SEO-Константа
Яндекс.Директ + оптимизация
В ответ на введенный пользователем вопрос, система информационного поиска возвращает отранжированный список веб-документов. Если пользовательский запрос популярен (то есть под него подходит множество документов), то получаемый список обычно слишком велик, чтобы просмотреть его полностью. Исследования показали, что пользователи поисковых машин обычно просматривают только первые 10 или 20 результатов органической выдачи. В данной статье мы предлагаем новый подход к ранжированию популярных запросов, который помещает наиболее авторитетные страницы, соответствующие теме пользовательского запроса, на верхние позиции результатов органического поиска. Наш алгоритм использует специальный индекс «экспертных документов». Они представляют собой подмножество интернет-страниц, идентифицируемых как каталоги ссылок, ведущих на неаффилированные источники по определённым темам. Ранжирование результатов в органической выдаче происходит на основании совпадения пользовательского запроса и релевантного текста, описывающего гиперссылки, которые проставляются на экспертных документах и ссылаются на целевую страницу. Мы представляем прототип поисковой системы, которая использует в своей работе нашу схему ранжирования и оцениваем её производительность. Для относительно малого (2,5 млн. страниц) экспертного индекса наш алгоритм обрабатывал широкие запросы сопоставимо с крупными системами информационного поиска.
При осуществлении поиска в интернете, широкие запросы (broad queries) генерируют избыточный объем ответов. Получаемый набор сложно ранжировать, основываясь только на его содержимом, поскольку качество и «авторитетность» страницы (а именно, мера авторитетности страницы, относительно заданной темы) не могут быть оценены посредством исследования её контента. В традиционном информационном поиске мы предполагаем, что статьи, содержащиеся в корпусе, данных происходят из доверенного источника и все слова, найденные в статье, предназначаются для пользователя. Эти предположения неприменимы к Глобальной паутине постольку, поскольку содержимое создаётся источниками различного качества, а слова зачастую добавляются без разбора для повышения ранга интернет-страницы. Например, некоторые страницы создаются специально для того, чтобы ввести в заблуждение ранжирующие механизмы поисковых машин, и известны как спам-страницы. Самые изощренные практики поискового спама включают в себя умышленную отдачу разного контента пользователю и агенту накопления данных с единственной целью увеличения пользовательского трафика, приходящегося с поиска. Но даже при отсутствии намерения манипулирования алгоритмами ранжирования, как правило, веб изобилует тематической информацией, популярной среди пользователей. Следовательно, в случае широких запросов поиск, основанный на совпадении ключевых слов, составляющих пользовательский вопрос и текст документа, оказывается неэффективным.
Предыдущие подходы, использовавшие анализ содержимого в задаче ранжирования широких запросов, не умеют отличать авторитетные страницы от неавторитетных (другими словами, они не в состоянии обнаружить спам-документы). По этой причине качество ранжирования ухудшается, и системы информационного поиска обратились к использованию иных источников информации, помимо содержимого страниц, с тем чтобы качество ранжирования оставалось на соответствующем уровне. Далее мы опишем некоторые стратегии ранжирования, а затем и наш новый способ авторитетного ранжирования, который мы называем Hilltop.
В прошлом было использовано три подхода, связанных с улучшением авторитетности результатов ранжирования:
Ранжирование, основанное на ручной классификации: такие компании как Yahoo! и Mining Company нанимают редакторов для ручного ассоциирования набора категорий и ключевых слов с подмножеством документов в вебе. Затем они сопоставляются с пользовательскими запросами для возврата наиболее релевантных результатов. Проблема этого подхода заключается в том, что: а) подход требует крайне много времени и применим только к малому числу страниц; б) зачастую ключевые слова и результаты отнесения к тем или иным классам, осуществляемое людьми-редакторами, оказываются неполными или не соответствующими действительности. При нынешней скорости роста интернета и большом разнообразии поисковых запросов, этот метод не является комплексным решением нашей проблемы.
Ранжирование, основанное на данных пользования вебом: некоторые сервисы вроде DirectHit собирают информацию, касательно: а) вопросов отдельных пользователей, задаваемых поисковым системам и б) страниц, которые они потом просматривают, а также длительности визита, относительно каждой просмотренной страницы. Эта информация используется далее для возврата страниц, которые большинство пользователей посещает после обработки заданного запроса. Для успешной работы этого метода требуется сбор огромного количества данных по каждому запросу. Таким образом, потенциальный набор запросов, к которым применим данный метод, очень мал. К тому же, данная техника уязвима к спаму.
Ранжирование, основанное на связанности: этот подход включает анализ гиперссылок между интернет-страницам, основываясь на предположении, что: а) цитирование страниц осуществляется в пределах их тематической принадлежности и б) авторитетные страницы обычно ссылаются на другие авторитетные страницы.
PageRank [Page и др. 98] представляет собой алгоритм ранжирования, исходящий из предположения (б). Он вычисляет запросо-независимую оценку авторитетности для каждой интернет-страницы и использует полученную оценку для ранжирования результатов органической выдачи. Поскольку PageRank не зависит от запроса, сам по себе он не может отличить страницы, обладающие общей авторитетностью от страниц авторитетных по тематике запроса. То есть, в целом авторитетный веб-сайт может содержать страницу, релевантную определенному запросу, но при этом он не располагает авторитетом, относительно тематики пользовательского запроса. В частности, такая страница может быть рассмотрена в рамках сообщества тех пользователей, что создают тематические документы, отвечающие на поисковый запрос, как не представляющая какой-либо значимой ценности.
Альтернативой PageRank является Topic Distillation [Kleinberg 97, Chakrabarti и др. 98, Brahat и др. 98, Chakrabarti и др. 99]. Topic Distillation в начале вычисляет запросо-зависимый подграф Сети. Это выполняется посредством включения страниц, соответствующих тематике запроса в граф и игнорирование тех документов, которые не относятся к заданной тематике. Затем алгоритм вычисляет оценку для каждой страницы в подграфе, основываясь на гиперссылочной связанности: каждой странице присваивается оценка авторитетности (authority score). Эта оценка вычисляется посредством суммирования весов всех ссылок, ведущих на интернет-страницу. Для каждой такой ссылки вес вычисляется посредством оценивания того, насколько хорошим источником ссылок является цитирующая страница. В отличие от PageRank, Topic Distillation применим только к широким запросам, поскольку требует наличия сообщества тематических страниц.
Проблемой Topic Distillation является то, что вычисление подграфа Сети по каждому запросу в режиме реального времени трудновыполнимо. В идеальном случае нам необходимо рассмотреть каждую страницу, содержащуюся в интернете, на предмет ее тематического соответствия пользовательскому запросу. На практике же используется аппроксимация. Осуществляется предварительное ранжирование по запросу с анализом содержимого документа. Из возвращенного топа выбираются страницы, соответствующие данному запросу. Так создаётся отобранное множество (selected set). Затем в него добавляются некоторые страницы, имеющие одну или две исходящие ссылки из отобранного множества, однако только в том случае, если они тематически совпадают с поисковым запросом. Такой подход может оказаться неэффективным, потому что он зависим от полноты отобранного множества. Высокорелевантная и авторитетная страница может быть исключена из результатов ранжирования в случае использования подобного рода схемы в том случае, если она не обнаруживается в начальном отобранном множестве, либо какие-то интернет-страницы, цитирующие ее, сами не были включены в отобранное множество. Процедура «сфокусированного сканирования» была предложена [Chakrabatri и др. 99] для обхода всего веба с целью обнаружения полного подграфа, отвечающего тематике пользовательского запроса, однако она оказалось слишком медленной для применения на онлайн-поиске. К тому же, затраты на вычисление всего подграфа не являются оправданными, так как пользователей интересуют только топовые результаты ранжирования.
Наш подход основан на тех же предположениях, что и другие алгоритмы, основанные на связанности, то есть на том, что количество и качество документов-источников, ссылающихся на страницу, являются хорошим показателем её качества. Главное отличие состоит здесь в том, что мы принимаем во внимание лишь «экспертные» источники — страницы, которые были созданы ради самой цели направления людей к ресурсам. Отвечая на пользовательский запрос, мы сперва вычисляем перечень наиболее релевантных экспертов, тематически связанных с самим запросом. Затем мы идентифицируем релевантные ссылки в выбранном множестве экспертов и следуем по ним с целью обнаружения целевых веб-страниц. Далее целевые страницы ранжируются согласно количеству и релевантности неаффилированных экспертов, цитирующих их со своего содержимого. Получается, что оценка целевой страницы отражает общее мнение лучших независимых экспертов по тематике пользовательского запроса. Когда такой пул экспертов недоступен, Hilltop не выдаёт никаких результатов. Таким образом Hilltop нацелен на улучшение точности поисковых результатов, а не на охват всех пользовательских запросов, адресуемых к поисковой системе.
Наш алгоритм состоит из двух основных фаз:
(i) Поиск экспертов
Экспертной страницей мы считаем такую страницу, которая посвящена определённой теме и цитирует множество неаффилированных документов, также отвечающей заданной тематике. Логично, что страницы должны рассматриваться неаффилированными в том случае, если они созданы веб-мастерами, относящимися к неаффилированным организациям. На шаге предварительной обработки, отсканированное системой информационного поиска подмножество страниц идентифицируются в качестве экспертных документов. В своём эксперименте мы классифицировали в качестве экспертных 2.5 млн. из 140 млн. страниц, содержащихся в индексе AltaVista. Страницы данного подмножества индексированы в специальный инверсированный индекс. По введённому запросу производится поиск по экспертному индексу с целью обнаружения и ранжирования подходящих экспертных страниц. Эта фаза вычисляет лучшие экспертные страницы, соответствующие тематике пользовательского запроса, а также связанную с ними информацию.
(ii) Целевое ранжирование
Мы считаем страницу авторитетной, относительно тематики пользовательского запроса, в том и только в том случае, если на нее ссылаются некоторые из лучших экспертов, связанные с заданной темой. Разумеется, в действительности экспертные страницы могут быть экспертными, относительно более общей или смежной тематики. Если это так, то релевантным может быть признано только подмножество гиперссылок, содержащихся на экспертной странице. В таких случаях рассматриваемые ссылки должны браться с особой избирательностью, чтобы убедиться в том, что описывающий их текст соответствует поисковому запросу. Скомбинировав релевантные исходящие ссылки из выборки экспертных документов, мы можем найти страницы, которые наиболее высоко ценятся сообществом веб-документов, связанных с темой запроса. Это и является основой высокой релевантности, обеспечиваемой нашим алгоритмом.
Имея топ отранжированных экспертных страниц и связанную с ними информацию, мы отбираем подмножество гиперссылок, содержащихся в контенте экспертных страниц. А именно, мы отбираем те ссылки, которые ассоциируются со всеми ключевыми словами, составляющие пользовательский запрос. Это означает, что ссылка соответствует запросу. В ходе последующего анализа связанности выбранных ссылок мы идентифицируем подмножество их целей в качестве топа страниц, отранжированных в соответствии с тематикой пользовательского запроса. Идентифицируемые нами цели — это те веб-документы, которые на которые ссылаются хотя бы две неаффилированные экспертные по данной теме страницы. Целевые страницы ранжируются посредством присвоения им ранжирующей оценки, которая вычисляется с помощью комбинирования оценок экспертных документов, ссылающихся на заданную цель.
Оставшаяся часть статьи организованна следующим образом: в Разделе 2 описывается выбор и индексирование экспертных документов; в Разделе 3 даётся детальное описание схемы ранжирования, используемой при обработке запроса; Раздел 4 демонстрирует пользовательскую оценку реализации нашего прототипа; в Разделе 5 подводятся итоги текущего исследования.
Широкий тематический профиль очень распространен в Глобальной паутине и обычно включает в себя многочисленные интернет-ресурсы, созданные людьми. Однако существуют некоторое количество людей или организаций, которые создают ресурсы, имеющие узкую тематическую специализацию постольку, поскольку это увеличивает их популярность и влияние в рамках конкретного веб-комьюнити, проявляющего интерес к заданной теме. Создатели данного рода ресурсов стремятся сделать их настолько исчерпывающими и актуальными, насколько это только возможно. Мы рассматриваем ссылки, ведущие с таких ресурсов, в качестве рекомендаций, а страницы их содержащие в качестве экспертных документов. Задача состоит в том, чтобы отличить экспертную страницу от документов прочего типа. Другими словами, мы должны ответить на вопрос: что же именно делает страницу экспертной? Интуитивно мы полагали, что экспертная страница должна отвечать критериям объективности и разнообразия: то есть, её рекомендации должны быть объективными и указывать на различные неаффилированные с ней документы, имеющие схожую тематику. Поэтому, в целях нахождения экспертных документов, нам требуется узнать, принадлежат ли два сайта одной и той же или нескольким родственным организациям.
Мы считаем пару хостов аффилированными в случаях, когда одно или оба из данных утверждений верны:
Мы называем токенами имени хоста подстроки, разделённые «.» (точкой). Суффикс хостнейма считается общим (generic), если он встречается на большом количестве различных хостов. Например, доменное имя верхнего уровня «.com» и национальное доменное имя верхнего уровня «.co.uk» имеются у огромного числа хостов, а значит, суффикс является общим. При сравнении двух хостов, если у обоих мы уберём общий суффикс, и предшествующая ему часть окажется одинаковой, то эти хосты мы будем считать аффилированными. К примеру, сравнивая «ibm.com» и «ibm.co.mx» мы проигнорируем общие суффиксы «.com» и «.com.mx». Получится, что в обоих случаях крайне правым токеном является «ibm», который для этих двух хостов идентичен. То есть эти хосты рассматриваются нами как аффилированные. Как вариант, мы можем поставить условие, чтобы в обоих случаях общие суффиксы были одинаковыми.
Связь при аффилиации является транзитивной: если A и B аффилированы, и B и C аффилированы, то мы принимаем A и C за аффилированные, даже если мы не располагаем очевидными доказательствами этого факта. В действительности многие неаффилированные хосты могут быть классифицированы как аффилированные, однако мы считаем это приемлемым, поскольку данное отношение определено как консервативное.
На этапе предварительной подготовки мы выполняем поиск хостовых аффиляций. Используя алгоритм обнаружения объединений (union-find algorithm), мы группируем в соответствующие наборы хосты, которые либо имеют идентичный крайне правый не-общий суффикс, либо общий IP-адрес. Каждому набору присваивается уникальный идентификатор (например, хост с лексикографически наименьшим хостнеймом). Поиск аффилированных хостов присваивает каждому хосту идентификатор его набора или его самого (если он не входит ни в один набор). Это процедура необходима для сравнения хостов. Если поиск отображает два хоста с одинаковыми идентификаторами, то они аффилированы, в противном случае они неаффилированы.
На этом шаге мы обрабатываем базу данных страниц системы информационного поиска (мы использовали базу данных документов, отсканированных AltaVista в апреле 1999 года) и отбираем подмножество тех страниц, которое мы считаем хорошими источниками ссылок по определённым тематикам, хотя и неизвестными. Процедура выглядит следующим образом:
Принимая во внимание все страницы, имеющие полустепень исхода превышающую предельно-допустимое максимальное значение k (например, k=5), мы проверяем, ведут ли их гиперссылки на k различных неаффилированных хостов. Каждая такая страница считается нами экспертным документом.
В случае классификации по широким рубрикам (например, искусство, наука, спорт и др.), заранее определенных для каждой страницы, хранящейся в базе данных поисковой системы, мы можем поставить дополнительное условие, чтобы большинство k неаффилированных URL-адресов, найденных на предыдущем шаге, указывали на страницы, классифицированные по аналогичным им широким рубрикам. Это позволит нам отличать случайные коллекции ссылок от каталогов ресурсов. Ко всему прочему, можно использовать иные свойства страниц, такие как регулярность разметки.
Чтобы найти экспертные страницы, соответствующие запросам пользователей, нами был создан инверсированный индекс, в котором в целях сопоставления мы закрепили ключевые слова за экспертами, на которых они появляются. При осуществлении данной процедуры, мы индексировали лишь тот текст, который содержался в HTML-секциях, включающих в себя «ключевые фразы» экспертной страницы. Ключевая фраза (key phrase) — это текст, описывающий один или более URL-адресов, встречающийся на странице. Каждая ключевая фраза имеет место быть в тексте документа. URL-адрес, расположенный в пределах какой-либо фразы, считается «квалифицированный» ею. Например, TITLE, заголовки (то есть текст, заключенный между парой тегов) и анкорный текст экспертной страницы считаются ключевыми фразами. TITLE является элементом, который описывает все гиперссылки, встречающиеся в документе. Заголовок описывает все гиперссылки до следующего заголовка аналогичного или следующего уровня. Анкорный текст распространяется только тот URL-адрес, с которым он ассоциирован. Инвертированный индекс организован в виде списка совпадающих позиций с экспертными документами. Каждое совпадение позиций соответствует обнаружению конкретного ключевого слова в ключевой фразе конкретной экспертной страницы. Все совпадения позиций заданного ключевого слова по определенному пользовательскому запросу последовательны. В каждой позиции мы также храним:
В дополнение к этому, для каждого экспертного документа имеется список URL-адресов, содержащихся в нём (как индексы в глобального списке URL-адресов), и для каждогоURL мы поддерживаем идентификаторы ключевых фраз, описывающих его. Для того чтобы не давать преимущество длинным ключевым фразам, мы ограничили количество ключевых слов, содержащихся в любой ключевой фразе (к примеру, до 32).
В ответ на пользовательский запрос, мы для начала определяем список из N наиболее релевантных данному запросу экспертов. Например, в нашем эксперименте N=200. Затем мы ранжируем результаты, выборочно следуя по релевантным гиперссылкам с этих экспертов и присваивая оценку авторитетности каждой целевой странице. В данном разделе мы опишем то, как вычисляются экспертные оценки, а также авторитетности.
Для того чтобы отвечающий эксперт удовлетворял поисковый запрос, минимальным требованием является наличие хотя бы одного URL-адреса, у которого все ключевые слова, составляющие запрос пользователя, содержались бы в ключевых фразах, квалифицирующих его. Надежной аппроксимацией может быть требование нахождения всех ключевых слов, составляющий пользовательский запрос, встречающихся в документе. Далее мы присваиваем каждому кандидату в экспертные документы некоторую оценку, отражающую количество и важность (importance) ключевых фраз, которые содержат ключевые слова, составляющие запрос пользователя, а также степень их соответствия самому запросу.
Таким образом, мы вычисляем экспертную оценку в виде кортежа из трёх компонентов (S0,S1,S2). Пусть k — это количество слов в вводимом в поисковую строку запросе q. Компонент оценки Si вычисляется только с учетом тех ключевых фраз, которые содержат ровно k — i из слов, составляющих пользовательский запрос. То есть, S0 — это оценка, вычисляемая по фразам, содержащим все термины поискового запроса.
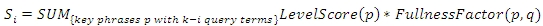
LevelScore(p) — это оценка, назначаемая фразе в зависимости от её типа. К примеру, в нашей реализации мы использовали LevelScore равную 16 для фраз, содержащихся в TITLE, 6 для заголовков (H1) и 1 для анкорного текста гиперссылок. Всё это основано на том предположении, что для определения эксперта текст TITLE более полезен, чем текст, содержащийся в заголовках, который, в свою очередь, более полезен, чем текст анкора гиперссылки.
FullnessFactor(p,q) оценивает количество терминов на странице p, охватываемых терминами в запросе q. Пусть plen — это длина p. Пусть m — количество терминов в p, которые не содержатся в q (то есть лишние термины пользовательского запроса). Тогда FullnessFactor(p, q) вычисляется следующим образом:
Наша цель заключается в предпочтении экспертных документов, которые полностью соответствуют ключевым словам, составляющих поисковых запрос; экспертам, которые соответствуют всем кроме одного ключевого слова, и т.д. Следовательно, мы начинаем ранжирование экспертов с S0. Мы разрываем связи с S1 и продолжаем их с S2. Оценка каждого эксперта конвертируется в скалярную величину по взвешенной сумме трёх компонентов:
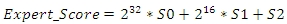
Мы рассматриваем первые N экспертных документов отранжированных на предыдущем шаге (например, первые 200) и исследуем интернет-страницы, которые они цитируют. Такие страницы называются целями. Из этого набора целей мы и выберем топовые страницы. Для того чтобы целевая страница была учтена нашим алгоритмом, на неё должны указывать по крайней мере 2 эксперта на хостах, неаффилированных ни между собой, ни с целевой страницей. Для всех целей мы вычисляем целевую оценку, отражающую как число, так и релевантность экспертов, ссылающихся на неё, а также релевантность фраз, квалифицирующих гиперссылки.
Оценка цели T вычисляется в три шага:
Для каждого ключевого слова, составляющего пользовательский запрос, w , положим occ(w,T) — число различных ключевых фраз в экспертном документе E, которые содержат w и квалифицируют ребро (E,T). Введём «оценку ребра» для (E,T), представленную Edge_Score(E,T), которая вычисляется следующим образом:
Список целевых страниц ранжируется по Target_Score. Опционально, данный список может быть отфильтрован с помощью проверки на наличие ключевых слов, составляющих пользовательский запрос, в целевых документах. Опционально, мы можем сравнить соответствие ключевых слов запроса по каждой цели для расчета Match_Score, используя контентный анализ, и скомбинировать Target_Score с Match_Score перед началом процесса ранжирования целевых страниц.
Рисунок 1. Результаты ранжирования с помощью алгоритма Hilltop по запросу «jobs»
Для того чтобы оценить наш прототип системы информационного поиска, мы провели два эксперимента с участием пользователей, направленных на оценку полноты (recall) и точности (precision). В обоих экспериментах, которые были проведены в августе 1999 года, для сравнения были также задействованы три прочих поисковых систем: AltaVista, DirectHit и Google. Заметим, что нынешние результаты ранжирования этих систем могут отличаться.
Для нашего первого эксперимента мы попросили семерых волонтёров предложить на их усмотрение домашние страницы десяти организаций (компаний, университетов, магазинов и т. п.). Ряд запросов приведено в следующей таблице:
| Альфа Фи Омега | Бэст Бай | Диджитал | Диснейленд |
| Доллар Банк | Групленс | ИНРИА | Киблер |
| Маутин Вью Паблик Лайбери | Мейсис | Миннеаполис Сити Пейджес | Московский авиационный институт |
| МЕНСА | ОЭСР | ОСУ | Питтсбург Стилерз |
| Пицца Хат | Университет Райса | СОНИ | Сэйфвэй |
| Шоппинг-центр Станфорд | Трек Байсикл | ЮСТА | Вэнгард Инвестмент |
Эти запросы были адресованы всем четырём системам информационного поиска. Мы предполагаем, что в каждом случае существует только одна домашняя страница. Каждый раз при обнаружении данной домашней страницы среди первых десяти результатов органического поиска, мы записывали её ранг. Рисунок 2 отображает среднюю полноту для рангов с 1 до 10 по каждой из четырёх поисковых систем: нашей машины Hilltop (HT), Google (GG), AltaVista (AV) и DirectHit (DH). Средняя полнота на ранге k в данном эксперименте — это вероятность нахождения искомой домашней страницы в первых k результатах.
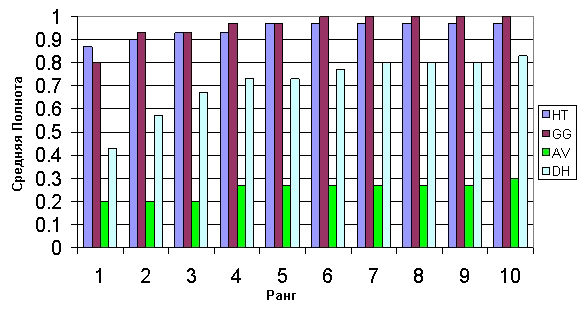
Рисунок 2. Средняя полнота и ранг.
Наша поисковая машина продемонстрировала хорошую производительность по всем использованным запросам. Примерно для 87% запросов Hilltop возвратил желаемую страницу в качестве первого результата, что сравнимо с 80% у Google, тогда как DirectHit и AltaVista успешно присвоили страницам ранг 1 всего в 43% и 20% случаев соответственно. Анализируя последующие результаты, мы видим, что средняя полнота увеличивается до 100% у Google, до 97% у Hilltop, до 83% у DirectHit и до 30% у AltaVista.
Для того чтобы оценить способность алгоритма Hilltop генерировать качественную первую страницу результатов органического поиска по широким запросам, мы попросили добровольцев предложить обширные темы (то есть такие, по которым может существовать множество качественных страниц) и сформулировать соответствующие запросы. Мы собрали 25 подобного рода запросов, которые перечислены ниже:
| Аэросмит | Амстердам | фоны | шахматы | словарь |
| мода | бесплатное программное обеспечение | FTP поиск | Годзилла | Гранд Зэфт Авто |
| поздравительные открытки | Дженнифер Лав Хьюитт | Лас-Вегас | Лувр | Мадонна |
| МЕДЛАЙН | MIDI | газеты | Париж | Поиск людей |
| реал аудио | программное обеспечение | продвижение сайтов | теннис | НЛО |
Затем мы использовали скрипт для адресации каждого запроса всем четырем поисковым системам и сбора первых 10 результатов, записывая при этом для каждого результата URL-адрес, ранг, а также поисковую машину, которая его обнаружила. Нам нужно было объективно определить, какие из результатов являются релевантными. Для каждого запроса мы сгенерировали список уникальных URL-адресов, объединенных с результатами по всем системам информационного поиска. Список был представлен асессору в случайном порядке, без какой-либо информации о рангах страниц или той поисковой системы, которая их возвратила. Асессор оценил релевантность каждой страницы, относительно заданного запроса по двоичной шкале (1 — «хорошая страница по заданной тематике», 0 — «не релевантна или не найдена»). Затем, другой скрипт скомбинировал полученные рейтинги с рангами и информацией, касающейся источников. После чего была получена средняя точность на ранге k (где k=1, 5 и 10). Результаты приведены на Рисунке 3.
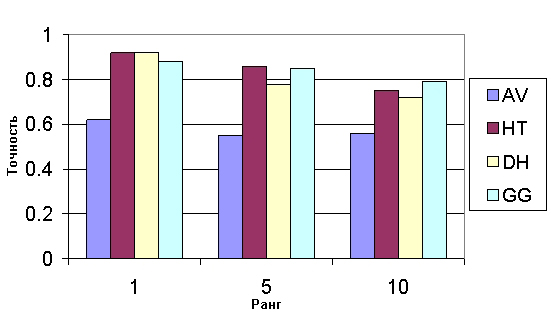
Рисунок 3. Средняя точность для ранга k.
Данные результаты показывают, что для обширных тем наша система информационного поиска возвращает большой процент высокорелевантных страниц по всем десяти топовым страницам, что сравнимо с Google и DirectHit и лучше чем у AltaVista. Для ранга 1 алгоритм Hilltop и DirectHit имеют среднюю точность в 0.92. Средняя точность для ранга 10 у Hilltop составляет 0.77, что близко к результату лучшей поисковой системы Google, имеющей точность 0.79 для ранга 10.
Мы описали новый алгоритм ранжирования широких запросов, называемый Hilltop, и реализацию поисковой системы, использующей данную методологию. Для данного широкого запроса, Hilltop генерирует список целевых страниц, которые могут быть авторитетными страницами в рамках его тематики. Это обеспечивается тем фактом, что они высоко оцениваются тематическими документами в Сети. При вычислении полезности целевой страницы по цитирующим ее гиперссылкам, мы принимаем во внимание только те ссылки, которые исходят из документов, рассматриваемых как экспертные. В нашем определении, экспертами являются каталоги ссылок, указывающих на множество неаффилированных сайтов. Это является признаком того, что данные страницы были созданы для направления пользователей к ресурсам, и поэтому мы считаем их мнение ценным для работы нашего алгоритма. Кроме того, при вычислении уровня релевантности мы требуем совпадения пользовательского запроса и текста экспертной страницы, который квалифицирует рассматриваемую гиперссылку. Это гарантирует нам то, что рассматриваемые гиперссылки подходят под тематику запроса. Для большей аккуратности мы требуем, чтобы хотя бы 2 неаффилированных эксперта указывали на возвращённую страницу, имея релевантный текст, описывающий их связь. Результатом описанных выше шагов является генерация списка страниц, которые отличаются высокой релевантностью запросу пользователя и имеют высокое качество.
Алгоритм Hilltop сильно напоминает технологию связности, методологию PageRank и Topic Distillation. В отличие от PageRank, наш алгоритм динамичен и принимает во внимание связность на веб-графе конкретно по тематике поискового запроса. Благодаря этому, он может вычислить релевантность содержимого, исходя из точки зрения сообщества веб-мастеров, заинтересованных в тематике запроса. В отличие от Topic Distillation, мы перебираем и рассматриваем все хорошие экспертные документы, соответствующие теме, и, следовательно, все хорошие целевые страницы, попадающие под неё. Для того чтобы найти наиболее релевантные экспертные документы, мы используем собственный подход, основанный на ключевых словах, фокусируясь только на тексте, который наилучшим образом охватывает область настоящего анализа (TITLE документа, заголовки разделов H1-H6 и анкорный текст гиперссылок). Затем, следуя по гиперссылкам, мы увеличиваем оценку тех целевых документов, чей квалифицирующий текст лучше подходит под пользовательский запрос. То есть, совмещая контентный анализ и гиперссылочную связность, мы достигаем большей точности и полноты. Важной особенностью нашего алгоритма является то, что, в отличие от Topic Distillation, мы можем доказать, что если та или иная страница не оказалась в предложенных пользователю результатах, то это является следствием дефицита со стороны саппортеров, которые бы оправдали ее нахождение среди прочих ответов. Таким образом, мы имеем меньшую вероятность не учесть хорошие страницы по заданной теме, что является проблемой всех систем, использующих Topic Distillation. Кроме того, поскольку мы используем индекс, оптимизированный для поиска экспертов, наша реализация использует меньше данных чем Topic Distillation, и как следствие — работает быстрее.
Индексация анкорного текста гиперссылок впервые была предложена в WWW Worm [McBryan 94]. В некоторых системах, использующих Topic Distillation, таких как Clever [Chakrabarti и др. 1998], как и в поисковом движке Google [Page и др. 98], анкорный текст рассматривается в качестве оценки релевантности ссылки. Мы обобщаем данный подход до прочих форм текста, которые могут «квалифицировать» гиперссылку документа-источника, также рассматривая TITLE страниц и их заголовки. Кроме того, в отличие от систем, использующих Topic Distillation, мы оцениваем экспертные документы исходя из соответствия их содержимого запросу пользователя, а не из того факта, что они только цитируют качественные целевые страницы. Это помогает избежать обнуления оценки «нишевых экспертов» (то есть экспертов, которые ссылаются на новые или слабо связанные страницы), что часто происходит в алгоритмах Topic Distillation.
Используя методологию слепой оценки, мы обнаружили, что Hilltop обеспечивает высокий уровень релевантности по широким запросам и в процессе тестирования не уступает лучшим коммерческим системам информационного поиска.
 |
Кришна Бхарат – член исследовательской группы в Google Inc, Маунтин-Вью, штат Калифорния. Ранее он работал в Compaq Computer Corporation’s System Research Center, где и проводилось описанное исследование. Его исследовательские интересы включают обнаружение цифрового контента и информационный поиск, проблемы пользовательского интерфейса в Веб-поиске и автоматизации задач, а так же оценка релевантности документов в Глобальной Паутине. Он получил докторскую степень по специальности Компьютерных Технологий в Технологическом Институте Джорджии в 1996, где он работал над поддержкой инструментов и инфраструктуры для распределённых приложений пользовательского интерфейса. |
 |
Джордж Андрей Михаила – кандидат в Доктора Наук на Факультете Компьютерных Технологий в Университете Торонто. Летом 1999 он проходил интернатуру в Compaq Computer Corporation’s System Research Center. Его исследовательские интересы включают в себя языки запросов, методы обнаружения информации, сетевые информационные системы и интеграцию баз данных. Он получил степень Магистра Компьютерных Технологий в Университете Торонто в 1996 с темой диплома «WebSQL и SQL-подобный язык запросов для Глобальной Паутины. |
Ссылки:
[Chakrabarti et al 98] S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, P. Raghavan, and S. Rajagopalan. Automatic Resource Compilation by Analyzing Hyperlink Structure and Associated Text. Proceedings of the 7th World-Wide Web conference, 1998.
[Chakrabarti et al 99] S. Chakrabarti, M. van den Berg and B. Dom. Focused crawling: A new approach to topic-specific Web resource discovery. In the 8th World Wide Web Conference, Toronto, May 1999.
[Bharat et al 98] K. Bharat and M. Henzinger. Improved algorithms for topic distillation in a hyperlinked environment. In SIGIR Conference on Research and Development in Information Retrieval, volume 21. ACM, 1998.
[McBryan 94] Oliver A. McBryan. GENVL and WWWW: Tools for Taming the Web. First International Conference on the World Wide Web. CERN, Geneva (Switzerland), May 25-26-27 1994.
Перевод материала «When Experts Agree: Using Non-affiliated Experts toRank Popular Topics» выполнил Максим Евмещенко
Полезная информация по продвижению сайтов:
Перейти ко всей информации