивирусному ПО. Мы обнаружили 209 файловых хостингов, распространяющих вредоносные файлы с 97% аккуратностью (с θ = 0.5) после первого исполнения нашего алгоритма на веб-графе и 1239 файлхостингов после 12 еженедельных запусков с аккуратностью в 98%. Мы также обнаружили 2454 сайтов-дистрибьюторов вредоносного программного обеспечения, связанных с этими файлообменниками с 98% аккуратностью. После того, как обозначенные интернет-сайты были забанены в соответствии с политикой поисковой системы по противодействую спаму, мы наблюдали 2,1 кратное снижение среднего числа дистрибьюторов вредоносного программного обеспечения в ТОП 10 результатов органического поиска. Приблизительное число загрузок вредоносного ПО, обнаруженное с помощью нашего алгоритма, снизилось примерно в 3,4 раза по данным тулбарных логов. Только 9% файлов с хостингов вредоносного ПО обнаруженных нашим методом были распознаны антивирусным сканированием цифровых подписей. Однако практически все (96%) эти файлы были распознаны как вредоносные после мануальной верификации. Спустя 2 недели мы ещё раз проверили разметку антивирусов и выяснили, что они подтвердили вредоносность более 90% файлов на хостингах по нашим старым результатам. Таким образом, мы получили информацию о вредоносных файловых хостингах (а стало быть, и о файлах) более быстро, нежели чем это осуществляют компании-произодители антивирусов. Обучающий набор неавтономных вредоносных файлообменников был помечен нашим методом с 86% полнотой. Оценка полноты достаточно затруднена постольку, поскольку полнота методологии во многом зависит о начального набора. Мы не можем использовать все антивирусные данные для измерения полноты, потому что в отличие от антивирусного программного обеспечения, наш алгоритм фокусируется на обнаружении вредоносных файлхостингов, а не на файлах. Однако высокая аккуратность и скорость обнаружения демонстрируют эффективность нашего метода.
Мы предложили новый эффективный алгоритм обнаружения дистрибьюторов вредоносного программного обеспечения. Для создания двудольного графа сайтов и файловых хостингов использовался крупный анонимизированный журнал пользовательских загрузок файлов со страниц веб-сайтов. В качестве основополагающего принципа предложенной технологии майнинга графа, позволяющей идентифицировать дистрибьюторов вредоносного ПО, была использована концепция гемофильности. Для параллельных вычислений над очень большими наборами данными была использована модель программирования MapReduce. Этот подход был реализован на системе поискового антиспама Яндекса, который привел к существенному уменьшению в результатах органического поиска количества веб-сайтов, распространяющих вредоносное ПО. Мы планируем исследовать новые возможности применения данной методологии, в частности, мы предполагаем использовать ее для детекции других типов поискового спама, а также улучшить существующий метод, используя дополнительную информацию о веб-сайтах.
Перевод материала «Graph-based Malware Distributors Detection» выполнил Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации