SEO-Константа
Яндекс.Директ + оптимизация
Противодействие поисковому спаму является одной из первостепенных задач систем информационного поиска. Современные технологии обнаружения веб спама, как правило, разрабатываются для определенных, известных типов манипулятивных практик и оказываются абсолютно неэффективными в случае появления новых инструментов воздействия на алгоритмы ранжирования. Используя анализ информации пользовательского поведения, извлекаемой из логов веб-доступа, предложенный нами алгоритм обнаружения спам страницы основывается на байесовских методах машинного обучения. Основной вклад настоящей работы заключается в следующем: Во-первых, исследуются паттерны пользовательских визитов на некачественные веб-документы; предлагается ряд особенностей пользовательского поведения, позволяющих отличить обычную страницу от спам-документа. Во-вторых, новый фреймворк обнаружения спама предполагает возможность обнаружения обманных практик различного вида, в том числе и недавно появившегося в среде поисковой оптимизации, посредством все того же анализа пользовательского поведения. Практические эксперименты, проведенные на крупномасштабной коллекции пользовательских логов, продемонстрировали эффективность учтенных особенностей поведения пользователей, а также разработанного нами фреймворка.
С увеличением информации, содержащейся в Глобальной паутине, поисковые системы играют все более значимую роль в повседневной жизни людей. Согласно отчету по исследованию поискового поведения, системами информационного поиска пользуется 69.4% китайских интернет-пользователей; из них 84.5% рассматривают поисковые машины в качестве основного инструмента доступа к веб-информации [CNNIC 2009]. Несмотря на то, что поисковые системы обычно возвращают своим пользователям тысячи поисковых результатов, подавляющее большинство их клиентов просматривают только первые несколько страниц в результатах органической выдачи [Silverstein и др. 1999]. По этой причине нахождение сайтов в результатах органической выдачи стало основной проблемой поставщиков поиска. Проблемой это стало во многом и потому, что в целях достижения «незаслуженно высоких оценок или благоприятного соответствия какой-либо страницы пользовательскому запросу, отличающихся от истинной ценности веб-документа» [Gyongyi и Garcia-Molina 2005], поисковая оптимизация разрабатывает различные типы манипулятивных технологий, вводящих в заблуждение алгоритмы систем информационного поиска. В 2006 году было подсчитано, что к категории спама относится порядка 1/7 англоязычных веб-страниц, и данные некачественные документы препятствуют процессу удовлетворения информационных потребностей интернет-пользователей [Wang и др. 2007]. Таким образом, вычисление спама считается одной из первостепенных проблем, которая встает перед поставщиками веб-поиска [Henzinger и др. 2003]. Большинство анти-спам технологий используют особенности веб-документов, относящиеся либо к их содержимому, либо к гиперссылочной структуре, для последующего построения соответствующих спам-классификаторов.
В подобного рода фреймворках детекции спам-документов разработчики анти-спам технологий изучают характеристики того определенного типа спама, инъекция которого была осуществлена в индексную базу и теперь отображается в результатах органической выдачи, а затем разрабатывают стратегии для его идентификации. Однако, после обнаружения и фильтрации из результатов поиска одного типа спама, разработчики манипулятивных практик создают новые, более совершенные спам технологии, предназначенные для обмана поисковых машин. С момента широкого распространения поисковых систем, пришедшегося на конец 90-х, сегодня веб спам развился из ссылочного спаминга и манипуляций, связанных с использованием ключевых фраз, до обманных технологий, которые применяют маскировку и скрытую переадресацию, реализуемую посредством JavaScript. Несмотря на то, что методы машинного обучения, будучи легко адаптируемые к вновь разрабатываемым спам-методикам, продемонстрировали свое превосходство в задачах вычисления некачественных документов, данные подходы требуют исследований, учитывающих особенности конкретных спам-страниц и создания подходящих обучающих наборов. Такого рода анти-спам фреймворк вызывает множество проблем у разработчиков поисковых машин. Борьба с поисковым спамом становится в этом случае бесконечным процессом. Разработка и реализация анти-спам технологий имеет под собой трудность временного момента, который заключается в том, что в той ситуации, когда разработчики поисковых машин обнаруживают определенный тип спама и нейтрализуют его влияние на результаты поиска, ему уже удается привлечь внимание большого числа интернет-пользователей, а спамеры переключаются на новые типы манипулятивных методологий. В отличие от преобладающих подходов, мы предлагаем анти-спам фреймворк иного типа: фреймворк детекции поискового спама основывается на мудрости толпы. В последнее время теория мудрости толпы получила пристальное внимание в исследованиях веб-поиска (например, Fuxman и др. [2008], Bilenko и White [2008]). В этих работах мудрость толпы обычно рассматривается как своего рода неявная обратная связь, свидетельствующая о важности веб-документа и его релевантности поисковому запросу. В отличие от предшествующих исследований мы используем теорию мудрости толпы в задачах идентификации спам страниц посредством анализа пользовательских логов веб-доступа. Маскируясь под обычные веб-страницы, поисковый спам стремится обмануть алгоритмы ранжирования систем информационного поиска, предлагая их клиентам некачественное содержимое, которое не может удовлетворить информационные потребности интернет-пользователей. Следовательно, паттерны пользовательских визитов на некачественные веб-страницы отличаются от заходов на ординарные документы с качественным содержимым. Путем сбора и анализа крупномасштабной коллекции пользовательских логов доступа к Сети мы можем обнаружить ряд особенностей в пользовательском поведении при посещении спам-документов. Эти особенности используются для разработки анти-спам алгоритма, предназначенного для своевременной, эффективной и независимой от типа идентификации поискового спама. Вклад настоящей работы в рассматриваемую нами тему заключается в следующем:
Остальная часть настоящей работы организована следующим образом. В разделе 2 дается краткий обзор смежных работ по теме вычисления спама. В разделе 3 анализируется различия в паттернах пользовательских визитов, наличествующие между спам-страницами и ординарными документами, а также предлагаются соответствующие особенности. Фреймворк обнаружения спама основывается на анализе поведения и схеме обучения, предложенной в Разделе 4; экспериментальные результаты, представленные в Разделе 5, оценивают производительность нашей методологии на крупномасштабной коллекции реальных логов веб-доступа. В завершении текущего материала делается заключение и обсуждается будущая работа.
В соответствии с таксономией поискового спама, предложенной в работе [Gyongyi и Garcia-Molina 2005], манипулятивные технологии могут быть сгруппированы в две категории: ссылочный спам и манипуляции, связанные с использованием ключевых фраз. Применение ключевых фраз относится к тем практикам, которые приспосабливают содержимое определенных HTML-секций некачественной страниц таким образом, что она становится релевантной поисковым запросам пользователей [Gyongyi и Garcia-Molina 2005]. К подобного рода HTML-секциям, которые используются для реализации данной технологии, чаще всего относятся TITLE документа, мета-тег KEYWORDS, URL-адрес и анкоры гиперссылок. В целях получения более высокого ранга, который достигается путем обмана алгоритмов расчета релевантности контента пользовательским запросам, в указанных выше HTML-секциях перечисляются (иногда многократно) наиболее популярные ключевые фразы. Ссылочные спамеры создают искусственную гиперссылочную структуру для оптимизации тех оценок, что присуждаются алгоритмами анализа ссылок. Как правило, для вычисления авторитетности цифровых документов используются такие алгоритмы гиперссылочного анализа, как Google PageRank [Brin и Page 1998] и HITS [Kleinberg 1999]. Ссылочные фермы, приманки (honeypots, дословно с англ. «горшочки с медом») и обмен спам-линками — все это является средствами манипулирования ссылочным графом, которые вводят обозначенные ранее алгоритмы в заблуждение. После предложенной в 2005 году таксономии поискового спама [Gyongyi и Garcia-Molina 2005] в Глобальной паутине появилось еще больше типов манипулятивных технологий, отнесение которых в ту или иную существующую категорию в ряде случаев представляются достаточно трудной задачей. Вследствие применения технологии маскировки (клоакинга) пользователям некачественной страницы и сканирующим механизмам поисковых машин может отдаваться различное содержимое [Wu и Davison 2005]. При попытке просмотра пользователем «нормальной» веб-страницы его интернет-обозреватель может быть автоматически перенаправлен на сторонние спам-домены [Wang и др. 2007]. В настоящее время для реализации данных обманных практик спамеры используют технологии JavaScript, Каскадные Таблицы Стилей (CSS) или даже Flash-ролики (см. Рисунок 1).
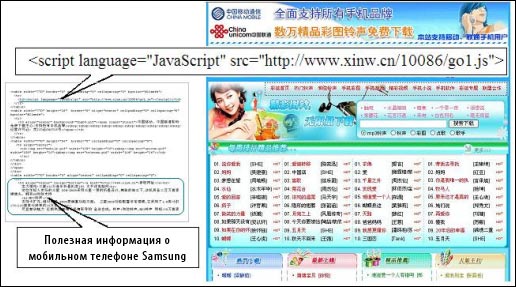
Рисунок 1. Спам-страница, использующая JavaScript для сокрытия рекламы. Реклама, предлагающая скачать рингтон для мобильного телефона, скрыта в JavaScript [xinw.cn/10086/go1.js]. В левой части рисунка мы видим исходный HTML-код документа; в правой части рисунка то, как он отображается в браузере пользователя.
Как только в вебе появляется новый тип поискового спама, разработчики систем информационного поиска создают такую анти-спам технологию, которая позволяла бы его идентифицировать. Тогда спамерами реализуются новые манипулятивные практики, которые смогли бы обмануть данные технологии, и так далее до бесконечности. В целях противодействия поисковому спаму и совершенствования взаимодействия с пользователем, как поисковые системы, так и исследователи веб-поиска разработали огромное количество методов, позволяющих обнаружить некачественные документы в сети. Относительно недавно, Castillo и Davison [2010] предоставили исчерпывающий обзор, затрагивающий тему противодействия веб-спаму, а также разместили все существующие анти-технологии по трем группам, а именно: группа методов идентификации спама, основанных на анализе содержимого; группа анти-спам технологий, исследующих ссылочную структуру; группа алгоритмов, использующих данные пользования.
2.2.1 Алгоритмы идентификации спама, основанные на анализе содержимого и гиперссылочной структуры
Действия, направленные на манипулирование алгоритмами ранжирования, иногда могут быть обнаружены посредством анализа статистических особенностей, относящихся к содержимому интернет-страниц, в том числе тех, что описаны в работах Fetterly и др. [2004], а также Ntoulas и др. [2006]. Недавно, Cormack и др. [2011] сконструировали классификатор из запросов-приманок с N-граммными контентными характеристиками. Они обнаружили, что классификатор показал хорошие результаты на веб-корпусе ClueWeb, имеющего масштаб в терабайт данных, а также улучшил производительность поиска для большинства результатов WEB TREC. Тем временем, подавляющее большинство исследований по обнаружению спама, фокусировалось на анализе гиперссылочных структур. Работы Davison [2000], а также Amitay и др. [2003] стали одними из первых исследований ссылочного спама. Gyongyi и др. [2004] предложили вероятностный алгоритм доверия TrustRank, основной задачей которого является отделение авторитетных документов от спам-страниц. Его работа была продолжена крупными исследованиями, затрагивающих данную проблему, среди которых можно выделить работы, описывающую алгоритмы Anti-Trust Rank [Krishnan и Raj, 2006] и Truncated PageRank [Becchetti и др. 2006]. В целях комбинирования гиперссылочных особенностей и достижения большей эффективности идентификации спама были также использованы методы, в основе которых лежит машинное обучение [Geng и др. 2007]. Wu и Davison [Wu и Davison 2005] предложили методологию вычисления сокрытия (клоакинга), который основан на сканировании и сравнении различных копий интернет-страничек. Wang и др. [2007] предложил идентификацию тех некачественных документов в сети, которые используют технологию автоматических редиректов, посредством соединения спамеров и рекламодателей через анализ перенаправлений. Svore и др. [2007] использовали запросо-зависимые особенности для улучшения эффективности обнаружения веб-спама.
Все вышеуказанные анти-спам технологии могут идентифицировать специфичные типы поискового спама, и в подавляющем большинстве случаев достигают существенного результата в задачах его вычисления. Однако по той простой причине, что сетевую экологию постоянно «загрязняют» новые типы манипулятивных технологий, наиболее совершенный веб-спам все еще может быть обнаружен в результатах органической выдачи, а иногда даже на самых лидирующих позициях систем информационного поиска. С данными методологиями вычисления спама связывают две основные проблемы:
2.2.2 Вычисление спама посредством анализа пользовательского поведения
Для разрешения двух указанных выше проблем, наличествующих в том случае, если мы применяем алгоритмы, основывающиеся на анализе гиперссылочной структуры и исследующих контентные особенности веб-документов, ряд исследователей попытались улучшить производительность обнаружения поискового спама посредством подключения анализа пользовательского поведения. В целях идентификации спамеров или их активности, эти работы опирались на данные поисковых логов, логов просмотра или логов пользовательских кликов, совершаемых по рекламным объявлениям. Многие из них фокусировались на обнаружении практики кликфрода (скликивания рекламного объявления) [Jansen 2007] или автоматического поискового трафика [Buehrer 2008] посредством сепарации аномальных кликов от ординарных. В большей степени они были сконцентрированы над задачей нейтрализации спам-активности, а не удаления некачественных документов с помощью анализа пользовательского поведения. В области исследования идентификации спама посредством анализа пользования Bacarella и др. [2004], используя информацию поведения пользователей при просмотре интернет-страниц, построили граф пользовательского трафика. Они обнаружили, что интернет-сайты, имеющие крайне высокий показатель взаимосвязанного трафика (relative traffic), как правило, оказывались некачественными ресурсами. В целях обнаружения ключевых фраз-приманок, которые обычно используются спамерами, Ntoulas и др. [2006], а также Castillo и др. [2008] анализировали логи поисковых запросов. Впоследствии Chellapilla и Chickering [2006] обнаружили, что в качестве манипулятивных ключевых фразах могут использоваться как высокопопулярные, так и монетизирующиеся поисковые запросы. Основное отличие между нашим фреймворком и всеми упомянутыми выше методологиями заключается в том, что мы в равной степени фокусируемся на анализе данных пользовательского поведения на поиске, так и на поведенческой информации, получаемой в ходе просмотре пользователем интернет-страниц. Именно это позволяет нам получить четкую картину, относительно выхода пользователей на спам-страницы и их последующего взаимодействия с некачественными документами. Таким образом, мы можем сравнить паттерны пользовательских визитов как для спам-документов, так и для ординарных страниц, а также с их помощью предложить соответствующий метод определения некачественных узлов. В наших предыдущих работах [Liu и др. 2008a][Liu и др. 2008b] мы предложили три характеристики пользовательского поведения и построили наивный байесовский классификатор для сепарации некачественных страниц от ординарных документов. В настоящем материале мы предлагаем вам три новые особенности, которые являются производными от информационных моделей пользовательского поведения. Кроме того, производительность предложенного нами алгоритма сравнивается с некоторыми широкораспространенными алгоритмами обучения. В дополнение к этому, мы использовали набор данных, отличный от использованного нами ранее в [Liu и др. 2008a] и [Liu и др. 2008b]. Нашей целью являлось доказательство надежности и эффективности текущего методов вычисления спама.
С развитием систем информационного поиска устанавливаемые в браузер пользователя тулбары становятся все более популярными. Многие поисковые системы (например, Google и Yahoo!) разработали данное программное обеспечение с целью увеличения количества обращений к своим сервисам. Действительно, как правило, пользователи устанавливают панель инструментов для получения мгновенного доступа к различным поисковым службам, а также для оснащения своих интернет-обозревателей рядом полезных расширений, таких как блокировка всплывающих рекламных окон и ускорение процесса загрузки файлов из интернета. Для предоставления своим пользователям дополнительных услуг более высокого качества, большинство тулбарных сервисов также занимаются сбором анонимной информации о пользовательских кликах, записываемых в ходе просмотре страничек интернет-сайтов, что разрешается лицензией пользовательского соглашения. Предыдущие работы [Bilenko и White 2008] использовали такого рода кликовую информацию для улучшения производительности функции ранжирования. В настоящем материале мы использовали логи веб-доступа, собранные посредством панели инструментов поисковых систем, так как именно такой тип источника данных занимается непрерывным сбором информации о пользовательском поведении при минимальной стоимости. Записанная в логах веб-доступа информация представлена в Таблице 1.
| Имя | Описание |
| ID пользователя | Случайный ID пользователя |
| URL источника | URL текущей страницы |
| Целевой URL | URL страницы перехода |
| Время | Временной промежуток поведения пользователя |
Таблица I. Информация, записанная в логах веб-доступа.
Пример 1. Образец лога веб-доступа от 15 декабря 2008 года.
| Время | ID пользователя | URL источника | Целевой URL |
| 1:07:09 | 3ffd50dc34fcd7409100101c63e9245b | v.youku.com/v_plavlist/fl 707968o1р7.html | youku.com/playlist_show/id_ 1707968.html |
| 1:07:09 | f0ac3a4a87dla24b9claa328120366b0 | user.qzone.qq.com/234866837 | cne.imgcachc.qq.com/qzone/blog/tmygbstatic.htm |
| 1:07:09 | 3tb5ae2833252541b9ccd9820bad30f6 | qzone8.net/hack/45665.html | qzone8.net/hack/ |
Из Таблицы 1 и Примера 1 мы видим, что никакой приватной информации в логах веб-доступа не содержится. Представленная информация может быть получена достаточно просто, а именно посредством применения тех панелей инструментов, которые предлагаются коммерческими поисковыми системами и устанавливаются в браузер пользователя. Следовательно, их использование представляется нам вполне оправданным в задачах получения таких типов информации и их применения для идентификации спама. Логи веб-доступа собирались в период с 12 ноября по 15 декабря 2008 года с помощью широко используемой в Китае коммерческой поисковой системы. В общей сложности, в этих логах содержались записи о 3.49 млрд. пользовательских кликах по 970 млн. интернет-страниц (4.25 млн. сайтов) и 28.1 млн. пользовательских сессий.
После сбора логов веб-доступа нам потребовалась процедура очистки данных от возможных шумов с целью их уменьшения. Для того чтобы сохранить только существенные данные пользовательского поведения мы выполнили следующие три шага:
3.2.1 Обнаружение перенаправлений
Некоторые клики, которые мы наблюдаем в логах веб-доступа, в действительности не относятся к действиям, совершаемых пользователями в процессе серфинга. Напротив, настоящие события являются следствием широко распространенной технологии автоматического перенаправления URL. Такие записи должны быть исключены постольку, поскольку они не составляют данные «пользовательского поведения». Мы идентифицируем перенаправления на основании часто встречающихся ссылочных паттернов и верификации этих паттернов с использованием поискового сканера. В процессе очистки мы исключили из нашего поведенческого набора более 70 млн. записей о перенаправлении. Несмотря на то, что ряд предыдущих работ [Buehrer и др. 2008] отмечали, что перенаправления могут быть использованы в качестве сигнала, указывающего на мошенническую деятельность, мы обнаружили, что большинство редиректов приходится на ординарные веб-документы. Например, на сайте g.cn выполняется автоматическое перенаправление на ресурс google.cn; несмотря на то, что первый URL-адрес не только короче, но и легко запоминаем для большинства веб-пользователей, основным адресом китайской версией поисковой системы Google является именно второй URL.
3.2.2 Обнаружение кликфрода
В процессе анализа логов веб-доступа мы предположили, что под всяким кликом следует подразумевать желание пользователя посетить целевую страницу в целях удовлетворения информационных потребностей или получения каких-либо услуг. Однако пользователи могут проходить по ссылкам, ведущих на целевой документ, без какой-либо реальной заинтересованности. Деятельность, при которой пользователи (или их программная имитация) могут скликивать рекламные объявления, размещенные по принципу платы за клик, называется кликфродом. В ходе идентификации кликфрода, вычислить который нам позволили технологии той самой коммерческой поисковой системы, что помогала нам собирать логи веб-доступа, мы обнаружили около 41 млн. записей, относящихся к подобного рода мошеннической практике.
3.2.3 UV и UV с уникальных IP
В том случае, если на один сайт приходится мало пользовательских визитов (сокр. UV) или в том случае, если большинство из них осуществляется с одного IP-адреса, можно обнаружить, что данные пользовательского поведения, относящиеся к указанному ресурсу, формируют только несколько пользователей. Такого рода поведенческие данные могут быть необъективными и ненадежными. Следовательно, для этих интернет-сайтов нам необходимо уменьшить объем поведенческих данных. Мы просмотрели логи веб-доступа и подсчитали данные UV для каждого сайта из тех, что значились в наших записях. Таким образом, были удалены данные пользовательского поведения для интернет-сайтов с UV < 10 (включая 1.01 млрд. пользовательских кликов).
В процессе выполнения всех трех шагов по очистке записей, по истечению которого было удалено 1.12 млрд. пользовательских кликов, в нашем распоряжении осталось приблизительно 68% от исходного набора данных. Мы полагаем, что очистка данных крайне необходима постольку, поскольку полезные для нас особенности пользовательского поведения не должны извлекаться из поведенческого набора, имеющего шумы и недостоверную информацию.
В течение всего времени сбора логов веб-доступа, три профессиональных асессора занимались созданием обучающего спам-множества. Сперва, эти асессоры проинспектировали результаты поисковой выдачи для 500 наиболее популярных (frequently-proposed) пользовательских запросов, которые были выбраны случайным образом из наиболее запрашиваемых той системы информационного поиска, что помогала нам осуществлять сбор логов веб-доступа. Мы удалили запросы навигационного типа, так как в результатах органической выдачи на них откликалось только несколько спам-документов. В процессе аннотирования обучающего набора страница P обозначалась нами как спам-документ в том случае, если она отвечала любому из всех предложенных ниже критериев:
Для начала два асессора проинспектировали результаты поисковой выдачи и аннотировали некоторое число некачественных страниц. В том случае, если их мнение, касательно качественной составляющей определенных документов расходилось, к делу подключался третий асессор, который решал в чью же именно пользу следует вынести окончательное решение. Поскольку нам было необходимо создание обучающей выборки на уровне веб-сайтов, далее мы снова исследовали аннотированные спам-страницы на предмет того, возможно ли рассматривать в качестве некачественных ресурсов те сайты, к которым относились вышеуказанные документы (в соответствии с нашей логикой, некачественный сайт характеризуется высоким содержанием спам-страниц). И вновь, задачу по аннотированию веб-сайтов выполняли все та же тройка асессоров. Мы также исключили те сайты, что не значились в очищенных логах веб-доступа. В завершении, для создания обучающей спам-выборки, мы отобрали 802 сайта.
Для создания проверочного спам-множества, мы выбрали случайным образом 1997 веб-сайтов из очищенных логов веб-доступа (около 1/2000 всех сайтов, представленных в корпусе) и попросили трех наших асессоров проаннотировать данные ресурсы. Процесс аннотирования обучающего спам-набора был выполнен с использованием популярных ненавигационных запросов (в том числе множества запросов-приманок), в то время как проверочная выборка создавалась рандомно. Причина, по которой процесс обучения может основываться на спам-образцах и неразмеченных данных, в то время как процесс проверки, который должен учитывать как спам (спам-положительный результат), так и НЕ-спам (отрицательный результат) образцы, заключается в необходимости оценивания производительности предложенного нами алгоритма. В том случае, если для построения проверочного набора мы также используем поисковую выдачу некоторых запросов-приманок, процесс создания выборки может быть необъективным как по отношению к контенту, так и по отношению к качеству документов (наиболее высокоранжируемые результаты, соответственно, принадлежат наиболее качественным страницам). С целью подбора некоторого сайта-кандидата S, отвечающего требованиям нашей проверочной выборки, процесс аннотации выполнялся следующим образом:
Для начала мы извлекли из логов веб-доступа информацию, касающуюся пользовательских визитов по интернет-документам в S, а также сформировали список всех страниц с указанием частоты пользовательских посещений для всякой из них. Затем, комментаторы просмотрели первые несколько документов, имеющих наиболее высокую частоту посещений, и проверили их на предмет качества, то есть являлись ли они спам-страницами или нет. Документ P аннотировался как некачественный в том случае, если он соответствовал любому из нижеперечисленных критериев:
Как и прежде, два наших эксперта занимались просмотром результатов поиска и комментированием спам-документов. В том случае, если их мнения, относительно какого-либо документа, расходились, в дело подключался третий асессор, который решал в какую же именно категорию следует отнести страничку. Если три или более страниц S, имеющих высокую частоту визитов, комментировались как «Спам», в категорию некачественных S относился весь сайт целиком. Результатом процесса аннотирования стало то, что некачественными были признаны 491 сайт, к категории НЕ-спам было отнесено 1248 сайтов; 258 ресурсов в процессе аннотирования оказались недоступными, а потому не были отнесены в какую либо определенную категорию, получив от нас отметку «Оценка невозможна».
Посредством логов веб-доступа, а также обучающего/проверочного набора мы смогли исследовать различные поведенческие паттерны между ординарными и некачественными страницами с целью лучшего понимания персептивных и когнитивных факторов, лежащих в основе пользовательского поведения. На основании анализа этих отличий мы предложили некоторый ряд особенностей пользовательского поведения, позволяющих различать спам-документы от ординарных веб-страниц.
В этом Разделе мы предлагаем вам ознакомиться с шестью особенностями пользовательского поведения, которые помогают отличить качественные документы от спам-страниц. Первые пять характеристик используют паттерны пользовательского поведения, в то время как последняя характеристика — гиперссылочный анализ; она является особенностью, извлекаемой из графа пользовательских просмотров, также сконструированного с учетом данных логов веб-доступа. Мы сравнивали особенность распределения ординарных и спам-страниц вместо того, чтобы заниматься сравнением спам и НЕ-спам документов. Дело в том, что существуют колоссальные различия в паттернах пользовательских визитов между НЕ-спам документами. Приведем пример: и домашняя станица ресурса CNN, и тот документ, что относится к новостной статье указанного издания, может быть рассмотрен в качестве НЕ-спам документа, в то время как количество пользовательских визитов/кликов по ним будет значительно отличаться. Если бы мы создали обучающий набор, состоящий из НЕ-спам страниц, мы бы не смогли охватить все типы НЕ-спам документов, которые имеют несколько сотен, тысяч или даже десятки тысяч примеров в глобальной паутине. Таким образом, в анализе характеристик и процессе обучения алгоритма, все неразмеченные интернет-странички рассматриваются нами в качестве выборки «ординарных страниц».
В дополнение к тем характеристикам (Показатель пользовательских визитов, приходящихся на системы информационного поиска (SEOV), показатель посредничества (SP), показатель непродолжительной навигации (SN)), которые были описаны в наших предыдущих работах [Liu и др. 2008a][Liu и др. 2008b], мы представляем здесь три абсолютно новые особенности пользовательского поведения: тематическое разнообразие пользовательских запросов, по которым документ может быть обнаружен в результатах поиска (QD); количество спам-ориентированных запросов (SQN) и человеко-ориентированный TrustRank. Их использование позволяет сделать предложенный нами фреймворк детекции некачественных страниц более эффективным. Мы применяем меньшее число особенностей, нежели чем тем методы, которые были предложены в предыдущих исследованиях. Например, в работе Agichtein и др. [2006] используется 298 характеристик. Такое количественное различие объясняется тем, что наш фреймворк фокусируется на высокоуровневые характеристики; каждая из этих особенностей исследовалась нами на предмет ее пригодности в задачах обнаружения спама. Задействование небольшого числа особенностей позволяет получить более высокую производительность с относительно простым и эффективным алгоритмом обучения, что может иметь куда большую полезность при решении практических задач в реальных условиях интернет среды. В текущем Разделе статистические распределения этих особенностей в обучающем наборе сравниваются с теми, что имеются в выборке ординарных страниц. Набор ординарных документов содержит все страницы, записанные в логах веб-доступа, которые были описаны в Разделе 3.
Пользователи могут посещать страницы веб-сайтов различными способами: посещение может складываться посредством рекомендаций тех или иных ресурсов, поступившие от их друзей и знакомых; после просмотра рекламы, которая, естественно, должна вызвать у них доверие и желание посетить рекламируемый сайт; пользователи могут возвращаться к значимым с их субъективной точки зрения страницам, используя закладки браузера или историю посещений; наконец, они также могут следовать по исходящим гиперссылкам с определенного документа, которые отвечают их интересам. Несмотря на то, что продвижение сайтов старается привлечь внимание пользователей к некачественной странице, ее содержимое не может удовлетворять информационные потребности подавляющего большинства пользователей поиска. Следовательно, вероятность того, что друзья нашего абстрактного пользователя будут рекомендовать ему посетить спам-документ, как и то, что сам пользователь пожелает сохранить результат в закладках или выйти на него, посредством прохождения по исходящим ссылкам с НЕ-спам ресурса, является крайне незначительной. Для большинства спам-страниц значительная доля пользовательских визитов приходится именно на результаты органического поиска. Однако, если ординарный документ содержит полезную информацию, в этом случае у пользователя существуют и альтернативные пути выхода/возврата на данный ресурс (например, посредством все тех же рекомендаций от знакомых), а не только путем прохождения по результатам выдачи систем информационного поиска. Мы определяем показатель пользовательских визитов, приходящихся с поисковых машин (коэффициент SEOV), на некоторую страницу p как:
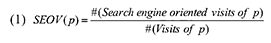
В то время, как ординарный документ может иметь разнообразный спектр источников пользовательских визитов, заходы на некачественную страницу в своей основной массе складываются из поискового трафика, оставляя удельный вес прочих источников крайне незначительным. Таким образом, значения коэффициента SEOV для спам-страницы должны быть выше, нежели чем у ординарных страниц. Представленные на Рисунке 2 статистические результаты подтверждают наше предположение.
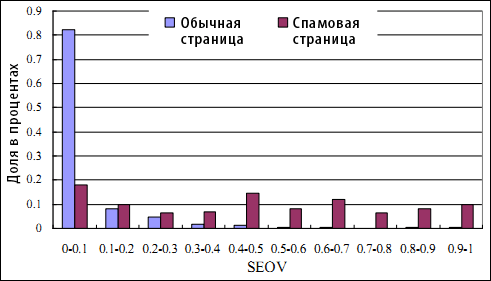
Рисунок 2. Распределение SEOV (Search Engine Oriented Visiting) для ординарных документов и спам-страниц. (Ось категорий: значение интервала SEOV; Ось значений: процент страниц с соответствующими значениями SEOV).
Рисунок 2 демонстрирует статистику посещений ординарных страниц по всем интернет-сайтам из нашей коллекции логов веб-доступа, которая была описана в Разделе 3. Статистика показывает, что удельный вес поискового трафика для 82% ординарных страниц составляет менее чем 10%, в то время как почти 60% спам-документов получат более 40% своих пользователей с поисковых систем. Кроме того, в то время как 20% спам-страниц имеют показатель SEOV превышающий 0.7, в числе ординарных документов подобной отметки достигает менее чем 1% страниц. Отсюда мы видим, что показатель SEOV у большинства спам-страниц будет выше, нежели чем у ординарных документов по той простой причине, что системы информационного поиска испытывают существенное давление со стороны спамденсинга и во многих случаях они являются единственным источником трафика для их страниц.
После прохождения пользователя по гиперссылке, в логах веб-доступа записывается как URL-адрес страницы-источника, так и URL целевого документа. Всякая страница может служить в разных случаях как источником, так и целью. Тем не менее, мы обнаружили, что некачественные страницы существенно реже выступают в логах веб-доступа в качестве документа-источника. Несмотря на то, что спам- страницы могут содержать сотни или даже тысячи исходящих гиперссылок, большинство пользователей редко осуществляют по ним переходы на следующие документы.
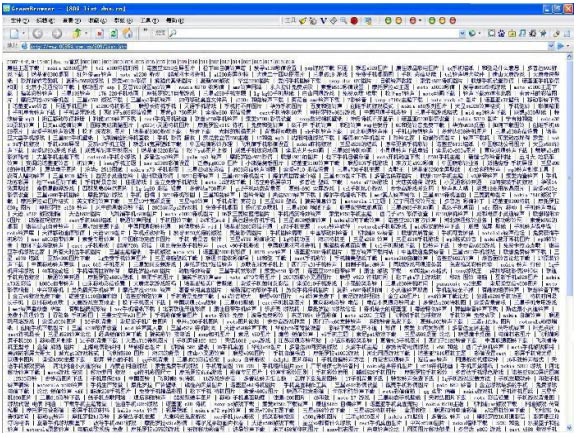
Рисунок 3. Спамовая страница, содержащая множество ключевых фраз для привлечения пользователей. Все ключевые фразами являются анкорами гиперссылок, ведущих на одну и ту же рекламу.
Мы можем определить коэффициент посредничества (SP) заданной интернет-страницы p как число обнаружений документа p в качестве страницы-источника, разделенное на количество ее обнаружений в логах веб-доступа в целом:

Экспериментальные результаты, приведенные на Рисунке 4, демонстрируют распределение ординарных и спам-страниц. Можно увидеть, что показатель посредничества у большинства ординарных документов оказывается существенно выше, нежели чем у некачественных страниц. Из нашего обучающего набора почти половина спам-страниц обнаруживаются в качестве документов-источников крайне редко (SP< 0.05). Только 7.7% спам-документов имеют показатель посредничества выше, чем 0.40, в то время как среди ординарах страниц такое значение можно присвоить более чем 53%.
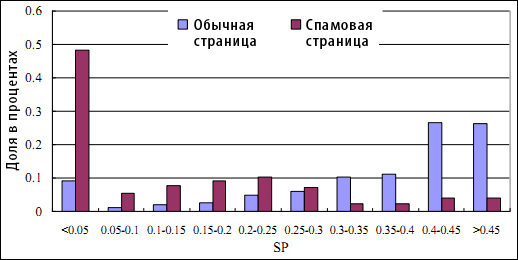
Рисунок 4. Распределение SP (Source Page) по ординарным и спам-документам. (Ось категорий: значение интервала SP; Ось значений: процент страниц с соответствующими значениями SP).
Аналогично предыдущему рисунку, статистическая информация по ординарным документам в этом случае также собиралась по всем интернет-сайтам из нашей коллекции логов веб-доступа, которая была описана в Разделе 3. Различия в распределении значений SP можно объяснить тем, что некачественные документы, как правило, создаются с целью агрессивной демонстрации вводящий в заблуждение рекламы или предложения услуг, явно низкого качества. Следовательно, подавляющее большинство пользователей, в случае обнаружения подобного рода сомнительного контента, не будут проходить по предложенным им гиперссылкам. Несколько спам-страниц все же обнаруживаются нами в качестве источника, но только по той простой причине, что при посещении этих документов через гиперлинки, пользователи отказываются от дальнейшего просмотра и уходят на другие страницы.
Внимание пользователей является одним из важнейших ресурсов, к обладанию которым стремится вебмастер. Увеличение посещаемости и просмотров страниц также имеет важное значение для подавляющего большинства коммерческих интернет-сайтов. Следовательно, владельцы ординарных сайтов стремятся к тому, чтобы их пользователи осуществляли навигацию в пределах заданного графа настолько долго, насколько это возможно. Однако, если мы взглянем на веб-спамеров, то в их случае дела обстоят совершенно по-иному. Вместо того, чтобы удержать своих пользователей, основная задача спамера при разработке сайта заключается в агрессивной демонстрации рекламы или предложения тех услуг, которые, вполне вероятно, пользователю не интересны. Они не рассчитывают на то, что пользователь будет осуществлять навигацию по страничкам сайта; следовательно, когда пользователь посещает какой-либо документ на некачественном ресурсе, реклама или предложение услуг будет продемонстрирована ему незамедлительно, по принципу «здесь и сейчас». Между тем, такое поведение со стороны спамеров является причиной отказа пользователя от дальнейшего просмотра (он не ожидает обнаружения подобного рода содержимого) и его досрочного ухода с веб-сайта. Следовательно, мы предполагаем, что в своей основной массе количество пользовательских просмотров страниц некачественного интернет-сайта не будет достигать существенного значения. Мы определяем показатель непродолжительной навигации (коэффициент SN) сайта s следующим образом:
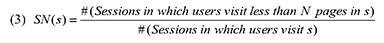
В отличие от рассмотренных ранее SEOV и SP, показатель непродолжительной навигации является ресурсной характеристикой, нацеленной на идентификацию мошеннических технологий. На основании того опыта, который был накоплен в процессе наших исследований, мы устанавливаем предельно допустимое пороговое значение N= 3. В то время как пребывание пользователей на некачественном сайте будет непродолжительным, на ординарном веб-сайте количество просмотренных страниц будет выше по той простой причине, что во втором случае он разрабатывается с целью максимально долгого удержания посетителей. Следовательно, коэффициент SN для спам-сайтов будет более высоким, чем для ординарных ресурсов. Статистические результаты, представленные на Рисунке 5, подтверждают наше предположение.
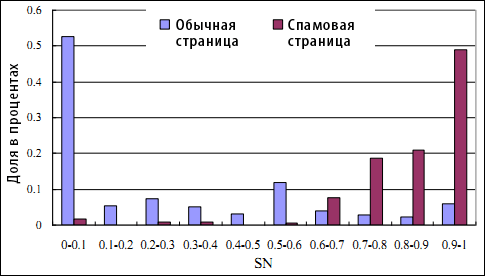
Рисунок 5. Распределение SN (Short-time Navigation) для ординарных и спам-сайтов. (Ось категорий: значение интервала SN; Ось значений: процент страниц с соответствующими значениями SN).
Если посмотреть на Рисунок 5, то можно увидеть, что 53% ординарных сайтов имеют показатели SN меньшие, чем 0.1, что свидетельствует о том, что более 90% сессий содержат более чем 2 просмотренных документов (как уже говорилось при определении SN, предельно допустимое пороговое значение N=3). Тем не менее, только 14% некачественных интернет-ресурсов имеют показатели NS меньшие, чем 0.1. Между тем, 35% спам-сайтов имеют значения SN превышающие 0.80, что соответствует просмотру 1-2 страниц прежде отказа от дальнейшего посещения ресурса. Следовательно, мы наблюдаем, что показатели SN большинства некачественных сайтов существенно превышают те значения, которые получают ординарные ресурсы по той простой причине, что первая категория сайтов никогда не имела и не будет иметь намерений удержать своих пользователей на веб-сайтах.
В Разделе 4.1 мы обнаружили, что источниками большинства посещений спам-документов являются поисковые системы. Когда мы занимались анализом тех поисковых запросов, по которым данные страницы появлялись в результатах органического поиска, мы обнаружили, что посредством их учета мы можем получить новые характеристики, которые также помогут нам отличать ординарные документы от спам-страниц. На основании проведенного анализа мы предложили две новые особенности, которым посвятили Раздел 4.4 и 4.5. Для того, чтобы привлечь пользователей поиска, многие спам- документы стараются ранжироваться по различным классам поисковых запросов. Например, спам-страница может содержать разно-тематические ключевые фразы (скачать рингтоны, скачать программное обеспечение, часто-задаваемые вопросы по использованию мобильных телефонов и пр.) для того, чтобы поисковик признал ее релевантной запросам, которые, естественно, могут описывать как отличные пользовательские намерения, так и тематики. В противоположность этому, ординарные документы имеют тенденцию иметь такое содержимое, которое релевантно малому числу тем и, следовательно, количество разно-тематических запросов, по которым их можно обнаружить относительно невелико. Для того, чтобы описать данную разницу между ординарными и спам-документами, мы предложили следующую характеристику, которая позволяет оценивать тематическое разнообразие пользовательских запросов (QD), по которым страница p может быть обнаружена в результатах органического поиска:
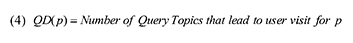
Для расчета QD(p) нам необходимо получить число тематических запросов, по которым пользователи попадают на документ p посредством обращения к поиску. Используя логи веб-доступа, мы собрали все запросы по которым были совершены визиты на страницу p. Затем, мы сгруппировали полученные запросы по тематике в соответствии с их схожестью (term similarity). Для расчета подобия между запросами мы определили функцию подобия по содержимому (content-based similarity function) нескольких запросов a и b как:
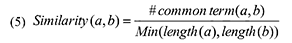
Здесь длина(a) и длина(b) указывает на количество терминов в соответствующих запросах, а #common term(a, b) — на количество общих терминов в этих двух запросах. В том случае, если Similarity(a, b) оказывается большим, чем предельно допустимое пороговое значение T, запросы a и b рассматриваются как тематически связанные. Исходя из нашего опыта, для всех проводимых экспериментов T=0.2. После того, как мы рассчитали параметр QD по всем страницам из нашего обучающего набора, мы получили следующие статистические распределения (см. Рис. 6):
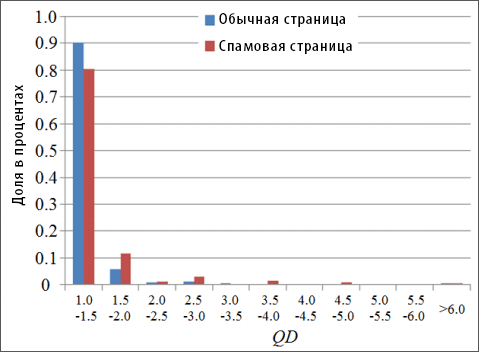
Рисунок 6. Распределение QD (Query Diversity) по ординарным и спам-документам. (Ось категорий: значение интервала QD; Ось значений: процент страниц с соответствующими значениями QD).
Значения QD для порядка 90% ординарных страниц и 80% спам-документов достигает значения меньшее или равное 1.5. Доля некачественных страниц со значением QD, превышающего 4.0 составляет 2.1%, что в 2.4 больше, чем соответствующая доля (0.86%) у регулярных документов. Некоторые ординарные страницы также имеют высокие значения QD; большинство из них являются посредниками (hub pages) или входными страницами веб-сайтов. Однако, в целом, показатель QD некачественных страниц выше, чем у ординарных документов по той простой причине, что в индустрии поискового спама наличествует тенденция к разработке разно-тематического содержимого, отвечающего различным пользовательским запросам. Распределение QD по ординарным документам и спам-страницам показывает, что применение данной особенности переставляется не столь эффективным инструментом для решения поставленных перед нами задач, как это наблюдается в случае с показателями SEOV, SP или SN. Однако мы обнаружили, что она позволяет идентифицировать важные виды спама (например, интернет-страницы, представляющие собой свалку ключевых фраз).
Когда мы изучали поисковые запросы по которым пользователи попадают на основную массу некачественных страниц, мы обнаружили, что большинство данных запросов не только популярны среди пользователей поиска, но и возвращают относительно малое число тех документов, которые смогли бы удовлетворить их информационные потребности. Если мы используем P(visit) в качестве представления вероятности посещения некачественной страницы S, тогда:
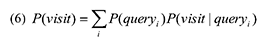
В этом уравнении queryi является теми запросами, которые приводят пользователя на документ S. Следовательно, P(queryi) является вероятностью того, что вопрос queryi будет задан системе информационного поиска, а P(visit|queryi) — вероятностью соответствующего посещения документа S в процессе поиска информации по запросу queryi. Отсюда видно, что спам-документы создаются под такого вида поисковые запросы по причине того, что, во-первых, все эти вопросы высокочастотные, а потому вероятность P(queryi) является высокой; а во-вторых, по ним можно обнаружить относительно малое количество ресурсов, а потому вероятность его посещения P(visit|queryi) также относительно высока. Следовательно, мы видим, что при создании своих некачественных веб-сайтов, поисковые спамеры употребляют некоторый ряд излюбленных ключевых фраз, которые в дальнейшем мы будем называть «спам-ориентированными запросами» (spam queries). В том случае, если мы сумеем их идентифицировать, тогда мы сможем использовать их в задачах обнаружения возможных некачественных страниц по их наличию вообще/тому их количеству, которое составляет удельный вес содержимого интернет-ресурсов. Для того чтобы их идентифицировать, мы, для начала, собрали пользовательские запросы, ведущие на 2732 спам-сайтов. Данные некачественные ресурсы были аннотированы асессорами коммерческой поисковой системой при рассмотрении случайной выборки результатов органического поиска за октябрь 2008 года. Была проведена сегментация текста и удаление стоп-слов, а также идентифицированы в качестве спам-терминов, те слова, которые появлялись в более чем в четырех выборках поисковых запросов, ведущих на некачественные веб-сайты. В общей сложности в ходе данного процесса мы собрали 2794 спам- терминов. Те, спам-ориентированные поисковые запросы, которые имели наибольшую частоту употребления в нашей коллекции представлены в следующей таблице:
Таблица II. Десятка наиболее часто-встречающихся спам-ориентированных поисковых запросов
| Спам-ориентированный запрос на китайском языке | Перевод на русский язык и толкование | Количество спам-сайтов, возвращенных в результатах поиска по запросам, содержащих данные термины |
| 照片 | Фото (как правило расширяет спам-ориентированный запрос ) | 1127 |
| 五月天 | «May day» (популярный китайский порно-ресурс, который на сегодняшней день заблокирован правительством КНР) | 803 |
| 人体 | Человеческое тело | 673 |
| 故事 | Рассказ | 582 |
| 藝術 | Арт (как правило расширяет спам-ориентированный запрос ) | 515 |
| 電影 | Фильм | 498 |
| 免費 | Бесплатно | 484 |
| 欧美 | Западный (как правило расширяет спам-ориентированный запрос ) | 483 |
| 美女 | Красотка | 475 |
| 視頻 | Видео | 452 |
В Таблице II мы можете оценить наиболее часто упоминаемые ключевые фразы, ассоциирующиеся с порнографическими ресурсами, которые запрещены на территории КНР. Несмотря на то, что подобного рода веб-сайты запрашиваются огромным числом интернет-пользовталей, доступными на сегодняшний день являются единицы. Но именно по этой причине их в наибольшей степени предпочитают спамеры. Для того чтобы подсчитать количество спам-ориентированных ключевых фраз, ассоциирующихся с какой-либо определенной веб-страницей, мы определяем число спам-ориентированных запросов (SQN), по которым заданный документ p возвращается в результатах поиска как (7):
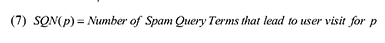
Из определения SQN, можно увидеть, что при составлении перечня спам-ориентированных запросов наша основная задача состоит в отнесении того или иного пользовательского запроса в спам-категорию или, наоборот, не включение его оный класс. Данный перечень может быть получен либо автоматическим способом, либо мануальным. В Уравнении (6) мы указали, что спамеры отдают предпочтение тем вопросам пользователей, которые при своей частой запрашиваемости, имеют дефицит в плане достоверных интернет-источников, возвращаемых системой информационного поиска. Следовательно, на основании частотности и соответствующего числа предлагаемых ресурсов могут быть разработаны автоматические методы. Особенности и алгоритм, предложенный Castillo и др. [2008] или Ntoulas и др. [2006] также могут быть использованы в задачах обнаружения спам-ориентированных ключевых фраз. Однако, как было описано выше, мы выбираем ручной способ, который поможет определить нам спам-ориентированные фразы с большей надежностью, нежели чем автоматические методы. Эта методология основывается на том факте, что каждая коммерческая поисковая система в значительной степени зависима от результатов аннотирования и оценок производительности, совершенствующих алгоритмы ранжирования. В процессе аннотирования, асессоры присваивают документам, возвращенных по какому-либо запросу, соответствующие отметки релевантности. Обычно, они также идентифицируют низкокачественные или откровенно некачественные результаты органической выдачи, аннотированная спам-страница может послужить как отличный источник для генерации необходимых нам спам-терминов. Таким образом, системам информационного поиска оказывается крайне удобно содержать обновляемый перечень спам-ориентированных ключевых фраз для расчета значения SQN. Несмотря на то, что спам-ориентированные фразы появляются в запросах, которые приводят пользователей на спам-страницы, очень часто, они достаточно редки для запросов, соответствующих ординарным документам. Следовательно, мы предположили, что значение SQN некачественной страницы должно быть более высоким, нежели чем для ординарных документов. Статистические данные, представленные на Рисунке 7, подтверждают наше предположение:

Рисунок 7. Распределение количества спам-ориентированных запросов (SQN) по ординарным и спам-страницам. (Ось категорий: значение интервала SQN; Ось значений: процент страниц с соответствующими значениями SQN).
На Рисунке 7, значение SQN для 83% ординарных страниц оказывается меньшим или равным 3.0, в то время как аналогичный показатель SQN имеет только половина спам-документов. Кроме того, менее чем 2% ординарных и более 20% спам-страниц имеют значение SQN превышающее 10.0. Следовательно, мы обнаруживаем, что для некачественных документов показатель SQN оказывается более высоким, чем для ординарных страниц постольку, поскольку спам-документы чаще используют спам-ориентированные ключевые фразы для получения более высокого рейтинга.
Классический алгоритм доверия TrustRank является эффективным алгоритмом ссылочного анализа, который назначает доверительные оценки веб-документам и обычно используется для идентификации некачественных страниц. Однако, как и прочие алгоритмы гиперссылочного анализа, методология TrustRank основывается на двух базовых предположениях [31]: предположение рекомендательного характера связи и предположение тематической близости. Иными словами, предполагается, если две страницы связаны гиперссылкой, ссылающаяся страница рекомендует к посещению цитируемый документ (рекомендательность); две страницы имеют схожую тематику (локальность). Тем не менее, поскольку текущая веб-среда загрязнена спамом и рекламными ссылками, указанные предположения и эффективность оригинального алгоритма доверия TrustRank неуклонно снижается. Для достижения лучших результатов в задачах оценки качественной составляющей веб-страниц с помощью текущих инструментов ссылочного анализа, исследователи предложили множество таких техник, как методологию обнаружения рекламы, сегментирования документов [Cai и др. 2004], а также идентификацию наиболее важных блоков в структуре интернет-документа [Song и др. 2004]. Однако большинство из предложенных методов взаимодействуют с содержимым документа или анализируют HTML-структуру, что не может давать эффективного результата для подавляющего большинства интернет-страниц. Для решения указанной проблемы, такие исследователи как Liu и др. [2008] запустили алгоритмы ссылочного анализа (BrowseRank) не на полном гиперссылочном графе, а на графе пользовательских просмотров. Предполагалось, что граф пользовательских просмотров поможет избежать множества проблем, возникающих на практике по той простой причине, что все гиперссылки на графе пользовательских просмотров выбираются для прохождения на тот или иной документ самими пользователями. В нашей предыдущей работе [Liu и др. 2009], мы обнаружили, что размер реберного набора графа пользовательских просмотров составляет только 7.59% реберного набора оригинального гиперссылочного графа, хотя оба графа имеют смежный набор вершин. Несмотря на то, что это свидетельствует о редуцировании подавляющей доли гиперссылочной информации, мы обнаружили стабильный рост в производительности алгоритма доверия TrustRank на графе пользовательских просмотров в плане отыскания не только качественных, но и некачественных интернет-страниц. Поскольку увеличение производительности оказалось достаточно стабильным, а вычислительные затраты значительно меньшими (по причине меньшего размера графа), мы запускаем алгоритм TrustRank на графе пользовательских просмотров, называя получаемые результаты оценками человеко-ориентированного TrustRank. Используя логи веб-доступа, описанные в Разделе 3, мы создаем граф пользовательских просмотров и сравниваем производительность алгоритма доверия на различных гиперссылочных графах. Для начала нам необходимо создать для алгоритма TrustRank исходное множество высококачественных документов, от которого будут распространятся наши доверительные оценки. В своих экспериментах мы будем использовать технологию создания, предложенную Gyongyi и др. [2004], которая базируется на алгоритме инверсивного Google PageRank и человеческих аннотациях. В качестве исходного набора было выбрано 1153 высококачественных интернет-сайтов; учитывая размер нашего графа пользовательских просмотров, количество итераций алгоритма составило 20. Для полного гиперссылочного графа мы использовали набор данных, описанный в работе Liu и др. [2009], который включал в себя более 3 млрд. страниц (все страницы содержались в индексе коммерческой поисковой машины). В целях оценки производительности мы создали проверочную выборку для реализации на нем попарного ранжирования. Первым технологию попарного ранжирования в качестве одной из метрик, позволяющей оценивать качество алгоритма, также использовал Gyongyi и др. [2004], примерно в тоже самое время, когда им был предложена методология доверия TustRank. Мы создали проверочный набор для реализации попарного ранжирования, включавший в себя 700 пар веб-сайтов. Эти пары были аннотированы теми же самыми асессорами, что помогали нам создавать обучающий спам-набор, описанный в Разделе 3. Считается, что попарное ранжирование показывает различие в репутации и пользовательских предпочтениях для пары веб-сайтов. Экспериментальные результаты человеко-ориентированного и традиционного TrustRank представлены в Таблице III.
Таблица III. Аккуратность попарного ранжирования для алгоритма TrustRank на разных графах.
| Граф | Аккуратность попарного ранжирования |
| Граф пользовательских просмотров | 0.9586 |
| Гиперссылочный граф | 0.8571 |
Глядя на результаты, приведенные в Таблице III, можно увидеть, что граф пользовательских просмотров имеет лучшую производительность по метрике аккуратности попарного ранжирования. Данные результаты согласуются с результатами, полученными в работах [Liu и др. 2008][Liu и др. 2009], которые обнаружили, что алгоритм гиперссылочного анализа может куда лучше отражать пользовательские предпочтения в том случае, если он выполнен на графе пользовательских просмотров, а не на оригинальном гиперссылочном графе. Liu и др. [2009] строят свои выводы, опираясь на сравнение ТОП20 сайтов, отранжированных различными алгоритмами ссылочного анализа. Наши результаты были получены в ходе использования попарного ранжирования на тестовом наборе существенно большего размера, а, следовательно, они являются более достоверными.
5. Пользовательское поведение, положенное в алгоритм обнаружения поискового спама
С целью комбинации особенностей пользовательского поведения, описанных в Разделе 4, мы использовали механизм машинного обучения, как завершающий этап решения нашей задачи по вычислению поискового спама. Во таких предыдущих исследованиях, как Svore и др. [2007], идентификация поискового спама рассматривалась как проблема классификации. Классификация спам-страниц имеет схожие трудности с классификации интернет-страниц, описанной в работе Yu и др. [2004] при отсутствии негативных образцов. Положительные образцы (спам-документы) могут аннотироваться некоторым числом асессоров, посредством применения таких технологий, как пулинг (pooling) [Voorhees 2001]. Однако в этом случае имеется большое количество негативных образцов, что равномерная выборка без смещения является практически невозможной, потому что это является основной проблемой исследователей Веба [Henzinger 2003]. Для того, чтобы избежать равномерной выборки и процесса аннотирования большого числа негативных образцов, исследователи разработали некоторый ряд алгоритмов обучения по крупномасштабным неразмеченным данным. Было предложено несколько механизмов обучения для классификации страниц на основании неразмеченных данных и числа положительных образцов. Для решения указанной проблемы были использованы такие технологии, как фреймворк машинного обучения PEBL (основывающийся на SVM с двумя классами) [Yu и др. 2004], частичное обучение с учителем [Nigam и др. 2000], одноклассовое обучение [Denis 1998] и SVM с одним классом (OSVM) [Manevitz и Yousef 2002]. В отличие от этих алгоритмов, наш анти-спам методология основывается на фреймворке, использующего наивный байесовский классификатор, который, как считается, является одним из самых конкурентоспособных методов решения практических задач машинного обучения [Mitchell 1997]. Мы использовали метод Байеса по той простой причине, что он является не только эффективным, но и действенным инструментом обучения при классификации документов или интернет-страниц. Наивный байесовский классификатор также предлагает нам вероятность того является ли та или иная веб-страница спамом или нет, что потенциально может быть использовано при построении результатов органической выдачи поисковых систем. Экспериментальные результаты, приведенные в Разделе 6.3, также показывают нам его эффективность по сравнению с такими алгоритмами машинного обучения, как OSVM, SVM с двумя классами, а также деревьями принятия решений. В задачах классификации некачественных страниц мы рассматриваем два случая: в первом случае классификация основывается только на одной характеристике, а во втором — участвуют несколько особенностей.
Случай 1. Анализ с использованием единственной характеристикой. Если мы используем только одну особенность пользовательского поведения A, вероятность некачественной природы интернет-страницы p, обладающей данной особенностью А, можно обозначить как:
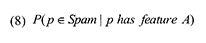
Мы можем использовать Теорему Байеса для того, чтобы переписать данное уравнение следующим образом:

В Уравнении (9), P(p ∈ Spam) является долей некачественных страниц во всей коллекции документов. Во множестве случаев оценить эту долю представляется достаточно трудно, в том числе и в нашей задачи по классификации спам-страниц. Тем не менее, если мы будем просто сравнивать значения P(p ∈ Spam | p has feature A) в заданном веб-корпусе, то P(p ∈ Spam) может быть рассмотрена как постоянная величина и, соответственно, не повлиять на результаты нашего сравнения. В фиксированном корпусе мы можем переписать Уравнение (8) следующим образом:
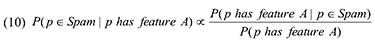
По условиям Уравнения (10), p(p has feature A | p ∈ Spam) может быть вычислено с использованием доли страниц в нашем наборе некачественных документов, обладающих особенностью A, в то время как P(p has feature A) равно доле документов с особенностью A в заданном корпусе. Здесь мы получаем:
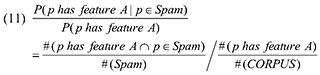
Если механизм отбора некачественных страниц из имеющейся выборки может быть рассмотрен в качестве аппроксимации равномерного процесса (в отличие от задачи равномерной выборки НЕ-спам документов, что существенно упрощает нашу работу постольку, поскольку по нашему предположению спам-страницы обладают схожими особенностями пользовательского поведения), мы можем переписать Уравнение (11) следующим образом:
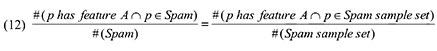
Подставляя выражения (11) и (12) в (10), получаем:

Можно увидеть, что в Уравнении (13) оценка #(Spam sample set) и #(CORPUS) может проводиться с использованием размера обучающего набора и корпуса. Посредством количества страниц, обладающих особенностью А в обучающем множестве и корпусе, возможно получение #(P has feature A ∩ p ∈ Spam sample set) и #(P has feature A). Следовательно, все слагаемые Уравнения (13) могут быть получены с использованием статистического анализа корпуса веб страниц; в соответствии с данным Уравнением мы можем вычислить вероятность поискового спама для каждой страницы.
Случай 2. Анализ с использованием нескольких особенностей. Если для идентификации спам-страницы мы будем использовать более одной характеристики, теорема Байеса предполагает следующее уравнение:
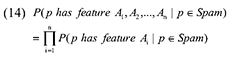
Пытаясь решить задачу классификации интернет-страниц с использованием особенностей пользовательского поведения, мы также обнаружили, что следующее Уравнение примерно соответствует Таблице IV.
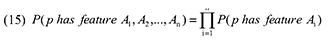
Таблица IV. Корреляция значений между особенностями пользовательского поведения на веб-странице.
| — | SEOV | SP | SN | TrustRank | QD | SQN |
| SEOV | 1.000 | — | — | — | — | — |
| SP | 0.0255 | 1.000 | — | — | — | — |
| SN | 0.1196 | 0.1221 | 1.000 | — | — | — |
| TrustRank | 0.0027 | 0.0163 | 0.0444 | 1.000 | — | — |
| QD | 0.0506 | 0.0512 | 0.0776 | 0.3447 | 1.000 | — |
| SQN | 0.1460 | 0.0706 | 0.1747 | 0.1186 | 0.5712 | 1.000 |
Корреляция показателей, приведенная в Таблице IV, показывает, что большинство особенностей примерно независимы друг от друга, так как корреляция их значений относительно невелика. Это объясняется тем фактом, что данные характеристики выводятся из различных информационных источников и, таким образом, вероятность их успешного влияния друг на друга невелика. Единственным исключением является зависимость QD и SQN, обусловленная тем, что оба показателя извлекаются из поисковых запросов, по которым пользователи попадают на интернет-странички. Следовательно, для проверки независимости между особенностями пользовательского поведения, в последующих частях нашего с Вами материала мы сохраним особенность SQN и откажемся от характеристики QD. При рассмотрении оставшихся пяти особенностей, перечисленных в Таблице IV, можно обнаружить, что значения атрибутов независимы, а также условно независимы от данного целевого значения. В ходе статистического анализа данных Таблицы IV, следующие Уравнения приблизительно справедливы в задачах классификации интернет-страниц, согласно нашим «наивным» предположениям:

Если мы подставим (9) в Уравнение (12), мы получим следующее уравнение для случая использования нескольких особенностей:
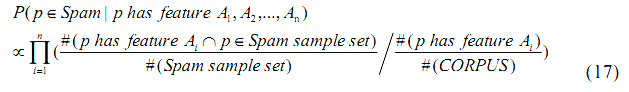
С учетом данного Уравнения, вероятность того, что веб-страница окажется некачественным документом, может быть рассчитана с учетом информации, следующей из нашего веб-корпуса, и соответствующей выборки спам-страниц. Следовательно, в задачах идентификации поискового спама мы можем использовать следующий алгоритм:
Шаг 1. Собираем логи веб-доступа (содержащих информацию, представленную в Таблице I) и создаем корпус пользовательских логов S;
Шаг 2. Рассчитываем показатели SEOV, SP и SQN в соответствии с Уравнениями (1), (2), (4) и (7) для каждой веб-страницы в S;
Шаг 3. Рассчитываем показатели SEOV, SP и SQN для каждого интернет-сайта в S, усредняя оценки по всем документам, формирующих ресурс;
Шаг 4. Рассчитываем показатель SN для каждого веб-сайта в S в соответствии с Уравнением (3);
Шаг 5. Создаем граф пользовательских просмотров по данным S и получаем оценки человеко-ориентированного TrustRank в соответствии с алгоритмом, предложенным Gyongyi и др [2004];
Шаг 6. Рассчитываем P(Spam | SEOV, SP, SN, SQN, TrustRank) в соответствии с Уравнением (13) для каждого документа в S.
Алгоритм 1. Детекция поискового спама с использованием поведенческих факторов
После исполнения Алгоритма 1 на S, мы получаем оценку вероятности обнаружения поискового спама для каждого документа в S. Эта оценка может быть использована для сепарации спам-страниц от ординарных документов.
После этапа обучения на обучающей выборке, мы переходим к созданию байесовского классификатора, который присваивает вероятность того, является ли веб-документ поисковым спамом или нет, на основании анализа пользовательского поведения. Мы использовали этот классификатор для обозначения вероятностей спама на всех веб-сайтах в логах доступа к Вебу.
Нами использовалась техника определения спама относительно всего сайта, а не постраничный метод в целях уплотнения данных – когда мы обрабатывали данный о каждой страницы, то было видно, что некоторые из них имели очень низкое число посещений и это снижало надёжность расчётов относительно поведения пользователей (SEOV и SP). Например, некоторые старые новости могут уже не вызывать интереса у пользователей. Но когда пользователь ищет требуемую информацию, он может попадать на такие страницы – и единственный визит за долгое время регистрирует SEOV = 1.00, что служит индикатором потенциальной спамовости страницы. Однако объединение информации со всех страниц сайта помогает избежать подобных ошибок, так как на сайте размещены ещё и актуальные новостные страницы.
Создание обучающей и тестовой выборок описаны в Разделе 3.4. Результаты всех экспериментов показаны в данном разделе.
Мы подобрали кривые ROC и соответствующие значения AUC для оценки производительности алгоритма детекции спама. Это является полезным методом для организации классификаторов и визуализации их производительности. Метод использовался во многих исследованиях по детекции спама, например в Web Spam Challenge и [Svore и др. 2007], [Abernethy и др. 2008]. Значения AUC по алгоритмам показаны в таблице V.
Таблица V. Значения корреляции между характеристиками пользовательского поведения на Веб-страницах.
| Выбор характеристики | Значение AUC | Потеря производительности |
| Все характеристики | 0.9150 | / |
| Все, кроме SEOV | 0.8935 | -2.40% |
| Все, кроме SP | 0.9010 | -1.55% |
| Все, кроме SN | 0.8872 | -3.13% |
| Все, кроме человеко-ориентированного TrustRank | 0.8051 | -13.64% |
| Все, кроме SQN | 0.8831 | -3.61% |
| Только человеко-ориентированный TrustRank | 0.8128 | -12.57% |
Как видно из таблицы V, использование всех предложенных характеристик дало значение AUC в 0.9150 по нашему алгоритму. Это показывает, что наш метод с вероятностью в 0.9150 отличит спамовую страницу от обычной. Таблица V так же показывает, что исключение любой предложенной характеристики повредит производительности. Однако последовательное исключение может послужить метрикой мощности каждой характеристики по детекции спама. Следовательно, человеко-ориентированный TrustRank является наиболее эффективной характеристикой, так как его исключение максимально снижает производительность алгоритма. Так же видно, что все пять предложенных характеристик дают максимальную производительность при работе в комплексе.
Ещё одним интересным открытием является то, что исключение из работы любой другой характеристики помимо человеко-ориентированного TrustRank даёт весьма незначительную потерю производительности (менее 5%). Однако при отдельном использовании человеко-ориентированного TrustRank произвоидтельность снизилась до AUC = 0.8128. Этот результат выше прочих, полученных при помощи четырёх характеристик в комплексе, но ниже, чем у комплекса из пяти характеристик (потеря производительности в 12.57%). Таким образом, хотя человеко-ориентированный TrustRank является наиболее эффективной характеристикой в детекции спама, наибольшая производительность достигается при комбинированном подходе.
Чтобы показать эффективность предложенного нами алгоритма детекции на основе обучения (Алгоритм 1), мы сравнили его производительность с прочими методиками. Алгоритм 1, машина опорных векторов и алгоритмы древа решений были приспособлены для использования пяти характеристик, описанных в Разделе 4 (кроме QD, т.к. её значения корреляции с SQN относительно высоко).
Инструментарий libSVM и C4.5 были использованы в наших экспериментах по сравнению в качестве реализации SVM и алгоритмов древ решений. Для обучения SVM мы использовали как одноклассовый, так и двухклассовый SVM для завершения задачи по идентификации спама. Обучение двухклассового SVM основано как на спамовых, так и неспамовых образцах, а одноклассовая SVM использует только спамовые образцы. В обучающую выборку включены только спамовые образцы. Поэтому мы подготовили дополнительную неспамовую выборку из 904 веб-сайтов для двухклассовой SVM. Она была создана с помощью того же метода, как и проверочная спамовая выборка из Раздела 3.3 , однако её размер был меньше проверочной выборки, так что количество спамовых и неспамовых образцов было примерно одинаковым.
Мы сравнили производительность нашего алгоиртма детекции (Алгоритм 1) с одноклассовой SVM, так как оба метода не требуют обучающих неспамовых образцов (хотя Алгоритм 1 так же требуется неразмеченных данных в процессе обучения). Для обучения двухклассовой SVM мы использовали C-SVC SVM и выбрали радиальную базисную функцию (RBF) в качестве ядра машины опорных векторов. Для обоих SVM применялась пятислойная кросс-валидация и решетчатого поиска для подстройки параметров C, γ и ν.
Для процесса обучения древа решений так же требовались образцы обоих типов, поэтому использовались обе выборки. После обучения C4.5 оригинальное древо состояло из 23 узлов, а усеченное — из 11 узлов.
Результаты оценки производительности обучающихся алгоритмов показаны в таблице VI и на рисунке 8. Видно, что значения точности одноклассовой SVM (с полнотой в 25%, 50% и 75%) и древа решений (с полнотой 75%) не записаны. Это является следствием того, что полнота алгоритмов не достигает данных значений в экспериментах.
Таблица VI. Сравнение AUC/точность-полнота по различным обучающимся алгоритмам детекции спама.
| Точность | AUC | AUC в сравнении с Алгоритмом 1 | |||
| Полнота 25% | Полнота 50% | Полнота 75% | |||
| Двухклассовая SVM | — | — | — | 0.5072 | -77.96% |
| Древо решений | 64.03% | 50.50% | — | 0.7149 | -26.26% |
| Алгоритм 1 | 100.00% | 76.14% | 43.75% | 0.9150 | / |
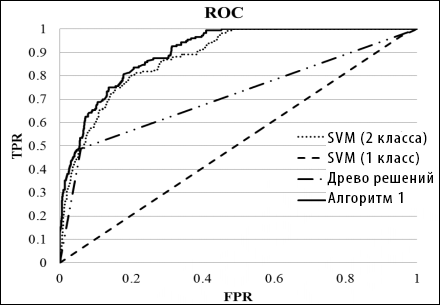
Рисунок 8. Кривые ROC различные алгоритмов.
По результата эксперимента в таблице VI и рисунке 8 мы обнаружили, что по метрике значений AUC Алгоритм 1 работает лучше всех. Обычная двухклассовая SVM была второй по производительности, а одноклассовая SVM показала себя хуже всего. По метрике точности и полноты предложенный алгоритм имел самую высокую точность при полноте в 25%, 50% и 75%. Удивителен тот факт, что производительность данного алгоритма превышала все остальные даже когда значения полноты достигали 75%. Это показывает, что предложенный алгоритм на основе спама и неразмеченных данных может успешно отличать крупную долю спамовых сайтов от нормальных.
Феномен производительность Алгоритма 1, возможно, заключается в том факте, что байесово обучение в особенности эффективно при низкой корреляции характеристик (см. Таблицу IV). Однако мы считаем, что этот результат тесно связан с тем фактом, что Алгоритм 1 использует информацию из неразмеченных данных, размер которых намного выше, чем обучающая спамовая/неспамовая выборка. Одноклассовая SVM работала хуже всех (немногим лучше случайных результатов) так как использовала только информацию из положительных примеров обучающей выборки и упустила прочую полезную информацию. Двухклассовая SVM и древо решений работали не так хорошо, так как они использовали бесспамовые обучающие образцы, охватывающие только малую долю неспамовых сайтов в Сети.
Как утверждается в Разделе 2, множество спамоборческих техник были предложены в целях идентификации спамовых страниц и удаления их из поисковой выдачи. Среди этих плгоритмов некоторых не были разработаны для специфических типов спама, например, основанный на содержании метод Cormack и др [2011] и алгоритм TrustRank от Gyongyi и др. [2004]. Мы сравнили производительность человеко-ориентированного алгоритма с этими двумя методиками, так как предлагаемый нами алгоритм так же способен идентифицировать разнообразные типы спама (см. раздел 6.5).
Метод, основанный на содержании был выбран по причине доказанной эффективности по бенчмаркам TREC Web track и WEBSPAM Challenge. С целью получения информации требуемой алгоритмом мы использовали корпус SogouT, содержащий 130 млн страниц, сканированных в китайском сегменте Сети в середине 2008 года. Страницы в созданной спамовой/бесспамовой обучающей выборке и проверочная выборка были отфильтрованы из корпуса и из них были извлечены 4-грамные характеристики пересекающихся байтов. Так как данные о доступе к Сети собирались на несколько месяцев позже создания корпуса SogouT, некоторые веб-сайты в обучающей/тестовой выборке не были включены в корпус. Мы обнаружили, что 641, 634 и 1377 сайтов были оставлены для обучающей спамовой выборки, бесспамовой выборки и проверочной выборки, соответственно. Мы в точности следовали инструкции по проверке алгоритма и задали такие же параметры его работы за исключение того, что китайские символы заключались в два байта. Таким образом символьные 4-грамные характеристики оригинального алгоритма были заменены на 2-грамные характеристики в нашей реализации.
Касательно алгоритма TrustRank мы использовали ту же исходную выборки, что и человеко-ориентированный TrustRank в Разделе 4.6. TrustRank работал со стандартными параметрами (коэффициент затухания = 0.85, число итераций = 20) по всему гиперссылочному графу, описанному в работе Liu и др. [2009], который содержит более 3 млрд страниц (все страницы в индексе коммерческой поисковой системы).
После запуска алгоритмов по проверочной выборке мы оценили их производительность по метрикам AUC и полноте-точности. Результаты показаны в Таблице VII и на Рисунке 9.
Таблица VII. Сравнение AUC/полнота-точность по разным алгоритмам детекции спама.
| Точность | AUC | |||
| Полнота 25.00% | Полнота 50.00% | Полнота 75.00% | ||
| Алгоритм контентного анализа [Cormack и др. 2011] | 81.63% | 7.65% | 4.08% | 0.6414 |
| Алгоритм ссылочного анализа [Gyongyi и др. 2004] | 74.43% | 34.09% | 18.75% | 0.7512 |
| Алгоритм анализа поведенческих факторов (Алгоритм 1) | 100.00% | 76.14% | 43.75% | 0.9150 |
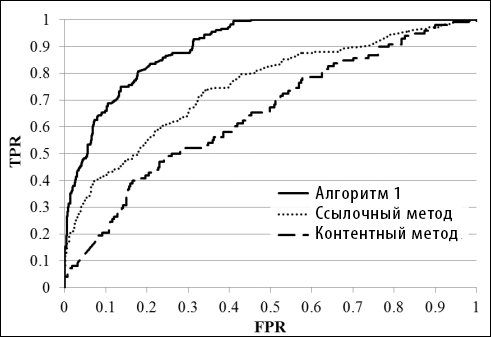
Рисунок 9. Кривые ROC различных анти-спам алгоритмов.
Результаты эксперимента в Таблице VII и на Рисунке 9 показывают, что предложенный человеко-ориентированный алгоритм превосходит и контентно-ориентированны и ссылочный алгоритмы по обеим метрикам оценки. TrustRank получил более высокие значения AUC, чем контентный метод, но его точность понижалась при полноте в 25%. Это означает, что крупная доля топовых страниц в списке спамовых результатов по контентному методу действительно были спамом.
Когда мы смотрим на результаты детекции спама контентным методом, было обнаружено, что этот метод идентифицирует большую часть спама по «приманочным» темам, уже существующим в спамовой обучающей выборке. Однако по спамовым темам вне обучающей выборки, производительность не так хороша. И хотя размер обучающей выборки был меньше для контентного метода из-за отсутствующих страниц в корпусе SogouT, мы считаем, что это являлось ключевой причиной для низкой производительности. Создание обучающей выборки со всевозможными спамовыми темами было бы весьма трудоёмким и сложным для регулярного обновления до актуального состояния. По сравнению с контентными методами, предложенный человеко-ориентированный алгоритм не требует информации о контенте страницы и задействования крупномасштабных контентных характеристик. И хотя он может упускать какую-либо контентную информацию, записанную на Веб-страницах, такие характеристики пользовательского поведения как SQN могут быть использованы для получения спамовой информации в процессе детекции. Как следствие, человеко-ориентированный подход работал лучше, чем контентный анализ.
Ещё одним открытием было то, что алгоритм TrustRank работал хуже, чем предложенный человеко-ориентированный алгоритм. Его производительность AUC (0.7512) были ниже, чем производительность человеко-ориентированного TrustRank (0.8128), предложенного в Разделе 4.6. Это коррелирует с нашими открытиями в работе Liu и др. [2009] о том, что алгоритм ссылочного анализа работал лучше на графе пользовательского сёрфинга, чем на всём гиперссылочном графе.
При рассмотрении результатов идентификации мы так же обнаружили, что предложенный алгоритм может определять некоторые новые типы спамовых веб-страниц, которые не распознаются прочими алгоритмами. Рисунок 10 показыавет спамовую страницу, которая была обнаружена человеко-ориентированным алгоритмом, но проигнорирована контентным методом и TrustRank.
В отличие от традиционных спам-контентных страниц, спамовые страницы на Рисунке 10 использовали поисковые результаты из крупнейшей китайской поисковой системы Baidu.com в качестве своего содержания. Поисковые результаты сканировались по Baidu.com по «приманочному» запросу (например, название телешоу или знаменитой песни) и использовались для обмана поисковой системы. По данной спамерской технике, сниппеты результатов (рис. 10а 10б) и ссылки (рис 10а) помещались на сами страницы. Несмотря на свою релевантность запросу, они несли нулевую смысловую нагрузку для сетевых пользователей, так как большая часть пользователей уже посетила страницу выдачи. Спамеры сконструировали такие страницы с целью увеличения посещаемости, хотя и поисковые системы и пользователи направлялись на абсолютно бесполезный ресурс.
По этой причине данный вид спама оказался более сложным для обнаружения, чем прочие его виды, такие как простое повторение ключевых фраз, наполнение контента нерелевантными ключевыми фразами, включение в скопированный контент ключевых фраз, а также склейка содержимого. Во-первых, «приманочные» запросы получают множество откликов в выдаче, потому что система старается найти совпадение по ключевой фразе. Во-вторых, приманочные запросы размещены по своему контексту в сниппетах поисковых результатов. По этим причинам данный вид спама считается высокорелевантной страницей по запросу-приманке. Как следствие, классические характеристики контентного спама, такие как длина документа [Ntoulas и др. 2006], длина заголовка страницы [Ntoulas и др. 2006], n-грамная языковая модель [Ntoulas и др. 2006] [Cormack и др. 2011] и теги POS [Piskorski и др. 2008] с трудом характеризуют данный вид спама.
Однако ситуация в корне другая при использовании человеко-ориентированного фреймворка детекции спама. Технологии спама не меняют того факта, что спамовые страницы созданы для обмана пользователей. Поэтому характеристики пользовательского поведения (в особенности SEOV, SN и SQN) могут легко идентифицировать такие страницы.
Рисунок 10. Две спамовых страницы, использующие популярный запрос-приманку «珠光宝气» (в пер. «Жемчужина жизни» — популярное на TV китайское игровое шоу) в своем содержимом.


Одной из проблем современных анти-спамовых технологий яаляется то, что их возможность охвата всего многообразия спама не так вилка. Поэтому мы хотели проверить, насколько хорошо предложенный алгоритм справляется с этой задачей. По результатам эксперимента в Таблице VIII мы обнаружили, что ссылочный, словесный и все прочие виды спама могут быть обнаружены при помощи нашего алгоритма.
Таблица VIII. Тип страниц 300 возможных спам-страниц, анализированных алгортмом.
| Тип страницы | % |
| Неспамовые | 5.33% |
| Спам (ключевые фразы) | 31.67% |
| Спам (ссылки) | 25.33% |
| Спам (фразы + ссылки) | 11.33% |
| Спам (другой) | 27.00% |
| Недоступные страницы | 9.33% |
В Таблице VIII 300 страниц, среди которых мог встречаться спам были маркированы алгоритмом в соответствии с их типом. Эти страницы являются самыми высокоранжируемыми в списке потенциально спамовых страниц, упорядоченного по вероятности спама. Во-первых, мы узнали, что большинство идентифицированных страниц действительно являлись спамовыми, а 5.33% были обычными страницами. Однако дальнейший анализ неспамовых страниц показал, что они являются страницами низкого качества, использующими некоторые техники SEO-оптимизации для привлечения пользователей. Во-вторых, некоторое число страниц были недоступны во время запроса. Мы считаем, что большая часть этих страниц ранее была спамовыми, так как подобные страницы склонны к частому изменению своих URL, чтобы не попадать в бан-листы поисковых систем. В то же время обычные страницы не меняют свои доменные имена, так как это вредит их позициям в выдаче поисковых систем. Наконец, видно что фразовый и ссылочный спам легко идентифицируется нашим алгоритмом. Мы использовали характеристики пользовательского поведения для определения Веб-спама, что позволило не обращать внимания и не тратить ресурсы на идентификацию его типа. Этот факт можно считать возможным решением проблемы многообразия спама в Разделе 2.2.
Мы упоминали «проблему своевременности» в разделе 2.2 и посчитали её одной из наиболее сложных для современных антиспамовых технологий. Мы узнали ,что наш алгоритм успешно идентифицирует различные виды веб-спама и хотели бы максимально сократить время идентификации спамовых страниц. Поэтому мы провели несколько экспериментов для оценки скорости нашего алгоритма и её сравнения с прочими антиспамовыми системами.
В таблице VIII мы получили информацию о типах страниц по 300 страницам из списка возможного спама. Среди этих страниц 256 были спамовыми, а 28 на момент запроса были недоступны для анализа. Мы использовали данные о доступе к Сети с 12 ноября 2008 по 15 декабря 2008. Алгоритм обнаружил спамовые страницы 15 декабря. Если поисковые системы могут идентифицировать спам так же быстро, как и наш алгоритм, посещаемость этих сайтов из выдачи должна быть снижена. Для определения эволюции посещаемости мы собрали данные по этим сайтам с 22 декабря 2008 по 20 января 2009. На рисунке 11 показаны результаты анализа.
На рисунке 11 пять самых популярных поисковых систем в Китае (Baidu, yahoo! China, Google China, Sogou, Yodao) былииспользованы для сбора данных о пользовательских визитах. Из рисунка 11 (а) видно, что за период сбора данных количество переходов из поисковых систем было относительно высоко (в среднем 4085 UV в день). Спустя месяц средняя посещаемость упала примерно до 3189 UV/день. Этот результат показывает, что поисковые системы идентифицировали некоторые спамовые сайты перестали их высоко ранжировать. Однако общее число переходов из поисковых систем всё ещё составляло около 80% в первые 30 дней. Предложенный метод детекции спама способен обнаруживать спам в первый же месяц (15 декабря 2008), а поисковые системы тратят на 10 дней больше (40 дней). Это означает, что наш алгоритм хорошо справляется с «новорождёнными» спамовыми страницами и превосходит в этом антиспамовые технологии коммерческих поисковых систем.
Рисунок 11. Переходы из поисковых систем. (a) 12 ноября 2008 – 15 декабря 2008. (b) 22 декабря 2008 – 20 января 2009.
По вышеописанным результатам экспериментов мы обнаружили, что предложенный фреймворк эффективно работает в детекции спама и в особенности хорош в идентификации нового спама и разнообразных типов спамовых технологий. Однако существует несколько ограничений предложенного метода. Некоторые используемые фреймворком характеристики получаются из взаимодействия пользователя с поисковой системой (такие как SEOV, QD и SQN). Это означает, что спам должен быть сначала проиндексирован поисковой системой, а затем осмотрен пользователями в течение нескольких недель перед непосредственным удалением.
В процессе удаления спама посредством мудрости толпы спамовые страницы показываются некоторым пользователям. На этих пользователей будет влиять существование спамовых сайтов и алгоритм сможет определить спам на основе их поведения. И хотя мы считаем предложенный фреймворк способным к эффективной идентификации поискового спама, необходимо свести число пользователей, страдающих от спама к минимуму.
Чтобы узнать, как много пользователей будут подвержены влиянию спама до непосредственной идентификации алгоритмом, мы изучили, как много данных об использовании Сети требуется предложенному алгоритму для эффективной работы. По всем 1997 веб-сайтам в созданной тестовой выборке (описанной в Разделе 3.3) мы подсчитали их статистику UV с 12 ноября 2008 по 15 декабря 2008. Было обнаружено, что наиболее посещаемым сайтом является tianya.com, который посетило 2375743 пользователей. Так же было несколько сайтов с низким UV, хотя все сайты были посещены как минимум 10 пользователями после процесса фильтрации, (описанного в Разделе 3.2) который исключил сайты менее чем с 10 посещенями. После получения статистики UV мы разбили веб-сайты тестовой выборки на 10 блоков. Каждый блок содержкал около 200 образцов. Размер блоков и их соответствующие диапазоны UV показаны в Таблице IX.
Таблица IX. Размер разбитых блоков и соответствующие диапазоны UV в тестовой выборке.
| Номер блока | Количество веб-сайтов | Диапазон UV |
| 1 | 96 | 10-15 |
| 2 | 96 | 16-35 |
| 3 | 197 | 36-100 |
| 4 | 202 | 100-300 |
| 5 | 20 | 301-1,500 |
| 6 | 202 | 1,501-5,100 |
| 7 | 201 | 5,101-16,000 |
| 8 | 205 | 16,001-53,000 |
| 9 | 205 | 53,001-250,000 |
| 10 | 192 | 250.001++ |
После разбиения веб-сайтов в тестовой выборке на блоки, мы изучили производительность детекции спама в каждом блоке по метрике значений AUC. Результаты эксперимента показаны на рисунке 12. По результатам были сделаны следующие выводы:
Во-первых,производительность детекции спама во всех блоках превышала 0.76 по метрике AUC, что показывает эффективность алгоритма даже с небольшим количеством данных об использовании. Во-вторых, алгоритм, анализирующий поведение пользователей, работал лучше при больших объёмах данных об использовании, так как производительность в блоках 6-10 была существенно выше производительность в блоках 1-5. Однако при увеличении числа посещений с 10-15 (блок 1) до 301-1500 (блок 5) производительность оставалась примерно одинаковой. Это означает, что производительность обнаружения спама по веб-сайтам с UV менее 1500 (за 33 дня в среднем по 45 UV) может быть не такой эффективной, как с большим количеством UV. По сравнению с большим числом пользователей поисковых систем, необходимый объём данных об изспользовании сайтов относительно мал, в особенности, когда речь идёт о спамовых сайтах. Поэтому мы считаем предложенный алгоритм актуальным для использование в коммерческих поисковых системах.
Однако предложенный человеко-ориентированный фреймворк не стоит считать полной альтернативой современным методам детекции спама. Этот метод можно использовать для определения свежих спам-сайтов и, что важнее, для новых спамерских технологий, но для этого требуется достаточный объём данных об использовании. Поисковые системы, в индекс которых включено множество спамовых страниц, показывают минимальное количество спама в топовых результатах. Спамовые страницы, которые не показываются пользователям практически недоступны для анализа нашим алгоритмом, так как он не сможет собрать информацию о пользовательском поведении. Но вообще, уменьшение количества этих страниц довольно важно для улучшения эффективности поисковых систем. Поэтому наш алгоритм стоит использовать наряду с классическими антиспамовыми технологиями, которые нацелены на максимально быстрое выявление и удаление спама вместо ожидания его выдачи пользователям.
Рисунок 12. Производительность детекции спама в разных блоках.
Большинство методик обнаружения спама нацелены на известные типы спамовых страниц используя контентный или гиперссылочный анализ. На фоне этих классических методов мы предлагаем новый человеко-ориентированный подход. Наш алгоритм анализирует крупномасштабные логи доступа к Сети и использует отличительные характеристики пользовательского поведения на нормальных и спамовых страницах. Мы комбинируем технологии машинного обучения и описательный анализ поведенческих характеристик на спамовых страницах. Таким образом достигается более глубокое понимание связи между паттернами поведения пользователей и спамерской деятельностью.
На данный момент человеко-ориентированный подход может быть не так эффективен как передовые антиспамовые алгоритмы. Однако с помощью пользовательского поведения предложенный метод может выявлять различные виды спамовых страниц вне зависимости от используемого типа спамерской технологии. Свежий спам так же может быть обнаружен достаточно быстро, при этом с минимальным влиянием на пользователей. Наш метод не ставит своей целью полную замену существующих антиспамовых алгоритмов, но он может помочь поисковым системам в поиске самого надоедливого спама и выявлении передовых спам-технологий.
В ближайшем будущем мы надеемся расширить наш фреймворк до учёта содержания страницы и гиперссылочных характеристик. Так же мы планируем провести исследование модели оценки качества веб-страницы на основе результатов, полученных в данной работе.
На ранних стадиях работы мы получили много ценной информации из дискуссий с Ийяном Ином, Зийяном Тоном, Куо Жаном и Янли Ни. Выражаем благодарность Жаочану Вону из sogou.com за его помощь в создании корпуса данных. Так же благодарим всех анонимных рецензентов данной работы за их ценные комментарии и предложения.
Перевод материала «Identifying Web Spam with the Wisdom of the Crowds» выполнили Константин Скоморохов и Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации