SEO-Константа
Яндекс.Директ + оптимизация
В текущем материале показано, что учет данных пользовательского поведения может значительно улучшить качество предлагаемых результатов в реальных условиях веб-поиска. Рассматриваются альтернативы для включения обратной связи в процесс ранжирования, а также исследуется вклад обратной связи с пользователем по сравнению с другими сигналами, применяющихся поисковыми машинами. Сообщаются результаты крупномасштабных оценок: более 3000 запросов и 12 миллионов взаимодействий между пользователем и популярными системами информационного поиска. Показано, что включение неявной обратной связи в общую функцию ранжирования может увеличить аккуратности алгоритмов сортировки сайтов в органическом поиске на 31% по сравнению с их оригинальным исполнением.
Миллионы пользователей взаимодействуют с поисковыми системами ежедневно. Они обращаются на поиск посредством своих вопросов, в полученных ответах, переходят по ссылкам, кликают на рекламу, проводят время на страницах, переформулируют свои запросы, а также выполняют другие действия. Эти взаимодействия могут служить ценным источником информации для настройки и улучшения ранжирования результатов веб-поиска и могут дополнить более ценные явные решения.
Использование неявной обратной связи для получения релевантной выдачи и персонализации поиска стала активной областью для исследований. Последние работы Якимса и других, исследующих неявные обратные связи в управляемых условиях, показали важность включения неявной обратной связи в процесс ранжирования. Цель данной работы состоит в том, чтобы понять, как неявные обратные связи могут быть использованы в крупномасштабных операционных средах для улучшения поиска. Каким образом осуществлять их сравнение и присовокупить к тем признакам, по которым мы оцениваем интернет-страницы, текст анкора или ссылочных алгоритмов, таких как Google PageRank? Несмотря на то, что интуитивно взаимодействие пользователя с поисковой системой должно выявить по крайней мере, некоторую статистическую информацию, которая может быть использована для улучшения ранжирования, оценка пользовательских предпочтений в реальных условиях веб-поиска является сложной задачей, так как реальные взаимодействия пользователей имеют тенденцию быть более «зашумленными», чем принято считать в контролируемых параметрах предыдущих исследований.
В данной статье исследуется, могут ли неявные обратные связи быть полезными в реальных условиях, где обратный отклик может быть искажен (или иметь состязательный характер), а механизм поиска уже использует сотни сигналов с их многочисленными комбинациями. Для этого исследуются различные подходы для ранжирования результатов выдачи с помощью реального поведения пользователей полученного как часть нормального взаимодействия с механизмом поиска.
Особый вклад этой работы включает в себя:
Полученные данные резюмируются, и обсуждаются расширения для текущей работы в разделе 7, в котором делаются выводы настоящей статьи.
Ранжирование результатов поиска является фундаментальной проблемой поиска информации. Наиболее распространенные подходы в первую очередь сосредоточены на связке «запрос-страница ему релевантная», а также общем качестве страницы [3,4,24]. Однако с ростом популярности поисковых систем, неявные обратные связи (т. е. действия пользователей, предпринятые при взаимодействии с поисковой системой) могут быть использованы для улучшения ранжирования. Оценка неявного соответствия результатов органической выдачи и пользовательских запросов изучалось несколькими исследовательскими группами. Обзор неявных характеристик составлен Келли и Тиваном [14]. В то время как развивалась значимость проникновения в суть неявных оценок релевантности, это исследование не было применено для улучшения ранжирования результатов веб-поиска в реальных условиях.
Тесно связанный с данной работой, Якимс в [11] собрал неявные оценки внутри явных, представляя технику, основанную исключительно на данных кликабельности для обучения функций ранжирования. Фокс и соавторы [8] исследовали связь между явными и неявными оценками веб-поиска, а также разработали Байесовскую модель, отражающую корреляцию между неявными и явными оценками результатов поиска, релевантных как для уникальных запросов, так и на протяжении всей поисковой сессии. Эта работа рассматривала широкий круг пользовательского поведения (например, время пребывания на странице поисковой выдачи, время прокрутки, переформулирование запроса) в дополнение к популярному изучению поведения на основании кликабельности. Тем не менее, попытки моделирования были направлены на прогнозирование суждений о явной релевантности из неявных действий пользователя, а не конкретно на обучение функций ранжирования. Другие исследования поведения пользователей в веб-поиске, включающие работы Фаро и Джавлина [19], не были непосредственно применены для улучшения качества ранжирования.
Совсем недавно, Якимс и соавторы [12] представили эмпирические оценки интерпретации данных по кликам. Проводя исследования по отслеживанию человеческого взгляда и сопоставляя полученные прогнозы с явными рейтингами, авторы показали, что есть возможность точно интерпретировать клики в управляемых лабораторных условиях. К сожалению, в какой степени предыдущие исследования соотносятся с условиями работы реальных поисковиков, остается по большим вопросом. В то же время, в недавней работе (например, [26]) показано, что в то время как использование информации кликабельности для улучшения функции ранжирования веб-поиска является перспективным, оно захватывает лишь один из аспектов взаимодействия пользователя с механизмами веб-поиска.
Представленная статья опирается на существующие исследования по разработке техники интерпретации поведения пользователя для реальных условий веб-поиска. Вместо того чтобы рассматривать каждого пользователя в качестве надежного «эксперта», в данной статье собрана информация из нескольких, ненадежных пользовательских сессий на странице результатов органической выдачи, о чем рассказано в следующих двух разделах.
Рассмотрим два взаимодополняющих подхода к ранжированию с использованием неявной обратной связи: (1) обработка неявной обратной связи, как независимого основания для ранжирования результатов, и (2) интеграция особенностей неявной связи непосредственно с алгоритмом ранжирования. Мы опишем два основных подхода к ранжированию. Характеристики неявной обратной связи описаны в разделе 4, а алгоритмы для интерпретации и включения неявной обратной связи описаны в разделе 5.
Общий подход заключается в переоценке результатов, содержащихся в системах информационного поиска, посредством анализа кликов и другим взаимодействиям пользователей для осуществления запросов в предыдущих поисковых сессиях. Каждому результату присваивается оценка в соответствии с ожидаемой релевантностью / удовлетворенностью пользователя на основе предыдущих взаимодействий, в результате чего упорядочение предпочтений происходит на основе взаимодействия с пользователем.
В то время как была проделана значительная работа по объединению многих механизмов ранжирования, мы адаптируем простой и надежный подход, игнорирующий множество оригинальных оценок. Основной причиной их игнорирования служит то, что, поскольку пространство признаков и алгоритм обучения отличаются, то оценки не могут быть сопоставлены напрямую, и при ре-нормализации полезность каждой отдельной оценки стремится к убыванию. Мы проводили эксперименты с различными объединяющими функциями по разработке набора запросов (и, использовали множество взаимодействий по различным промежуткам времени из конечных наборов оценок). Было обнаружено, что простая эвристическая комбинация объеденных рангов работает хорошо, и является устойчивой к различиям в оценках оригинальных рангов. Для данного запроса q, неявная оценка ISd вычисляется для каждого результата d из доступных характеристик взаимодействия с пользователем, выдающая нам неявный ранг Id для каждого результата. Мы вычисляем объединенную оценку SM(d) для d путем комбинации рангов, получающихся из неявной обратной связи, Id с исходным рангом d, Od:
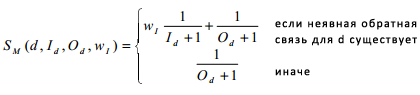
где вес wi является эвристическим коэффициентом масштабирования представляющим относительную «важность» неявной обратной связи. Результаты запроса упорядочены по уменьшению значения SM для построения окончательного рейтинга. Один частный случай этой модели возникает при настройке WI на очень большое значение, фактически заставляя выбранные (по клику) результаты иметь более высокий рейтинг, чем невыбранные (по клику) результаты — это интуитивно понятный и эффективный эвристический метод, который мы будем использовать в качестве базового. Применение более сложных классификаторов и комбинаций ранжирующих алгоритмов может привести к дополнительному улучшению, и является перспективным направлением для дальнейшей работы.
Подход, описанный выше, предполагает отсутствие взаимодействия между теми основными характеристиками, что используются в оригинальной формуле ранжирования, и особенностями неявной обратной связи. Теперь покажем интеграцию особенностей неявной обратной связи непосредственно в процесс ранжирования.
Современные поисковики в интернете ранжируют результаты, основываясь на большом количестве признаков, в том числе на основе особенностей, связанных с контентом (т.е., насколько тесно запрос совпадает с текстом, или TITLE, или анкором ссылок документа) и запросо-независимых качественных характеристик страницы (например, Google PageRank документа или домена). В большинстве случаев, автоматические (или полуавтоматические) методы разработаны для настройки конкретной функции ранжирования, комбинирующей эти особенности.
Таким образом, естественным подходом является включение особенностей неявной обратной связи как особенностей алгоритма ранжирования. Во время обучения или настройки, алгоритм ранжирования может быть настроен по умолчанию, но также и с дополнительными параметрами. Во время выполнения запроса механизм поиска мог бы извлекать особенности неявные обратной связи, ассоциированные со всякой парой «пользовательский запрос — URL ему релевантный». Эта модель требует такого алгоритма ранжирования, который был бы устойчив к тем классам запросов, для которых неявный отклик не был сообщен заранее, а именно к более чем 50% запросов, которые уникальны. Теперь мы опишем алгоритм, который мы использовали, для обучения комбинированного набора признаков, включая неявную обратную связь.
Одним из ключевых аспектов нашего подхода заключается в использовании последних достижений в области машинного обучения, а именно обучаемого алгоритма ранжирования сайтов в системах информационного поиска (например, [5, 11] и классические результаты рассмотрены в [3]). Нам доступны асессорские оценки релевантности для множества веб-запросов и результатов. Таким образом, привлекательным выбором для использования представляется для нас техника машинного обучения с учителем, которая позволит обучить функцию ранжирования, лучше всего предсказывающую оценки релевантности.
RankNet является одним из таких алгоритмов. Это нейросетевой алгоритм, который оптимизирует веса характеристик для лучшего соответствия предусмотренных попарных пользовательских предпочтений. Хотя конкретные алгоритмы обучения, используемые RankNet, выходят за рамки этой статьи, они подробно описаны в [5] и включают в себя обширную оценку и сравнение с другими методами ранжирования. Привлекательной особенностью RankNet является временная эффективность обучения и исполнения — он быстро вычисляется и масштабируется, а обучение может быть проведено на более чем тысячах запросов и связанных с ними результатах.
Мы используем 2-х слойную реализацию RankNet для того, чтобы смоделировать нелинейные связи между характеристиками. Кроме того, RankNet может обучаться на многих (дифференцируемых) функциях стоимости и, следовательно, может автоматически обучить функцию ранжирования по маркерам, предоставляемым человеком, что является привлекательной альтернативой эвристическим методам комбинирования тех или иных особенностей. Таким образом, мы также будем использовать RankNet как основной критерий, для того, чтобы исследовать вклад неявной обратной связи в различные варианты ранжирования.
Нашей целью является точная интерпретация зашумленной обратной связи с пользователем, получаемая при отслеживании взаимодействия пользователя с поисковой системой. Интерпретация неявной обратной связи в реальных условиях веб-поиска является не простой задачей. Мы характеризуем эту проблему подробно в [1], где мы обосновываем и оцениваем широкое разнообразие моделей неявной деятельности пользователя. Общий подход заключается в представлении действий пользователя для каждого результата поиска в виде вектора признаков, и затем обучении алгоритма на этих признаках для обнаружения тех значений признаков, которые свидетельствуют о релевантных (и нерелевантных) результатах поиска. Сначала мы кратко резюмируем наши характеристики и модели, а также подход к обучению (раздел 4.2), чтобы обеспечить достаточную информацию, для репликации нашей методологи ранжирования с последующими экспериментами.
Модель поведения на веб-поиске была получена как комбинация «фонового» компонента (например, шумы и искажения в поведении пользователя, независящие от запроса и релевантности, в том числе позиционные смещения от результата взаимодействия), и «релевантного» компонента (например, запросо-ориентированное поведение, свидетельствующее о релевантности полученных результатов по данному запросу). Мы разрабатываем наши характеристики, для того, чтобы воспользоваться преимуществами агрегированного поведения пользователя. Набор характеристик включает в себя непосредственно наблюдаемые особенности (данные рассчитываются непосредственно из наблюдений для каждого запроса), а также запросо-ориентированные вторичные особенности, рассчитываемые как отклонение от общего распределения запросо-независимых значений для соответствующих, непосредственно наблюдаемых, значений характеристик.
Особенности, используемые для представления взаимодействия пользователя с результатами веб-поиска, приведены в таблице 4.1. Эта информация была получена посредством использования программного обеспечения, установленного на стороне клиента в ходе пользования основными поисковыми системами.
Мы включили традиционные особенности неявной обратной связи, такие как подсчет кликов по результатам органической выдачи, а также новые производные характеристики, такие как отклонение наблюдаемого числа кликов для данного пары «запрос-URL» от ожидаемого числа кликов для данной позиции. Мы также моделируем поведение браузера после прохождения по ссылке со страницы выдачи на сайт — например, среднее время пребывания на странице для данной пары «запрос-URL», а также его отклонения от ожидаемого (среднего) времени нахождения на ней. Кроме того, набор характеристик был разработан с учетом необходимой информации взаимодействия с пользователем для того, чтобы обеспечить достоверную интерпретацию обратной связи. Например, пользователи веб-поиска часто могут определять, отвечает ли ссылка на их вопрос, глядя на TITLE веб-документа, его URL и сниппет — во многих случаях, у человека не возникает необходимости в просмотре исходного документа. Для моделирования этого аспекта пользовательского взаимодействия мы включаем такие характеристики, как дублирование слов в TITLE страницы и слов в запросе (TitleOverlap) и доли слов из запроса, пересекающейся со сниппетом сайта.
| Характеристики кликов | |
| Position | Позиция URL в Текущем рейтинге |
| ClickFrequency | Число кликов по этому запросу, пары URL |
| ClickProbability | Вероятность клика по этому запросу и URL |
| ClickDeviation | Отклонение от ожидаемой вероятности клика |
| IsNextClicked | 1, если кликнули на следующий результат, в противном случае – 0 |
| IsPreviousClicked | 1, если кликнули на предыдущий результат, в противном случае – 0 |
| IsClickAbove | 1, если кликнули выше, в противном случае – 0 |
| IsClickBelow | 1, если кликнули ниже, иначе 0 |
| Характеристики просмотра | |
| TimeOnPage | Время просмотра страницы |
| CumulativeTimeOnPage | Совокупное время просмотра для всех последующих страниц после поиска |
| TimeOnDomain | Совокупное время просмотра для этого домена |
| TimeOnShortUrl | Совокупное время просмотра на префиксе URL, без параметров |
| IsFollowedLink | 1, если следуют по ссылке на полученном результате, в противном случае – 0 |
| IsExactUrlMatch | 0, если используется агрессивная нормализация, 1 в противном случае |
| IsRedirected | 1, если начальный URL такой же, как окончательный URL, 0 в противном случае |
| IsPathFromSearch | 1, если только проследовали по ссылке после запроса, в противном случае – 0 |
| ClicksFromSearch | Количество переходов, для достижения страницы из запроса |
| AverageDwellTime | Среднее время пребывания на странице для этого запроса |
| DwellTimeDeviation | Отклонение от среднего времени пребывания на странице |
| CumulativeDeviation | Отклонение от среднего совокупного времени пребывания |
| DomainDeviation | Отклонение от среднего времени пребывания на домене |
| Запросо-текстовые характеристики | |
| TitleOverlap | Слова запроса пересекаются с названием документа |
| SummaryOverlap | Слова запроса пересекаются со сниппетом |
| QueryURLOverlap | Слова запроса пересекаются с URL-адресом |
| QueryDomainOverlap | Слова запроса пересекаются с доменным именем |
| QueryLength | Количество токенов в запросе |
| QueryNextOverlap | Доля слов пересекающихся со следующим запросом |
Таблица 4.1: Некоторые характеристики, использующиеся для представления истории переходов после завершения процесса поиска для заданного запроса и URL результатов органической выдачи.
Описав наш набор характеристик, мы кратко рассмотрим наш общий подход к моделированию пользовательского поведения.
Чтобы научиться интерпретировать наблюдаемое поведение пользователя, мы соотносим его действия (например, характеристики данные в таблице 4.1) с явными пользовательскими суждениями по набору обучающих запросов. Мы обнаруживаем все экземпляры в наших сессионных логах, отражающих все те запросы, которые были адресованы поисковой машине, а также агрегированные характеристики поведения пользователей для всех поисковых сессий с участием этих запросов.
Каждый наблюдаемая пара «запрос-URL» представлена характеристикам в таблице 4.1, со значениями, усредненными по всем поисковым сессиям, и с присвоением им одной из шести возможных асессорских оценок, касающихся релевантности, начиная от «Отлично» и заканчивая «Плохо». Эти, маркированные векторы признаков, используются в качестве входных данных для алгоритма обучения RankNet (см. раздел 3.3), который воспроизводит обучающую модель поведения пользователя. Этот подход особенно привлекателен, так как не требует дополнения методами эвристики. В результате модель поведения пользователя используется таким образом, чтобы помочь отранжировать результаты органического поиска либо самостоятельно, либо в комбинациями с другими сигналами, как это будет описано ниже.
Конечная цель включения неявной обратной связи в процесс ранжирования заключается повышение релевантности возвращаемых результатов поисковых систем. Таким образом, мы сравним методы ранжирования по большому набору запросов, оцениваемых с помощью асессорских меток. Чтобы оценки были реалистичными, мы извлекли случайную выборку запросов из пользовательских логово основной поисковой системы с ассоциированными для них результатами и соответствующими действиями пользователей. Мы описываем этот набор данных подробно дальше. Наши метрики описаны в разделе 5.2, который мы используем для оценки альтернатив ранжирования, представленных в разделе 5.3 и используемых в экспериментах раздела 6.
Мы сравнили наши методы ранжирования по случайной выборке из 3000 запросов из пользовательских логов поисковой системы. Запросы были извлечены из логов поиска случайно и равномерно, посредством токенов без замещения, в результате чего мы имеем образцовые запросы, репрезентативные их общему распределению. В среднем, 30 результатов были помечены асессорами с использованием шестибальной шкалы, начиная от «отлично» до «плохо». В целом, было более 83000 результатов с явными оценками релевантности. Для того чтобы вычислить различные статистические данные, документы с маркером «хорошо» или лучше будут считаться «релевантными», а с более худшими маркерами – «нерелевантными». Отметим, что эксперименты проводились уже над выскоранжируемыми результатами в органической выдаче поисковых машин, что соответствует стандартам пользовательского взаимодействия, ограниченного небольшим числом высоко отранжированных результатов при удовлетворении своего вопроса.
Данные пользовательского взаимодействия собирались в период свыше 8 недель, посредством лишь тех участников эксперимента, которые согласились предоставлять нам информацию добровольно. В общей сложности было обработано более 1,2 миллиона уникальных запросов, то есть в результате мы получили более 12 миллионов индивидуальных взаимодействий с поисковой системой. Данные состояли из взаимодействия пользователя с механизмом веб-поиска (например, клик на ссылку результата, возврат к результатам поиска, и т.д.) выполненного после того, как вопрос был задан поиску. Эти действия были агрегированы между пользователями и поисковыми сессиями, и преобразованы в характеристики в таблице 4.1.
Чтобы создать обучающие, проверяющие и тестовые наборы запросов, мы создали три различных случайных блока по 1500 обучающих, 500 проверяющих, и 1000 тестовых запросов. Разделение из их общей совокупности было сделано случайно по запросу таким образом, чтобы не было никакого дублирования в обучающих, проверяющих и тестовых запросах.
Мы оцениваем алгоритмы ранжирования в диапазоне общепринятых метрик поиска информации, а именно точность в K (P(K)), Normalized Discounted Cumulative Gain (NDCG), и среднее значение точности (MAP). Каждая метрика фокусируется на различных аспектах производительности системы, как мы опишем ниже.
Точность в K: Как наиболее интуитивная метрика, P (K) сообщает долю документов входящих в топ K результатов, которые были помечены как релевантные. В нашей ситуации, мы требуем от релевантного документа асессорскую метку «хорошо» или выше. Положения релевантных документов в топ K не имеет значения, и, следовательно, эта метрика является оценкой общего уровня удовлетворенности пользователей топ K результатами.
NDCG в K: NDCG является возвращенной оценкой, разработанной специально для оценки веб-поиска и сравнения его с идеальной моделью [10]. Для данного запроса q, отранжированные результаты рассматриваются по нисходящей, а NDCG вычисляется по формуле:
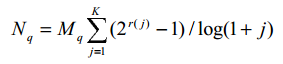
Где Mq является нормализованной константой рассчитываемой так, что наилучшее упорядочение получит NDCG в 1 (такое значение оно принимает лишь в том случае, если функция смогла отсортировать веб-странички в порядке убывания асессорских оценок), и каждый r (j) является целым числом асессорских оценок релевантности (0 = «Плохо» и 5 = «Отлично») результата возвращенного на позицию j. Обратите внимание, что немаркированные и «плохие» документы не влияют на сумму, но уменьшают NDCG для запроса имеющего релевантные документы на более низких позициях.
MAP: Средняя точность для каждого запроса определяется как средняя точность К значений вычисленных после каждого возвращенного релевантного документа. Окончательное значение MAP определяется как средняя величина усредненных значений точности для всех запросов из тестового набора. Эта метрика является наиболее часто используемым однозначным итогом для избыточного набора запросов.
Напомним, что наша цель заключается в оценке эффективности использования неявного поведения пользователя для реального веб-поиска. Одним из аспектов является сравнение полезности неявной обратной связи с другой информацией, доступной поисковой системе. В частности, мы сравнили эффективность неявного поведения пользователя с соответствием контентным характеристикам, с качеством статичных особенностей (авторитетность) страницы, и комбинациями всех упомянутых характеристик.
BM25F: Мы применили функцию ранжирования BM25F, которая была использована на TREC 2004 [23,27]. BM25F и ее модификации были подробно описаны и оценены в литературе по поиску информации. Функция BM25F исследует документ как совокупность нескольких полей, длины которых нормализуются независимо друг от друга, при этом каждому полю назначается своя степень значимости в конечной формуле ранжирования. Мы использовали ее вариант в нашем эксперименте для вычисления отдельных оценок соответствия для каждого поля результирующего документа (например, текст из HTML-секции BODY, текст TITLE и ссылочного анкора), и включили сюда запросо-независимую ссылочную информацию (например, PageRank, ClickDistance и вложенность URL). Функция подсчета и настройка полей степеней значимости подробно описаны в [23]. Обратите внимание, что мы не считаем BM25F непосредственно явной или неявной обратной связью в настройках нашей системы.
RN: Ранжирование, осуществляемое искусственной нейронной сетью (RankNet, описанная в разделе 3.3), которая обучается ранжировать результаты поиска в вебе за счет включения BM25F и большого количества дополнительных статических и динамических характеристик, описывающих всякий результат поиска. Эта система автоматически оптимизирует веса для всех характеристик (в том числе оценку документа BM25F) на основе явных человеческих меток для большого набора запросов. Системы, включающие реализацию RankNet, в настоящее время используются основными поисковыми системами, и могут считаться самой передовой технологией веб-поиска.
BM25F-RerankCT: Ранжирование осуществляется путем включения статистики кликов, для того чтобы изменить порядок результатов веб-поиска, прежде упорядоченных по BM25F. Клики являются крайне важным частным случаем неявной обратной связи, и как было показано, коррелируют с релевантным результатом. Этот частный случай метода ранжирования рассмотрен в разделе 3.1, с весом wi установленным в 1000 и рейтингом Id , являющимся простым числом кликов по результату, соответствующий d. По сути, эта методология ранжирование помещает в ТОП все возвращенные результаты веб-поиска, имеющие по крайней мере один клик (и располагает их в порядке убывающей кликабельности). Относительный ранг оставшейся части результатов остается неизменным, и они располагаются ниже всех кликнутых результатов. Этот метод служит нашим базовым методом пересортировки с использованием неявной обратной связи.
BM25F-RerankAll: Ранжирование производится путем пересортировки результатов полученных от функции BM25F, используя все особенности пользовательского поведения (раздел 4). Этот метод обучает модель пользовательских предпочтений путем сопоставления значений признаков с явными маркерами релевантности с помощью использования алгоритма искусственной нейронной сети RankNet (раздел 4.2). Во время его исполнения для данного запроса неявная оценка Ir вычисляется для каждого результата r с доступными характеристиками пользовательского взаимодействия, и осуществляет неявное ранжирование. Объединенный ранг вычисляется, как описано в разделе 3.1. На основании опытов по расширению набора признаков мы установили значение Wi до 3 (влияние параметра Wi для данного метода оказалось незначительным).
BM25F + All: Рейтинг, полученный путем обучения RankNet (раздел 3.3) на наборе характеристик оцененных BM25F, а также на всех характеристиках неявной обратной связи (раздел 3.2). Мы использовали 2-х слойную реализацию RankNet [5] обученной на запросах и маркерах на обучающих и проверочных наборах.
RN + All: Ранжирование получено путем обучения 2-х слойного алгоритма ранжирования RankNet (см. раздел 3.3) на объединении всех контентых, динамических характеристиках, а также на особенностях неявной обратной связи (т. е. все характеристики, описанные выше вкупе со всеми новыми неявными особенности, которые мы ввели после).
Методы ранжирования, описанные выше, охватывают диапазон информации, используемой для построения поисковой выдачи, начиная от тех, что не используют явную или неявную обратную связь (то есть, BM25F), и заканчивая современным поисковым механизмом, применяющим сотню сигналов и явные оценки релевантности (RN). Как будет показано дальше, включение поведения пользователей в эти системы ранжирования значительно повышает релевантность возвращаемых документов.
Неявные обратные связи, используемые для ранжирования веб-поиска, могут быть использованы в ряде направлений. Мы сравниваем альтернативные методы применения неявной обратной связи, как посредством пересортировки топовых результатов (т.е., BM25F-RerankCT и BM25F-RerankAll методы, которые переупорядочивают результаты, полученные функцией BM25F), а также за счет интеграции неявных характеристик непосредственно в процесс ранжирования (т.е, методы RN + ALL и BM25F + All, которые обучаются ранжированию на особенностях неявной обратной связи и других характеристиках). Мы сравниваем наши методы по более устойчивым базисам (BM25F и RN) по NDCG, точности в K и MAP, определенных в разделе 5.2. Результаты были усреднены по трем случайным блокам, представляющих собой разбиение общего набора данных. Каждый такой блок содержал 1500 обучающих, 500 проверяющих, и 1000 тестовых запросов, при этом все наборы запросов не пересекались. Сначала мы приведем результаты по всей 1000 тестовых запросов (то есть, в том числе тем, для которых не существует неявных оценок, для которых мы используем оригинальные сигналы, использующиеся при ранжировании). Далее мы проводим углубленный анализ того, где использование неявной обратной связи оказалось наиболее выгодным.
Сначала мы проводили опыты с различными методами пересортировки результатов поиска BM25F. На рисунках 6.1 и 6.2 описывается NDCG и точность для функции BM25F, а также пересортировка результатов с использованием пользовательской обратной связи (раздел 3.1). Включение пользовательской обратной связи (либо в рамках пересортировки или как характеристик для непосредственного обучения) приводит к значительным улучшениям (используя двухвыборочный t-тест с р = 0,01) и при оригинальном ранжировании BM25F, и при пересортировке с учетом кликов. Улучшение является последовательным – через 10 лучших результатов, и наибольшим для самых верхних результатов: NDCG в 1 для BM25F + All оказывается равным 0,622 по сравнению с 0,518 исходных результатов, а точность в 1 аналогично увеличивается с 0,5 до 0,63. Основываясь на этих результатах, в своей модели мы будем использовать прямую комбинацию (например, BM25F + All) для последующего сравнения с применением неявной обратной связи.
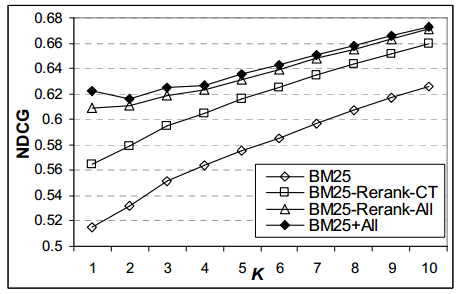
Рисунок 6.1: NDCG в K для BM25F, BM25F-RerankCT, BM25F-Rerank-All и BM25F + All для различных K
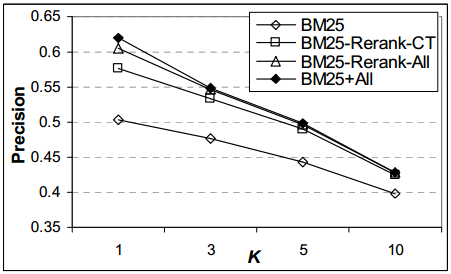
Рисунок 6.2: Точность в K для BM25F, BM25F-RerankCT, BM25F-Rerank- All и BM25F + All для различных K
Интересно, что использование только кликов, дающих значительное преимущество по сравнению с первоначальным ранжированием по функции BM25F, оказывается не столь эффективным, как рассмотрение полного набора особенностей из таблицы 4.1. В то время как мы анализируем пользовательское поведение (и наиболее эффективные характеристик) в отдельной статье [1], сейчас имеет смысл дать конкретный пример такого рода шумов присущих реальной обратной связи с пользователями в условиях веб-поиска.
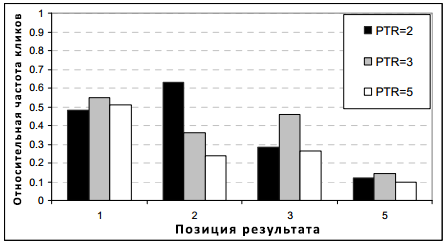
Рисунок 6.3: Относительная частота кликов по запросам для релевантных топовых сайтов по различным позициям (PTR).
Если бы пользователями рассматривались только релевантные результаты, полученные в ответ на их запрос, они бы кликали на результаты, расположенные на наиболее высоких позициях. К сожалению, как показали Якимс и другие, от того, на какие результаты пользователи будут кликать больше, зависит оформление сниппета сайта, поэтому продвижение сайтов на текущем этапе развития поисковых машин должно уделять повышенное внимание на то, как представлены сайты их клиентов в органическом поиске. Пользователи часто кликают на те результаты, которые хоть и менее релевантные, но расположены выше соответствующей ссылки на оригинал документа. Предположительно это происходит потому, сниппет веб-сайта не дает той достаточной информации, которая бы позволила человеку более точно оценить релевантность; более того, релевантными страницами оказываются те, что размещаются посередине списка с результатами поиска. Рисунок 6.3 показывает относительную частоту кликов для запросов с известной релевантностью по позициям отличных от первой позиции; релевантность топовых результатов (PTR) колеблется в диапазоне 2-10. Например, для запросов с первым релевантным результатом, имеющим позицию 5 (PTR = 5), больше кликов приходится на нерелевантные результаты, находящиеся выше первого релевантного, который занял пятое место. Как мы увидим далее, обучение на расширенном наборе особенностей пользовательского поведения, приводит к значительному улучшению аккуратности в случае использования исключительно кликов.
Сейчас мы рассмотрим взаимодействие пользовательского поведения с учетом расширенного набора характеристик и RN (раздел 5.3), использующейся основными поисковыми системами. RN включает в себя BM25F, ссылочные характеристики, а также сотни других особенностей. Рисунок 6.4 представляет NDCG в K, а рисунок 6.5 — точность в К. Интересно, что в то время как оригинальный RN является более аккуратным, нежели чем только BM25F, включение особенностей неявной обратной связи (BM25F + All) в функцию ранжирования, значительно превосходит оригинальную формулу RN. Иными словами, неявная обратная связь включает в себя достаточную информацию, которая позволяет заменить сотни других сигналов, доступных RankNet и проводящего свое обучение на наборе особенностей RN.
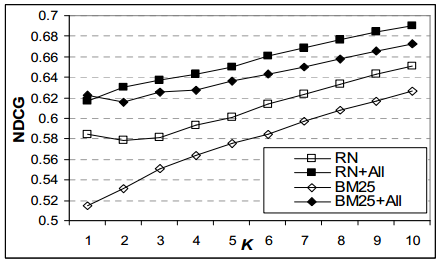
Рисунок 6.4: NDCG в K для BM25F, BM25F + All, RN и RN + All для различных K
Кроме того, расширение набора характеристик RN за счет особенностей, присущих неявной обратной связи позволяет получить значительный прирост всех оценок, допускающих использование RN + All, чтобы превзойти все другие известные нам методы. Это может свидетельствовать о взаимодополняющем характере неявной обратной связи с другими сигналами, доступным передовым поисковым системам.
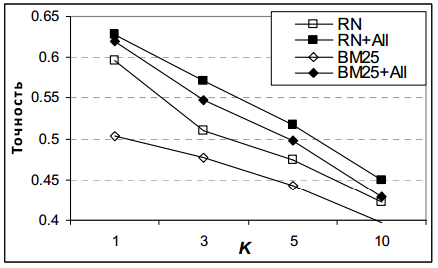
Рисунок 6.5: Точность в K для BM25F, BM25F + All, RN и RN + All для различных K
Мы резюмируем эффективность различных методов ранжирования в таблице 6.1. Здесь мы касаемся показателя средней точности (MAP) для каждой системы. Хотя интерпретация на интуитивном уровне представляется затруднительной, MAP позволяет произвести сравнение по единой метрике. Прирост, отмеченный *, являются значительным на уровне р = 0,01 с использованием двухвыборочного t-теста.
| MAP | Прирост | P(1) | Прирост | |
| BM25F | 0.184 | — | 0.503 | — |
| BM25F-Rerank-CT | 0.215 | 0.031* | 0.577 | 0.073* |
| BM25F-RerankImplicit | 0.003 | 0.605 | 0.503 | 0.028* |
| BM25F+Implicit | 0.222 | 0.004 | 0.620 | 0.015* |
| RN | 0.215 | — | 0.597 | — |
| RN+All | 0.248 | 0.033* | 0.629 | 0.032* |
Таблица 6.1: Среднее значение точности для всех методов.
До сих пор мы сообщали о результатах усредненных по всем запросам в тестовом наборе. К сожалению, для осуществления пересортировки мы получили менее чем половины необходимых взаимодействий. Из 1000 запросов в тестовой выборке, только для 46% и 49% запросов, в зависимости от разбивки обучающего-тестового множества, было получено той необходимой информации о взаимодействиях для того, чтобы сделать соответствующие прогнозы (то есть, был по меньшей мере 1 поисковая сессия, в ходе которой по крайней мере 1 URL был кликнут пользователем). Это не удивительно: более половины всех вопросов, с которыми люди обращаются на поиск, имеет распределение с длинным хвостом, то есть они уникальны в рамках одной сессии. Теперь рассмотрим производительность модели ранжирования по тем запросам, для которых было доступно взаимодействие с пользователем. Рисунок 6.6 показывает NDCG для подмножества тестовых запросов с учетом характеристик неявной обратной связи. Прирост до 1 крайне значителен. NDCG в 1 для функции BM25F + All увеличивается от 0,6 до 0,75 (31% относительного прироста), достигая производительности сравнимой с RN + All, оперирующего расширенным набором характеристик.
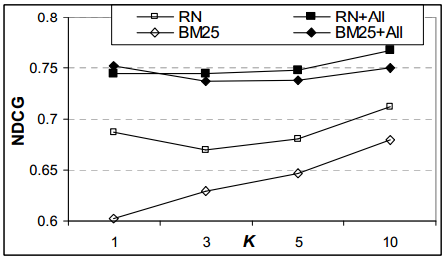
Рисунок 6.6: NDCG в K для BM25F, BM25F + All, RN и RN + All на тестовых запросах с учетом пользовательского взаимодействия.
Кроме того, прирост точности в топ 1 оказывается существенным (рис. 6,7), и, вероятней всего, это смогут ощутить даже рядовые пользователи систем информационного поиска. В случае применения неявной обратной связи, система BM25F + All возвращает релевантный документ ближе к 1 почти в 70% случаев, по сравнению с 53%, когда неявная обратная связь игнорируется в оригинальной функции BM25F.
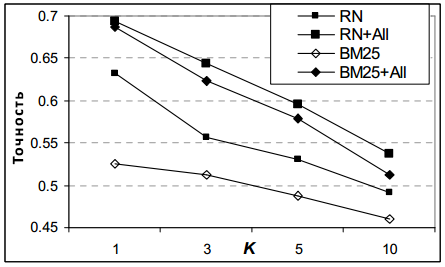
Рисунок 6.7: Точность в К, NDCG в K для BM25F, BM25F + All, RN и RN + All на тестовых запросах с учетом пользовательского взаимодействия.
Мы подведем итоги по метрике МАР по опробованным запросам в таблице 6.2. MAP дает существенные и значительные улучшения особенно по сравнению с BM25F.
| Метод | MAP | Прирост | P(1) | Прирост |
| RN | 0.269 | 0.051 (19%) | 0.632 | 0.061 (10%) |
| RN+All | 0.321 | 0.051 (19%) | 0.693 | 0.061 (10%) |
| BM25F | 0.236 | 0.056 (24%) | 0.525 | 0.162 (31%) |
| BM25F+All | 0.292 | 0.056 (24%) | 0.687 | 0.162 (31%) |
Таблица 6.2: Среднее значение точности (MAP) на опробованных запросах для самых эффективных методов
Теперь проанализируем случаи, когда неявная обратная связь оказалась наиболее полезными. Рисунок 6.8 иллюстрирует улучшения MAP по сравнению с «базовым» BM25F выполненным для каждого запроса с MAP ниже 0,6. Обратите внимание, что большая часть улучшений приходится на плохоудовлетворяющие запросы (например, MAP <0,1). Интересно, что наличие данных о поведении пользователей ухудшает точность для запросов с высокой оригинальной оценкой MAP. Одним из возможных объяснений этого феномена является то, что подобного рода «незамысловатые» запросы, как правило, относятся к навигационным (т.е. имеющие один, высоко отранжированный, наиболее подходящий ответ), и взаимодействие пользователя с низкоотранжированными результатами может указывать на различные потребности в информации, которые лучше удовлетворяются менее популярными и, соответственно, менее релевантными сайтами.
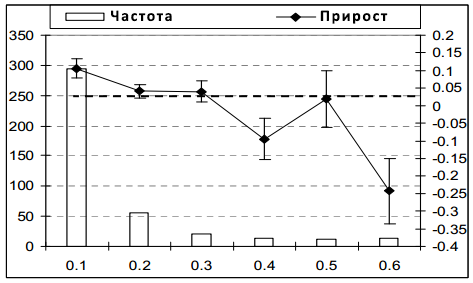
Рисунок 6.8: Прирост BM25F + All в сравнении с оригинальной функцией BM25F
Подводя итог наших экспериментальных результатов можно сказать, что применение неявной обратной связи в реальных условиях веб-поиска, привело к значительным улучшениям по сравнению с первоначальным ранжированием, при использовании стандартных BM25F и RN. Наш расширенные набор неявных характеристик, такие как время пребывания на странице и отклонения от обычного поведения, дает преимущества по сравнению с использованием только кликов как показателя пользовательского интереса. Кроме того, непосредственное включение особенностей неявной обратной связи в обученную функцию ранжирования представляется более эффективным, чем при использовании неявной обратной связи при пересортировке. Улучшения, наблюдаемые на больших тестовых наборах запросов, представляются для нас крайне значимыми.
В данной работе мы исследовали полезность включения зашумленной неявной обратной связи, полученной из реального веб-поиска для улучшения качества информационного поиска. Мы провели крупномасштабные оценки более 3000 запросов и более 12 миллионов взаимодействий пользователей с наиболее крупной поисковой системой, посредством установления на клиентской стороне специального программного обеспечения, собирающего статистические данные об их посещениях. Мы сравнили два варианта включения неявной обратной связи в процесс поиска, а именно пересортировку с учетом неявной обратной связи и использование особенностей неявной обратной связи непосредственно при обучении функции ранжирования. Наши эксперименты показали значительное улучшение по сравнению с методами, которые не учитывают неявную обратную связь. Прирост особенно существенен для топ K = 1 в итоговом рейтинге с увеличение точности до уровня в 31%, хотя улучшение затрагивает все значения К. Наши опыты показали, что применение неявной обратной связи с пользователями вкупе с существующими анализаторами контента и ссылочного графа может значительно улучшить производительность веб-поиска. Интересно отметить, что неявная обратная связь представляет особую ценность для запросов, которые имеют низкую степень удовлетворения в случае оригинального ранжирования (например, МАР ниже, чем 0,1). Одним из перспективных направлений дальнейшей работы является применение последних исследований в области автоматического прогнозирования сложности пользовательских запросов, и попытки включить неявную обратную связь для «трудных» запросов. В качестве еще одного направления исследования мы изучаем методы для расширения наших прогнозов на ранее неизвестные нам запросы, которые позволят получить больше информации о поведении пользователей на реальном веб-поиске.
Мы благодарим Криса Берджеса и Мэтта Ричардсона за реализацию RankNet для наших экспериментов. Мы также благодарим Роберта Рагно за его ценные советы и участие в обсуждениях.
Перевод материала «Improving Web Search Ranking by Incorporating User Behavior Information» выполнили Галия Габитова и Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации